








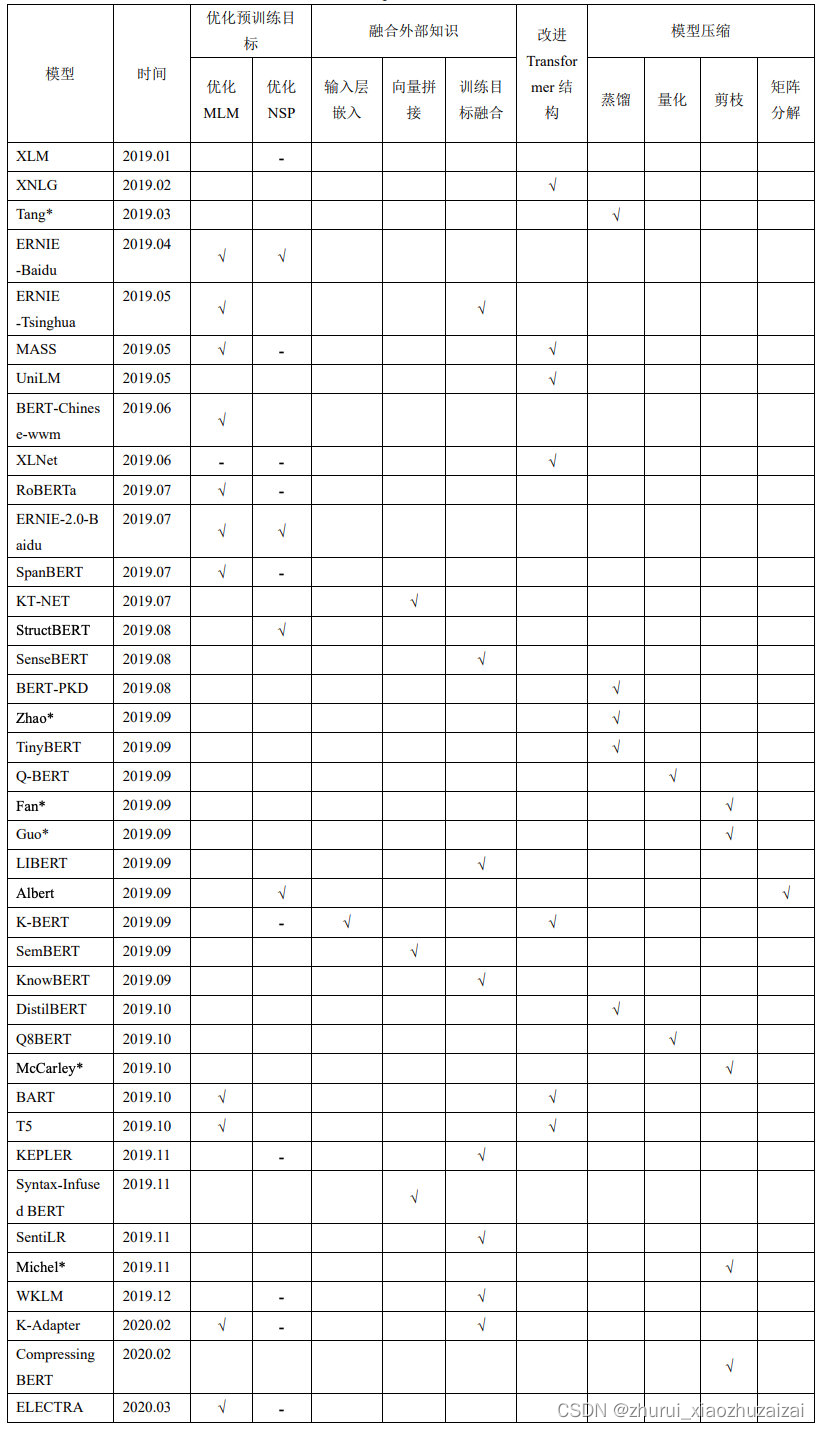
别人整理的比较全的综述:
NLP预训练模型1 – 综述
NLP预训练模型2 – BERT详解和源码分析
NLP预训练模型3 – 预训练任务优化(ERNIE、SpanBERT)
NLP预训练模型4 – 训练方法优化(RoBERTa、T5)
NLP预训练模型5 – 模型结构优化(XLNet、ALBERT、ELECTRA)
NLP预训练模型6 – 模型轻量化(ALBERT、Q8BERT、DistillBERT、TinyBERT等)
Transformer家族1 – Transformer详解和源码分析
模型训练优化
RoBERTa
论文:A Robustly Optimized BERT Pretraining Approach.
在更长的句子上训练,动态更改mask的模式。
LUKE
LUKE(Language Understanding with Knowledge-based Embeddings)
实体感知的自我注意机制,它是对transformer原有的注意机制的有效扩展,该机制在计算注意力分数时考虑到了标记(单词或实体)的类型。
LUKE是以Roberta作为基础的预训练模型,并通过同时优化MLM的目标和我们提出的任务进行模型的预训练。并在5个流行的数据集上获得了最先进的结果
学习笔记
Deberta
论文题目:DeBERTa: Decoding-enhanced BERT with Disentangled Attention[1]
代码地址:https://github.com/microsoft/DeBERTa
(1)注意力解耦机制(disentangled attention mechanism)。每个word的 embedding 由 content embedding 和position embedding 组成。但不是BERT中直接将 content embedding 和 position embedding 向量相加。 word之间的注意力权重用word的content和相对位置的解耦矩阵表示。
内容-内容(content-to-content)内容-位置(content-to-position)位置-内容(position-to-content)位置-位置(position-to-position)
由于token之间注意力权重与token本身的内容和token之间的相对位置有关,那么建模过程内容-位置和位置-内容这两项都不能丢掉。另外,由于使用的是相对位置编码,位置-位置这一项并不能提供更多额外的信息,所以实现过程将这一项丢掉。

