





aws集群emr重启
This post gives you a quick walkthrough on AWS Lambda Functions and running Apache Spark in the EMR cluster through the Lambda function. It also explains how to trigger the function using other Amazon Services like S3.
这篇文章向您提供有关AWS Lambda函数的快速演练,并通过Lambda函数在EMR集群中运行Apache Spark。 它还说明了如何使用其他Amazon Services(例如S3)来触发功能。
什么是AWS Lambda? (What is AWS Lambda?)
AWS Lambda is one of the ingredients in Amazon’s overall serverless computing paradigm and it allows you to run code without thinking about the servers. Serverless computing is a hot trend in the Software architecture world. It enables developers to build applications faster by eliminating the need to manage infrastructures. With serverless applications, the cloud service provider automatically provisions, scales, and manages the infrastructures required to run the code.
AWS Lambda是亚马逊整体无服务器计算范例的组成部分之一,它使您无需考虑服务器即可运行代码。 无服务器计算是软件体系结构领域的热门趋势。 它使开发人员无需管理基础架构即可更快地构建应用程序。 借助无服务器应用程序,云服务提供商可以自动配置,扩展和管理运行代码所需的基础架构。
It abstracts away all components that you would normally require including servers, platforms, and virtual machines so that you can just focus on writing the code.
它抽象化了您通常需要的所有组件,包括服务器,平台和虚拟机,以便您可以专注于编写代码。
Since you don’t have to worry about any of those other things, the time to production and deployment is very low. Another great benefit of the Lambda function is that you only pay for the compute time that you consume. This means that you are being charged only for the time taken by your code to execute.
由于您不必担心其他任何事情,因此生产和部署时间非常短。 Lambda函数的另一个巨大好处是,您只需为消耗的计算时间付费。 这意味着只向您收取代码执行所花费的时间。
This is in contrast to any other traditional model where you pay for servers, updates, and maintenances.
这与您需要支付服务器,更新和维护费用的任何其他传统模型形成对照。
The AWS Lambda free usage tier includes 1M free requests per month and 400,000 GB-seconds of compute time per month. To know about the pricing details, please refer to the AWS documentation: https://aws.amazon.com/lambda/pricing/
AWS Lambda免费使用层包括每月100万个免费请求和每月40万GB-秒的计算时间。 要了解定价详细信息,请参阅AWS文档: https : //aws.amazon.com/lambda/pricing/
You do need an AWS account to go through the exercise below and if you don’t have one just head over to https://aws.amazon.com/console/. If you are a student, you can benefit through the no-cost AWS Educate Program. I would suggest you sign up for a new account and get $75 as AWS credits. I won’t walk through every step of the signup process since its pretty self explanatory.
您确实需要一个AWS帐户来完成以下练习,如果您还没有一个,请直接前往https://aws.amazon.com/console/ 。 如果您是学生,则可以通过免费的AWS Educate计划受益。 我建议您注册一个新帐户,并获得75美元的AWS积分。 由于注册过程很容易说明,因此我不会介绍注册过程的每个步骤。
什么是Apache Spark? (What is Apache Spark?)
Apache Spark is a distributed data processing framework and programming model that helps you do machine learning, stream processing, or graph analytics. It is an open-source, distributed processing system that can quickly perform processing tasks on very large data sets. It is often compared to Apache Hadoop, and specifically to MapReduce, Hadoop’s native data-processing component. The difference between spark and MapReduce is that Spark actively caches data in-memory and has an optimized engine which results in dramatically faster processing speed.
Apache Spark是一个分布式数据处理框架和编程模型,可帮助您进行机器学习,流处理或图形分析。 它是一个开放源代码的分布式处理系统,可以对非常大的数据集快速执行处理任务。 通常将它与Apache Hadoop进行比较,尤其是与Hadoop的本地数据处理组件MapReduce进行比较。 Spark和MapReduce之间的区别在于,Spark主动在内存中缓存数据,并具有优化的引擎,从而可以显着提高处理速度。
To know more about Apache Spark, you can refer to these links:
要了解有关Apache Spark的更多信息,可以参考以下链接:
https://spark.apache.org/docs/latest/
https://spark.apache.org/docs/latest/
https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-spark.html
https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-spark.html
In this article, I would go through the following:
在本文中,我将介绍以下内容:
- Creating Lambda functions in Python 在Python中创建Lambda函数
- Integrating it with other AWS services such as S3 将其与其他AWS服务(例如S3)集成
- Running a Spark job as a Step Function in EMR cluster 在EMR集群中将Spark作业作为步进功能运行
I assume that you have already set AWS CLI in your local system. If not, you can quickly go through this tutorial https://cloudacademy.com/blog/how-to-use-aws-cli/ to set it up.
