





One of the most common exercises in data analysis is to split your data into groups and perform an aggregation.
数据分析中最常见的练习之一是将数据分为几组并进行汇总。
For example, let’s say you have customer sales data with several different dimensions:
例如,假设您有几个不同维度的客户销售数据:
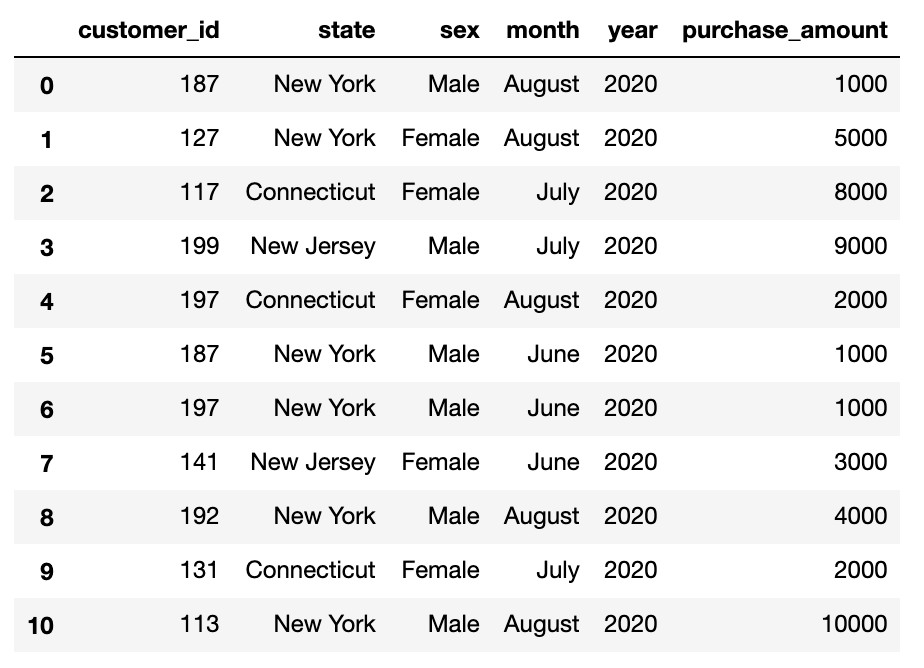
A natural question might be to ask — what is the sales total by state? Or by sex? Or by month?
一个自然的问题可能是要问-各州的总销售额是多少? 还是按性别? 还是按月?
In this post, I’ll walk through the ins and outs of the Pandas “groupby” to help you confidently answers these types of questions with Python.
在本文中,我将逐步介绍Pandas“ groupby”的来龙去脉,以帮助您自信地用Python回答这些类型的问题。
可视化的“分组”数据 (A visual representation of “grouping” data)
The easiest way to remember what a “groupby” does is to break it down into three steps: “split”, “apply”, and “combine”.
记住“ groupby”的操作的最简单方法是将其分为三个步骤:“拆分”,“应用”和“组合”。
1.Split: This means to create separate groups based on a column in your data. For example, we can split our sales data into months.
