







第三章 uvm 核心类
1 uvm_void 只是一个virtual class,需要基层的子类完成相关功能,子类有uvm_object和uvm_port_base
2 uvm_object 提供的方法的相关的宏操作,主要提供核心方法:copy() clone() compare() print() pack/unpack
3 域的自动化(field_automation),通过域的自动化,可以直接调用uvm_object的相关方法;
`uvm_object_utils_begin(box)
`uvm_filed_int(a,UVM_ALL_ON)
`uvm_object_utils_end;
4 copy 已经创建好对象了,只需要对数据进行拷贝,属于深拷贝;clone会自动创建对象,并进行数据拷贝;
5 full_name 指的的是component所处的完整层次结构。
6 uvm_coreservice_t类
7 `uvm_component_utils调用过程中,实现类型定义 typedef uvm_object_register #(T,Tname) 充当代理,在创建实例的时候将实例的句柄和名字name放在一个关联数组中,当需要创建实例时,先从global_tab中找到name索引对应的实例指针,然后调用new函数。
factory机制实际上是对sv中new方法进行重载,根据类名创建实例。
typedef uvm_object_registry#(T,Tname) type_id;
class register#(type T = uvm_object,Tname = "");
T inst;
string name = Tname;
endclass
class driver;
typedef register#(driver,"driver") type_id;
local static type_id
static function type_id get();
if(me != null) begin
me = new();
global_tab[me.name] = me;
end
return me;
endfunction
function uvm_component create_component_by_name(string name);
register#(uvm_object,"") ptr;
ptr = global_tak[name];
ptr.inst = new("uvm_test_top",null);
return ptr.inst;
endfunction
endclass
第四章 TLM 通信
1 tlm 是基于事务transaction的通信方式
2 就单向端口而言,声明port和export作为request发起者,需要指定transaction 类型
3 put: 通信发起者A把一个transaction发送给B。A为port,用方框表示;B为Export(extend port),用圆圈表示。数据流的方向从A到B; get: A向B索要一个transaction。A依然是发起者,B为“目标”。数据流的方向从B到A。Note: Port 和 Export体现的是控制流,发起者为port,而export只能被动的接收port的命令;transport:transport相当于一次put操作和get操作
4 uvm中使用connect()来建立连接关系,只有发起者才能调用connect(),而被动承担者充当connect()函数的参数。A_port和B_export都充当一道门,只有通行作用,没有存储作用。因此transaction必须由B_export后续的某个组件进行处理。关键要在B中实现一个put的函数或者任务。
A.port.connect(B.export);
B.connect(B.imp);
// transaction flow
当组件调用A.port.put(t)时,可以理解为A.port.put(t) 会调用B.export.put() -> B.IMP.put(t)-> B中的put()
5 在uvm 中只有IMP 才能作为连接关系的终点,如果是PORT或EXPORT作为终点则会报错。
6 analysis port 和 analysis export与get和put系列的端口之间的区别:
