





端到端机器学习
When working on any Machine learning type problem, it is important that the ML engineer and, even the entire data science team are conscious of the structure of their workflow and the sequence of steps they will be taking, for them to be able to produce a scalable ML solution in different areas of applications and environments. In this article, you will understand the importance of following a standard structured ML workflow, you will also see the steps involved and how it can be applied to a real-life project. There is always a method to everything right ;-)
在处理任何机器学习类型问题时,很重要的是,ML工程师,甚至整个数据科学团队都必须意识到其工作流程的结构以及将要采取的步骤顺序,以便他们能够制定出一个在应用程序和环境的不同领域中的可扩展ML解决方案。 在本文中,您将了解遵循标准的结构化ML工作流程的重要性,还将看到其中涉及的步骤以及如何将其应用于现实生活中的项目。 总有一种正确的方法;-)
标准ML工作流程,内容和原因 (Standard ML Workflow, the What, and Why)
Practitioners and experts with years of experience up their sleeves in the industry have strongly recommended that a standard workflow be followed when working on an ML project from start to end because, it allows you as an ML engineer to make the best decisions considering how they affect future steps, measure the solution performance and, easily go back to a phase to optimize for better performance of the entire solution. Here’s a checklist to follow that is an excerpt from the popular and very resourceful ML textbook by Aurelien Geron, Hands-On Machine Learning with Scikit-Learn, and TensorFlow.
拥有多年行业经验的从业者和专家强烈建议从头到尾进行ML项目时遵循标准的工作流程,因为它使您作为ML工程师可以考虑它们的影响来做出最佳决策未来的步骤,测量解决方案的性能,然后轻松地回到一个阶段进行优化,以提高整个解决方案的性能。 这是一份要遵循的清单,该清单摘自Aurelien Geron的流行且资源丰富的ML教科书,Scikit-Learn的动手机器学习和TensorFlow。
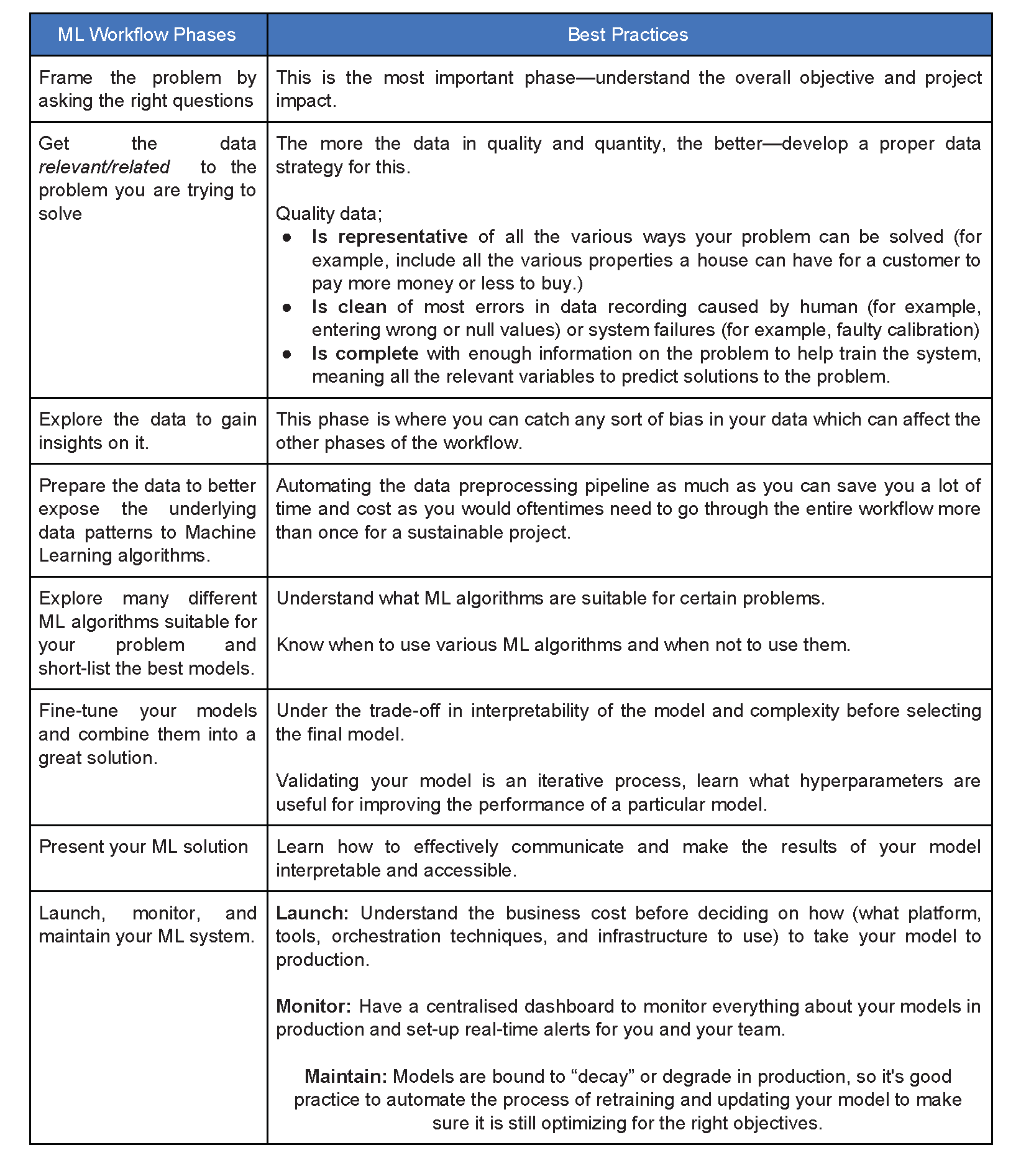
ML工作流程的阶段(Phases of ML Workflow)
From the picture above, which I will advise you to save a copy of for future reference, you can see how the standard ML workflow methodology is summarized into 8 main steps that are briefly yet clearly explained. Now let us look closely at a fictitious business problem and see how this workflow can be applied to it.
