






预览版本
PyTorch基础
1)导入PyTorch:import torch
2)安装PyTorch(终端命令行在对应python环境中下载):pip install torch
3)创建张量:torch.tensor()
4)将NumPy数组转换为PyTorch张量:torch.from_numpy()
5)检查张量大小:tensor.size()
6)访问张量的形状:tensor.shape
7)使用张量进行逐元素操作(类似Python的numpy数组的操作)
8)检查GPU可用性:torch.cuda.is_available()
9)将张量移动到GPU:tensor.to('cuda')
张量操作
- 逐元素加法:torch.add(x, y)
- 矩阵乘法:torch.mm(input, other)或input @ other
- 矩阵转置:tensor.t()或tensor.transpose()
- 张量重塑:tensor.view(size)
- 增加维度:torch.unsqueeze(tensor, dim)或tensor.unsqueeze(dim)
- 展平张量:torch.flatten(tensor)或tensor.view(-1)其实就是将任意维度的张量展开为一维张量。
- 沿维度连接张量:torch.cat(tensors, dim)
- 指定维度求和:tensor.sum(dim)
- 计算均值:tensor.mean(dim)
- 获取最大值索引:torch.argmax(tensor, dim)
- 逐元素平方根:torch.sqrt(tensor)
自动求导和梯度
21)启用梯度跟踪:torch.tensor(data, requires_grad=True)或tensor.requires_grad_(True)
22)使用梯度跟踪变量torch.autograd.Variable(tensor,requires_grad=True)
23)计算梯度:tensor.backward()
24)访问梯度:tensor.grad
25)推理期间禁用梯度跟踪:torch.no_grad()
26)定义可训练参数:torch.nn.Parameter(tensor)
27)清除累积梯度:optimizer.zero_grad()
神经网络
28)创建神经网络模块:torch.nn.Module
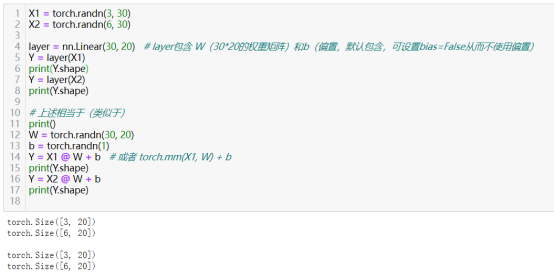
29)定义全连接层:torch.nn.Linear(in_features, out_features)
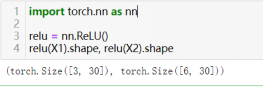
30)使用激活函数:torch.nn.ReLU(),其他激活函数:torch.nn.xxx()
31)堆叠层为顺序模型:torch.nn.Sequential(*layers)
32)使用激活和损失函数:torch.nn.functional.relu(input),其他函数xxx:torch.nn.functional.xxx()
33)初始化权重:torch.nn.init.xavier_uniform_(tensor),其它初始化方法xxx:torch.nn.init.xxx()
损失函数
34)选择损失函数:torch.nn.CrossEntropyLoss()等等
35)自定义损失函数:torch.nn.Module
训练模型
36)设置模型为训练模式:model.train()
37)设置模型为评估模式:model.eval()
38)前向传递:model.forward(input)或直接model(input)
39)通过计算后的损失反向传播:loss.backward()
40)更新模型参数:optimizer.step()
- 使用自定义数据集:torch.utils.data.Dataset
- 使用数据加载器:torch.utils.data.DataLoader43)使用优化器:torch.optim.SGD(model.parameters(),…)等等
模型评估
44)评估模型:model.evaluate(validation_loader)
45)计算分类任务指标:torchmetrics.functional.accuracy(output, target)
迁移学习
46)使用预训练模型:torchvision.models.resnet50(pretrained=True)
47)改全连接层:model.fc = torch.nn.Linear(...)
48)冻结层:for param in model.parameters():param.requires_grad = False
模型保存和加载
49)保存和加载整个模型:torch.save(model, "xxx.pth")和torch.load(“xxx.pth”)
50)保存和加载模型检查点(模型当前权重):torch.save(model.state_dict(),"xxx_params.ckpt")和model.load_state_dict(torch.load("xxx_params.ckpt"))
数据可视化
51)可视化二维张量:matplotlib.pyplot.imshow(tensor)
52)使用TensorBoard可视化计算/训练等过程中的各种数据
序列模型
53)词嵌入:torch.nn.Embedding(num_embeddings, embedding_dim)
54)循环神经网络:torch.nn.RNN(input_size, hidden_size, num_layers)
RNN变体:GRU,LSTM等:torch.nn.GRU(), ……
- 注意力机制:torch.nn.MultiheadAttention(embed_dim, num_heads)
学习率调度器
56)使用学习率调度器:torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma)
57)自定义学习率调度策略:
class CustomAnnealingLR(torch.optim.lr_scheduler _LRScheduler):……
分布式训练
58)多GPU训练/分布式训练:torch.nn.parallel.DistributedDataParallel(DDP)
梯度裁剪
59)裁剪梯度:torch.nn.utils.clip_grad_norm_(parameters, max_norm)
模型微调
60)尝试使用逐步解冻的方法对预训练模型进行微调。
处理不平衡数据集
61)对不平衡数据集使用加权损失函数:为损失函数的weights参数指定具体的值
62)采用过采样或欠采样技术来平衡不平衡数据集中的类别比例。
自定义激活函数
63)定义激活函数:class CustomActivation(torch.nn.Module)
模型集成
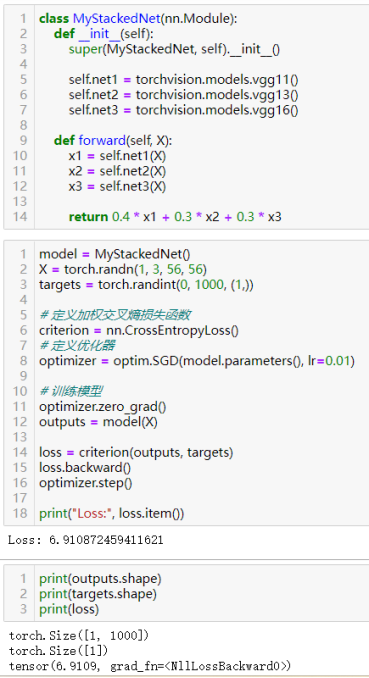
64)通过平均或投票结合“不同”模型进行集成学习。
65)实现堆叠技术以组合模型。
理缺失数据
66)使用掩码张量处理缺失数据。
67)使用插补技术处理缺失数据。
导出到ONNX
68)将PyTorch模型转换为ONNX格式以提高互操作性:torch.onnx.export(…)
69)使用ONNX在边缘设备上部署PyTorch模型。
导出到TorchScript
70)将PyTorch模型转换为TorchScript以优化部署:torch.jit.trace(model, example)或torch.jit.script(my_model)
基础实验
1 PyTorch基础
1)导入PyTorch:import torch
2)安装PyTorch(终端命令行在对应python环境中下载):pip install torch
3)创建张量:torch.tensor()
torch.tensor(data)中的data可以是列表、元祖、numpy数组等
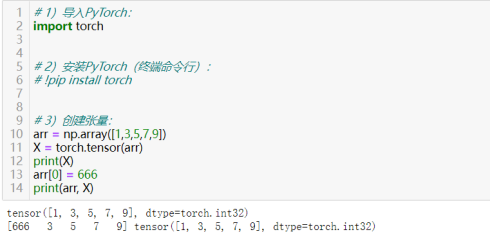
4)将NumPy数组转换为PyTorch张量:torch.from_numpy()
创建后的数组与原数组共用数据的存储区,另外:张量转NumPy:numpy_array = tensor.numpy()