我假设您已经在本地系统中设置了AWS CLI。 如果没有,您可以快速浏览本教程https://cloudacademy.com/blog/how-to-use-aws-cli/进行设置。
I have tried to run most of the steps through CLI so that we get to know what's happening behind the picture.
我尝试通过CLI运行大多数步骤,以便我们了解图片后面的情况。
1.创建一个S3存储桶 (1. Creating an S3 bucket)
- Create an s3 bucket that will be used to upload the data and the Spark code. 创建一个s3存储桶,该存储桶将用于上传数据和Spark代码。
Get the Arn for the bucket created. To find the ARN for an S3 bucket, you can look at the Amazon S3 console Bucket Policy or CORS configuration permissions pages.
获取创建的存储区的Arn。 要查找 S3存储桶 的ARN ,您可以查看Amazon S3控制台存储桶策略或CORS配置权限页面。
aws s3api create-bucket --bucket <bucket-name> --region us-east-1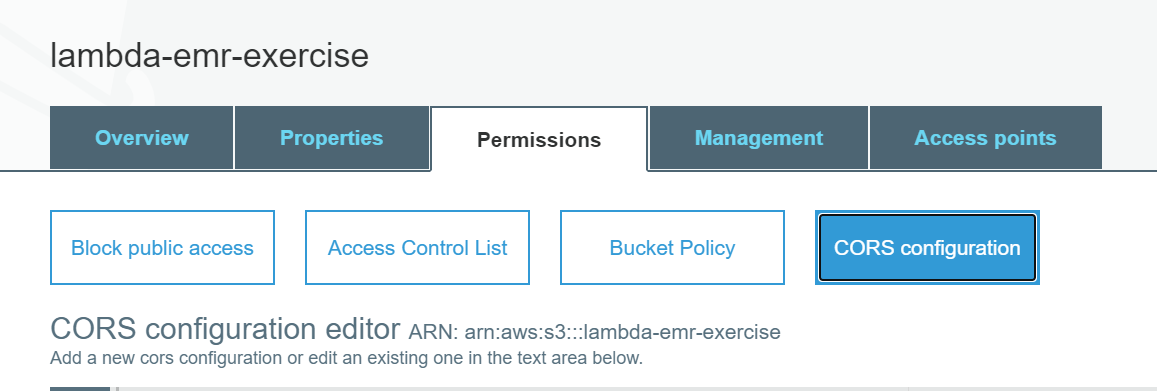
2.创建IAM角色和策略 (2. Creating an IAM Role and Policies)
An IAM role is an IAM entity that defines a set of permissions for making AWS service requests. IAM policy is an object in AWS that, when associated with an identity or resource, defines their permissions.
IAM 角色是一个IAM实体,它定义了一组用于发出AWS服务请求的权限。 IAM 策略是AWS中的一个对象,当与身份或资源关联时,将定义其权限。
2.1. Creating an IAM policy with full access to the EMR cluster.
2.1。 创建对EMR群集具有完全访问权限的IAM策略。
Create a file in your local system containing the below policy in JSON format. e.g policy
在本地系统中以JSON格式创建一个包含以下策略的文件。 例如政策
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "elasticmapreduce:*",
"Resource": "*"
}
]
}Run the command to create a policy:
运行命令以创建策略:
aws iam create-policy --policy-name <policy-name> --policy-document file://<filename>A similar output will be printed to the console like below:
类似的输出将打印到控制台,如下所示:
{
"Policy": {
"PolicyName": "emr-full-access",
"PolicyId": "ANPAQ6X4YKPB7BY",
"Arn": "arn:aws:iam::123456789012:policy/emr-full-access",
"Path": "/",
"DefaultVersionId": "v1",
"AttachmentCount": 0,
"PermissionsBoundaryUsageCount": 0,
"IsAttachable": true,
"CreateDate": "2020-09-04T03:20:42Z",
"UpdateDate": "2020-09-04T03:20:42Z"
}
}Note down the ARN (highlighted in bold )created which will be used later.