1.拆分:这意味着根据数据中的列创建单独的组。 例如,我们可以将销售数据分成几个月。
2. Apply: This means that we perform a function on each of the groups. For example, we can sum the sales for each month.
2. Apply:这意味着我们在每个组上执行一项功能。 例如,我们可以汇总每个月的销售额。
3. Combine: This means that we return a new data table with each of the results from the “apply” stage.
3.合并:这意味着我们将返回一个新的数据表,其中包含来自“应用”阶段的每个结果。
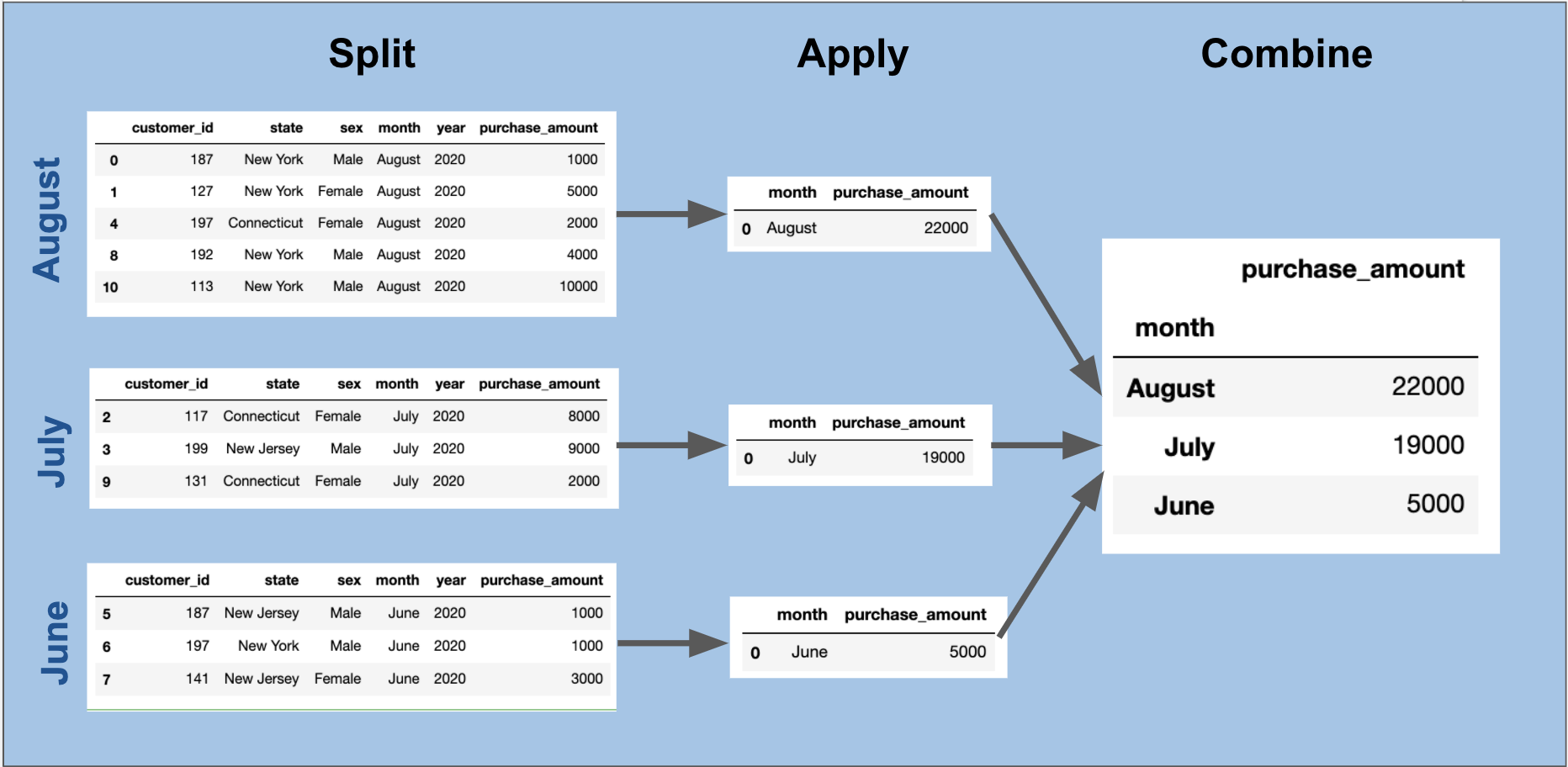
The magic of the “groupby” is that it can help you do all of these steps in very compact piece of code.
“ groupby”的神奇之处在于它可以帮助您以非常紧凑的代码段完成所有这些步骤。
在熊猫中运行“ groupby” (Running a “groupby” in Pandas)
In order to get sales by month, we can simply run the following:
为了按月获得销售,我们可以简单地运行以下命令:
sales_data.groupby('month').agg(sum)[['purchase_amount']]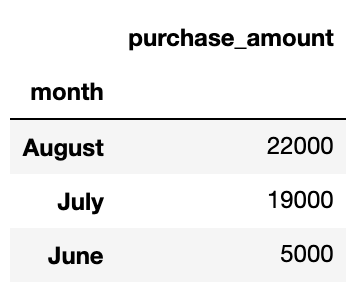
了解熊猫的“拆分”步骤 (Understanding the “split” step in Pandas)
The first thing to call out is that when we run the code above, we are actually running two different functions — groupby and agg — where groupby addresses the“split” stage and agg addresses the “apply” stage.