- analysis port 可以连接多个imp,可以实现一对多的通信。而put和get是一对一的
- analysis port 没有blocking和noblocking区分,因为其本身就是广播,不必等待其他端口的响应。
- analysis port 只有一种操作:write()。在analysis_imp所在的component中必须有一个名为
write的函数
7 如果一个component中有多个imp,由于接收到的数据应该做不同的处理,因此每个imp都应该对应一个write() 函数,这时需要定义一个宏`uvm_analysis_imp_decl(_monitor)
8 fifo 通信端口的本质是一个缓存和两个IMP。 下图圆圈export的本质还是IMP; get() 任务被调用会从缓存中拿走一个transaction;peek会把transaction复制一份,内部transaction不会减少。其通信机制为:当FIFO的blocking_put_export 或者put_export被连接到blocking_put_port或put_port上,fifo内部定义的put 任务就会被调用,这个任务会把传递的transaction放入fifo 内部,同时把这个transaction通过put_ap使用write()函数发送出去。
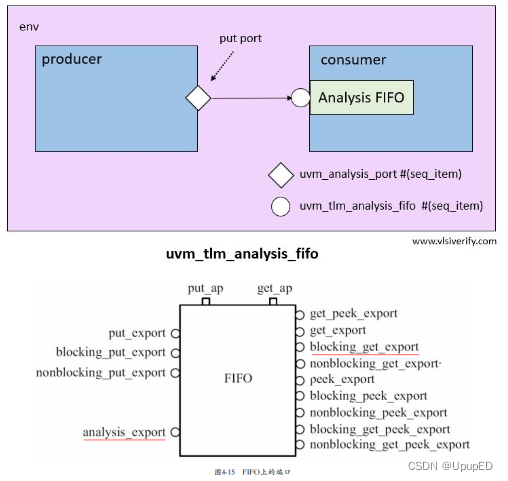
class scb;
uvm_blocking_get_port#(trans) exp_port;
endclass
class env;
uvm_tlm_analysis_fifo#(trans) agt_scb_fifo;
function void connect_phase(...);
agt.ap.connect(agt_scb_fifo.analysis_export);
exp_port.connect(agt_scb_fifo.blocking_get_export);
endfunction
endclass
9 uvm_tlm_analysis_port 和 uvm_tlm_fifo 的区别在于,uvm_tlm_analysis_port存在一个analysis_export端口,并且有一个write函数。
第五章 phase 机制
1 sv 在构造验证环境时,面临层次化先后顺序,以及组件例化后连接的问题。phase机制的引入将uvm仿真阶段层次化。有9个主要的phase,run_phase任务和细分的12个phase 并行。
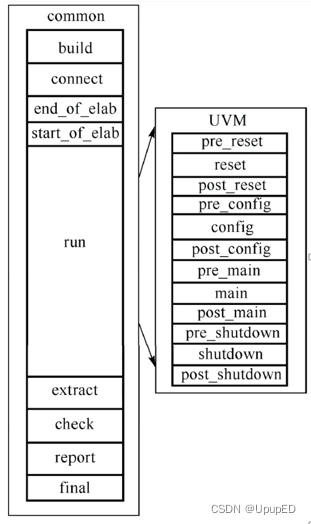
2 build phase 执行顺序是自上而下的。这也符合验证结构建设的逻辑。因为只有先例化高层组件,才会创建空间来容纳底层组件。其他function phase都是自下而上执行的。对于connect_phase,先执行drive和monitor的connect_phase,再执行agent的connect_phase。
3 类似run_phase、main_phase、task_phase是自下而上的启动,同时在运行。
3 uvm编译的运行顺序:首先在调用仿真器之前,需要完成编译的建模阶段,然后在仿真之前,会分别执行硬件的always、initial语句,以及uvm的调用测试方法run_test和几个phase(build、connect、end_of_elaboration和start_of_simulation),开始仿真后执行run_phase() 或者12个细分的phase;仿真结束后,将会执行剩余的phase,分别是extract、check、report、final
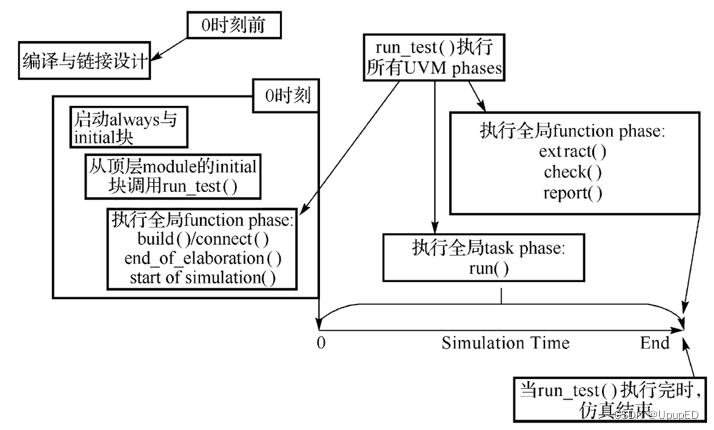
4 建立验证环境可以通过全局函数run_test()来选择需要运行的uvm_test。指定的test 将作为顶层组件。如何run_test()没有传递参数,可以在仿真时通过+UVM_TESTNAME=testname来指定test。
5 uvm 顶层类uvm_root继承于uvm_component,只有一个顶层类uvm_root所例化的对象,即uvm_top。
