






ViT+Swin+TNT论文阅读
能力不足,理解有限,请多指点。
记录一下阅读的三篇论文,三个应用于视觉方面的Transformer变体模型。
一、ViT(Visual Transformer)
Visual Transformer,Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
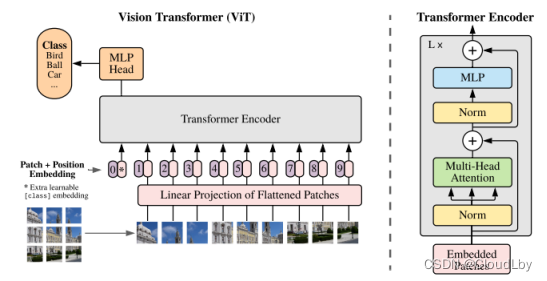
ViT模型架构如上图所示。在ViT中,先将作为输入数据的图像
x
∈
R
H
×
W
×
C
x\in{R^{H \times{W\times{C}}}}
x∈RH×W×C重构为二维补丁序列
x
p
∈
R
N
×
P
2
C
x_p\in{R^{N\times{P^2{C}}}}
xp∈RN×P2C,其中
(
P
,
P
)
(P,P)
(P,P)是每个图像补丁的分辨率,
N
=
H
W
/
P
2
N=HW/P^2
N=HW/P2是图像补丁的个数。
分成N块补丁后,补丁经过线性映射,所有向量的维度都变成D维,向量还需包含补丁信息(Patch embedding)和位置信息(Position embedding)。在进入Transformer Encoder前,每个向量都需插入一个可学习的分类头(Extra learnable class embedding),这些分类头随机初始化后在训练时通过学习来调整参数。
ViT使用的Transformer Encoder与NLP中的Encoder没有很大的变化,此处模型由L层构成,其中使用Layer Normalization进行归一化、使用GeLU作为MLP的非线性激活函数。
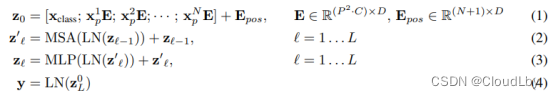
公式(1)的
x
p
i
x_p^i
xpi均为分类头,第一个
x
c
l
a
s
s
x_{class}
xclass作为不包含任何信息的分类头附加的补丁信息为空,E为Patch Embedding,
E
p
o
s
E_{pos}
Epos是Position Embedding。公式(4)的结果y是Transformer Encoder的输出结果,也是MLP Head的输入,最后得到分类结果。
ViT这篇论文主要做的工作是将NLP领域中的Transformer模型应用于视觉领域上,对于CV和NLP这两者不同的输入,ViT将有三个维度的图像降维再升维得到了能够用于Transformer的二维向量,一定程度上解决了输入不同的问题。但论文只提到了分类问题上的应用,还需要讨论能否普遍应用于CV领域的其他问题上。
二、Swin Transformer
Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 10012-10022.