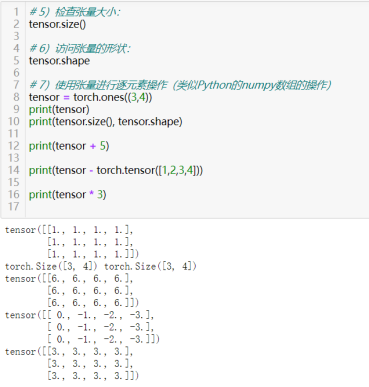
5)检查张量大小:tensor.size()
6)访问张量的形状:tensor.shape
7)使用张量进行逐元素操作(类似Python的numpy数组的操作)
对两个或多个张量中对应位置的元素进行数学运算,如加、减、乘、除等,(在某些情况下,使用广播机制,可使得形状不同的张量进行逐元素操作)
8)检查GPU可用性:torch.cuda.is_available()
- 将张量移动到GPU:tensor.to('cuda')
2张量操作
- 逐元素加法:torch.add(x, y)
- 矩阵乘法:torch.mm(input, other)或input @ other
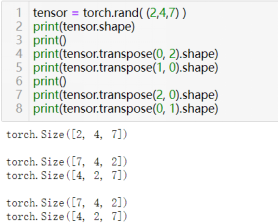
- 矩阵转置:tensor.t()或tensor.transpose()
tensor.transpose(dim0, dim1) 函数用于交换张量(tensor)中两个维度的位置。这个函数不会改变张量中元素的值,只是改变了这些元素在内存中的排列顺序,或者说改变了张量的形状(shape),但总元素数量保持不变。
- 张量重塑:tensor.view(size)在保持原张量tensor的元素数量不变和元素相对存储次序不变下调整tensor的形状。
- 增加维度:torch.unsqueeze(tensor, dim)或tensor.unsqueeze(dim)在张量tensor的维度dim中插入新维度
- 展平张量:torch.flatten(tensor)或tensor.view(-1)其实就是将任意维度的张量展开为一维张量。
- 沿维度连接张量:torch.cat(tensors, dim)torch.cat( (tensor1, tensor2, …), dim )将多个张量在维度dim上拼接,每个张量维度长度相同且除维度dim外其它维度大小相等。
- 指定维度求和:tensor.sum(dim)
- 计算均值:tensor.mean(dim)
计算均值时数据元素的数据类型不能是整型
- 获取最大值索引:torch.argmax(tensor, dim)
- 逐元素平方根:torch.sqrt(tensor)
略
3自动求导和梯度
21)启用梯度跟踪:torch.tensor(data, requires_grad=True)或tensor.requires_grad_(True)
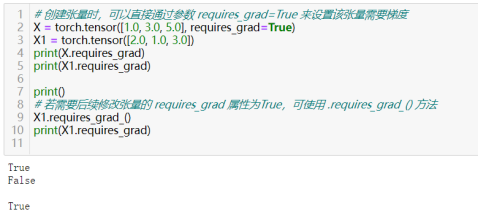
22)使用梯度跟踪变量torch.autograd.Variable(tensor,requires_grad=True)
在PyTorch的新版本中(0.4及以后),torch.autograd.Variable和torch.Tensor已经被合并,因此不再需要显式地通过torch.autograd.Variable来包装张量并设置requires_grad。
即该方法(已)弃用,实现的效果就是21)中的效果,虽然方法可能仍保留。
23)计算梯度:tensor.backward()