6 uvm结束仿真的机制是利用objection挂起机制来控制仿真结束,uvm_objection 类提供一种供所有component和sequence 共享的计数器,参与到objection机制的组件,可以独立的各自挂起objection,来防止run_phase()退出,在组件中落下objection后,uvm_objection共享的counter才会变0,意味着run_phase满足退出条件
7 在进入到某一task phase,uvm会收集此phase提出的所有objection,并且会监测所有phase是否已经撤销了,当发现所有都已经撤销后,就会关闭此phase,然后开始进入下一个phase。当所有phase都执行完毕,就会调用$finish将整个验证平台关闭掉。如果uvm发现此phase没有提起任何objection,那么将会直接跳转到下一个phase
8 run_test() 是一个任务,首先会获取uvm_root的单个实例uvm_top; 然后testcase的名字,创建testcase实例uvm_test_top;最后启动uvm_phase
task run_test(string test_name = "");
uvm_root top;
uvm_convervice_t cs;
top = cs.get_root();
top.run_test(test_name);
endtask
第六章 sequence
1 将激励放在driver 中生成,扩展性太差
2 sequence 通过start任务在目标sequencer上启动,启动后会自动调用body任务。除了body还会调用sequence的pre_body 和 post_body
3 `uvm_do_on(SEQ_OR_ITEM,SEQR) 用于显示地指定使用哪个sequencer发送transaction。
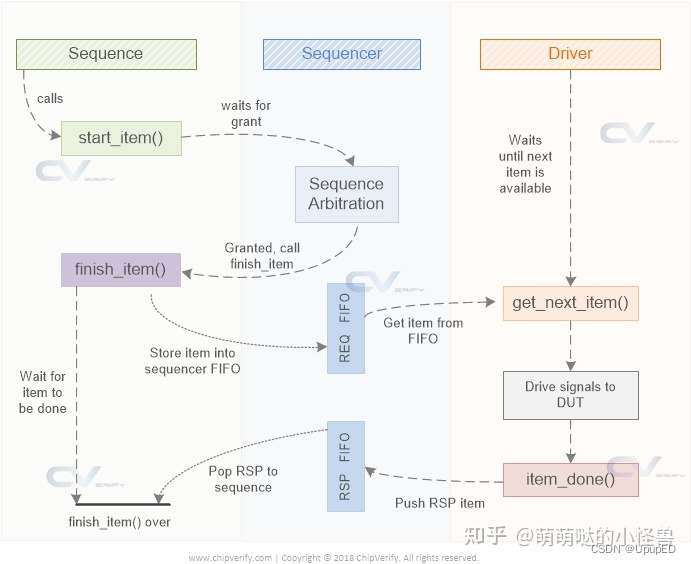
4 item 声明周期起始于sequence的body,而后经历随机化后穿越sequencer最终到达driver,被driver消化后,其生命周期结束。
5 sequence可以包含有序组织起来的item序列,考虑到item 创建后需要随机化,sequence在声明时也需要预留一些可供外部随机化的变量,通过层级传递约束,最终控制item 对象的随机变量。
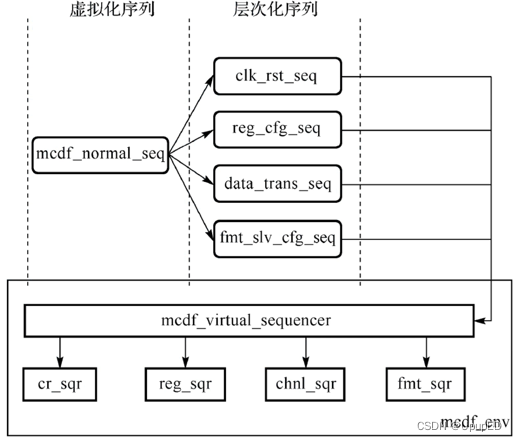
6 sequence可以分为flattern (扁平),主要包含item实例。层次(hierarchical sequence) 由更高层次的sequence来组织底层的sequence,进而让这些sequence按照一定顺序挂在到sequencer上,可以包含sequence和item。
7 底层sequence(clk_rst_seq, reg_test_seq) ,或element sequence。top_seq (可以称为hierarchical seq)可以容纳更多的sequence,并对它们进行协调的随机限制,通过对这些element sequence进行有机调度,从而完成一个期望的测试场景。
8 hierarchy seq 和 virtual sequence 共同点是都会对sequence 进行协调;它们的不同点在于hierarchy seq 中的seq 时同一个sequence,即hierarchy seq 会挂载到sequencer 上面。virtual sequence内部的sequence 可以面向不同的sequencer。
9 在uvm_test 中将virtual sequence 挂载到virtual sequencer上面,其目的是为了给virtual sequence提供一个中心化的路由。借助vseq 中的p_sequencer变量,可以在vseq中使用virtual sequencer内部的sequencer句柄。
10 每个sequence都有m_sequencer(uvm_sequencer_base)的成员变量 ,当sequence启动start()任务时会调用set_sequencer()方法,将m_sequencer的句柄指向当前sequence挂载的sequencer 上。
// uvm_sequence_base
task start(uvm_sequencer_base sequencer,...);
...