记下创建的ARN(以粗体突出显示),稍后将使用它。
We will be creating an IAM role and attaching the necessary permissions.
我们将创建一个IAM角色并附加必要的权限。
2.2. Creating an IAM role
2.2。 创建IAM角色
We create an IAM role with the below trust policy. An IAM role has two main parts:
我们使用以下信任策略创建IAM角色。 IAM角色有两个主要部分:
- Permission Policy which describes the permission of the role 权限策略,描述角色的权限
- Trust Policy which describes who can assume the role 描述谁可以承担角色的信任策略
Create a file containing the trust policy in JSON format. e.g. trust-policy.json
创建一个包含JSON格式的信任策略的文件。 例如trust-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}Run the command to create the role:
运行命令以创建角色:
aws iam create-role --role-name <role-name> --assume-role-policy-document file://<file-name.json>Note down the Arn value which will be printed in the console
记下将在控制台中打印的Arn值
We need ARN for another policy AWSLambdaExecute which is already defined in the IAM policies. AWSLambdaExecute policy sets the necessary permissions for the Lambda function.
对于另一个已在IAM策略中定义的策略AWSLambdaExecute ,我们需要ARN。 AWSLambdaExecute策略为Lambda函数设置必要的权限。
Run the below command to get the Arn value for a given policy
运行以下命令以获取给定策略的Arn值
aws iam list-policies --query 'Policies[?PolicyName==`emr-full`].Arn' --output text2.3. Attaching the 2 policies to the role created above
2.3。 将2个策略附加到上面创建的角色
aws iam attach-role-policy --role-name S3-Lambda-Emr --policy-arn "arn:aws:iam::aws:policy/AWSLambdaExecute"aws iam attach-role-policy --role-name S3-Lambda-Emr --policy-arn "arn:aws:iam::123456789012:policy/emr-full-policy"Note: Replace the Arn account value with your account number.
注意:用您的帐号替换Arn帐号值。
Make sure to verify the role/policies that we created by going through IAM (Identity and Access Management) in the AWS console.
确保通过在AWS控制台中通过IAM(身份和访问管理)来验证我们创建的角色/策略。
3.创建Lambda函数 (3. Creating the Lambda Function)
We create the below function in the AWS Lambda. After the event is triggered, it goes through the list of EMR clusters and picks the first waiting/running cluster and then submits a spark job as a step function.
我们在AWS Lambda中创建以下函数。 触发事件后,它将遍历EMR群集列表,并选择第一个等待/正在运行的群集,然后将Spark作业作为步进函数提交。
Zip the above python file and run the below command to create the lambda function from AWS CLI.
压缩上述python文件并运行以下命令,以从AWS CLI创建lambda函数。
aws lambda create-function --function-name FileWatcher-Spark \
--zip-file fileb://lambda-function.zip --handler lambda-function.lambda_handler --runtime python3.7 --role arn:aws:iam::123456789012:role/S3-Lambda-EmrReplace the zip file name, handler name(a method that processes your event). In my case, it is lambda-function.lambda_handler (python-file-name.method-name).
替换zip文件名,处理程序名称(处理事件的方法)。 就我而言,它是lambda-function.lambda_handler (python-file-name.method-name)。
Also, replace the Arn value of the role that was created above.
另外,替换上面创建的角色的Arn值。
Once it is created, you can go through the Lambda AWS console to check whether the function got created.
创建函数后,您可以通过Lambda AWS控制台检查该函数是否已创建。
Once we have the function ready, its time to add permission to the function to access the source bucket.
一旦我们准备好函数,就可以为该函数添加权限以访问源存储桶了。
aws lambda add-permission --function-name <FileWatcher-Spark> --principal s3.amazonaws.com \
--statement-id s3invoke --action "lambda:InvokeFunction" \
--source-arn <bucket-arn-value>\
--source-account <123456789012>Replace the source account with your account value. The account can be easily found in the AWS console or through AWS CLI.
