







 本文介绍了强化学习的基本概念,包括Agent-Environment框架、价值函数等。详细讲述了如何通过策略评估和优化来确定状态价值函数,以及使用蒙特卡洛策略评估、TD策略评估等方法。
本文介绍了强化学习的基本概念,包括Agent-Environment框架、价值函数等。详细讲述了如何通过策略评估和优化来确定状态价值函数,以及使用蒙特卡洛策略评估、TD策略评估等方法。
本文章收录在黑鲸智能系统知识库-黑鲸智能系统知识库成立于2021年,致力于建立一个完整的智能系统知识库体系。我们的工作:收集和整理世界范围内的学习资源,系统地建立一个内容全面、结构合理的知识库。
作者博客:途中的树
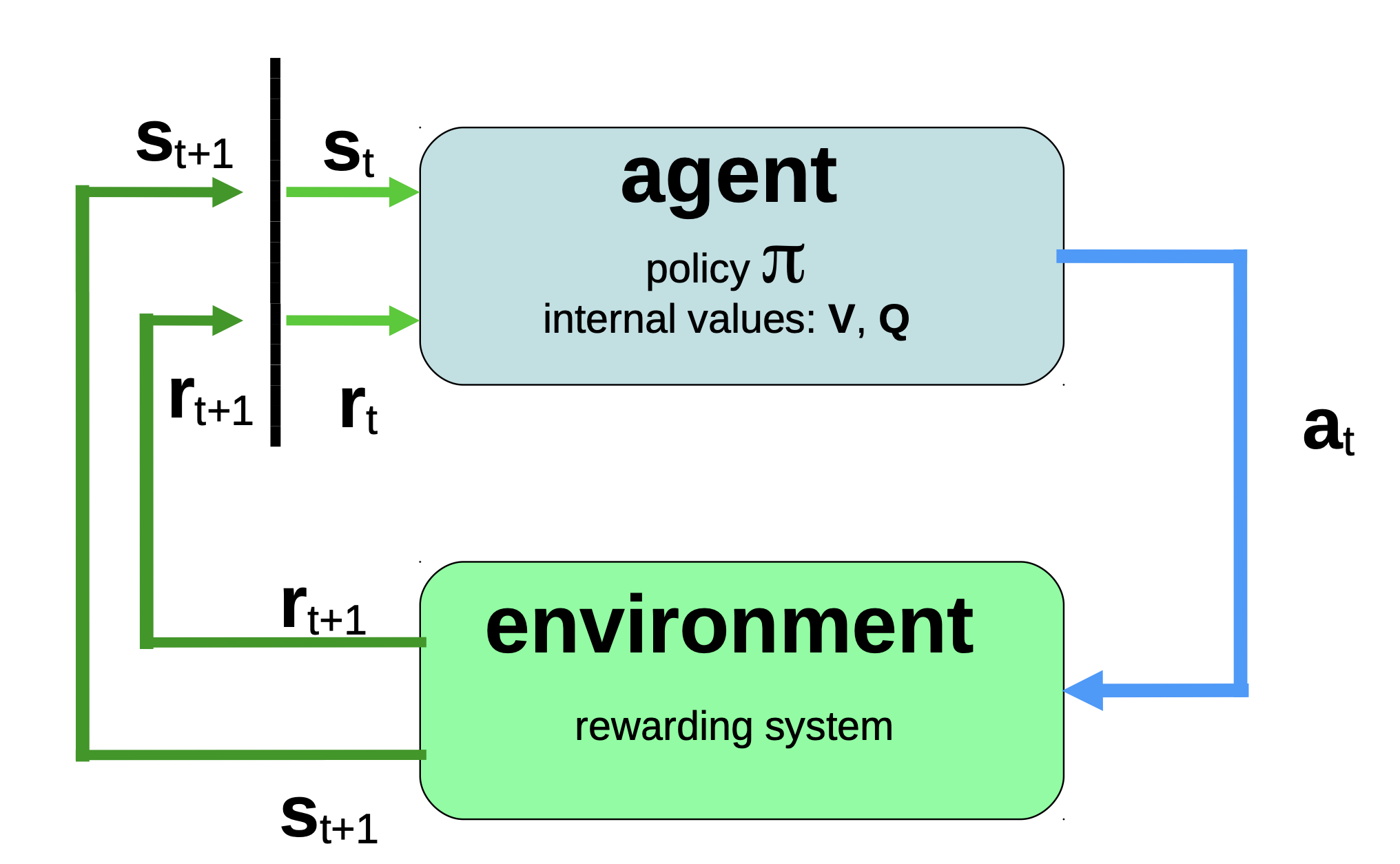
确定状态值
- 强化学习系统的一个子任务是
- 尽可能多地了解环境和它的奖励行为,以便更好地塑造代理的策略 π \pi π
- 使用行为策略使Agent与环境互动,Agent将获得奖励,并能了解环境的一些情况,根绝这些信息就可以确定某个状态的价值