set_sequencer(sequencer);
endtask
// uvm_sequence_item
virtual function void set_sequencer(uvm_sequencer_base sequencer);
m_sequencer = sequencer;
m_set_p_sequencer();
endfunction
virtual function void m_set_p_sequencer;
return;
endfunction
11 `uvm_declare_p_sequencer(SEQUENCER) 本质上声明了一个SEQUENCER 类型的p_sequencer成员变量,之后会将m_sequencer通过$cast 动态转化成p_sequencer
`uvm_declare_p_sequencer(virtual_sequencer)
// 宏定义
`define uvm_declare_p_sequencer(SEQUENCER) \
SEQUENCER p_sequencer;\
virtual function void m_seq_p_sequencer()
if(!$cast(p_sequencer,m_sequencer))
`uvm_fatal("DCLPSQ") \
endfunction
7 虚拟sequence(virtual sequence) 协调和控制测试场景,之所以为virtual sequence,因为该序列本身不会挂载于某个sequencer上,而是其内部不同类型的sequence最终挂载到不同的目标sequencer。
8 sequencer和driver 之间通过tlm端口进行传递
driver:
uvm_seq_item_pull#(REQ,RSP) seq_item_port;
uvm_analysis_port#(RSP) rsp_port;
sequencer:
uvm_seq_item_imp#(REQ,RSP,this type) seq_item_export;
uvm_analysis_export#(RSP) rsp_export;
driver 通过task get_next_item(output REQ req): 采用blocking的方式等待从sequence获取下一个item。
function item_done(input RSP) 通知sequence 当前sequence item 已经消化完毕,可以选择性传递RSP参数。
driver 也可以通过put_response()或者put() 方法单独发送response
9 sequencer 和 driver 都是参数化的类:
uvm_sequencer#(type REQ = uvm_sequence_item,RSP=REQ)
uvm_driver#(type REQ=uvm_sequence_item,RSP=REQ)
driver 得到REQ 对象的时候,需要进行动态转化,将REQ转化为uvm_sequence_item 的子类型才能从中获取有效的成员数据。
8 不使用宏来产生transaction要依赖两个任务:start_item 和 finish_item。使用者两个任务之前,需要先实例化transaction。create_item() 创建request item 对象,start_item()方法告诉sequencer当前sequence时有效,可以得到授权。finish_item()将item存放在sequencer的FIFO中;
第七章 uvm 寄存器模型
1 寄存器是模块之间相互交谈的窗口,可以通过寄存器读处当前硬件的状态,还可以配置寄存器。
2 当个寄存器可以拆分为多个域,不同的域代表某一项独立的功能。单个域可以有单个bit或者多个bit 构成。
3 寄存器建模:
- 将寄存器的各个域整理出来,然后调用uvm_reg_field::configure()函数配置各自的属性
- uvm_reg_block 可以模拟一个功能模块的寄存器模型,map的作用表示寄存器的地址;在reg_block中创建uvm_reg后,还需要调用uvm_reg::configure()去配置各个uvm_reg实例的属性
- uvm_reg_map需要在uvm_reg_block中例化,在例化后需要通过uvm_reg_map::add_reg()来添加uvm_reg对应的偏移地址和访问属性
- 在还没有集成predictor之前,可以采用auto predictor,因此需要调用uvm_reg_map::set_auto_predict(1),这种预测方法需要依赖于driver,当driver完成数据驱动后,寄存器模型自动跟新镜像值和期望值。
- 在顶层环境connect阶段,需要将通过uvm_reg_map::set_sequencer()将map与bus_sequencer和adapter连接。
4 寄存器模型前门访问
寄存器操作有两种方法:
1. uvm_reg::write,需要将参数path指定为UVM_FRONTDOOR
1. uvm_reg_sequence::read_reg()/write_reg
class ex_seq extends uvm_reg_sequence;
rgm_block ral;
task body();
uvm_status_e status;
uvm_reg_data_t data;
// register module access write/read
ral.ctrl.en.write(status,data,UVM_FRONTDOOR,this);
ral.ctrl.en.read(status,data,UVM_FRONTDOOR,this);
// pre-define method access
read_reg(ral.ctrl,status,data,UVM_FRONTDOOR);
write_reg(ral.ctrl,status,'h04,UVM_FRONTDOOR);
endtask
endclass
5 在后门访问时,首先需要确保寄存器模型建立时,将寄存器映射到dut一侧的hdl路径;
uvm_reg_block::add_hdl_path,将寄存器模型关联到dut一端,而通过uvm_reg::add_hdl_path.slice完成寄存器与hdl一侧的地址映射。
build函数以lock_model()结尾,表明结束地址映射关系,模型不会被外部修改。
后门访问的方法:uvm_reg::read/write,需要指名UVM_BACKDOOR的访问方式
uvm_reg_sequence::write_reg/read_reg
uvm_reg::peek、pock,读取寄存器(peek) ,修改寄存器(pock),这两种方法只针对后门访问。
6 实际应用场景: 1) 有时候存在地址不匹配的情况,先读后写无法有效测试出错误,可以通过前门配置寄存器,然后通过后门访问来判断hdl地址映射的寄存器变量值是否改变,最后通过前门访问读取寄存器的值.
