



小米
之前我们写了 京东 和 华为OD,不少同学在后台点名要看小米的职级和薪资。
没问题,在了解小米的薪资分布前,我们要先对小米职级有个初步概念。
小米职级从 13 到 22,共 10 级。
title 大致分为 专员(13~15级)、专家|经理|主管(16~18级)、总监(19~20级)、VP|CXO(21~22级) 几个大类。
看着挺老气的,和其他互联网大厂的各种序列不同,但据悉这还是小米近几年新搞出来的,此前都是高级工程师,技术专家等等,而且当时的职级水分很大。
现在进去的应届生基本都是 13 级,3 年经验如果特别优秀的话可以到 15 级。
哦对了,吉祥物雷军没有职级。
对小米的职级有了基本概念后,再来一览薪资分布:
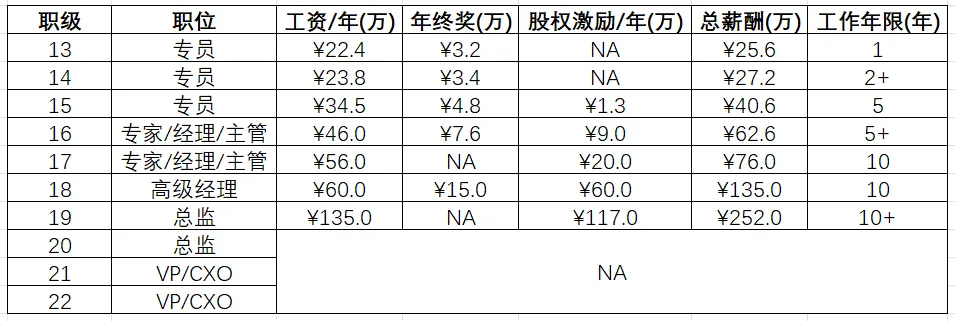
众所周知,小米在港股上市。往常是从 16 级(专家|经理|主管)及以上之后才有股权激励,现在优秀的 15 级(专员)也开始有股权激励了,如果后面小米发展成"全员持股"那竞争力会进一步加强。
今年上半年,在小米 SU7 战略性亏钱的大前提下,小米仍然实现了 17.27% 的净利增长,同时雷军在近期的小米应届生迎新典礼中宣布,今年还会新招 5000+ 的应届生。
一家「有待遇,有未来,有 HC」的国民公司,你会考虑加入吗?欢迎评论区交流。
...
回归主题。
来一道经典 DP 算法题。
题目描述
平台:LeetCode
题号:10
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
-
'.'匹配任意单个字符 -
'*'匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖整个字符串 s 的,而不是部分字符串。
示例 1:
输入:s = "aa" p = "a"
输出:false
解释:"a" 无法匹配 "aa" 整个字符串。
示例 2:
输入:s = "aa" p = "a*"
输出:true
解释:因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
示例 3:
输入:s = "ab" p = ".*"
输出:true
解释:".*" 表示可匹配零个或多个('*')任意字符('.')。
示例 4:
输入:s = "aab" p = "c*a*b"
输出:true
解释:因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。
示例 5:
输入:s = "mississippi" p = "mis*is*p*."
输出:false
提示:
-
-
-
s可能为空,且只包含从a-z的小写字母。 -
p可能为空,且只包含从a-z的小写字母,以及字符.和*。 -
保证每次出现字符 *时,前面都匹配到有效的字符
动态规划
整理一下题意,对于字符串 p 而言,有三种字符:
-
普通字符:需要和 s中同一位置的字符完全匹配 -
'.':能够匹配s中同一位置的任意字符 -
'*':不能够单独使用'*',必须和前一个字符同时搭配使用,数据保证了'*'能够找到前面一个字符。能够匹配s中同一位置字符任意次。
所以本题关键是分析当出现 a* 这种字符时,是匹配
个 a、还是
个 a、还是
个 a ...
本题可以使用动态规划进行求解:
-
状态定义:
f(i,j)代表考虑s中以i为结尾的子串和p中的j为结尾的子串是否匹配。最终我们要求的结果为f[n][m]。 -
状态转移:也就是我们要考虑
f(i,j)如何求得,前面说到了p有三种字符,所以这里的状态转移也要分三种情况讨论:-
p[j]为普通字符:匹配的条件是前面的字符匹配,同时s中的第i个字符和p中的第j位相同。 即f(i,j) = f(i-1, j-1) && s[i] == p[j]。 -
p[j]为'.':匹配的条件是前面的字符匹配,s中的第i个字符可以是任意字符。即f(i,j) = f(i-1, j-1) && p[j] == '.'。 -
p[j]为'*':读得p[j-1]的字符,例如为字符a。 然后根据a*实际匹配s中a的个数是 个、 个、 个 ...-
当匹配为 个: f(i,j) = f(i,j-2) -
当匹配为 个: f(i,j) = f(i-1,j-2) && (s[i] == p[j-1] || p[j-1] == '.') -
当匹配为 个: f(i,j) = f(i-2, j-2) && ((s[i] == p[j-1] && s[i-1] == p[j-1]) || p[j] == '.')
-
-
「我们知道,通过「枚举」来确定 * 到底匹配多少个 a 这样的做法,算法复杂度是很高的。」
「我们需要挖掘一些「性质」来简化这个过程。」