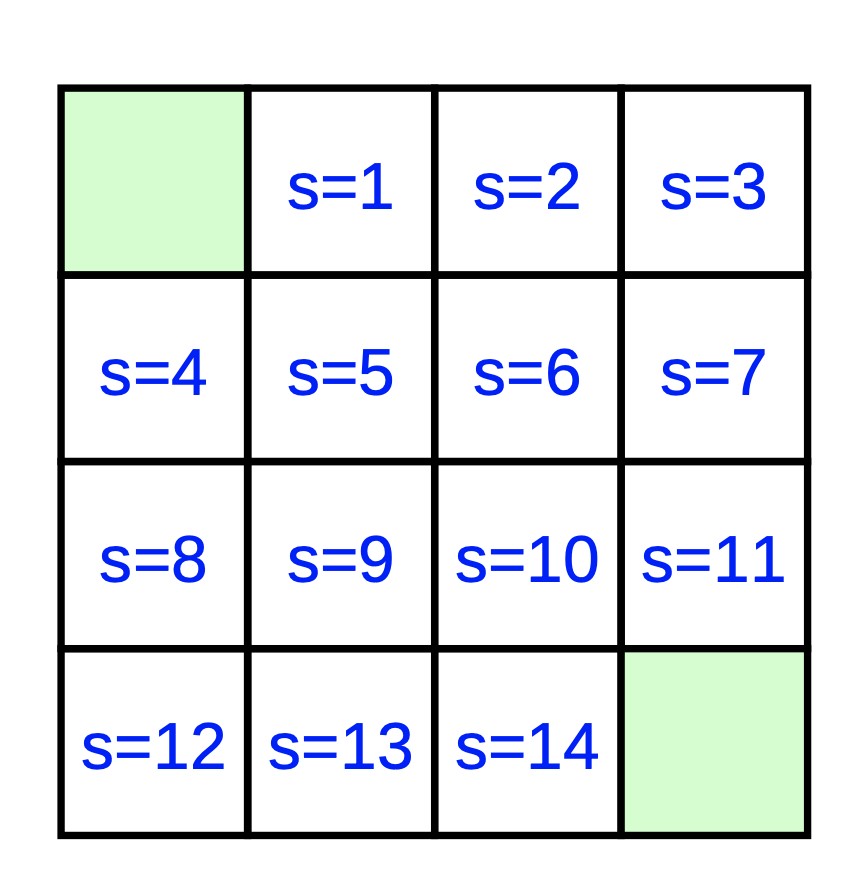
以网格环境为例
Example taken from Book, Sutton, Barto; Reinforcement Learning
-
假设一个网格地图
- 4 x 4离散空间位置
- 绿色角落是目标位置
- Agent的任务
- 找到到达两个目标位置之一的方法
- 状态 s t s_t st:Agent的位置
- 行动 a t a_t at: 上 下 左 右
- 奖励: ‘ r t = − 1 ‘ `r_t = -1` ‘rt=−1‘
- 完全负奖励
- 奖励无则损: γ = 1 \gamma=1 γ=1
-
任务:确认状态价值函数
- V ( s ) = ? V(s)=? V(s)=?
-
由于可用的状态s是离散的有限的(14个位置),状态值函数V(s)可以很容易的列举出来
- V ( s = 1 ) , V ( 2 ) , V ( 3 ) . . . V ( 14 ) V(s=1),V(2),V(3)...V(14) V(s=1),V(2),V(3)...V(14)
如何选择行为策略?