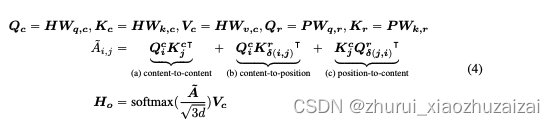
(2)用增强掩码解码器替换原始输出的 softmax层,以预测模型预训练时候被 mask 掉的token。如此解决BERT的预训练和微调阶段的不一致问题。

DeBERTa的encoder由11层 Transformer组成,decoder由2层参数共享的Transformer和一个Softmax输出层组成。因此,DeBERTa与BERT-base的参数量近似。在对DeBERTa模型进行预训练后,对11层encoder和1层decoder进行叠加,以恢复出标准的BERT-base结构进行微调。
1.DeBERTa V1 相比 BERT 和 RoBERTa 模型的改进:
两种技术改进:
注意力解耦机制
增强的掩码解码器
新的微调方法:虚拟对抗训练方法(SiFT)。2.DeBERTa V2 改进
tokenizer扩的更大(优化效果最明显)
transformer外使用了额外的卷积层
共享位置和内容的变换矩阵
应用桶方法对相对位置进行编码3.DeBERTa V3 改进
在模型层面并没有修改,将预训练任务MLM换成了ELECTRA一样类似GAN的RTD任务
参考资料: DeBERTa (v1, v2, v3)
WoBERT
token->word
NEZHA
绝对位置->相对位置
Roformer
token->word; 绝对位置->相对位置
roformer v2优化:去掉所有bias
layer norm -> RMSnorm, 去掉gamma参数
残差 new
蒸馏
ELECTRA
论文:Efficiently Learning an Encoder that Classifies Token Replacements Accurately.
提出了新的预训练任务和框架,把生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务,判断当前token是否被语言模型替换过。使用一个MLM的G-BERT来对输入句子进行更改,然后给D-BERT去判断哪个字被改过,如下:

生成器的训练目标还是MLM(作者在后文也验证了这种方法更好),判别器的目标是序列标注(判断每个token是真是假),两者同时训练,但判别器的梯度不会传给生成器。
ALBERT
论文:A Lite BERT For Self-Supervised Learning Of Language
Representations.
试图解决大部分预训练模型训练成本高,参数量巨大的问题。ALBERT为了减少模型参数主要有以下几点:
词嵌入参数因式分解;
隐藏层间参数共享
作者认为,词向量只是记忆了相对少量的词语的信息,更多的语义和句法等信息是由隐层记忆的,因此,他们认为,词嵌入的维度可以不必与隐藏层的维度一致,可以通过降低词嵌入的维度的方式来减少参数量。全连接层、注意力层的参数均是共享的,也就是ALBERT依然有多层的深度连接,但是各层之间的参数是一样的此外,为了提升模型性能,ALBERT提出了一种新的训练任务:句子间顺序预测,是给模型两个句子,让模型去预测两个句子的前后顺序。
https://mp.weixin.qq.com/s/um9jnDLGt5JejmVyeOSukw
虽然BERT模型本身是很有效的,但这种有效性依赖于大量的模型参数,所以训练一套BERT模型所需要的时间和资源成本是非常大的,甚至这样复杂的模型也会影响最终效果。在本文中,我们重点来介绍一种瘦身版的重磅BERT模型-ALBERT,它通过几种优化策略来获得比BERT小得多的模型,但在GLUE、RACE等数据集上反而超越了BERT模型。arXiv:1909.11942, 2019.
【1】本文是Microstrong观看蓝振忠在B站上讲解的直播课程《从BERT到ALBERT》直播地址:https://live.bilibili.com/11869202
【2】【自然语言处理】NLP免费直播(贪心学院),https://www.bilibili.com/video/av89296151?p=4
【3】对albert的理解 - xixika的文章 - 知乎 https://zhuanlan.zhihu.com/p/108105658
【4】ALBERT原理与实践,地址:https://mp.weixin.qq.com/s/SCY2J2ZN_j2L0NoQQehd2A
XLNET
论文:Net: Generalized Autoregressive Pretraining for Language Understanding.
结合了自回归和自编码的优势,仍遵循两阶段的过程,
第一个阶段是语言模型预训练阶段;
第二阶段是任务数据Fine-tuning阶段,
但是改动第一个阶段,不像Bert那种带Mask符号,而是采用排列组合的方式,借鉴自回归语言模型的方法预测下一个单词。且采用了双流自注意力机制。
PLM