24)访问梯度:tensor.grad

e.g.1

e.g.2
25)推理期间禁用梯度跟踪:torch.no_grad()
一个上下文管理器(context manager),用于暂时禁用梯度计算。
在训练神经网络时,我们通常需要计算梯度来更新网络的权重,但在某些情况下不需要计算梯度,可使用 torch.no_grad(),这能减少内存消耗并加速计算,因它避免了不必要的梯度计算。
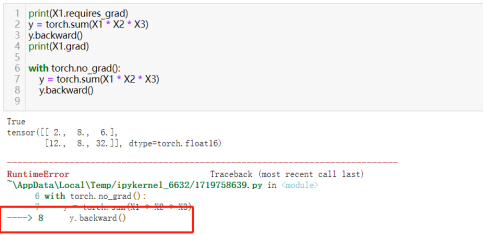
在禁用梯度计算的代码块中计算梯度会报错
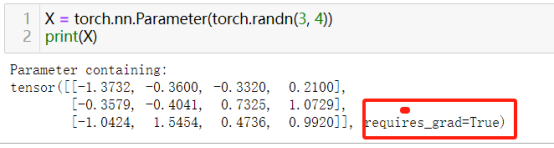
26)定义可训练参数:torch.nn.Parameter(tensor)
nn.Parameter是Tensor的一个子类,它会自动要求梯度。通常用于在自定义模型层定义可训练的参数,如权重和偏置。
27)清除累积梯度:optimizer.zero_grad()
在网络模型训练过程中,我们使用梯度下降法进行迭代时,模型参数每次迭代时结果一次反向传播后梯度会“累积”在模型参数中,为不影响参数优化的正确性,需要清理累积的梯度;先看看梯度的“累积”是怎么回事(更确切的说,应该是“累计”)
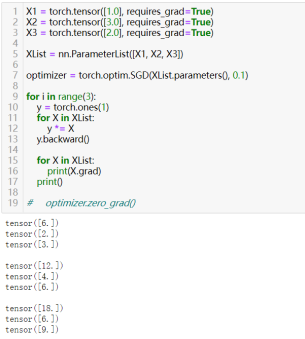
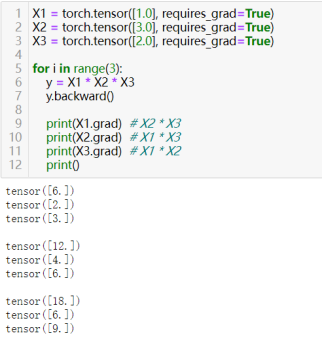
梯度累积举例
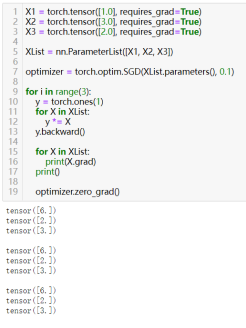
清除每次使用后的梯度,防止累积
4神经网络
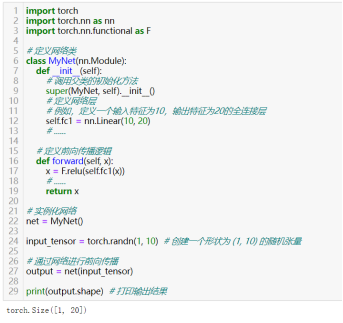
28)创建神经网络模块:torch.nn.Module
这是 PyTorch 中所有神经网络模块的基类。当自定义神经网络模型时,需要继承这个类,并实现至少两个方法:__init__ 和 forward。__init__ 方法用于初始化模块,即定义网络的层,而 forward 方法定义了数据通过网络层的前向传播逻辑。
29)定义全连接层:torch.nn.Linear(in_features, out_features)
30)使用激活函数:torch.nn.ReLU(),其他激活函数:torch.nn.xxx()
31)堆叠层为顺序模型:torch.nn.Sequential(*layers)

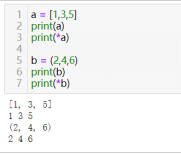
注:*layers 中的*把可迭代变量layers中的各元素取出,看简单例子:
32)使用激活和损失函数:torch.nn.functional.relu(input),其他函数xxx:torch.nn.functional.xxx()

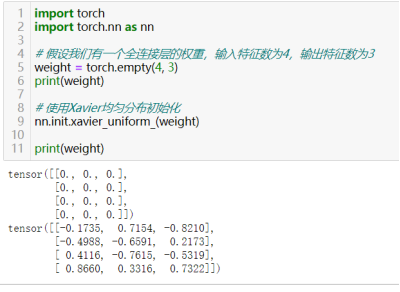
33)初始化权重:torch.nn.init.xavier_uniform_(tensor),其它初始化方法xxx:torch.nn.init.xxx()
用于将给定的张量(tensor)使用Xavier均匀分布(也称为Glorot初始化)进行初始化。有助于输入和输出的方差在神经网络层中保持一致,有助于缓解梯度消失或梯度爆炸的问题,特别是在使用Sigmoid或Tanh等激活函数时。
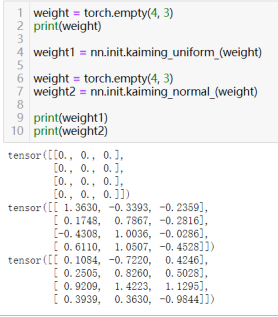
torch.nn.init.kaiming_uniform_或torch.nn.init.kaiming_normal_
进行He初始化(Kaiming初始化),分别使用均匀分布和高斯分布来初始化权重,特别适用于使用ReLU及其变体作为激活函数的神经网络。
5损失函数
34)选择损失函数:torch.nn.CrossEntropyLoss()等等
可到官方文档中搜索指定模块、函数的详细描述(包括)使用说明,上同下同): https://pytorch.org/docs/stable/index.html
神经网络中的损失函数是用来衡量神经网络输出结果与真实结果之间差异的函数,是评估算法模型得到的预测值与真实值之间差距的指标。损失函数值越小,说明二者之间的差距越小,表明模型拟合得越好。神经网络常用损失函数可以大致分为分类损失函数和回归损失函数两大类。
以交叉熵损失函数为例(常用于多分类模型),实际中,输入一般有两种形式会出现:predict(N,C)和target(N)或target(N, C),其中N为批次大小batch_size,C为类别数量classes_num.
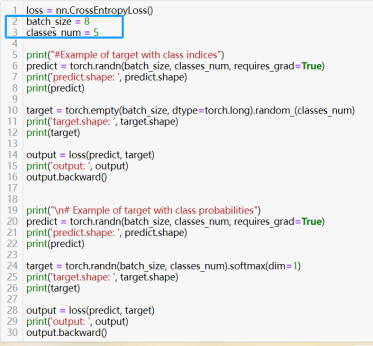

35)自定义损失函数:torch.nn.Module
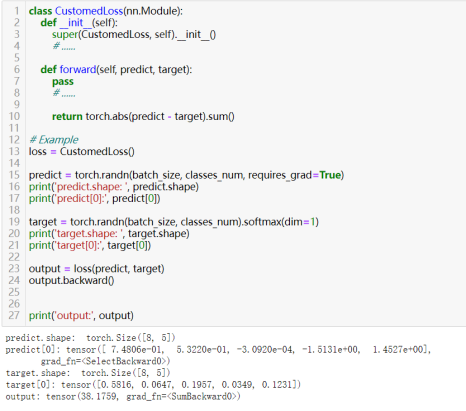
和自定义网络层(神经网络-28))类似,但很大的不同是,一般在forward方法中,输入张量有两个(模型预测输出和真实预测输出),且由于要通过损失函数反向传播,所以forward的最终输出是“标量”(零维张量)。
6训练模型
36)设置模型为训练模式:model.train()
在训练过程中,某些层(如Dropout和BatchNorm)会表现出不同的行为。为了明确指示模型当前处于训练模式,应调用model.train()。
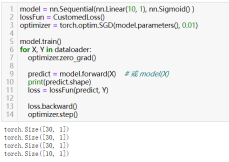
37)设置模型为评估模式:model.eval()
在评估(或测试)过程中,为了获得准确的性能评估,应将模型设置为评估模式。在评估模式下,某些层(如Dropout)将不会随机丢弃任何元素。
更直接地说,除了在模型训练过程中设置model为train()模式,其它时候一般都设置为评估模式。
38)前向传递:model.forward(input)或直接model(input)
39)通过计算后的损失反向传播:loss.backward()
40)更新模型参数:optimizer.step()