7 寄存器常规方法:
mirrored value: 硬件寄存器已知的状态值
desired_value: 用来更新硬件寄存器的值
actual_value: 硬件的真实数值
8 自动预测(auto-predictor)利用寄存器的操作来自动记录每次寄存器读写数值,并在后台自动调用predict()方法,如果出现其他的sequencer对通过总线对寄存器进行操作,或者通过其他总线对寄存器进行操作,都无法自动得到寄存器的mirrored 和 actual value
9 显示预测,通过总线监视器来捕捉总线事务,并将事务传递给predictor。集成过程中adapter与map的句柄也要传递给predictor,并且monitor采集的事务要通过analysis port 接入到predictor
10 uvm_reg 操作方法
uvm_reg_sequence提供的方法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i7fHzZfA-1676211924972)(C:/Users/WY/AppData/Roaming/Typora/typora-user-images/image-20221120221156060.png)]
通过前门访问,在总线事务完成后,镜像值和期望值才会更新与总线上相同的值
对于peek和poke,以及后门访问write、read,由于不通过总线,默认采用自动预测,方法调用完成后,镜像值和期望值也相同。
mirror()与read()类似,可以通过前门和后门,不同的是mirror不会返回读回的值,但是会修改对应的镜像值,可以将读回的值和模型原镜像值进行比较
ral.ctrl.mirror(status,UVM_CHECK,UVM_FRONTDOOR,this);
set() 修改期望值,可以先随机化,然后配置寄存器的其他域,当寄存器的期望值和镜像值不同,可以通过update()对硬件寄存器进行修改。
get() 获取期望值
ral.ctrl.randomize();
ral.ctrl.en.set(4'b1111);
ral.ctrl.update(status,UVM_FRONTDOOR,this);
11 寄存器覆盖率收集
1. coverage自动生成
uvm的寄存器模型已经内置了一些方法用来使能对应的covergroup,同时在调用write或者read方法时,会自动调用covergroup::sample来完成功能覆盖率收集.
在uvm_reg的构造函数中。通过set_coverage来判断是否需要例化,该方法会查看uvm_reg::m_has_cov
在新扩充的sample和sample_values函数可以看成时read、write函数的回调函数,用户需要填充该方法,可以保证自动采集数据,
class ctrl_reg extends uvm_reg;
rand uvm_reg_field en;
function new(string name = "ctrl_reg");
super.new(name,32,UVM_NO_COVERAGE);
set_coverage(UVM_CVR_FIELD_VALS);
if(has_coverage(UVM_CVR_FIELD_VALS)) begin
value_cg = new();
end
endfunction
covergroup value_cg;
option.per_instance = 1;
en: coverpoint en.value[0:0];
endgroup
function void sample(
uvm_reg_data_t data,
uvm_reg_data_t byte_en,
bit is_read,
uvm_reg_map map);
super.sample(data,byte_en,is_read,map);
sample_value();
endfunction
function void sample_values();
super.sample_value();
if(get_coverage(UVM_CVR_FIELD_VALS)) begin
value_cg.sample();
end
endfunction
endclass
- 自动收集覆盖率的形式不够灵活,它默认采样所有的域,包括哪些保留域。我们可以自定义cover group,一方面限定感兴趣的域和值,一方面指定采样事件
class coverage uvm_subscriber#(bus_trans);
rgm_block ral;
covergroup reg_value_cg;
option.per_instance = 1;
chnl1: coverpoint ral.ctrl_reg.en.value[0:0] {
bins len[] = {0,1,2,4,[4:7];}
}
endgroup
function new(string name,uvm_component parent);
super.new(name.parent);
reg_value_cg = new();
endfunction
function void write(T t);
reg_value_cg.sample();
endfunction
endclass
class ctrl_reg extends uvm_reg;
rand uvm_reg_field en;
function new(string name = "ctrl_reg");
super.new(name,32,UVM_NO_COVERAGE);
endfunction
function void build();
en = uvm_reg_filed::type_id::create("en");
en.configure(.parent( this ),
.size ( 1 ),
.lsb_pos ( 5 ),
.access ( "WO" ),