Swin这个名字取自Shifted的S+Windows的win
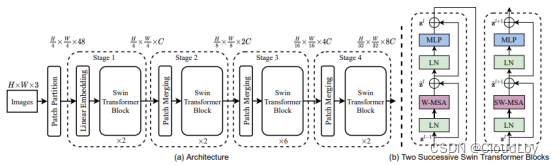
Swin的模型架构如上图所示。输入图像
x
∈
R
H
×
W
×
3
x\in{R^{H\times{W\times{3}}}}
x∈RH×W×3首先经过补丁分割(Patch Partition)下采样至四倍得到大小为
H
4
×
W
4
×
48
\frac{H}{4}\times{\frac{W}{4}\times{48}}
4H×4W×48(即
H
4
×
W
4
×
3
×
16
\frac{H}{4}\times{\frac{W}{4}\times{3\times{16}}}
4H×4W×3×16)。而后由Linear Embedding将维度调整至C维,将
H
4
×
W
4
×
C
\frac{H}{4}\times{\frac{W}{4}\times{C}}
4H×4W×C输入到Stage 1的Swin Transformer Block中。
Swin Transformer Block由两个类似Transformer Encoder的结构组成,W-MSA是常规的窗口内多头自注意力模块,SW-MSA是带有滑动窗口的多头自注意力模块。x2和x6都是偶数倍也是由于该两层连续结构,现在先将该模型的Transformer Block当作一个黑盒。
Stage 1输出的特征图尺寸仍为
H
4
×
W
4
×
C
\frac{H}{4}\times{\frac{W}{4}\times{C}}
4H×4W×C,作为输入在Patch Merging中。
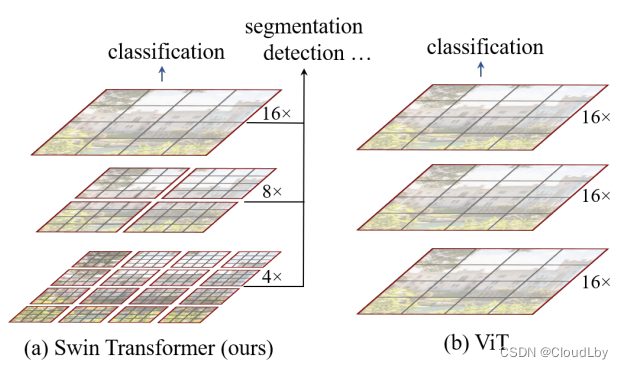
Patch Merging如(a)图所示,进行下采样操作,缩小特征图的H和W,并将通道维度翻倍,得到多尺度特征图。正常来说,维度应该呈4C倍增长,但由于使用了全连接层使得维度以2C倍增长。作者给出的(a)图中,Swin是以下采样4倍、8倍、16倍、32倍来得到层次特征图,而ViT一直都以16倍来操作,Swin这样做的好处是能得到更高维的特征信息,更适用于一些分割检测任务。
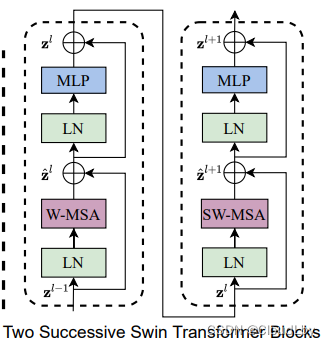
考虑到如果用图像作为输入数据,全局计算复杂度回呈二次型,这并不适用于处理密集预测任务和处理高分辨率图像的视觉问题。
因此,作者提出在互不重叠的窗口里做自注意力计算,Swin Transformer Block用基于滑动窗口的(S)W-MSA模块来代替常规的自注意力机制。

先看这4个公式,
z
^
l
\hat{z}^l
z^l是(S)W-MSA模块的输出特征图,
z
l
z^l
zl是MLP的输出特征图,将前一个模块得到的
z
l
−
1
z^{l-1}
zl−1作为输入,经过一个Block后得到
z
l
z^l
zl,再将
z
l
z^l
zl作为输入数据放进连续的Block中,得到
z
l
+
1
z^{l+1}
zl+1,输入和输出的维度不变。
这么看起来与常规的自注意力机制没有什么区别,那么基于窗口的自注意力机制有什么不同呢?