从上面的图片(我将建议您保存的副本以供将来参考)中,您可以看到标准ML工作流程方法是如何归纳为8个主要步骤的,这些步骤已进行了简要而清晰的解释。 现在,让我们仔细研究一个虚拟业务问题,并了解如何将此工作流程应用于该业务问题。
Problem Description
问题描述
The sales representative of a construction aggregate company had been facing difficulties meeting his sales targets which he believed was due to complaints from clients about inconsistencies in the product quality. From his meeting with the plant supervisor, he found out that the Production plant had undergone an upgrade in the last quarter and that raw materials normally go through testing before production. The Plant supervisor couldn’t see any obvious reason for the inconsistencies but to the Sales representative, the time of the upgrade coincides with when the complaints began. The meeting didn’t yield any solution for the sales rep yet. After doing some more research and interacting with his network, he found out that the machines had data records, so he inquired with the manager of the analytics department for a way forward. The analytics manager informed him of the availability of data that could maybe help them detect the inconsistency in concrete compressive strength through a robust model. The sales rep stated his interest in finding out the factors that influence the concrete compressive strength most so that he can strategize a way to present his findings to the management.
一家建筑骨料公司的销售代表面临实现其销售目标的困难,他认为这是由于客户抱怨产品质量不一致所致。 从与工厂主管的会面中,他发现生产工厂在上个季度进行了升级,原材料通常在生产前经过测试。 工厂主管看不出任何明显的原因引起的不一致,但是对销售代表而言,升级时间与投诉开始的时间是一致的。 会议尚未为销售代表提供任何解决方案。 经过更多研究并与他的网络进行交互之后,他发现这些机器具有数据记录,因此他向分析部门的经理询问了前进的方向。 分析经理告知他有可用的数据,这些数据可能可以帮助他们通过可靠的模型检测混凝土抗压强度的不一致。 销售代表表示他有兴趣找出最能影响混凝土抗压强度的因素,以便他可以制定策略向管理层介绍其发现。
Your role in this as an ML Engineer is to build an end-to-end ML project that solves this problem.
作为ML工程师,您的职责是建立一个解决此问题的端到端ML项目。
框架问题 (Frame the Problem)

