






接着上篇写的牛顿法,我们继续来研究牛顿法的改进方法——拟牛顿法。
拟牛顿法其实也是很简单了。为什么要研究出这种方法呢,就是因为常规的牛顿法每次迭代更新x值时都要计算Hessian矩阵。这是个二阶导矩阵,当x的维度增大时,它的计算量也是成指数倍增加的。比如: ,那么H矩阵的维度就是n*n。
所以,我们就想拿个一阶矩阵来近似于Hessian矩阵。过程如下图:

其实思想都很简单。DFP方法是用一个G正定矩阵来近似于Hessian的逆矩阵,而BFGS方法是用一个B正定矩阵来近似于Hessian矩阵。两个矩阵的更新表达式如下所示:
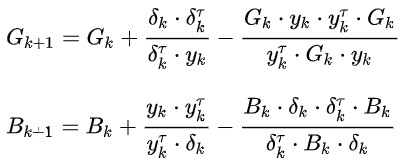
公式看上去都大同小异的,虽然式子有很多,但求起来都挺简单的。另外,BFGS方法是当前最流行的拟牛顿法,收敛的也更快。
下面是我的代码复现。
BFGS算法:
def bfgs_newton(f, x, iters):
"""
实现BFGS拟牛顿法
:param f: 原函数
:param x: 初始值
:param iters: 遍历的最大epoch
:return: 最终更新完毕的x值
"""
# 步长。设为1才能收敛,小于1不能收敛
learning_rate = 1
# 初始化B正定矩阵
B = np.eye(2)
x_len = x.shape[0]
# 一阶导g的第二范式的最小值(阈值)
epsilon = 1e-5
for i in range(1, iters):
g = jacobian(f, x)
if np.linalg.norm(g) < epsilon:
break
p = np.linalg.solve(B, g)
# 更新x值
x_new = x - p*learning_rate
print("第" + str(i) + "次迭代后的结果为:", x_new)
g_new = jacobian(f, x_new)
y = g_new - g
k = x_new - x
y_t = y.reshape([x_len, 1])
Bk = np.dot(B, k)
k_t_B = np.dot(k, B)
kBk = np.dot(np.dot(k, B), k)
# 更新B正定矩阵。完全按照公式来计算
B = B + y_t*y/np.dot(y, k) - Bk.reshape([x_len, 1]) * k_t_B / kBk
x = x_new
return x算法的执行效果如下:

可以看到,在第23次就收敛了。
DFP算法:
def dfp_newton(f, x, iters):
"""
实现DFP拟牛顿算法
:param f: 原函数
:param x: 初始值
:param iters: 遍历的最大epoch
:return: 最终更新完毕的x值
"""
# 步长
learning_rate = 1
# 初始化B正定矩阵
G = np.eye(2)
x_len = x.shape[0]
# 一阶导g的第二范式的最小值(阈值)
epsilon = 1e-5
for i in range(1, iters):
g = jacobian(f, x)
if np.linalg.norm(g) < epsilon:
break
p = np.dot(G, g)
# 更新x值
x_new = x - p * learning_rate
print("第" + str(i) + "次迭代后的结果为:", x_new)
g_new = jacobian(f, x_new)
y = g_new - g
k = x_new - x
Gy = np.dot(G, y)
y_t_G = np.dot(y, G)
yGy = np.dot(np.dot(y, G), y)
# 更新G正定矩阵
G = G + k.reshape([x_len, 1]) * k / np.dot(k, y) - Gy.reshape([x_len, 1]) * y_t_G / yGy
x = x_new
return x算法执行效率如下:

可以看到,执行到1000次也没有收敛。由此证明了BFGS算法的收敛性确实要优于DFP算法。
最后,我还要提一提矩阵与向量的相关计算问题。我在这块儿吃了一些苦头,这儿推荐一篇博文,里面记录了相关知识点。因为我们传入的X实际上是一个一维向量,与二维矩阵做乘积运算时,不同的顺序所得到的结果会有不同,我们需要注意。
完整版代码在此处下载。
















 545
545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











