






使用 PAI-EAS 简化大型语言模型的部署和集成
本文提供了使用人工智能平台-弹性算法服务部署大型语言模型(LLM)应用程序的全面指南。
本文详细介绍了如何使用 PAI-EAS(人工智能平台-弹性算法服务)部署大型语言模型(LLM)应用。部署过程支持 WebUI 界面和 API 调用。部署后,LLM 应用可以与 LangChain 框架集成,形成企业知识库,详情请见此处。PAI-EAS 还提供 BladeLLM 和 vLLM 等推理加速引擎,实现高并发和低延迟。
背景
随着 GPT 等大型模型的日益普及,LLM 应用程序的部署也成为一项抢手的服务。目前有许多开源大型模型可供选择,每个模型在不同专业领域都表现出色。PAI-EAS 简化了这些模型的部署,使在五分钟内启动推理服务成为可能。
部署 EAS 服务
要部署 EAS 服务,请按照以下步骤操作:
- 登录PAI控制台,选择工作区,选择“模型部署”>“模型在线服务(EAS)”,进入PAI-EAS模型在线服务页面;
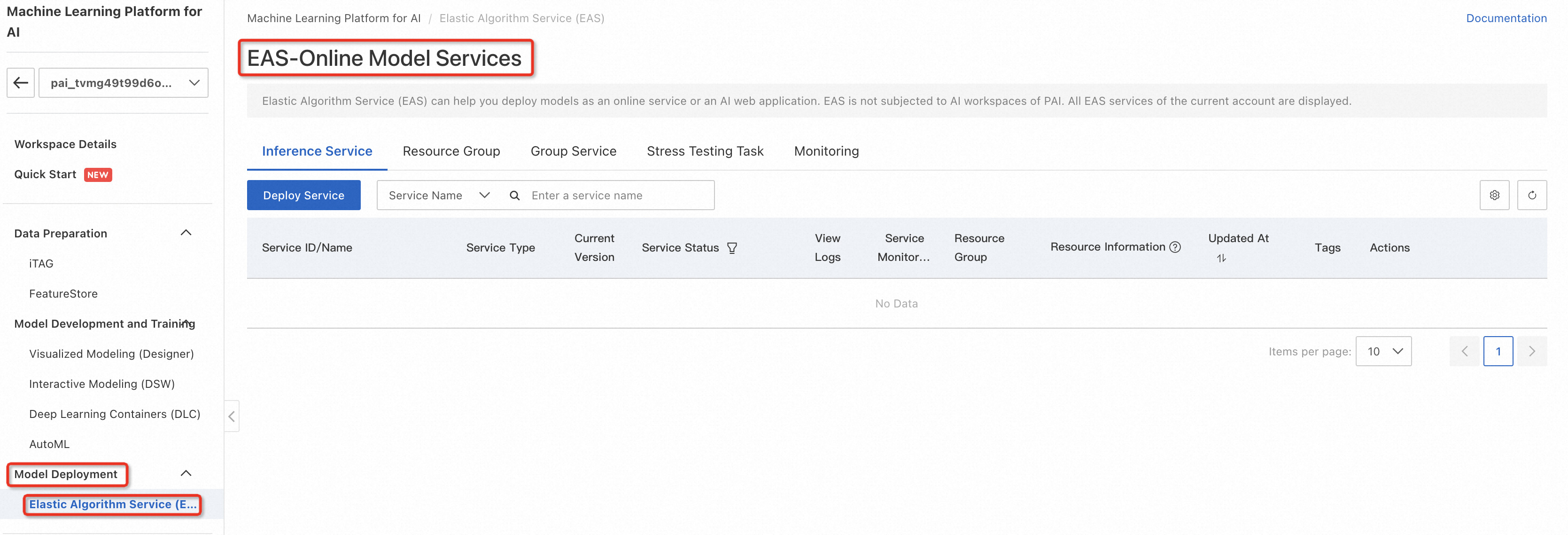
单击*“部署服务” ,配置服务名称(例如 llm_demo001)、部署方式(使用镜像部署 Web 应用)、*选择镜像(从 PAI 平台镜像列表中选择)等关键参数。
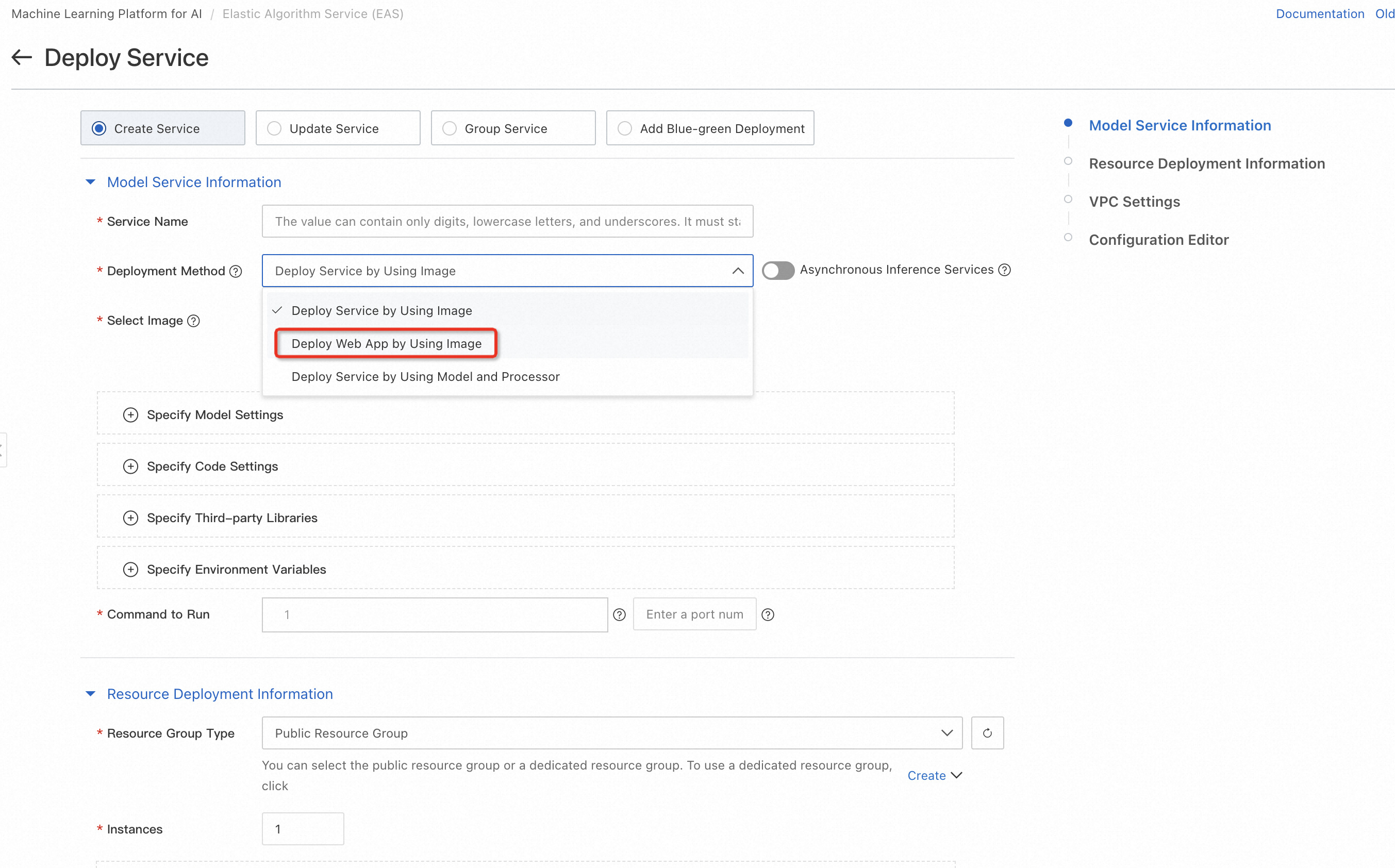
| 范围 | 除漆 |
|---|---|
| 服务名称 | 自定义服务的名称。本示例使用的示例值为 llm_demo001。 |
| 部署方法 | 选择镜像部署AI-Web应用。 |
| 图像选择 | 在PAI平台镜像列表中,选择_chat-llm-webui_,镜像版本选择2.x(目前最新版本为2.1), 由于版本迭代较快,部署时可以选择最高版本的镜像。 |
| 运行命令 | 运行命令(默认拉起Universal-7B参数量的大模型):python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen-7B-Chat 端口号:8000 一键拉起更多开源大模型的命令见下表。 |
| 资源组类型 | 选择一个公共资源组。 |