- 行为策略 π b \pi_b πb应该能够引导Agent通过环境达最终位置
- 该政策应该有明确的探索性exploration特征
- 即使没有一个价值函数 ( V ( s ) , Q ( s , a ) ) (V(s),Q(s,a)) (V(s),Q(s,a))是提前已知的,这个策略也应该可用
- 最理想的情况是,行为策略产生的行动序列能够使产生的价值函数 V ( s ) V(s) V(s)接近于最佳价值函数 V ∗ ( s ) V*(s) V∗(s)
策略评估
为了找到上例中提到的行为策略,我们需要进行策略评估
- 策略评估是遵循一个给定的行为策略 π b \pi_b πb确定价值函数的任务
- 策略评价是通过测量获得的奖励来评价使用特定策略的效果
- 策略评估的输出是一个价值函数 ( V ( s ) ) (V(s)) (V(s))的值
策略评估公式
- 使用策略 π \pi π估计/计算一个价值函数被称为政策评估(或预测问题)
- 参考强化学习(二):价值函数 已知价值函数为:
- V π ( s ) = ∑ a π ( s , a ) ∑ s ′ P s , s ′ a ( R s , s ′ a + γ V π ( s ′ ) ) V^{\pi}(s) = \sum_a \pi(s,a) \sum_{s'} P^a_{s,s'} (R^a_{s,s'} + \gamma V^{\pi}(s')) Vπ(s)=∑aπ(s,a)∑s′Ps,s′a(Rs,s′a+γVπ(s′))
- π ( s , a ) \pi(s,a) π(s,a)是在状态 s s s下执行行动 a a a的概率
- P s s ′ a P^a_{ss'} Pss′a是执行 a a a后从 s s s到 s ′ s' s′的转换概率
- R s s ′ a R^a_{ss'} Rss′a是执行 a a a后从 s s s到 s ′ s' s′的预期回报
- 线性环境
- 如果行为和属性是有限的已知的,则策略评估的方程就是一个 # S \#S #S线性方程系统,其中# S S S指的是未知的状态集合,我们需要找到位置的状态以及他们的价值函数
迭代策略评估
-
迭代策略评估是计算#S方程的方法之一
-
在迭代策略评估中,会产生一连串的递归定义的的值 V k ( s ) V_k(s) Vk(s)
- 即 l i m k → ∞ V k ( s ) = V π ( s ) lim_{k\rightarrow\infty}V_k(s)=V^{\pi}(s) limk→∞Vk(s)=Vπ(s)
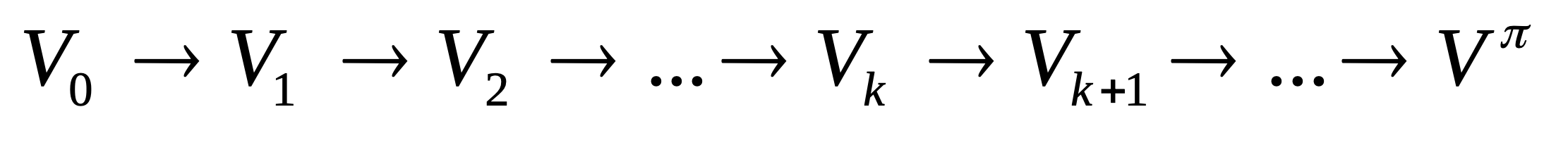
- 当然所有的价值函数 V V V都依赖于由策略 π b \pi_b πb选出的状态 s s s
- V 0 π ( s ) → V 1 π ( s ) → V 2 π ( s ) → . . . V k π ( s ) → V k + 1 π ( s ) → . . . V π ( s ) V^π_{0}(s)→ V^π_{1}(s)→ V^π_2(s)→ ... V^π_{k}(s)→V^π_{k+1}(s)→ ...V^π(s) V0π(s)→V1π(s)→V2π(s)→...Vkπ(s)→Vk+1π(s)→...Vπ(s)
- 从k到k+1的步骤需要进行 “Sweep”
- 对于所有状态s,对于从t到T的完整序列有:
- V π ( s ) ← ∑ a π ( s , a ) ∑ s ′ P s , s ′ a ( R s , s ′ a + γ V π ( s ′ ) ) V^{\pi}(s) \leftarrow \sum_a \pi(s,a) \sum_{s'} P^a_{s,s'} (R^a_{s,s'} + \gamma V^{\pi}(s')) Vπ(s)←∑aπ(s,a)∑s′Ps,s′a(Rs,s′a+γVπ(s′))
- 对于所有状态s,对于从t到T的完整序列有:
-
-
总结一下策略评估算法:
Taken from Book, Sutton, Barto; Reinforcement Learning, Chapter 4.