The first step of the ML workflow allows us to properly understand the project we are going into. Why do we even need to predict the concrete compressive strength? What is our objective? In this case, the aim is to resolve the problem of product quality inconsistency to improve sales. Being able to predict the concrete compressive stress and determine the factors influencing it will help us achieve this aim so yes this problem can be solved using ML. There are a lot more relevant questions that need to be asked in this phase, you can find some of those important questions here.
ML工作流程的第一步使我们能够正确理解我们要进行的项目。 为什么我们甚至需要预测混凝土的抗压强度? 我们的目标是什么? 在这种情况下,目的是解决产品质量不一致的问题,以提高销量。 能够预测混凝土的压应力并确定影响其的因素将有助于我们实现这一目标,因此可以使用ML解决此问题。 在此阶段,还有很多相关问题需要提出,您可以在此处找到一些重要问题。
获取相关数据 (Get Relevant Data)

We move to the next phase of our project, data gathering. Here you will need to determine what type of data you need and how much of it, find out data sources, check legal obligations for the data, get data and, determine its size and type. This phase is carried out better with the assistance of the project subject domain expert. You can also make effort to ensure data fairness in this phase. Note that automating this phase makes adding more data in the future more seamless. Remember to set aside your test set! In the problem being addressed here, our data source can be found here, you can get more understanding of the relevant data features by researching on the internet.
我们进入项目的下一个阶段,即数据收集。 在这里,您将需要确定所需的数据类型以及所需的数据量,找出数据源,检查数据的法律义务,获取数据,并确定其大小和类型。 在项目主题领域专家的协助下,可以更好地完成此阶段。 您也可以在此阶段努力确保数据公平。 请注意,此阶段的自动化使将来添加更多数据更加无缝。 记住要搁置测试仪! 在这里解决的问题中,我们的数据源可以在这里找到,您可以通过在Internet上进行研究来对相关数据功能有更多的了解。
探索性数据分析 (Exploratory Data Analysis)

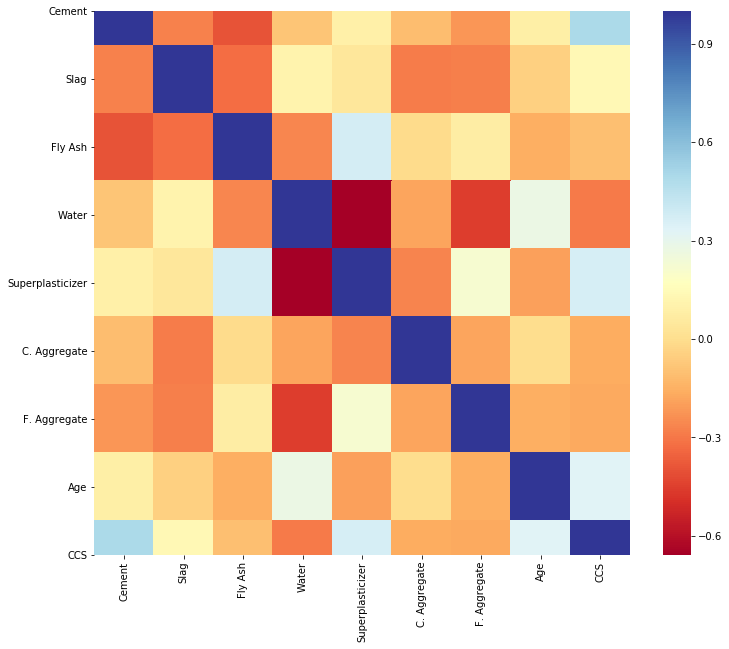
Drawing insights from exploring the data especially with the help of a domain expert can go a long way to save you the stress of taking the wrong approach or using the wrong attributes for your model building. Study the attributes of your data and characteristics, visualize and understand the data correlation and then document everything you learn from the exploration. Here are the first 5 instances of the data set we are working with,
尤其是在领域专家的帮助下,从探索数据中汲取见解可以大大节省您采取错误方法或使用错误属性进行模型构建的压力。 研究数据的属性和特征,可视化并了解数据的相关性,然后记录您从探索中学到的一切。 这是我们正在使用的数据集的前5个实例,
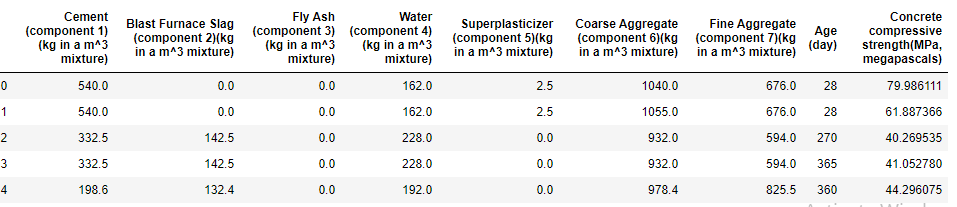
This is a heatmap showing our data correlation, there are many more things you can do during data exploration.
这是一个热图,显示了我们的数据相关性,在数据探索期间您还可以做更多的事情。
准备数据 (Prepare the Data)
Preparing and transforming the data helps the ML model to be built to better understand the underlying patterns.
准备和转换数据有助于构建ML模型,以更好地理解底层模式。

