







 本文详细介绍了推荐系统中常用的评价指标,包括HitRate、Precision、Recall和NDCG。HitRate关注推荐内容是否命中用户兴趣,Precision衡量推荐的准确性,Recall关注召回率,而NDCG考虑了评分的排序。这些指标对于线下模型评估和优化至关重要。同时,区分了线上评测与线下评测的不同,并通过实例帮助理解各指标的计算方式。
本文详细介绍了推荐系统中常用的评价指标,包括HitRate、Precision、Recall和NDCG。HitRate关注推荐内容是否命中用户兴趣,Precision衡量推荐的准确性,Recall关注召回率,而NDCG考虑了评分的排序。这些指标对于线下模型评估和优化至关重要。同时,区分了线上评测与线下评测的不同,并通过实例帮助理解各指标的计算方式。
目录
常用的评价标准:
第一类是线上评测,比如通过点击率、网站流量、A/B test等判断。这类评价标准在这里就不细说了,因为它们并不能参与到线下训练模型和选择模型的过程当中。
第二类是线下评测。评测标准很多,我挑几个常用的。我就拿给用户推荐阅读相关链接来举例好了。
Hit Rate(HR)
Hit Rate(HR) 所以到底是哪个????
一说:

https://zhuanlan.zhihu.com/p/67287992
二说
hit rate = 命中数/点击数
https://zhuanlan.zhihu.com/p/42158565/
三说
hit的定义为:看这召回的N个item中是否包含用户后续会点击的item(即hit),如果有则记为1,否则记为0,最后求sum(hit)/总用户数。
四说

TopN推荐
网站在提供推荐服务时,一般是给用户一个个性化的推荐列表,这种推荐叫TopN推荐。TopN推荐的预测准确率一般通过准确率(precision)和召回率(recall)度量。
令R(u)是根据用户在训练集上的行为给用户做出的推荐列表,而T(u)是用户在测试集上的行为列表。
Precision
推荐系统的准确率定义为:
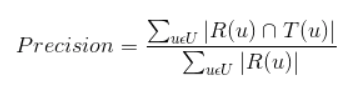
Recall
推荐系统的召回率定义为:
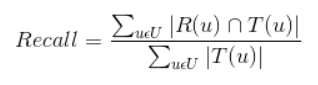
比如有一个训练集为(苹果,香蕉,橘子,草莓,哈密瓜,西红柿,黄瓜),用户选中其中几样,以此训练,
测试集为(梨子,菠萝,龙眼,黑莓,白菜,冬瓜)
根据用户在训练集上的行为:
给用户做出的推荐列表为R(u) =(梨子,菠萝,龙眼),用户在测试集上的实际行为列表T(u) =(梨子,黑莓,白菜,冬瓜)
那么R(u)和T(u)的交集为1,R(u)=3,T(u)=4,故准确率为1/3,召回率为1/4。
总结:
- precision是从已经预测为同一类别的样本抽样。是针对预测结果而言的,表示:预测样本为正的样本中有多少是真正的正样本。
- recall是从dataset的同一类的样本抽样。是针对原来样本而言的,表示:样本中的正例有多少被预测正确。
再举个例子
推荐系统往往只推荐有限个(如k个)物品给某个用户。真正相匹配的物品我们称之为相关物品(也就是二元分类中的阳性)。

k召回(recall at k)=所推荐的k个物品中相关物品的个数所有相关物品的个数k召回(recall at k)=所推荐的k个物品中相关物品的个数所有相关物品的个数。
k精度(precision at k)=所推荐的k个物品中相关物品的个数k精度(precision at k)=所推荐的k个物品中相关物品的个数k。
比如说,根据你的喜好,我们推荐了10个商品,其中真正相关的是5个商品。在所有商品当中,相关的商品一共有20个,那么
k召回 = 5 / 20
k精度 = 5 / 10
NDCG
可能大家接触比较多的是MAP,MAP考虑的是0和1的排序。而NDCG则是考虑到评分的排序。
说到NDCG就需要从CG开始说起。


参考:
希望之后能梳理出哪些是召回部分所用,哪些是排序模型所用。o(* ̄▽ ̄*)ブ

















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