| 资源配置方法 | 选择常规资源配置。 |
| 资源配置 | GPU类型必选,统一千文-7B参数量大模型实例类型默认推荐ml.gu7i.c16m60.1-gu30(性价比最高), 模型部署推荐资源见下表。 |
- 设置运行命令,为 Universal-7B 参数模型启动所需的大型模型,例如 Qwen/Qwen-7B-Chat。
3.选择合适的资源组类型和配置,建议使用ml.gu7i.c16m60.1-gu30等GPU类型以获得最佳性能。
| 模型类型 | 运行命令 | 推荐型号 |
|---|---|---|
| Qwen-1.8B | python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen-1_8B-Chat | • 单卡 GU30 • 单卡 A10 • 单卡 V100 • 单卡 T4 |
| Qwen-7B | python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen-7B-Chat | • 单卡 GU30 • 单卡 A10 |
| Qwen-14b | python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen-14B-Chat | • 单卡 GU30 • 单卡 A10 |
| Qwen-72B | python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen-72B-Chat | • 8 张 V100 卡 (gn6e) • 2 张 A100 卡 |
| 骆驼2-7B | python webui/webui_server.py --port=8000 --model-path=meta-llama/Llama-2-7b-chat-hf | • 单卡 GU30 • 单卡 A10 |
| 骆驼2-13B | python webui/webui_server.py --port=8000 --model-path=meta-llama/Llama-2-13b-chat-hf --precision=fp16 | • 单卡 V100(gn6e) • 双卡 GU30 |