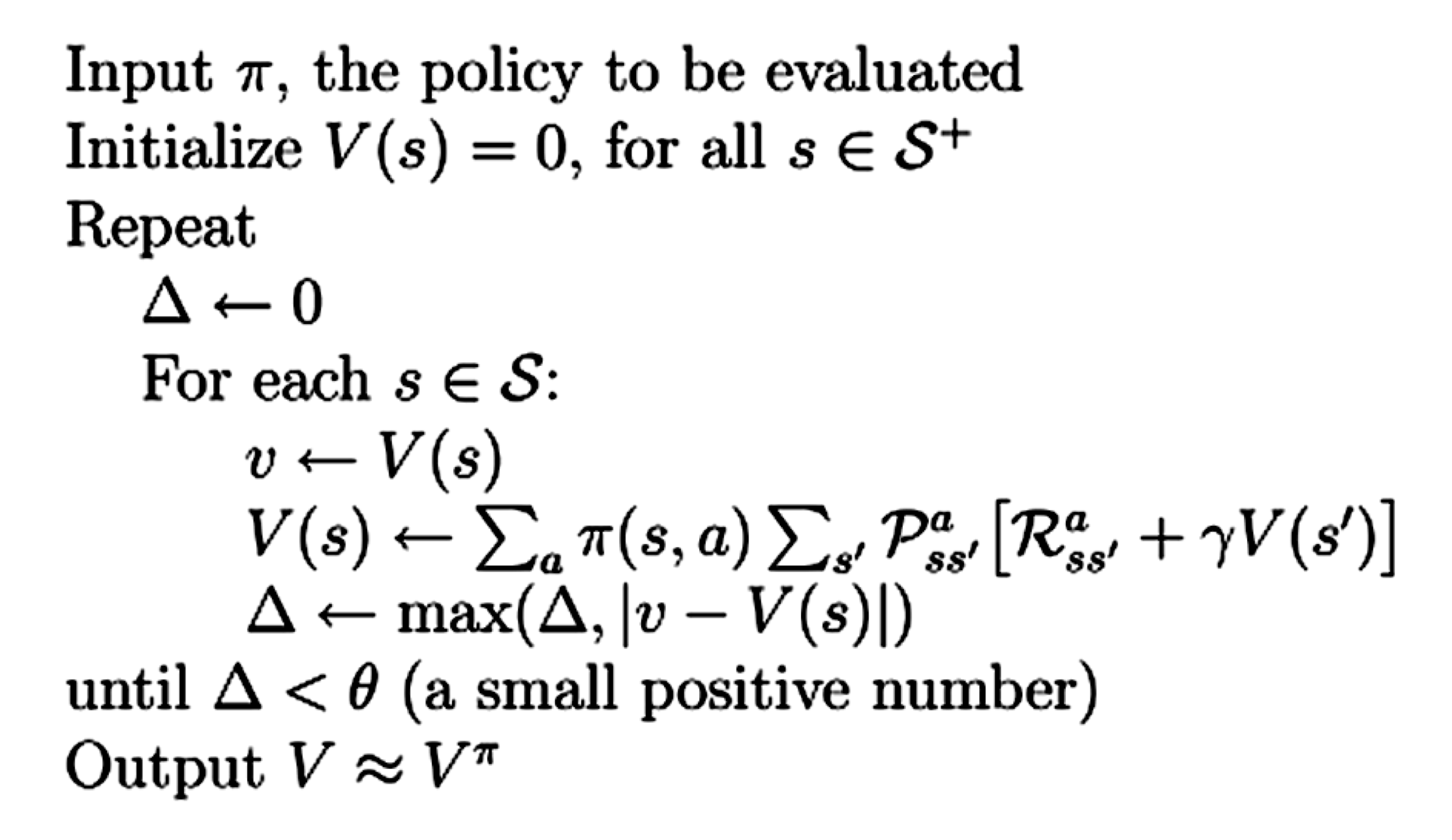
-
应用到上面提到的例子可得
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1476
1476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