首先要指出的是,当我们运行上面的代码时,我们实际上正在运行两个不同的函数-groupby和agg-其中groupby解决了“ split”阶段,而agg解决了“ apply”阶段。
For example, the following code actually does the work to split our data into “month” groups:
例如,以下代码实际上是将我们的数据分为“月”组的工作:
sales_data.groupby('month')
While this output is not particularly interesting, there are a handful of things we can do with this object before we even get to the aggregation stage:
尽管此输出并不是特别有趣,但是在进入聚合阶段之前,我们可以使用一些方法来处理此对象:
Check out the “groups” attribute:
查看“组”属性:
grouped = sales_data.groupby('month')
grouped.groups
Notice that the “groups” attribute returns a dictionary, whose keys are the groups and whose values are the row indexes from each group.
注意,“ groups”属性返回一个字典,该字典的键是组,其值是每个组的行索引。
2. Inspect an individual group using the “get group” method:
2.使用“获取组”方法检查单个组:
grouped.get_group('August')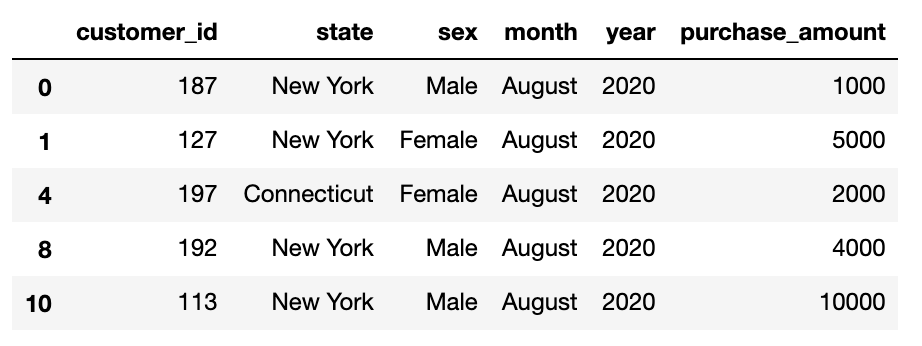
3. Iterate through each group:
3.遍历每个组:
for name, group in grouped:
print(name, group)
了解熊猫的“ agg”步骤 (Understanding the “agg” step in Pandas)
Now let’s explore the “agg” function.
现在让我们探讨“ agg”功能。
The simplest thing we can pass to “agg” is the name of the aggregation we would like to perform on each of the groups:
我们可以传递给“ agg”的最简单的事情是我们希望在每个组上执行的聚合的名称:
sales_data.groupby('month').agg(sum)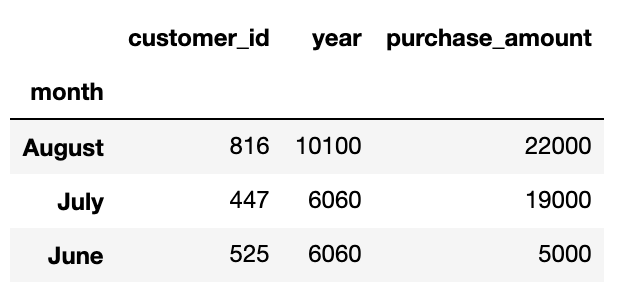
Note that this approach will return the sum of all available numerical columns in the DataFrame.
请注意,此方法将返回DataFrame中所有可用数字列的总和。
However, in this example, it doesn’t make any sense to return the sum of the “year” or “customer_id” columns.We can fix that by indexing with the list of columns we want to see at the end of our agg call:
但是,在此示例中,返回“ year”或“ customer_id”列的总和没有任何意义。我们可以通过索引要在agg调用末尾看到的列的列表来解决此问题。 :
sales_data.groupby('month').agg(sum)[['purchase_amount']]We can also index with a single column (as opposed to list):
我们还可以使用单个列(而不是列表)建立索引:
sales_data.groupby('month').agg(sum)['purchase_amount']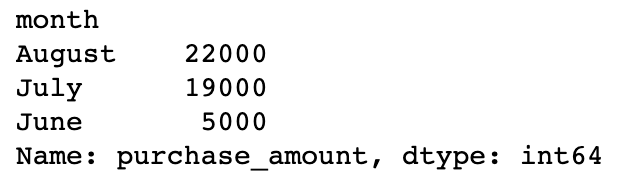
In this case, we get a Series object instead of a DataFrame. I tend to prefer working with DataFrames, so I typically go with the first approach.