- 使用自定义数据集:torch.utils.data.Dataset
- 使用数据加载器:torch.utils.data.DataLoader
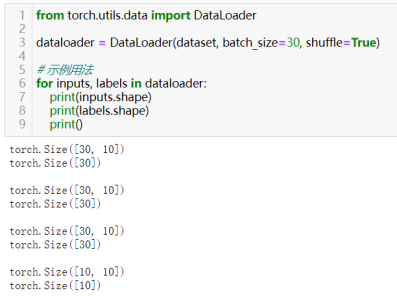
Shuffe
- 使用优化器:torch.optim.SGD(model.parameters(), …)等等
略
7模型评估
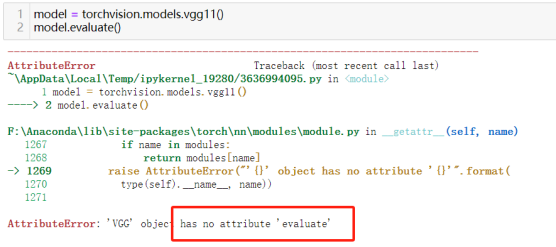
44)评估模型:model.evaluate(validation_loader)
Pytorch框架下模型没有直接用于评估的方法evaluate(),但可在自定义网络模型中加入该方法并实现是个可接受的途径。

45)计算分类任务指标:torchmetrics.functional.accuracy(output, target)
torchmetrics是一个用于 PyTorch 的开源库,提供了一组方便且高效的评估指标计算工具。(下载 pip install torchmetrics)该库提供多种评估指标,包括分类、回归、图像处理和生成模型等领域的常用指标。
可针对自己的学习任务对该库进行针对性学习和使用。
官网文档: https://lightning.ai/docs/torchmetrics/stable/
8迁移学习
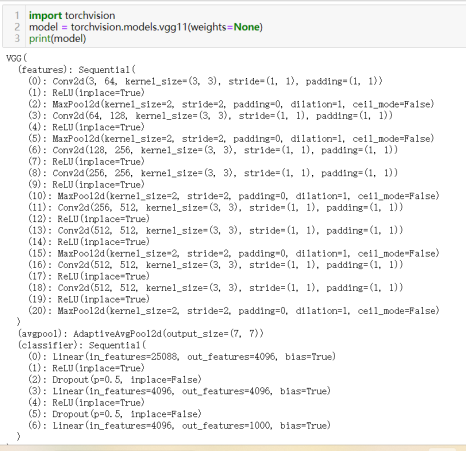
46)使用预训练模型:torchvision.models.resnet50(pretrained=True)
torchvision是pytorch的一个图形库,它服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。
torchvision.models中包含alexnet、densenet、inception、resnet、squeezenet、vgg,resnet等常用的网络结构,并且提供了预训练模型,使用参数pretrained控制是否加载预训练模型(True 或 False);其实在新版本中,pretrained关键字已被weights替代(True或None)。
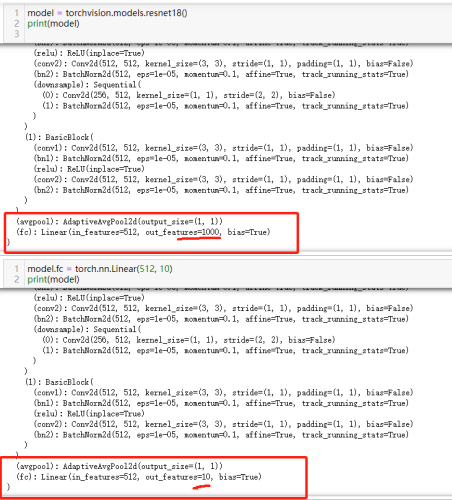
47)改全连接层:model.fc = torch.nn.Linear(...)
也可修改其它层,model.layerName = torch.nn.xxx(…)
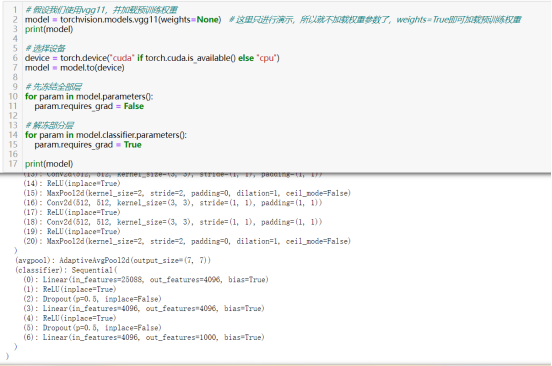
48)冻结层:for param in model.parameters():param.requires_grad = False

