






论文地址
https://arxiv.org/abs/1910.02490v3
论文总结和摘要:
Kimera是一个开源的C++实时语义SLAM系统,提供了:
视觉惯性状态估计(VIO模块)
全局一致的相机轨迹估计(姿态图优化器 PGO)
用于快速避障的低延时的局部网格地图(轻量级的3D网格重建模块)
全局语义标注的3D网格地图(稠密的3D语义重建模块)
kimera使用相机图像和惯导数据来构建语义注释的3D环境网格.
和现有的视觉-惯导SLAM库(例如ORB-SLAM、VINS-Mono、OKVIS、ROVIO)比较,Kimera是模块化结构,支持ROS,在CPU上运行.
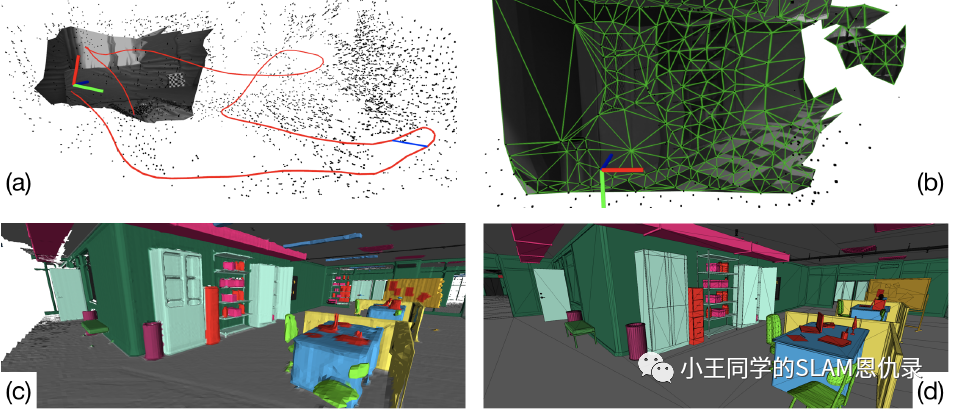
如上图所示
- 图(a) 以IMU帧率进行视觉惯导状态估计以及全局一致且对出格点鲁棒的轨迹估计.
- 图(b) 可用于快速避障的低时延局部场景3D网格.
- 图(c) 全局语义注释的3D网格.
- 图(d) 地面真实模型.
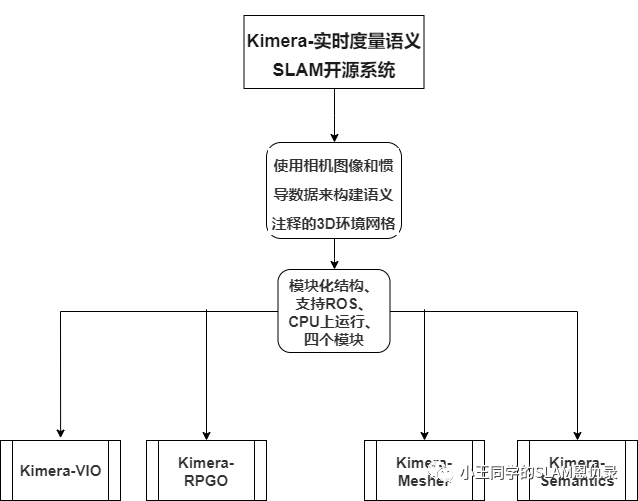
如上便是我制作的简易系统框架图,更丰富一点的流程图就不放出来了,个人学习使用. 作者使用模块化的思想来设计的SLAM系统,因此Kimera可单独分解为VIO系统或者完整的SLAM系统.
系统模块介绍
Kimera-VIO模块
什么是VIO?,VIO也就是Visual-Inertial Odometry,中文翻译成:视觉惯性里程计.
VIO使用论文:
《On-manifold preintegration theory for fast and accurate visual-inertial navigation》
中的方法,并扩展到了单目和双目图像数据上!
在这个模块中,包含了两个线程Kimera-VIO front end、Kimera-VIO back end.也就是前端线程和后端线程.
VIO前端:负责处理原始的传感器数据
IMU前端:执行流形预积分,从原始IMU数据中获得两个连续关键帧之间相对状态的紧凑预积分测量.
Vision前端:检测Shi-Tomasi角点,使用Lukas-Kanade tracker进行帧间搜索,对双目数据进行匹配,然后几何验证.其中用5点RANSAC进行单目验证和3点RANSAC进行立体视觉验证, 需要注意的是这里检测角点与双目匹配以及几何验证都是在关键帧上运行,在中间帧只进行特征追踪.
VIO后端:负责融合经过处理的各种测量量,生成传感器的状态预测(位姿、速度、偏移等)
在每一关键帧,IMU数据和视觉数据会被整合到一个固定滞后的平滑器中,该平滑器是一个"factor graph",使用GTSAM中的iSAM2即可得到.这里引用了很多论文的方法,最后得到了观测特征的3D坐标,去除了视差不足或离群的点,并使用GTSAM将超出平滑范围的状态边缘化.