在这种情况下,我们得到一个Series对象而不是DataFrame。 我倾向于使用DataFrames,因此通常采用第一种方法。
先进的“分组”概念 (Advanced “groupby” concepts)
Now that we have the basics down, let’s go through a few of the more advanced things we can do.
既然我们已经掌握了基础知识,那么让我们看一下我们可以做的一些更高级的事情。
多种聚合 (Multiple aggregations)
First, let’s say we want the total sales and the average sales by month. To accomplish this, we can pass a list of functions to “agg”:
首先,假设我们要按月列出总销售额和平均销售额。 为此,我们可以将函数列表传递给“ agg”:
sales_data.groupby(‘month’).agg([sum, np.mean])[‘purchase_amount’]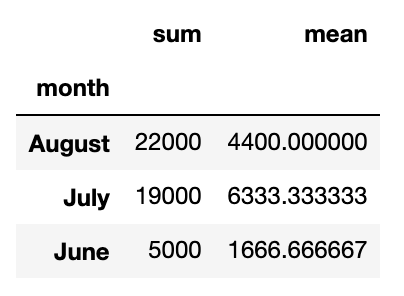
This is helpful, but now we are stuck with columns that are named after the aggregation functions (ie. sum and mean).
这很有用,但是现在我们停留在以聚合函数(即求和和均值)命名的列上。
And this becomes even more of a hindrance when we want to return multiple aggregations for multiple columns:
当我们要为多个列返回多个聚合时,这甚至变得更加困难:
sales_data.groupby(‘month’).agg([sum, np.mean])[[‘purchase_amount’, 'year']]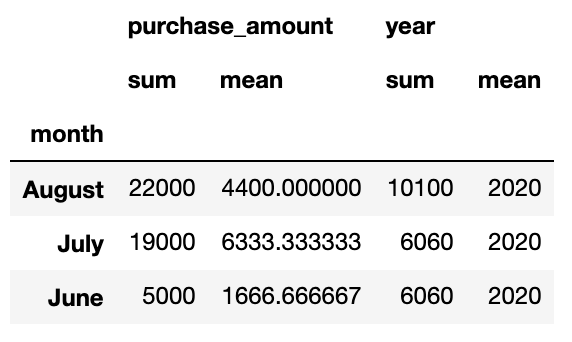
In this case, we’re stuck with a multi-index for our column names:
在这种情况下,我们为列名使用了多索引:

In order to resolve this, we can leverage the “NamedAgg” object that Pandas provides. The syntax here is a little different, but our output makes it very clear what’s going on here:
为了解决这个问题,我们可以利用熊猫提供的“ NamedAgg”对象。 这里的语法有些不同,但是我们的输出非常清楚这里发生了什么:
sales_data.groupby(“month”).agg(
total_sales=pd.NamedAgg(column=’purchase_amount’, aggfunc=sum),
avg_sales=pd.NamedAgg(column=’purchase_amount’, aggfunc=np.mean),
max_year=pd.NamedAgg(column=’year’, aggfunc=max))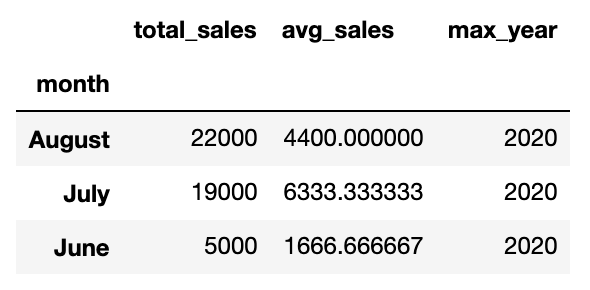
This is a really useful mechanism for performing multiple functions on different columns, while maintaining control of the column names in your output.