冻结层,即令网络结构中的某些层的参数(Tensor张量)取消其梯度的自动跟踪,这样在训练模型过程中更新参数时被“冻结”的参数不会得到更新;若把整个模型看作一个多元函数,每层参数看作一个“元”(自变量),冻结操作相当于把冻结的层看作常数(值为冻结前对应的的参数值)。
也可指定需要冻结的网络层中的参数;
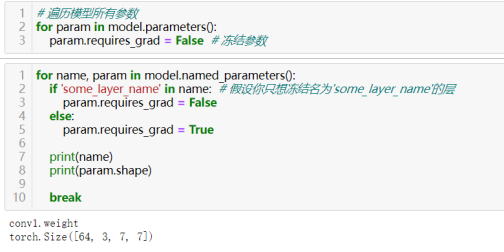
冻结网络模型中某些层的作用:
减少计算量:减少在反向传播过程中需要计算的梯度数量;
避免过拟合:预训练的模型的某些浅层特征(如边缘检测、颜色识别等)是通用的。通过冻结这些层,可以利用这些已学习到的特征,同时减少在新任务上过度训练的风险,有助于防过拟合;
保留预训练知识的精华;
提高模型稳定性:在某些情况下,通过冻结一部分层,可以减少需要优化的参数数量,从而提高训练的稳定性。
9模型保存和加载
49)保存和加载整个模型:torch.save(model, "xxx.pth")和torch.load(“xxx.pth”)
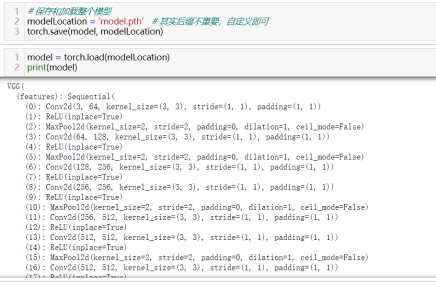
50)保存和加载模型检查点(模型当前权重):torch.save(model.state_dict(),"xxx_params.ckpt")和model.load_state_dict(torch.load("xxx_params.ckpt"))
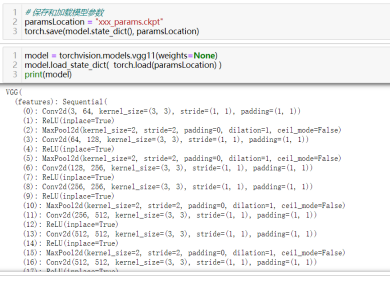
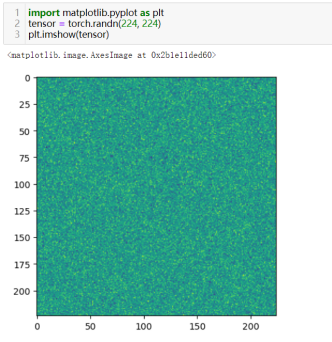
10数据可视化
51)可视化二维张量:matplotlib.pyplot.imshow(tensor)
常用于可视化二维常量(表示图像的张量)
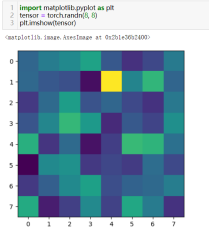
52)使用TensorBoard可视化计算/训练等过程中的各种数据torch.utils.tensorboard.SummaryWriter().add_scalar('loss', loss)
需要安装第三方包tensorboard且pytorch版本大于1.10才能使用上述方法