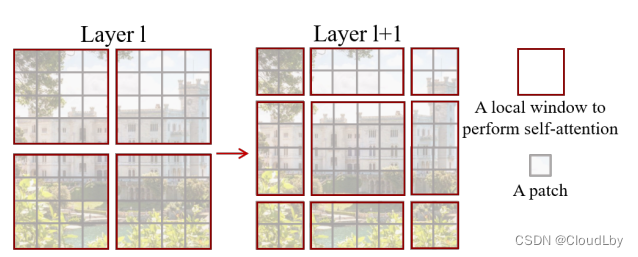
Swin会在第
l
l
l层将图像划分成大小为
M
×
M
M\times{M}
M×M的窗口,并在每个窗口里进行自注意力计算。接着在下一层Block即
l
+
1
l+1
l+1层中,将窗口向右和向下移动
⌊
M
2
⌋
\lfloor{\frac{M}{2}}\rfloor
⌊2M⌋位,得到新窗口后再计算新窗口内的相关性(即计算自注意力)。这样基于滑动窗口的自注意力机制不仅降低了计算复杂度,还将相邻窗口之间的信息连接起来,窗口之间互相通信,并且从架构图可以看到做了多次这样的移位操作,其实足够计算出整张图像的相邻信息。
但这种方法还是存在一些问题,像上面的示意图那样,窗口数量从4个变成了9个,而且有些窗口大小不一致,计算量也增至2.25倍。
为了解决这个问题,作者提出一种将元素向左上角循环移位的方法(Cyclic Shift)。
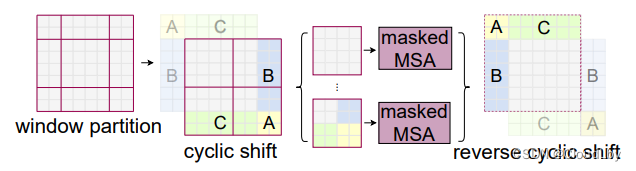
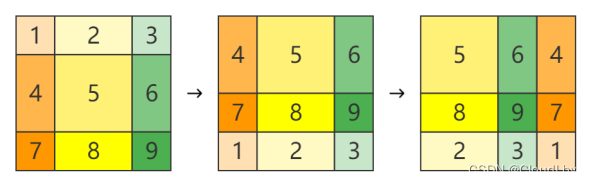
循环移位可以看作是先向上移动
⌊
M
2
⌋
\lfloor{\frac{M}{2}}\rfloor
⌊2M⌋位,再向左移动
⌊
M
2
⌋
\lfloor{\frac{M}{2}}\rfloor
⌊2M⌋位。移位后的窗口由于存在不相邻的子窗口,而不相邻的子窗口做相关性计算是没有意义的,因此需要遮挡掉不需要的计算结果。
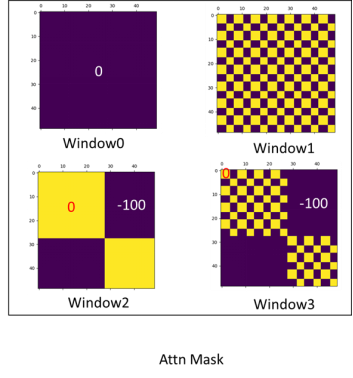
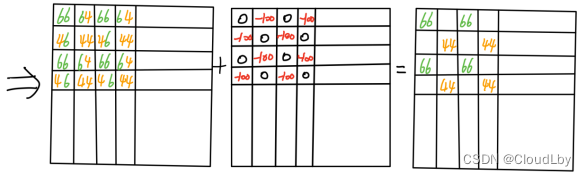
Swin的操作是先全部窗口进行相关性计算后,利用Masked MSA对不相邻子窗口的结果
Q
K
T
QK^T
QKT加上-100。因为经过归一化后数值一般都会变得很小,-100对这些小数值来说是一个更小的负数,在进行Softmax后会忽略掉(变为0),这就实现了遮挡不需要的计算结果。
结束后还需要将移位的子窗口归位,保持各元素之间相对位置不变。
下面简单比划一下为什么Masked这样设置:
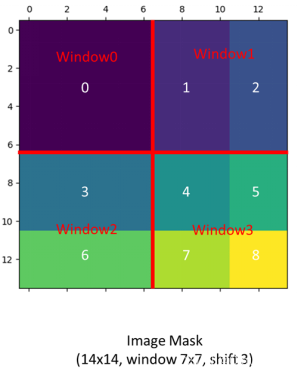
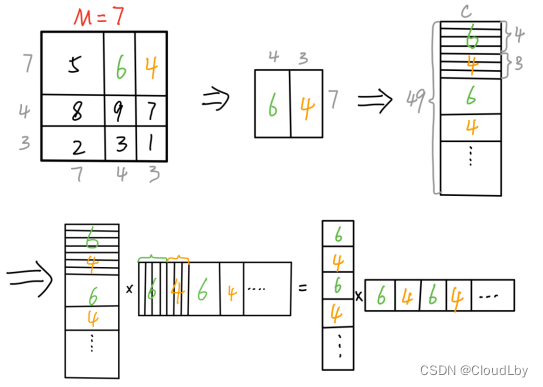
首先假设窗口大小M=7,故分别向上和向左移动3位,这里取序号为6和4的子窗口计算。将窗口内的各元素拉直成C维,得到的Q和K也是49xC维,计算
Q
K
T
QK^T