.volatile ( 0 ),
.reset ( 0 ),
.has_reset ( 1 ),
.is_rand ( 1 ),
.individually_accessible( 0 ) ););
endfunction
endclass
class rgm_block extends uvm_reg_block;
rand ctrl_reg ctrl;
function new(string name = "rgm");
super.new(name,UVM_NO_COVERAGE);
endfunction
function void build();
ctrl_reg ctrl = ctrl_reg::type_id::create("ctrl");
ctrl.configure(.blk_parent(this));
ctrl.build();
default_map = create_map("map",'h0,4,UVM_LITTLE_ENDIAN);
// map_name,offset,number of bytes, endianess
default_map.add_reg(ctrl,32'h0000_0000,4,"RW");
// 完成寄存器模型与dut各个寄存器的路径映射
add_hdl_path("reg_backdoor_path.dut");
ctrl.add_hdl_path_slice("reg0",'h04,0,32);
lock_model();
endfunction
endclass
class env extends uvm_env;
bus_agent agt;
rgm_block ral;
reg2bus_adapter adapter;
uvm_reg_predictor#(bus_trans) predictor;
function void build_phase(uvm_phase phase);
ral = rgm_block::type_id::create("ral");
ral.build();
ral.map.set_auto_predict(1);
adapter = reg2bus_adapter::type_id::create("adapter");
predictor = uvm_reg_predictor#(bus_trans)::type_id::create("predictor");
predictor.map = ral.default_map;
predictor.adapter = adapter;
endfunction
function void connect_phase(uvm_phase phase);
ral.map.set_sequencer(agt.sqr,adapter);
agt.mon.ap.connect(predictor.bus_in);
endfunction
endclass
第九章 UVM 代码可重构性
1 callback机制最大的用处就是提高验证平台的可重构性,通过提供一些接口满足需求。
-
首先需要定义一个类A,继承于uvm_callback,然后在这个类中声明一个virtual task,A派生类可以对这个任务进行重载。
-
然后要声明一个池子,专门存放A或者A派生类的一个池子。
class A extends uvm_callback; virtual taks pre_trans(drive,transaction tr); endtask endclass -
`uvm_register_cb(driver,A) 在组件中注册uvm_callbak
-
`uvm_do_callbacks(drive,A,pre_trans())在组件中嵌入callback任务
-
对回调类的回调方法进行重载
-
在测试用例中实例化callback对象
-
调用uvm_callbacks#(T,CB)::add::(t,cb)
T:表示回调类所在的组件名,即实现Callback机制的组件名,回调类与组件类在同一组件文件中;
CB:表示空壳回调类的类名;
t:表示回调类所在的组件的实例名,也就是组件的对象名;
cb:表示回调类的实例名,也就是对象名;
2 uvm_event
上面示例通过uvm_event_pool::get_global(“e1”)来获取同一个名称的uvm_event对象,即使该对象不存在,uvm_event_pool资源池会在第一次调用get_global()函数时创建一个对象
uvm_event 与 event的区别:
- event被->触发后,会触发使用@等待该事件的对象;uvm_event通过trigger()触发,会触发使用wait_trigger()等待该事件的对象
- 如果要再次等待事件触发,event只需要再次用->来触发,而uvm_event需要reset()方法重置初始状态,再使用trigger()来触发
- event不能携带更多信息,而uvm_event可以通过trigger(T data = null)的可选方式将伴随触发的数据对象都写入到该触发事件中,而等待该事件的对象可以通过wait_trigger_data(output T data)来获取事件触发时写入的数据对象
- event 触发时无法直接触发回调函数,而uvm_event可以通过add_callback(uvm_event_callback cb,bit append =1)函数来添加回调函数
- event无法直接获取等待它进程的数目,而uvm_event可以通过get_num_waiters()来获取等待它的进程数目
用途
- uvm_object与uvm_component之间的同步
- sequence与sequence之间的同步,或者sequence与driver之间的同步















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