Java 代码:
class Solution {
public boolean isMatch(String ss, String pp) {
// 技巧:往原字符头部插入空格,这样得到 char 数组是从 1 开始,而且可以使得 f[0][0] = true,可以将 true 这个结果滚动下去
int n = ss.length(), m = pp.length();
ss = " " + ss; pp = " " + pp;
char[] s = ss.toCharArray(), p = pp.toCharArray();
// f(i,j) 代表考虑 s 中的 1~i 字符和 p 中的 1~j 字符 是否匹配
boolean[][] f = new boolean[n + 1][m + 1];
f[0][0] = true;
for (int i = 0; i <= n; i++) {
for (int j = 1; j <= m; j++) {
// 如果下一个字符是 '*',则代表当前字符不能被单独使用,跳过
if (j + 1 <= m && p[j + 1] == '*' && p[j] != '*') continue;
// 对应了 p[j] 为普通字符和 '.' 的两种情况
if (i - 1 >= 0 && p[j] != '*') {
f[i][j] = f[i - 1][j - 1] && (s[i] == p[j] || p[j] == '.');
}
// 对应了 p[j] 为 '*' 的情况
else if (p[j] == '*') {
f[i][j] = (j - 2 >= 0 && f[i][j - 2]) || (i - 1 >= 0 && f[i - 1][j] && (s[i] == p[j - 1] || p[j - 1] == '.'));
}
}
}
return f[n][m];
}
}
C++ 代码:
class Solution {
public:
bool isMatch(string s, string p) {
int n = s.length(), m = p.length();
s = " " + s; p = " " + p;
vector<vector<bool>> f(n + 1, vector<bool>(m + 1, false));
f[0][0] = true;
for (int i = 0; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (j + 1 <= m && p[j + 1] == '*' && p[j] != '*') continue;
if (i - 1 >= 0 && p[j] != '*') {
f[i][j] = f[i - 1][j - 1] && (s[i] == p[j] || p[j] == '.');
} else if (p[j] == '*') {
f[i][j] = (j - 2 >= 0 && f[i][j - 2]) || (i - 1 >= 0 && f[i - 1][j] && (s[i] == p[j - 1] || p[j - 1] == '.'));
}
}
}
return f[n][m];
}
};
Python 代码:
class Solution:
def isMatch(self, s: str, p: str) -> bool:
n, m = len(s), len(p)
s, p = " " + s, " " + p
f = [[False] * (m + 1) for _ in range(n + 1)]
f[0][0] = True
for i in range(n + 1):
for j in range(1, m + 1):
if j + 1 <= m and p[j + 1] == '*' and p[j] != '*':
continue
if i - 1 >= 0 and p[j] != '*':
f[i][j] = f[i - 1][j - 1] and (s[i] == p[j] or p[j] == '.')
elif p[j] == '*':
f[i][j] = (j - 2 >= 0 and f[i][j - 2]) or (i - 1 >= 0 and f[i - 1][j] and (s[i] == p[j - 1] or p[j - 1] == '.'))
return f[n][m]
TypeScript 代码:
function isMatch(s: string, p: string): boolean {
let n: number = s.length, m: number = p.length
s = " " + s; p = " " + p;
let f: boolean[][] = new Array(n + 1).fill(false).map(() => new Array(m + 1).fill(false));
f[0][0] = true;
for (let i: number = 0; i <= n; i++) {
for (let j: number = 1; j <= m; j++) {
if (j + 1 <= m && p.charAt(j + 1) === '*' && p.charAt(j) !== '*') continue;
if (i - 1 >= 0 && p.charAt(j) !== '*') {
f[i][j] = f[i - 1][j - 1] && (s.charAt(i) === p.charAt(j) || p.charAt(j) === '.');
} else if (p.charAt(j) === '*') {
f[i][j] = (j - 2 >= 0 && f[i][j - 2]) || (i - 1 >= 0 && f[i - 1][j] && (s.charAt(i) === p.charAt(j - 1) || p.charAt(j - 1) === '.'));
}
}
}
return f[n][m];
};
-
时间复杂度: 表示 s的长度, 表示p的长度,总共 个状态。复杂度为 -
空间复杂度:使用了二维数组记录结果。复杂度为
最后
巨划算的 LeetCode 会员优惠通道目前仍可用 ~
使用福利优惠通道 leetcode.cn/premium/?promoChannel=acoier,年度会员 有效期额外增加两个月,季度会员 有效期额外增加两周,更有超大额专属 🧧 和实物 🎁 福利每月发放。
我是宫水三叶,每天都会分享算法知识,并和大家聊聊近期的所见所闻。
欢迎关注,明天见。
更多更全更热门的「笔试/面试」相关资料可访问排版精美的 合集新基地 🎉🎉

















 2656
2656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