QKT,结果中有序号6和序号6子窗口内元素计算、有序号4和序号4的元素计算、还有序号6和序号4元素的计算,而序号6和序号4窗口的计算是无意义的,因此我们加上一个掩码矩阵,对不需要的计算结果加上-100。
其他窗口的计算也类似。
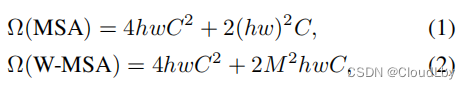
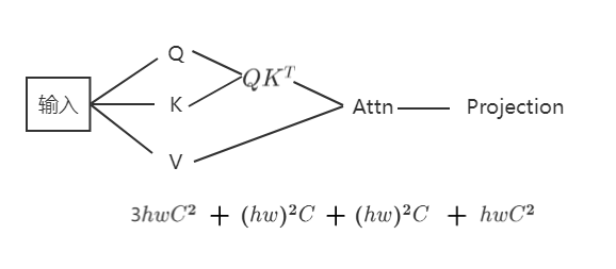

解释一下计算复杂度,对于常规的多头自注意力机制计算,输入图像与矩阵内积得到QKV,这三次内积的计算复杂度为
3
h
w
C
2
3hwC^2
3hwC2,
Q
K
T
QK^T
QKT的计算复杂度为
(
h
w
)
2
C
{(hw)}^2C
(hw)2C,忽略softmax的计算,Attention这一步的计算复杂度为
(
h
w
)
2
C
{(hw)}^2C
(hw)2C,最后多头映射的计算复杂度为
h
w
C
2
hwC^2
hwC2。
故常规的多头自注意力机制计算复杂度
=
4
h
w
C
2
+
2
(
h
w
)
2
C
=4hwC^2+2{(hw)}^2C
=4hwC2+2(hw)2C。
对于(S)W-MSA,在单个窗口内计算,
h
=
M
,
w
=
M
h=M, w=M
h=M,w=M,故单个窗口的计算复杂度
=
3
M
2
C
2
+
(
M
2
)
2
C
+
(
M
2
)
2
C
+
M
2
C
2
=
4
M
2
C
2
+
2
(
M
2
)
2
C
=3M^2C^2+{(M^2)}^2C+{(M^2)}^2C+M^2C^2=4M^2C^2+2{(M^2)}^2C
=3M2C2+(M2)2C+(M2)2C+M2C2=4M2C2+2(M2)2C,
又因由
h
M
×
w
m
\frac{h}{M}\times{\frac{w}{m}}
Mh×mw个窗口,故总体计算复杂度为
=
(
h
M
×
w
m
)
×
[
4
M
2
C
2
+
2
(
M
2
)
2
C
]
=
4
h
w
C
2
+
2
M
2
h
w
C
={(\frac{h}{M}\times{\frac{w}{m}})}\times{[4M^2C^2+2{(M^2)}^2C]}=4hwC^2+2M^2hwC
=(Mh×mw)×[4M2C2+2(M2)2C]=4hwC2+2M2hwC
三、Transformer in Transformer(TNT)
Han K, Xiao A, Wu E, et al. Transformer in transformer[J]. Advances in Neural Information Processing Systems, 2021, 34.
