







Xception: Deep Learning with Depthwise Separable Convolutions,在这篇文章中应用了深度可分离卷积。对于卷积来说可以看作三维的滤波器:通道维度+空间维度,常规的卷积就实现空间相关性和通道相关性。传统的卷积就是把所有通道当作一个整体来进行卷积,而在Xception文章中把通道数进行分组然后再卷积,然后再联合。
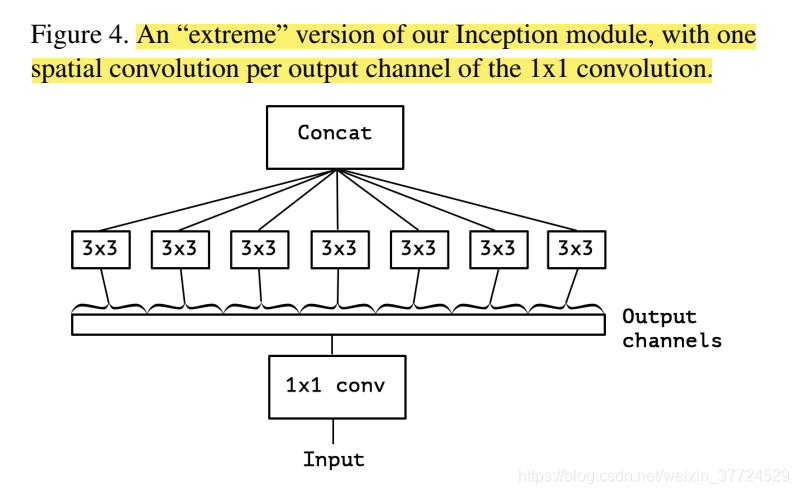
这幅图和Xception最接近,先进行1*1的卷积,然后再每个通道上进行3*3的卷积。将这个结果Concat起来就是卷积的结果,当然这也是一个可分离的卷积过程。 当Figure4和本文中还是有一点差别的:
- 深度可分离是先进行每个通道的卷积,然后得到结果concat起来,再进行1*1的卷积
- Inception中,每个操作后会有一个ReLU的非线性激活,深度分离是没有。

Xception的整体框架如下:
可以看到使用了残差网络的结构;接下来就聊聊每个模块中都用的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1737
1737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