用您的帐户值替换源帐户。 您可以在AWS控制台中或通过AWS CLI轻松找到该帐户。
aws sts get-caller-identityNow its time to add a trigger for the s3 bucket.
现在是时候为s3存储桶添加触发器了。
Create another file for the bucket notification configuration.eg. notification.json.
为存储桶通知配置创建另一个文件。 notification.json。
{
"LambdaFunctionConfigurations": [
{
"LambdaFunctionArn": "arn:aws:lambda:us-east-1:065987431742:function:FileWatcher-Spark",
"Events": ["s3:ObjectCreated:Put"],
"Filter": {
"Key": {
"FilterRules": [
{
"Name": "suffix",
"Value": ".csv"
}
]
}
}
}]
}We are using S3ObjectCreated:Put event to trigger the lambda function
我们正在使用S3ObjectCreated:Put事件 触发lambda函数
aws s3api put-bucket-notification-configuration --bucket lambda-emr-exercise --notification-configuration file://notification.jsonVerify that trigger is added to the lambda function in the console
验证触发器已添加到控制台中的lambda函数
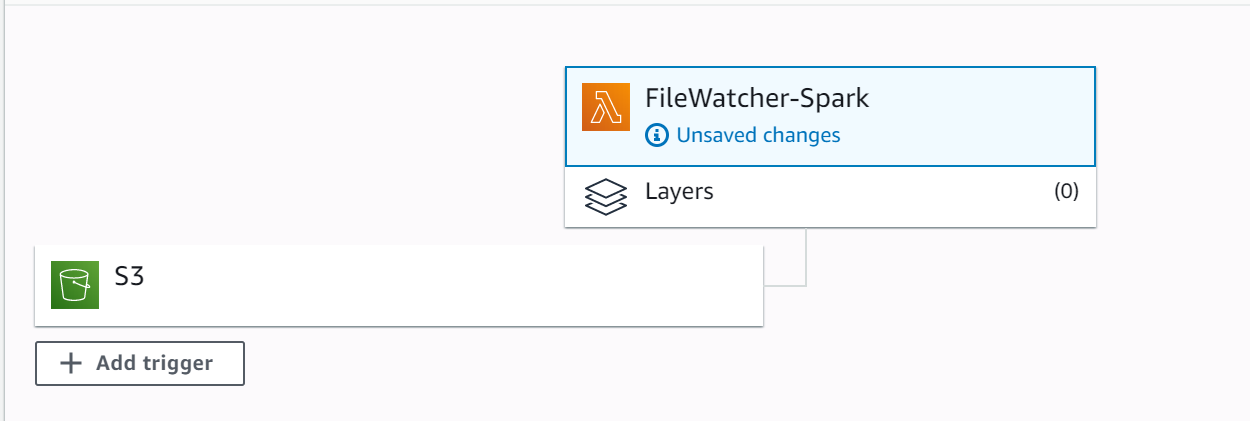
Create a sample word count program in Spark and place the file in the s3 bucket location. Ensure to upload the code in the same folder as provided in the lambda function.
在Spark中创建一个示例单词计数程序,并将文件放在s3存储桶位置。 确保将代码上传到lambda函数提供的文件夹中。
import sysfrom pyspark import SparkContext, SparkConfif __name__ == "__main__":
conf = SparkConf().setAppName("Spark Count")
sc = SparkContext(conf=conf)
input_file = sys.argv[1]
output_file = sys.argv[2]
readTextFile= sc.textFile(input_file).flatMap(lambda line: line.split(" "))wordCount = readTextFile.map(lambda word: (word, 1)).reduceByKey(lambda v1,v2:v1 +v2)wordCount.coalesce(1).saveAsTextFile(output_file)Start an EMR cluster with a version greater than emr-5.30.1.
启动版本高于emr-5.30.1的EMR群集。
Now, its time to trigger the function.