总的来说,VIO前端负责获取双目图像数据和IMU数据,输出特征的跟踪结果和IMU预积分结果,此外还输出IMU-rate的状态估计结果.而VIO后端就是用来输出优化后的状态估计.
Kimera-RPGO模块
什么是RPGO呢? RPGO也就是Robust Pose Graph Optimization.中文翻译成:鲁棒姿势图优化.
这个模块负责检测闭环、计算关键帧位姿.
闭环检测: 基于DBoW2,并使用词袋模型快速检测闭环.对每一个可能的闭环进行单目和双目验证, 剔除一些离群闭环,将剩余的闭环交由PGO solver解决.
鲁棒的PGO:该模块在GTSAM[1]中实现,并使用增量一致测量集最大化方法[2]来剔除异常值.
[1]: 《Factor graphs and GTSAM: A hands-on introduction》
[2]: Incremental Consistent Measurement Set Maximization,PCM,《Pairwise consistent measurement set maximization for robust multi-robot map merging》
在实际中,存储着里程数边缘(由Kimera-VIO产生)和闭环(由闭环检测产生);每次执行PGO时,首先使用修改后的PCM选择最大的一组一致闭环,然后在姿势图上执行GTSAM,包括里程计和一致的循环闭合.
总的来说,这个模块作用是检测闭环,剔除外点,估计全局连续的估计.
Kimera-Mesher模块
该模块可以快速生成两种3D网络:单帧网络、多帧网络.
- 单帧网格:首先通过当前关键帧成功跟踪的2D特征(由VIO前端生成)做2D Delaunay三角剖分.然后用来自VIO后端的3D点估计对2D Delaunay三角剖分进行反投影以生成3D网格.虽然单帧网格只提供低延迟障碍物检测,但通过2D标签对网格进行纹理化提供了来对生成网格进行语义标记的选项.
- 多帧网格:多帧网格将在VIO往后时间段(receding horizon)收集的每帧网格融合到单个网格中,并使规则化平面(planar surfaces).单帧3D网格和多帧3D网格都被编码为顶点位置列表以及顶点ID三元组(triplets)列表来描述三角面.假设在时间t − 1处已经有一个多帧网格,对于生成的每个新单帧3D网格(在时间t),遍历其顶点和三元组,并在每个顶点添加单帧网格中存在在多帧网格中丢失的顶点和三元组。然后,遍历多帧网格的顶点并根据最新的VIO后端估计更新其3D位置。最后,删除VIO时间范围之外旧特征相对应的顶点和三元组。结果是最新的跨当前VIO时间范围内所有关键帧的3D网格。如果在网格中检测到平面,则在VIO后端添加规则性因子,这带来VIO和网格规则化的紧耦合关系. Delaunay三角测量” 见论文
《Incremental visual-inertial 3D mesh generation with structural regularities》
Kimera-Semantics模块
采用了[1]中介绍的捆绑式光线投射(bundled raycasting)技术,实现了建立精确的全局三维网格(覆盖整个轨迹)以及语义标注网络.
- 全局mesh:
首先使用dense stereo方法[2]从双目数据中得到三维点云. 然后在每一关键帧上使用bundled raycasting方法得到TSFD,从中使用marching cube算法提取mesh
- 语义标注:
使用现成的像素级二维语义分割工具(深度神经网络,或经典的条件随机场方法),可以得到二维语义标签,然后将标签附加到dense stereo图生成的每个三维点上.
在光线投射(bundled raycasting)时还投射了语义标签,对于光线投射中的每束光线,根据束中观察到的标签的频率建立一个标签概率向量.然后,仅在TSDF截断距离(即接近表面)内传播该信息,以节省计算时间,最后使用贝叶斯更新更新每个体素的标签概率.在这个语义光线投射之后,每个体素都有一个标签概率向量,从中选择概率最大的标签。最后利用marching cubes算法提取语义mesh,该mesh比Kimera-mesher生成的多帧mesh更加精确,但速度更慢(>1.0s).
[1]:《“Voxblox: Incremental 3d euclidean signed distance fields for on-board mav planning》中介绍的捆绑式光线投射(bundled raycasting)技术
[2]:《Stereo processing by semiglobal matching andmutual information》
总的来说,这个模块使用volumetric(体积)的方法,创建一个慢但是精确的全局3D网格,并且使用2D像素级语义分割来语义标注3D网格.
评估工具
Kimera提供了一套开源的评估工具,用于VIO、SLAM和度量语义重建的调试、可视化和基准测试.此外,还提供了Jupyter notebook用于可视化中间VIO统计数据(例如特征轨迹的质量、IMU预集成错误)以及使用Open3D自动评估3D重建的质量.
一些实验
作者用一些对比实验来说明kimera模块的优点,这里不作介绍了,有兴趣可以看看论文.
参考:
- https://blog.csdn.net/weixin_38636815
- https://zhuanlan.zhihu.com/p/104011242















 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