- 运行记录相关的代码

b. 命令行运行:tensorboard --logdir= log_directory
其中log_directory默认为步骤a后产生的runs目录的地址
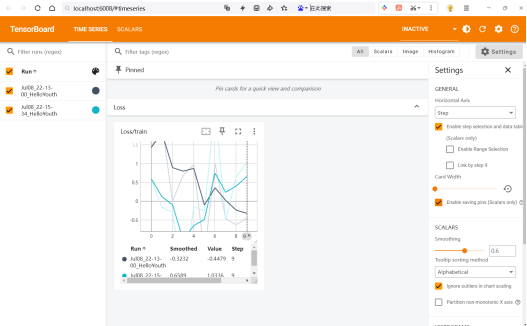
c.浏览器打开上一步产生的URL
11序列模型
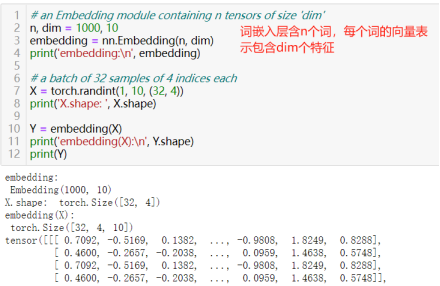
53)词嵌入:torch.nn.Embedding(num_embeddings, embedding_dim)
num _ embeddings:嵌入字典的大小(有多少个不同的“词”)
embedding _ dim:每个嵌入向量的大小(每个词向量的的特征的数量)
该模块的输入是一个索引列表,输出是相应的单词嵌入。(输入:包含要提取的索引的任意形状的IntTensor或LongTensor;输出:形状为(*,H),其中*是输入形状,H = embedding _ dim)
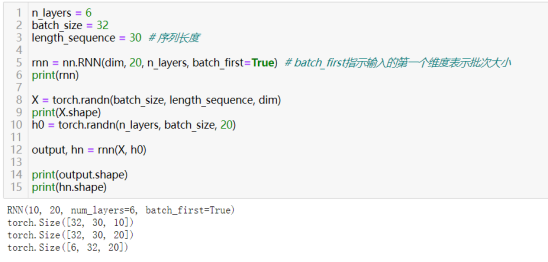
54)循环神经网络:torch.nn.RNN(input_size, hidden_size, num_layers)
RNN变体:GRU,LSTM等:torch.nn.GRU(), ……
input _ size–输入x中预期特征的数量(一般对应词向量的大小)
hidden _ size–处于隐藏状态的特征数量h
num_layers –循环层的层数
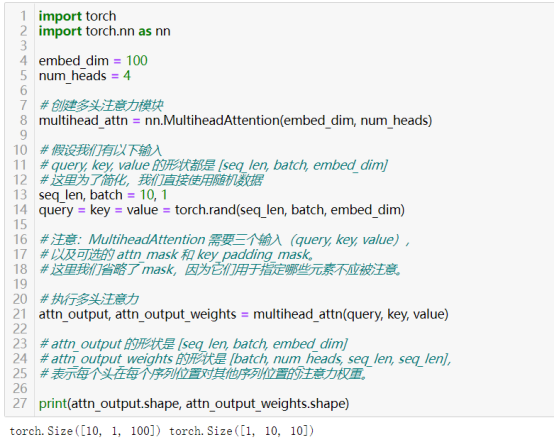
- 注意力机制:torch.nn.MultiheadAttention(embed_dim, num_heads)
MultiheadAttention是多头注意力机制,它是 Transformer 模型中的核心组件之一,它通过并行地在不同的表示子空间(即“头”)中执行注意力函数,允许模型在不同的位置同时关注来自输入序列的不同部分的信息。
核心参数:
- embed_dim:嵌入维度,即每个输入嵌入的维度大小。这个维度是输入序列中每个元素的特征向量的长度。
- num_heads:头的数量,即并行执行注意力函数的子空间数量。每个头的嵌入维度是embed_dim // num_heads(假设embed_dim能被num_heads整除,因为是必须的,否则执行报错)
12学习率调度器
56)使用学习率调度器:torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma)
官网文档
作用:在每step_size个epochs时,通过gamma衰减每个参数组的学习率。(基于步数的递减)
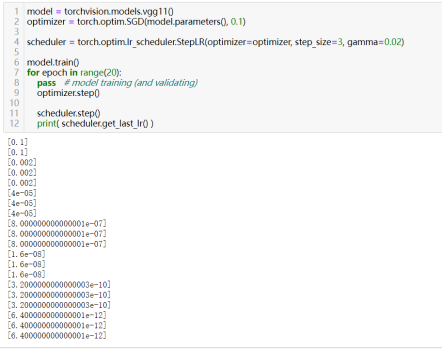
每step_size个epoch后将学习率乘以gamma
还有ExponentialLR调度器实现了类似指数衰减的效果,每个epoch将学习率乘以gamma。
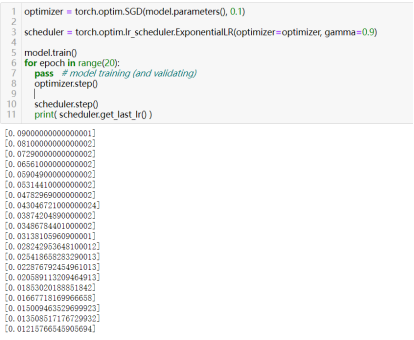
效果等价于StepLR(optimizer, step_size=1, gamma=0.9)
57)自定义学习率调度策略:
class CustomAnnealingLR(torch.optim.lr_scheduler _LRScheduler):……
除了深度学习框架本身提供的学习率调度策略相关的方法,若需要更复杂的学习率退火策略,可通过继承_LRScheduler基类来创建自己的调度器。
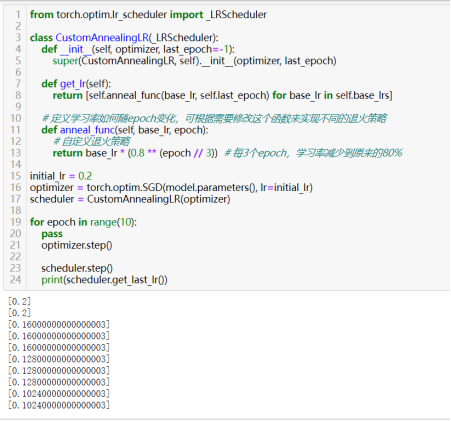
自定义学习率调度器可实现实际中需要的复杂的学习率改变策略,如学习率预热以稳定训练(如:预热阶段先线性增加至指定大小,然后保持不变),周期性循环变化等变化策略。
13分布式训练
58)多GPU训练/分布式训练:torch.nn.parallel.DistributedDataParallel(DDP)
官网文档
一般使用步骤:
- 初始化分布式环境:使用torch.distributed.init_process_group初始化分布式进程组。
- 设置设备:为每个进程分配一个GPU。
- 封装模型:使用DistributedDataParallel封装模型。
- 配置数据加载器:确保每个进程加载其专属的数据分片。
- 训练循环:在每个进程中运行训练循环,使用all_reduce操作同步梯度。
- 清理:在训练结束后清理分布式环境。
14梯度裁剪
59)裁剪梯度:torch.nn.utils.clip_grad_norm_(parameters, max_norm)
官方文档
作用:直接修改parameters中每个参数的.grad属性,将其梯度的范数裁剪到不超过max_norm指定的值。这样做有助于在训练过程中保持梯度的稳定性。
核心参数:
- parameters (Iterable[Tensor] or Tensor): 需要裁剪梯度的参数列表或单个参数。这通常是模型的parameters()方法的返回值,它包含了模型中所有可训练的参数。