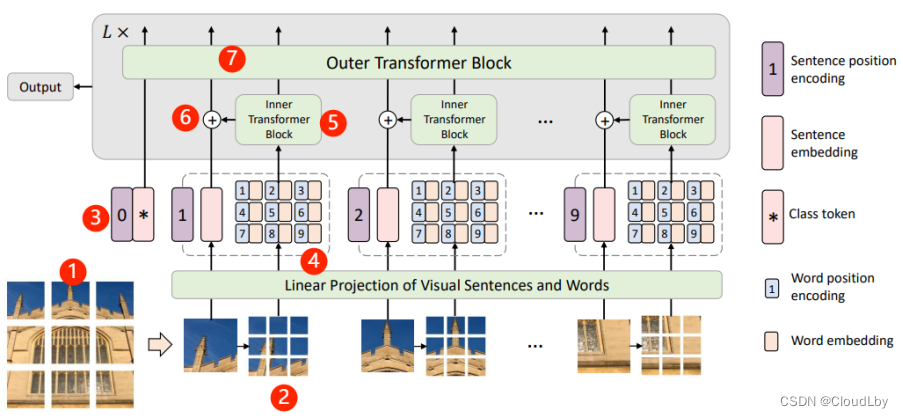
- 首先将输入的图像统一分割成n块补丁 X = [ X 1 , X 2 , . . . , X n ] ∈ R n × P × P × 3 X=[X^1,X^2,...,X^n]\in{R^{n\times{P\times{P\times{3}}}}} X=[X1,X2,...,Xn]∈Rn×P×P×3, X i X^i Xi为句子向量(sentence embedding);
- 每块句子补丁又分成m块子补丁 X i → [ x i , 1 , x i , 2 , . . . , x i , m ] , x i , j ∈ R S × S × 3 X^i→[x^{i,1},x^{i,2},...,x^{i,m}],x^{i,j}\in{R^{S\times{S\times{3}}}} Xi→[xi,1,xi,2,...,xi,m],xi,j∈RS×S×3, x i , j x^{i,j} xi,j为词向量(word embedding);
- 句子向量线性映射得到 Z 0 = [ Z c l a s s , Z 0 1 , Z 0 2 , . . . , Z 0 n ] × R ( n + 1 ) × d Z_0=[Z_class,Z_0^1,Z_0^2,...,Z_0^n]\times{R^{(n+1)\times{d}}} Z0=[Zclass,Z01,Z02,...,Z0n]×R(n+1)×d;
- 词向量线性映射得到 Y i = [ y i , 1 , y i , 2 , . . . , y i , m ] , y i , j = F C ( V e c ( x i , j ) ) Y^i=[y^{i,1},y^{i,2},...,y^{i,m}],y^{i,j}=FC(Vec(x^{i,j})) Yi=[yi,1,yi,2,...,yi,m],yi,j=FC(Vec(xi,j)),词向量的集合 Y l = [ Y l 1 , Y l 2 , . . . , Y l m ] Y_l=[Y_l^1,Y_l^2,...,Y_l^m] Yl=[Yl1,Yl2,...,Ylm];
- Inner Transformer Block处理词向量的数据流, Y ‘ l i = Y l − 1 i + M S A ( L N ( Y l − 1 i ) ) , Y L i = Y ‘ l i + M L P ( L N ( Y ‘ l i ) ) Y`_l^i=Y_{l-1}^i+MSA(LN(Y_{l-1}^i)), Y_L^i=Y`_l^i+MLP(LN(Y`_l^i)) Y‘li=Yl−1i+MSA(LN(Yl−1i)),YLi=Y‘li+MLP(LN(Y‘li));
- 词向量与句子向量相加, Z l − 1 i = Z l − 1 i + F C ( V e c ( Y l i ) ) Z_{l-1}^i=Z_{l-1}^i+FC(Vec(Y_l^i)) Zl−1i=Zl−1i+FC(Vec(Yli));
- Outer Transformer Block处理句子向量的数据流, Z ‘ l = Z l − 1 + M S A ( L N ( Z l − 1 ) ) , Z l = Z ‘ l + M L P ( L N ( Z ‘ L ) ) Z`_l=Z_{l-1}+MSA(LN(Z_{l-1})),Z_l=Z`_l+MLP(LN(Z`_L)) Z‘l=Zl−1+MSA(LN(Zl−1)),Zl=Z‘l+MLP(LN(Z‘L));
- TNT整个过程可以表示为: Y l , Z l = T N T ( Y l − 1 , Z l − 1 ) Y_l,Z_l=TNT(Y_{l-1},Z_{l-1}) Yl,Zl=TNT(Yl−1,Zl−1)。
TNT虽然也有考虑到图像的局部信息,但与Swin不同的是它没有考虑到与相邻窗口联系。















 4695
4695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









