






 本文详细介绍了如何在NCBI上查找并获取特定物种的基因CDS序列和蛋白序列,以DNA连接酶为例,提供了一步步的操作流程,包括关键词选择、物种确认和序列查找。强调了寻找CDS序列的重要性,并提示可能需要尝试多种关键词来找到正确的序列。
本文详细介绍了如何在NCBI上查找并获取特定物种的基因CDS序列和蛋白序列,以DNA连接酶为例,提供了一步步的操作流程,包括关键词选择、物种确认和序列查找。强调了寻找CDS序列的重要性,并提示可能需要尝试多种关键词来找到正确的序列。
一、 应用场景
需要表达某物种的特定蛋白或基因
二、 序列获取方法:
1. 打开NCBI网站(https://www.ncbi.nlm.nih.gov)
2. 点击下图红色箭头指示的下拉框
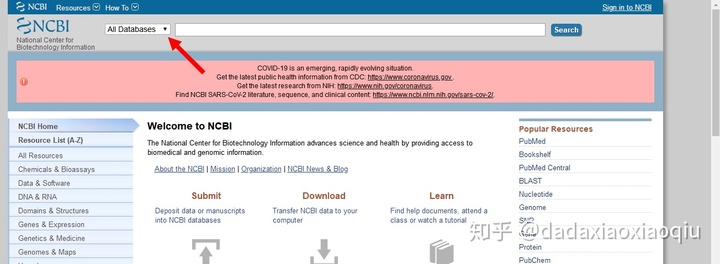
3. 找到下图所示的“Gene”
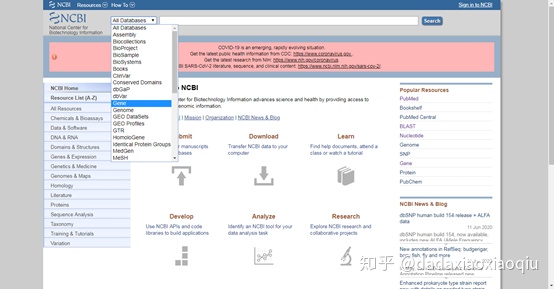
4. 选中“Gene”,在右边的搜索对话框中输入需要查找的基因名称。下图以 “DNA连接酶”为例,在对话框中输入 “DNA Ligase”,再点击最右边的Search。
5. 出现如下页面,找到“Search results”。红线指示的就是物种的名称
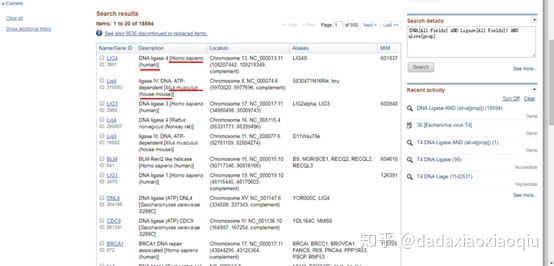
6. 仅仅搜索“DNA Ligase”会出现很多物种的DNA连接酶,我们在准备表达一个蛋白前,需要通过文献、专利或者竞品说明书确定具体物种的特定蛋白。
7. 比如通过前期查找文献、专利等资料确定需表达T4噬菌体来源的DNA ligase,那么可以在搜索框中输入“T4 DNA ligase”,出现如下页面。
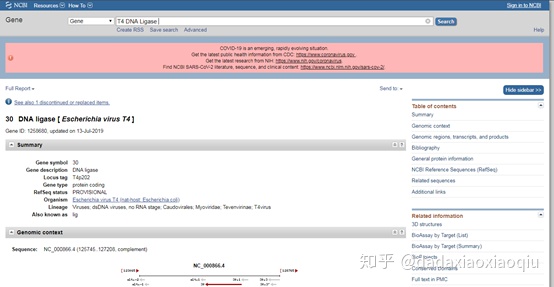
8. 下拉页面,找到下图红线框所示“mRNA and Proteins”,点击下图所示的“See identical proteins and their annotated locations for NP_049813.1”
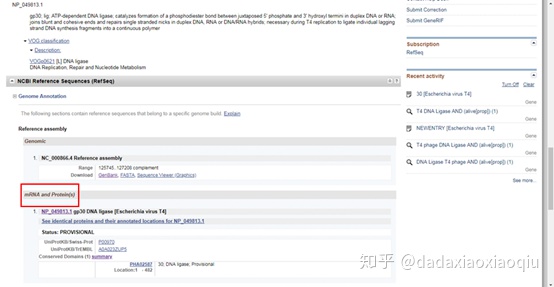
9. 出现下图所示,这是不同的人上传的序列。点击箭头所示的链接
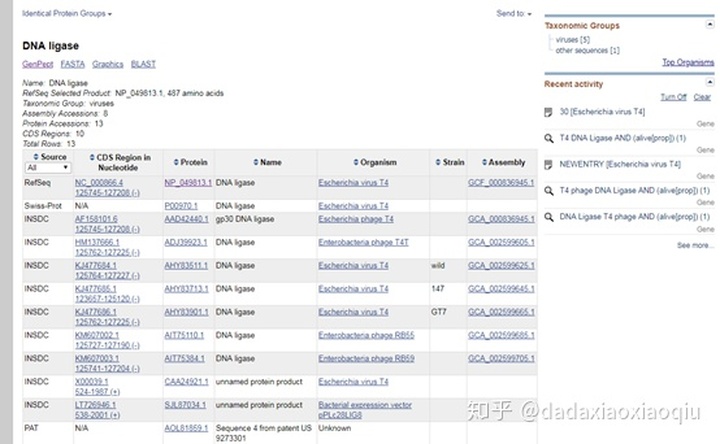
10. 出现下图所示页面,页面中包含该序列出现在那篇文献中,以及对应作者的信息等
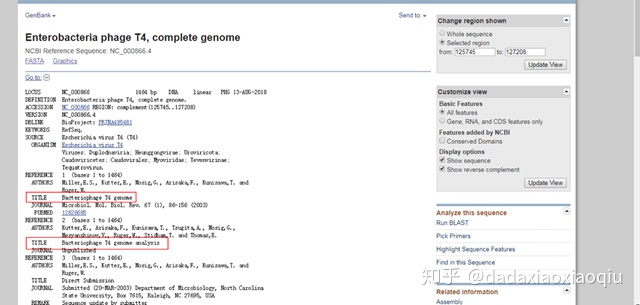
11. 下拉页面,可以找到蛋白序列和对应的CDS序列(使用原核表达系统表达真核生物来源蛋白,一定要找到CDS序列而不是整个基因序列)


注意:
1. 搜索某特定物种的蛋白时,可能需要尝试不同的关键词,才能找到对应的序列。
2. 找到的对应核酸序列必须是CDS区序列,蛋白序列和CDS序列找到其中一种即可。
三、序列合成
确定表达系和具体的表达载体后,将序列发送给基因合成公司进行密码子优化和序列合成。可要求基因合成公司将目的序列直接放在表达载体的特定位点,无需再进行克隆改造。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