MPNET
MLM与PLM结合【bert与xlnet结合】
ERNIE
论文:Enhanced Representation through Knowledge Integration.
使用NLP的工具来识别短语和实体,包括3种层级的Masking:基本、phrase和entity。依次对基于基本级别、短语级别、实体级别分别进行mask训练。对于对话数据,还训练了Dialogue
LM。使用Q和R标记query和response。与BERT 的对比图如下:

ERNIE 2.0
论文:A Continual Pre-training Framework for Language Understanding.
其框架如下:

构造多个无监督任务来学习词法、句法和语义的信息;
且通过增量的方式进行多任务学习,
引入新任务后,并不是只使用新的任务来训练,而是通过多任务学习同时学习之前的任务和新增加的任务,这样既要学习新的信息的同时也不能忘记老的信息。
多个无监督任务包括:
词法任务:Word、phrase、entity级别的mask;
预测一个词是否首字母大小的任务;
预测当前词是否出现在其他文档里
句法任务:把一个段落切分成1到m个段,随机打散,让模型来恢复;
两个句子距离的任务,对于两个句子有三种关系:前后相邻,不相邻但是属于同一个文档,属于不同的文档
语义任务:预测两个句子的语义和修辞关系;利用搜索引擎的数据,给定query和搜索结果,预测两个句子是强相关,弱相关和完全不相关
这几篇文章都是对 BERT 模型的 Pretraining 阶段的 Mask 进行了不同方式的改进,但是对于 BERT 模型本身(基于 Mask LM 的 Pretraining、Transformer 模型和 Fine-tuning)没有做任何修改。
XLMs
论文:Cross-lingual Language Model Pretraining.
跨语言版的bert,使用两种预训练方法:
基于单语种语料的无监督学习
基于跨语言的平行语料的有监督学习
具体实现使用了几种策略:
shared sub-word vocabulary、
causal language modeling、
masked language modeling、
translation language modeling,如下图所示:

CMLM
论文:Cross-lingual masked language model.
即跨语言掩码语言模型。对于无监督机器翻译而言,跨语言预训练模型XLM已被证实是有作用的,但是现有的工作中,预训练模型的跨语言信息只是通过共享BPE空间得到。这样得到的跨语言信号非常隐式,而且受限。CMLM可以将显式的跨语言信息作为训练信号,更好的训练跨语言预训练模型。
方法分为3步:
由n-gram向量推断得到n-gram翻译表。分别用两种语言的单语语料通过fasttext训练单语的n-gram向量,之后通过无监督跨语言词向量的方法得到跨语言n-gram向量,并由两种语言的n-gram向量相似度推断得到两种n-gram之间的翻译表。
在n-gram翻译表的辅助下,用提出的新的训练任务CMLM进行跨语言预训练:随机的mask掉n-gram的字符,在模型输出端,让其预测被mask掉的n-gram字符对应的几个翻译选项。由于n-gram BPE字符的长度与其对应的翻译候选可能不一样,为此借助IBM Model 的思想进行改进。
用预训练的模型初始化翻译模型得到的编码器和解码器,进行无监督机器翻译模型的训练。
SpanBERT
论文:SpanBERT:Improving Pre-training by Representing and Predicting Spans.
在跨度选择任务(例如问答和共指解析)方面取得了实质性进展。训练的方法主要是通过:
(1)掩码连续随机跨度,而不是随机令牌。
(2)优化跨边界目标(SBO),训练跨度边界表示以预测被屏蔽跨度的整个内容,而不依赖于其中的各个令牌表示。

MT-DNN
论文:Multi-Task Deep Neural Networks for Natural Language Understanding
BERT的fine-tune是针对不同的任务在编码层后面加上task-layer,
而MT-DNN就是把所有任务fine-tune的步骤都拼到了一起。
这里根据输出的不同将任务分成了四种。如下图所示:

优化速度和大小
I-BERT:整数量化
DistilBert:蒸馏模型
mobilebert:teacher训练
QDQBERT:量化,初始化的时候声明定义为量化类型的variable
squeezebert:self-attention转变为卷积
用来做生成
MASS
论文:Masked Sequence to Sequence pre-training for language generation.
框架如下图所示:
Bert只是用了transformer的encoder部分,其下游任务不适用于生成任务,提出联合训练encoder和decoder模型,训练分为两步。Encoder:输入为随机mask掉连续部分token的句子,使用transformer对其进行编码
Decoder:输入为与encoder同样的句子,但是mask掉的正好与encoder相反,使用attention机制训练,但是只预测encoder端被mask的单词。该操作可以迫使decoder预测的时候更依赖于source端的输入而不是前面预测出的token,防止误差传递。
此外,还提出一个对于mask长度的超参数k,实验表明k为句子长度的50%~70%模型效果最好。

UNILM
论文:UNIfied Language Model Pre-training for Natural Language Understanding and Generation.
框架如下图所示:
预训练了一个微调后可以同时用于自然语言理解和自然语言生成的下游任务模型,核心框架transformer,
预训练和目标结合了以下三个:
单向语言模型(同ELMO/GPT): 在做attention时只能mask其中一个方向的上下文
双向语言模型(同BERT): 可以同时看到两个方向的上下文
seq2seq语言模型: 输入为两个片段S1和S2,encoder是双向的,decoder是单向的,仅能attention到一个反向的token以及encoder的token
bertforgeneration
encoder = bert
decoder = bert
seq2seq训练
simbert = bert + UniLM
[CLS] SENT_A [SEP] SENT_B [SEP]
[CLS] SENT_B [SEP] SENT_A [SEP]
一个batch的[CLS], 对d做l2归一,两两做内积,scale后mask对角线, 每一行做自己的softmax,每个样本当作一个分类任务。目标签是他的相似句,因为自己本身已经被mask掉了
把batch内其他非相似样本都当作负例
roformer-sim = roformer +UniLM + BART denoiding + 蒸馏d
动态BERT, Dynamic BERT with Adaptive Width and Depth
像BERT和RoBERTa这样的预训练语言模型,尽管在许多自然语言处理任务中功能强大,但在计算和内存方面都很昂贵。为了缓解这个问题,一种方法是在部署之前对特定任务进行压缩。然而,最近的BERT压缩工作通常将大的BERT模型压缩到一个固定的更小的尺寸,并不能完全满足不同硬件性能的不同边缘器件的要求。在本文中,我们提出了一种**新的动态BERT模型(简称DynaBERT),它可以在自适应的宽度和深度上运行。DynaBERT的训练过程包括首先训练一个宽度自适应的BERT,然后通过从全尺寸的模型中提取知识到小的子网络中,允许自适应的宽度和深度。**网络重布线也被用来让更多的子网络共享更重要的注意力头部和神经元。在各种效率约束下的综合实验表明,我们提出的动态BERT(或RoBERTa)在其最大尺寸下的性能与BERT(或RoBERTa)相当,而在较小的宽度和深度下,动态BERT(或RoBERTa)的性能始终优于现有的BERT压缩方法。
https://arxiv.org/abs/2004.04037
调参技巧
6.1 How to Fine-Tune BERT for Text Classification 论文笔记
论文地址:How to Fine-Tune BERT for Text Classification?
实验主要在8个被广泛研究的数据集上进行,在BERT-base模型上做了验证。
文章的主要结论如下:
- 微调(fin-tune)策略 对于长文本,尝试了(1)取头部510 tokens,(2)尾部510 tokens,(3)头部128 tokens+尾部382
tokens,(4)分片并进行最大池化、平均池化、attention,发现方法(3)最好。因为文章的关键信息一般在开头和结尾。
分层训练,上层对文本分类更加重要。 灾难性遗忘:在下游finetune可能会遗忘预训练的知识。需要设置较小的学习率,如2e-5.
分层衰减学习率(Layer-wise Decreasing Layer
Rate),对下层设置更小的学习率可以得到更高的准确率,在lr=2e-5,衰减率ξ \xiξ=0.95
2. 继续预训练(Further Pretraining) 任务内(within-task) 和同领域(in-domain)的继续预训练可以大大提高准确率。 In-domain比within-task要好。
3. 多任务微调(Multi-task Finetuning) 在单任务微调之前的多任务微调有帮助,但是提升效果小于Further pretraining。
4. 小数据集 BERT对小数据集提升很大,这个大家都知道的。Further pretraining对小数据集也有帮助















 705
705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