Automate this process as much as possible so that you can easily prepare the test set and also fresh data sets or instances when you get them and also you can apply the same preprocessing to any other projects you have to work on. For our example, I tried different methods of scaling and transformation and decided that the model performed better without transformation. Here’s a link to the Github repo, so you can see practically how the methodology in this article is applied.
尽可能自动执行此过程,以便您可以轻松准备测试集以及获取时的新鲜数据集或实例,还可以将相同的预处理应用于必须处理的任何其他项目。 在我们的示例中,我尝试了不同的缩放和变换方法,并确定该模型在不进行变换的情况下表现更好。 这是Github存储库的链接,因此您实际上可以看到如何应用本文中的方法。
迭代不同的算法 (Iterate over Different Algorithms)

Explore different algorithms that you think might be suitable for your data set. If you read more about descriptions of the data set, you will see that the attributes have a non-linear relationship, this can also be deduced in the preprocessing stage, so in picking algorithms to work with, I gravitated towards more non-linear models. Automate this process as much as possible to make you model training faster. After evaluating the model performances, you can shortlist the top-performing models to optimize their performance. You must pay attention to see the variables significant for each model and also the type of errors they make so you know the best candidates in case you decide to build an ensemble model. You can always go back to any of the earlier phases, to better preprocess and understand attribute relationships.
探索您认为可能适合您的数据集的不同算法。 如果您阅读有关数据集描述的更多信息,您会发现属性具有非线性关系,这也可以在预处理阶段得出,因此在选择算法时,我倾向于使用更多的非线性模型。 尽可能自动执行此过程,以使您更快地建模训练。 在评估了模型的性能之后,您可以将性能最高的模型入围,以优化其性能。 您必须注意查看对于每个模型重要的变量,以及它们造成的错误的类型,以便在决定构建整体模型时了解最佳候选者。 您始终可以返回到任何较早的阶段,以更好地进行预处理和了解属性关系。
微调您的模型 (Fine-tune your Models)

Fine-tune your model for better performance. Tune hyperparameters, create an ensemble model, etc. In this phase, you need to keep in mind the trade-off of model complexity and interpretability. In the example project, after fine-tuning, I settled for the Decision Tree Regressor model because it didn’t overfit and it was also easier to illustrate the feature importance for the sales rep to see.
调整模型以获得更好的性能。 调整超参数,创建整体模型等。在此阶段,您需要记住模型复杂性和可解释性之间的权衡。 在示例项目中,经过微调后,我选择了决策树回归模型,因为它并不过分拟合,并且更容易说明销售代表要看的功能重要性。
介绍您的解决方案 (Present Your Solution)