现在,该触发功能了。
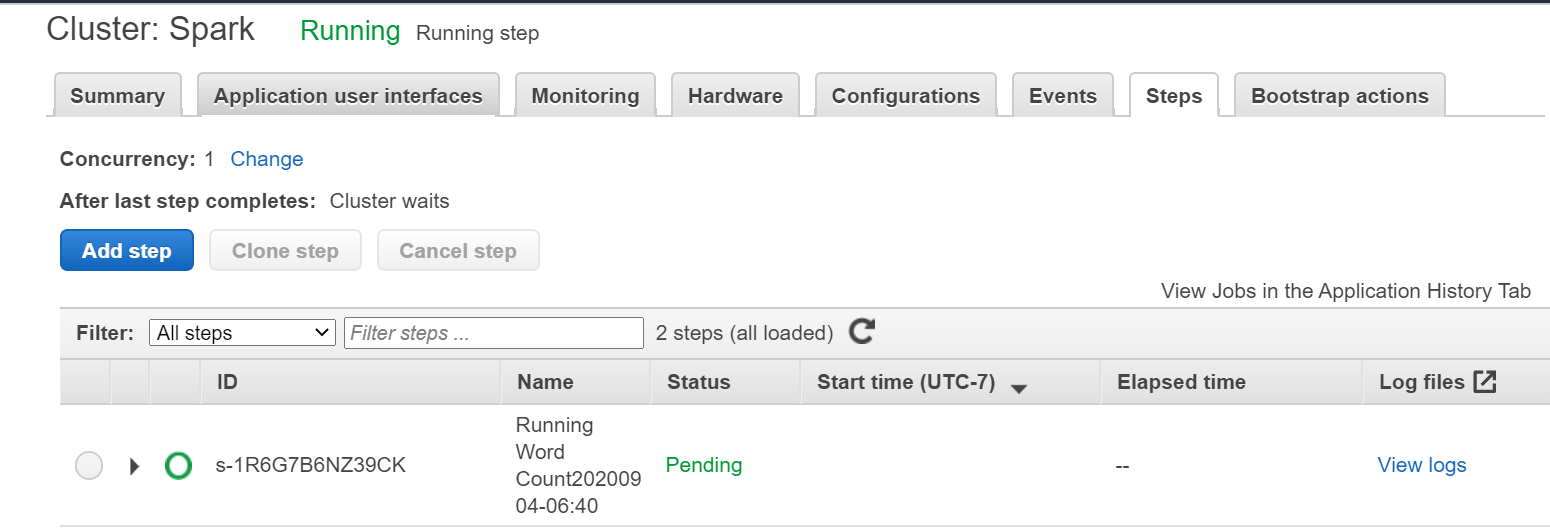
aws s3api put-object --bucket <bucket-name> --key data/test.csv --body test.csvSpark job will be triggered immediately and will be added as a step function within the EMR cluster as below:
Spark作业将立即触发,并将作为步骤功能添加到EMR集群中,如下所示:
摘要 (Summary)
This post has provided an introduction to the AWS Lambda function which is used to trigger Spark Application in the EMR cluster. The above functionality is a subset of many data processing jobs ran across multiple businesses. Data pipeline has become an absolute necessity and a core component for today’s data-driven enterprises. The article covers a data pipeline that can be easily implemented to run processing tasks on any cloud platform. Similar to AWS, GCP provides services like Google Cloud Function and Cloud DataProc that can be used to execute a similar pipeline.
这篇文章介绍了用于触发EMR集群中的Spark Application的AWS Lambda函数。 上述功能是跨多个业务的许多数据处理作业的子集。 数据管道已成为当今数据驱动企业的绝对必要和核心组成部分。 本文介绍了可以轻松实现的数据管道,以在任何云平台上运行处理任务。 与AWS类似,GCP提供了诸如Google Cloud Function和Cloud DataProc之类的服务,可用于执行类似的管道。
That’s all for today.
今天就这些。
Hope you liked the content. Feel free to reach out to me through the comment section or LinkedIn https://www.linkedin.com/in/ankita-kundra-77024899/. Thank you for reading!!
希望您喜欢该内容。 欢迎通过评论部分或LinkedIn https://www.linkedin.com/in/ankita-kundra-77024899/ 与我联系 。 谢谢您的阅读!!
aws集群emr重启















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









