





aws emr 大数据分析
This article is part of the series and continuation of the previous post.
In the previous post, we saw how we can stream the data using Kinesis Firehose either using stackapi or using Kinesis Data Generator.
在上一篇文章中,我们了解了如何使用Kinesis Firehose,使用stackapi或使用Kinesis Data Generator流数据。
In this post, let’s see how we can decide on the key processing steps that need to be performed before we send the data to any analytics tool.
在本文中,让我们看看如何确定将数据发送到任何分析工具之前需要执行的关键处理步骤。
The key steps, I followed in this phase are as below :
我在此阶段遵循的关键步骤如下:

Step 1 : Prototype in DataBricks
步骤1:DataBricks中的原型
I always use DataBricks for prototyping as they are free and can be directly connected to AWS S3. Since EMR is charged by the hour, if you want to use spark for your projects DataBricks is the best way to go.
我一直使用DataBricks进行原型制作,因为它们是免费的,并且可以直接连接到AWS S3 。 由于EMR是按小时收费的,因此,如果您想在项目中使用spark,DataBricks是最好的选择。
Key Steps in DataBricks
DataBricks中的关键步骤
Create a cluster
创建集群
This is fairly straightforward, just create a cluster and attach to it any notebook.
这非常简单,只需创建一个集群并将其附加到任何笔记本即可。

2. Create a notebook and attach it to the cluster
2.创建一个笔记本并将其附加到群集

3. Mount the S3 bucket to databricks
3.将S3存储桶安装到数据块
The good thing about databricks is that you can directly connect it to S3, but you need to mount the S3 bucket.
关于databricks的好处是您可以将其直接连接到S3 ,但是您需要安装S3存储桶。
Below code mounts the s3 bucket so that you can access the contents of the S3 bucket
下面的代码挂载了s3存储桶,以便您可以访问S3存储桶的内容
This command will show you the contents of the S3 bucket
此命令将向您显示S3存储桶的内容
%fs ls /mnt/stack-overflow-bucket/
%fs ls / mnt / stack-overflow-bucket /

After this we do some Exploratory data analysis in spark
之后,我们在Spark中进行一些探索性数据分析
这里完成的关键处理技术是: (Key Processing techniques done here are :)
Check and Delete duplicate entries ,if any.
检查并删除重复的条目(如果有)。
Convert the date into Salesforce compatible format (YYYY/MM/DD).
将日期转换为与Salesforce兼容的格式(YYYY / MM / DD)。
Step 2 : Create a Test EMR cluster
步骤2:建立测试EMR丛集
pyspark script that you developed in the DataBricks environment gives you the skeleton of the code .
您在DataBricks环境中开发的pyspark脚本为您提供了代码的框架 。
However, you are not done yet!You need to ensure that this code won’t fail when you run the script in aws. So for this purpose, I create a dummy EMR cluster and test my code in the iPython notebook.This step is covered in detail in this post.
但是,还没有完成!您需要确保在aws中运行脚本时此代码不会失败。 因此,对于这个目的,我创建了一个虚拟EMR集群和测试我在IPython的notebook.This步代码中详细说明了这个职位 。
Step 3:Test the Prototype code in pyspark
步骤3:在pyspark中测试原型代码
In the Jupyter notebook that you created, make sure to test out the code.
在您创建的Jupyter笔记本中,确保测试代码。
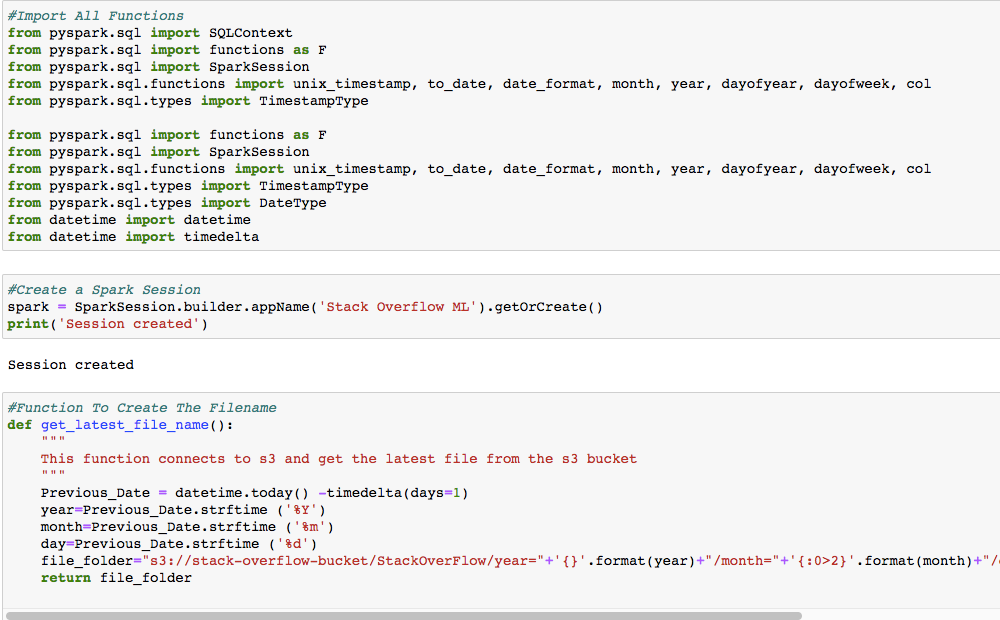

Key points to note here:
这里要注意的重点:
Kinesis Streams output the data into multiple files within a day. The format of the file depends on the prefix of the S3 file location set while creating the delivery stream.
Kinesis Streams在一天之内将数据输出到多个文件中。 文件的格式取决于创建传送流时设置的S3文件位置的前缀 。
Spark job runs on the next day and is expected to pick all the files of Yesterday’s date from the s3 bucket.
Spark作业在第二天运行,并有望从s3存储桶中提取昨天日期的 所有文件 。
Function get_latest_filename creates a text string which matches the file name spark is supposed to pick up.
函数get_latest_filename创建一个文本字符串 ,该文本字符串与应该接收的spark文件名称匹配。
So in the Jupyter notebook, i am testing if spark is able to process the file without any errors
因此,在Jupyter笔记本电脑中 ,我正在测试spark是否能够处理文件而没有任何错误
Step 4 & 5 :Convert the ipython notebook into python notebook and upload it in s3.
步骤4和5:将ipython笔记本转换为python笔记本,并在s3中上传。
You can use the below commands to convert the ipython notebook to pyscript
您可以使用以下命令将ipython笔记本转换为pyscript
pip install ipython
点安装ipython
pip install nbconvert
点安装nbconvert
ipython nbconvert — to script stack_processing.ipynb
ipython nbconvert —编写脚本stack_processing.ipynb
After this is done ,upload this script to the S3 folder
完成此操作后,将此脚本上传到S3文件夹
Step 5 : Add the script as a step in EMR job using boto3
步骤5:使用boto3将脚本作为EMR作业中的步骤添加
Before we do this, we need to configure the redshift cluster details and test if the functionality is working.
在执行此操作之前,我们需要配置redshift集群详细信息并测试该功能是否正常运行。
This will be covered in the Redshift post.
这将在Redshift帖子中介绍 。
aws emr 大数据分析















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