The importance of presenting your model in a way that is interpretable and understandable by a non-ML or data science professional is important in every setting. Let’s say I use a PowerPoint presentation of charts and graphs to show the sales representative the attributes that affect the concrete strength more than others, I would then have made it possible for him to communicate the finding with management to effect the required changes. Here’s a representation of the level of importance of the features in predicting the concrete compressive strength as stated in the problem overview, you can see the 3 main features that influence this prediction.
在每种情况下,以非ML或数据科学专业人员可以解释和理解的方式展示模型的重要性非常重要。 假设我使用PowerPoint图表和图表演示向销售代表展示了比其他因素更能影响混凝土强度的属性,那么我就可以使他与管理层沟通发现以实现所需的更改。 这是问题概述中所述特征在预测混凝土抗压强度方面的重要性级别的表示,您可以看到影响该预测的3个主要特征。
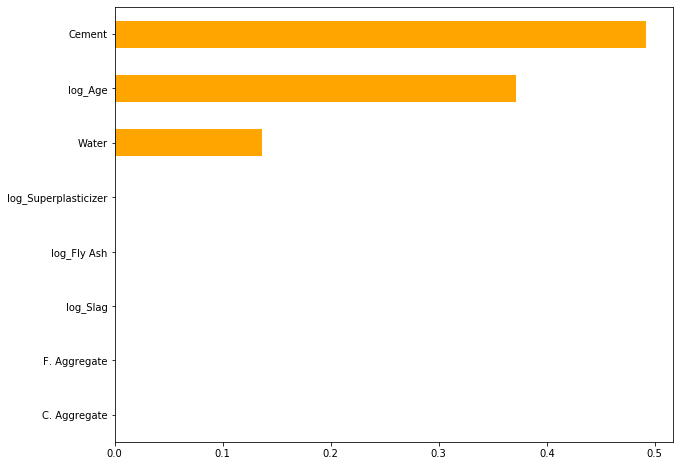
Always show them the big picture of your solution and showing what worked and what didn’t work.
始终向他们展示您的解决方案的概况,并告诉他们什么有效和什么无效。
启动和监控 (Launch and Monitor)

Finally, you have to get your ML solution into production and it doesn’t stop there. ML systems rot with more data so you also need to regularly monitor your model and if needed retrain the model to ensure good performance even as the data evolves. When deciding how to take your model to production you need to consider business cost and the user type. Since our example is a fictitious problem it is not being produced, but let’s say you had to take it to production, what strategy or platform would you use? You can share your ideas in the comments so we can see how they can be applied.
最后,您必须将ML解决方案投入生产,而且还不能止步于此。 机器学习系统会存储更多数据,因此您还需要定期监视模型,并在需要时重新训练模型以确保即使数据不断变化也具有良好的性能。 在决定如何将模型投入生产时,您需要考虑业务成本和用户类型。 由于我们的示例是一个虚构的问题,因此它没有被生产出来,但是假设您必须将其投入生产,那么您将使用什么策略或平台? 您可以在评论中分享您的想法,以便我们了解如何应用它们。
结论 (Conclusion)
You’ve seen the importance of applying a standard Machine Learning workflow to any project you are working on and how it can make your workflow smoothly and bring out the best solution. I want to stress this point, you need to perform a needs analysis and ask the relevant questions before jumping into solving any problem with ML so that you don’t put in all that work only to realize in the end that it doesn’t solve any problem.
您已经了解了将标准的机器学习工作流程应用于正在处理的任何项目的重要性,以及如何使您的工作流程顺畅并提出最佳解决方案。 我想强调这一点,您需要进行需求分析并提出相关问题,然后再着手解决ML的任何问题,以便您不会投入所有工作,只是最终意识到它无法解决任何问题。
Further Reading:
进一步阅读:
Hands-On Machine Learning with Scikit-Learn, Keras, and Tensorflow: Concepts, Tools and, Techniques to Build Intelligent Systems
使用Scikit-Learn,Keras和Tensorflow进行动手机器学习:构建智能系统的概念,工具和技术
端到端机器学习















 447
447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