- max_norm (float): 梯度的最大范数(norm)值。如果梯度的范数超过了这个值,梯度将会被裁剪,使得梯度的范数等于这个值。裁剪是通过对梯度进行缩放来实现的。
- norm_type (float, 可选): 用于计算梯度的范数的类型。默认为2.0,即使用L2范数(欧几里得范数)。你可以根据需要选择其他范数类型,如1.0表示L1范数(曼哈顿距离)。
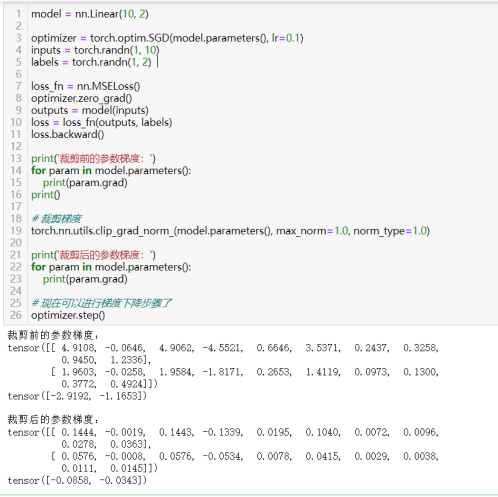
15模型微调
60)尝试使用逐步解冻的方法对预训练模型进行微调。
使用逐步解冻(gradual unfreezing)的方法,特别是在处理大型数据集或资源受限时:从冻结预训练模型的大部分层开始,然后随着训练的进行逐步解冻(即开始更新权重)更多的层。
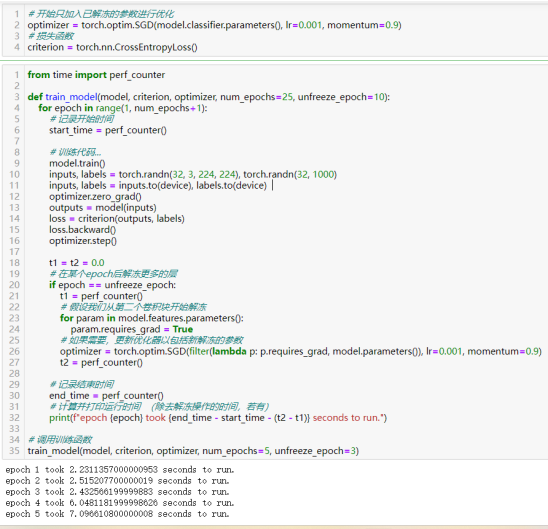
16处理不平衡数据集
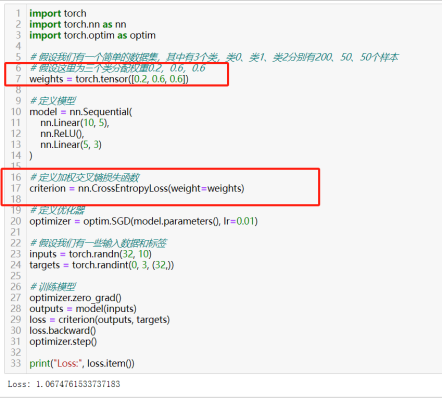
61)对不平衡数据集使用加权损失函数:为损失函数的weights参数指定具体的值
不平衡数据集:数据集中各个类别的样本量差异较大,通常表现为某一类别的样本数量远大于其他类别。这种数据分布情况在实际的许多应用中很常见。
对不平衡数据集使用加权损失函数首先要根据数据集中每个类的样本数量来确定权重。一般来说,少数类的权重应该更高;然后,PyTorch中的大多数损失函数都有weight参数,可为不同的类指定不同的权重。
62)采用过采样或欠采样技术来平衡不平衡数据集中的类别比例。
过采样:通过增加少数类样本的数量来平衡数据集,使得不同类别的样本数量更加接近;
欠采样:通过减少多数类样本的数量来平衡数据集,使得不同类别的样本数量更加接近;
上述两种途径相对,两种途径分别可有多种不同方式实现,适用情况分别为:数据集样本数量不足、充足。另外,可结合两种途径处理不平衡数据集,结合各自的优势。
17自定义激活函数
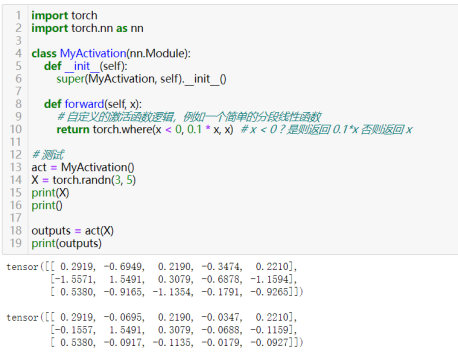
63)定义激活函数:class CustomActivation(torch.nn.Module)
实现形式和自定义网络层、自定义损失函数类似,但一般激活函数不包含需要更新的参数,只包括对输入(上一层的输出)进行非线性处理,最后的输出结果与输入在“形状”shape上保持不变(简单来说就是对输入的每个元素作映射输出,也即得到激活函数值)。
18模型集成
64)通过平均或投票结合“不同”模型进行集成学习。
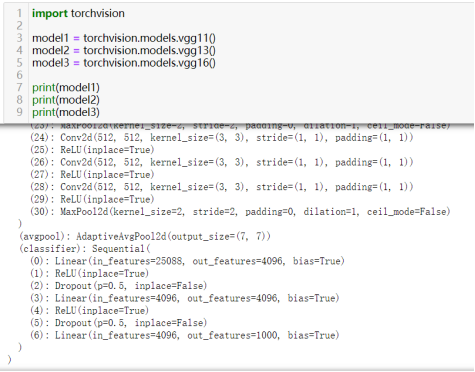
不同的模型定义
不同的含义:1、模型结构相同但参数不同;2、模型结构不同(here e.g.)
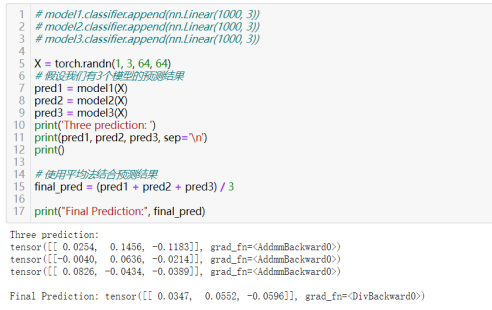
平均法
其实平均法通常用于回归问题,将多个模型的预测结果取平均值作为最终的预测结果
投票法通常用于分类问题,其中每个模型提供一个预测类别,然后计算每个类别得到的票数,票数最多的类别作为最终的预测结果。或者(适用只得到top1类别的):
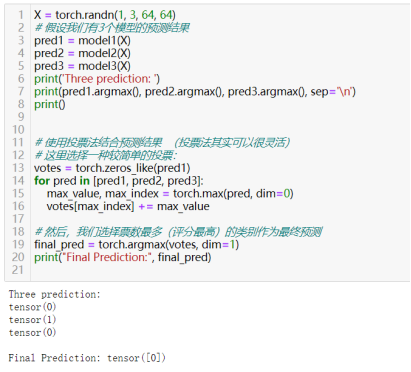
65)实现堆叠技术以组合模型。
基本步骤:
a.定义各个基础模型
首先,你需要定义一些基础的模型。这些模型可以是任何神经网络结构
b.创建堆叠模型
创建一个新的模型,它将包含所有基础模型的实例,并通过适当的连接方式将它们的输出组合起来。这可以通过简单地堆叠模型的输出或使用更复杂的组合策略来实现。
c.实例化模型并训练
实例化你的堆叠模型,并使用适当的损失函数和优化器进行训练。
19理缺失数据
66)使用掩码张量处理缺失数据。
掩码张量是一种与数据张量形状相同的布尔型张量,用于标记哪些数据是有效的(通常为True),哪些数据是缺失的或需要被忽略的(通常为False)。
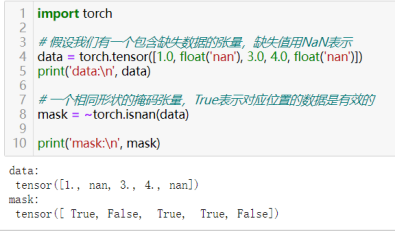
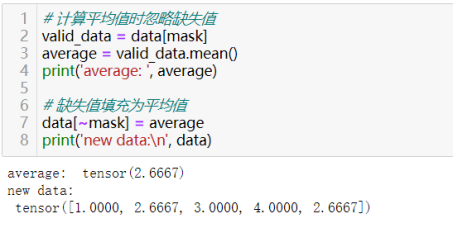
有了掩码张量之后,可用它来对数据进行各种操作,如计算平均值时忽略缺失值,缺失值处理(缺失值填充)等。
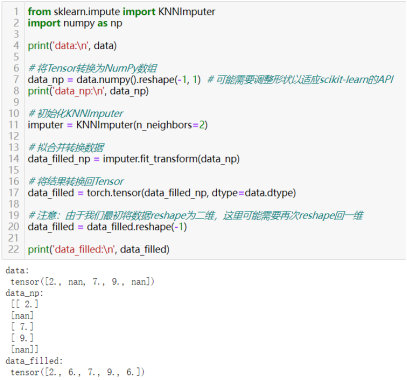
67)使用插补技术处理缺失数据。
在PyTorch中处理缺失数据时,插补(imputation)是一种常用的技术,用于填充数据中的缺失值。插补技术有很多种,包括简单插补(如均值插补、中位数插补、众数插补)、线性插补、K近邻插补(KNN)等。
PyTorch中并没有直接提供所有类型的插补函数,但可使用PyTorch的Tensor操作和NumPy库,或者结合pandas等其它第三方库来实现插补。
简单插补:适用非缺失值的均值、中位数、众数等填充缺失值;
线性插补:用于在两个已知点之间估计未知点的值。它通过计算目标点与起点之间的线性关系(即直线斜率)来确定插值点的值。线性插补通常用于时间序列数据,但在其他类型的序列数据中也可以使用。
K近邻插补(KNN插补):一种基于K近邻算法的插值方法,用于处理数据中的缺失值。它利用与缺失值最近的K个观测值来估计缺失值。适用于处理具有复杂关系的数据集,特别是在缺失值比例不高且数据分布相对均匀的情况下。