这是一种非常有用的机制,用于在不同的列上执行多种功能,同时保持对输出中列名的控制。
We can also pass a dictionary to the agg function, but this does not provide us with the same flexibility to name our resulting columns:
我们还可以将字典传递给agg函数,但这不能为我们提供相同的灵活性来命名结果列:
sales_data.groupby(“month”).agg( {‘purchase_amount’: [sum, np.mean],
‘year’: [max]})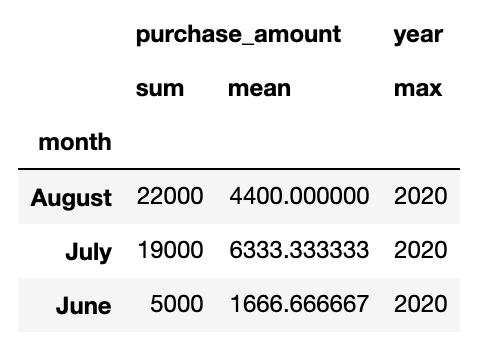
在多列上分组 (Grouping on multiple columns)
Another thing we might want to do is get the total sales by both month and state.
我们可能想做的另一件事是按月和按州获得总销售额。
In order to group by multiple columns, we simply pass a list to our groupby function:
为了对多列进行分组,我们只需将一个列表传递给groupby函数:
sales_data.groupby(["month", "state"]).agg(sum)[['purchase_amount']]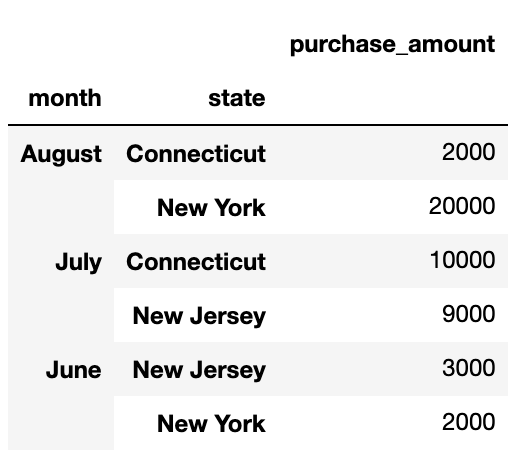
You’ll also notice that our “grouping keys” — month and state — have become our index. We can easily convert these to columns by running the “reset_index” function:
您还将注意到,我们的“分组键”(月份和州)已成为我们的索引。 我们可以通过运行“ reset_index”函数轻松地将它们转换为列:
g = sales_data.groupby([“month”, “state”]).agg(sum) g[[‘purchase_amount’].reset_index()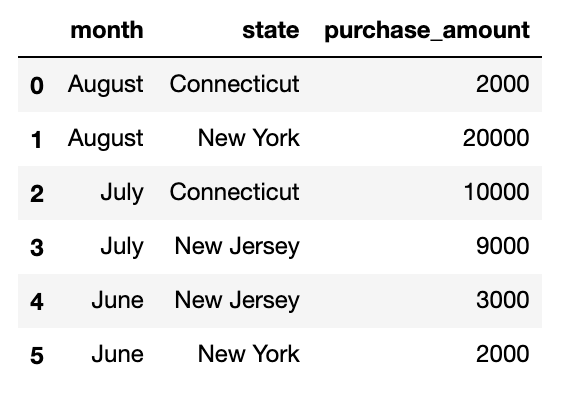
总结思想 (Closing thoughts)
Once you have a solid intuition behind the “split-apply-combine” approach, running a “groupby” in Pandas is fairly straightforward.
一旦对“拆分应用组合”方法有了深刻的了解,在Pandas中运行“ groupby”就非常简单了。
Nonetheless, you may still run into issues with syntax when you’re first getting comfortable with the functions. If you’re facing errors, I recommend taking a more careful look at the data types that you’re passing.
但是,当您初次熟悉函数时,仍然可能会遇到语法问题。 如果遇到错误,建议您仔细检查要传递的数据类型。
For example, if you’re running something similar to the code below, make sure that you’re passing a list of functions to agg and that you’re placing a list of columns inside another set of brackets to do the column indexing:
例如,如果您正在运行与以下代码类似的代码,请确保将函数列表传递给agg,并确保将列列表放置在另一组括号内以进行列索引:
sales_data.groupby(‘month’).agg([sum, np.mean])[[‘purchase_amount’, ‘year’]]For a quick review on Pandas indexing, checking out my intuitive guide below. Happy coding!
要快速浏览熊猫索引,请查看下面的直观指南。 编码愉快!
翻译自: https://towardsdatascience.com/ultimate-pandas-guide-mastering-the-groupby-104306251739















 2502
2502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}