20导出到ONNX
68)将PyTorch模型转换为ONNX格式以提高互操作性:torch.onnx.export(…)
ONNX(Open Neural Network Exchange)是一个开放的深度学习模型交换格式,旨在促进不同深度学习框架之间的互操作性。通过将PyTorch模型转换为ONNX格式,可以更容易地将模型部署到支持ONNX的其他平台或框架上,如TensorFlow、Caffe等。
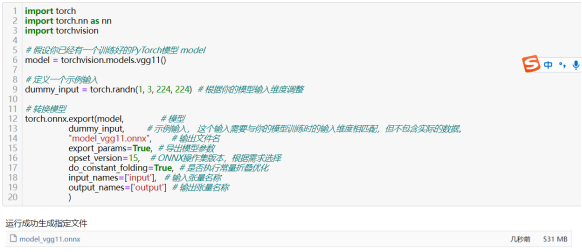
使用ONNX库中的onnx.checker.check_model函数验证转换后的ONNX模型是否有效。先下载ONNX库:pip install onnx

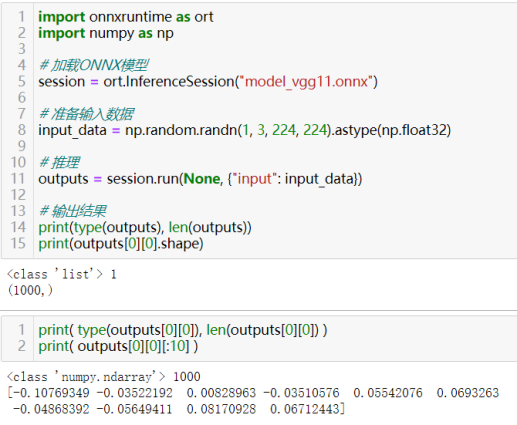
69)使用ONNX在边缘设备上部署PyTorch模型。
一般步骤:
- 将PyTorch模型转换为ONNX格式:(以上述保存的model_vgg11.onnx为例)
- 在边缘设备上安装ONNX Runtime:ONNX Runtime是一个高性能的推理引擎,支持多种硬件平台,包括CPU、GPU和边缘设备上的特定硬件加速器。在边缘设备上安装ONNX Runtime,并确保它与你的设备兼容。
- 加载ONNX模型并使用ONNX Runtime进行推理:使用ONNX Runtime的API加载ONNX模型。
- 准备输入数据,并将其转换为ONNX模型所需的格式。
使用ONNX Runtime的推理API进行模型推理,并获取输出结果。
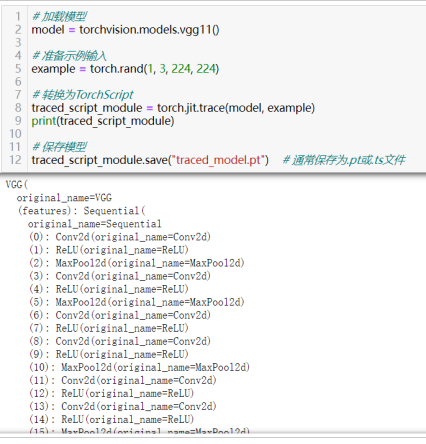
21导出到TorchScript
70)将PyTorch模型转换为TorchScript以优化部署:torch.jit.trace(model, example)或torch.jit.script(my_model)
TorchScript是PyTorch的一个功能,它提供了一种将PyTorch模型转换为中间表示(IR)的方式,这种中间表示可以在不依赖Python解释器的情况下运行,从而优化模型的部署和推理性能。
使用torch.jit.trace函数通过示例输入来记录模型的行为,并生成TorchScript。这种方法适用于模型结构中不包含控制流(如if语句、循环等)或控制流不依赖于模型输入的模型。看例子:
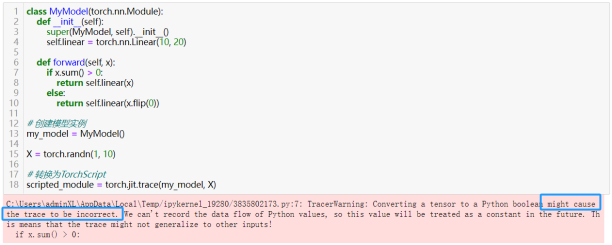
对于包含控制流的模型,或者当跟踪不足以捕获模型行为时,可以使用脚本化方法。如上述中的MyModel模型,使用torch.jit.script函数将模型转换为TorchScript。
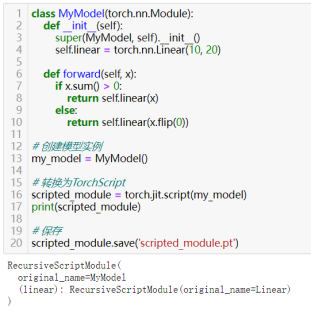
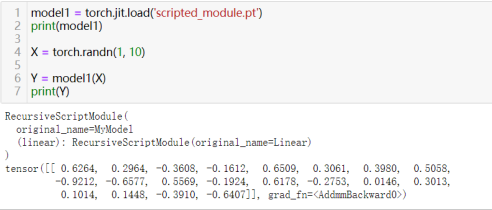
部署TorchScript模型时,可以在不依赖Python解释器的情况下运行,例如在C++中使用LibTorch,或者在Python中使用torch.jit.load加载模型进行推理。要使用上述保存的xxx.pt模型文件
更多学习资料后续更新可以关注微信公众号——分享之心
















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