| chatglm2-6B | python webui/webui_server.py --port=8000 --model-path=THUDM/chatglm2-6b | • 单卡 GU30 • 单卡 A10 |
| chatglm3-6B | python webui/webui_server.py --port=8000 --model-path=THUDM/chatglm3-6b | • 单卡 GU30 • 单卡 A10 |
| 白楚-13b | python webui/webui_server.py --port=8000 --model-path=baichuan-inc/Baichuan-13B-Chat | • 单卡 V100(gn6e) • 两卡 GU30 • 两卡 A10 |
| 百川2-7B | python webui/webui_server.py --port=8000 --model-path=baichuan-inc/Baichuan2-7B-Chat | • 单卡 GU30 • 单卡 A10 |
| 百川2-13B | python webui/webui_server.py --port=8000 --model-path=baichuan-inc/Baichuan2-13B-Chat | • 单卡 V100(gn6e) • 两卡 GU30 • 两卡 A10 |
| 伊-6B | python webui/webui_server.py --port=8000 --model-path=01-ai/Yi-6B | • 单卡 GU30 • 单卡 A10 |
| 米斯特拉尔-7B | python webui/webui_server.py --model-path=mistralai/Mistral-7B-Instruct-v0.1 | • 单卡 GU30 • 单卡 A10 |
| 猎鹰-7B | python webui/webui_server.py --port=8000 --model-path=tiiuae/falcon-7b-instruct | • 单卡 GU30 • 单卡 A10 |
4.部署服务并等待模型部署完成。
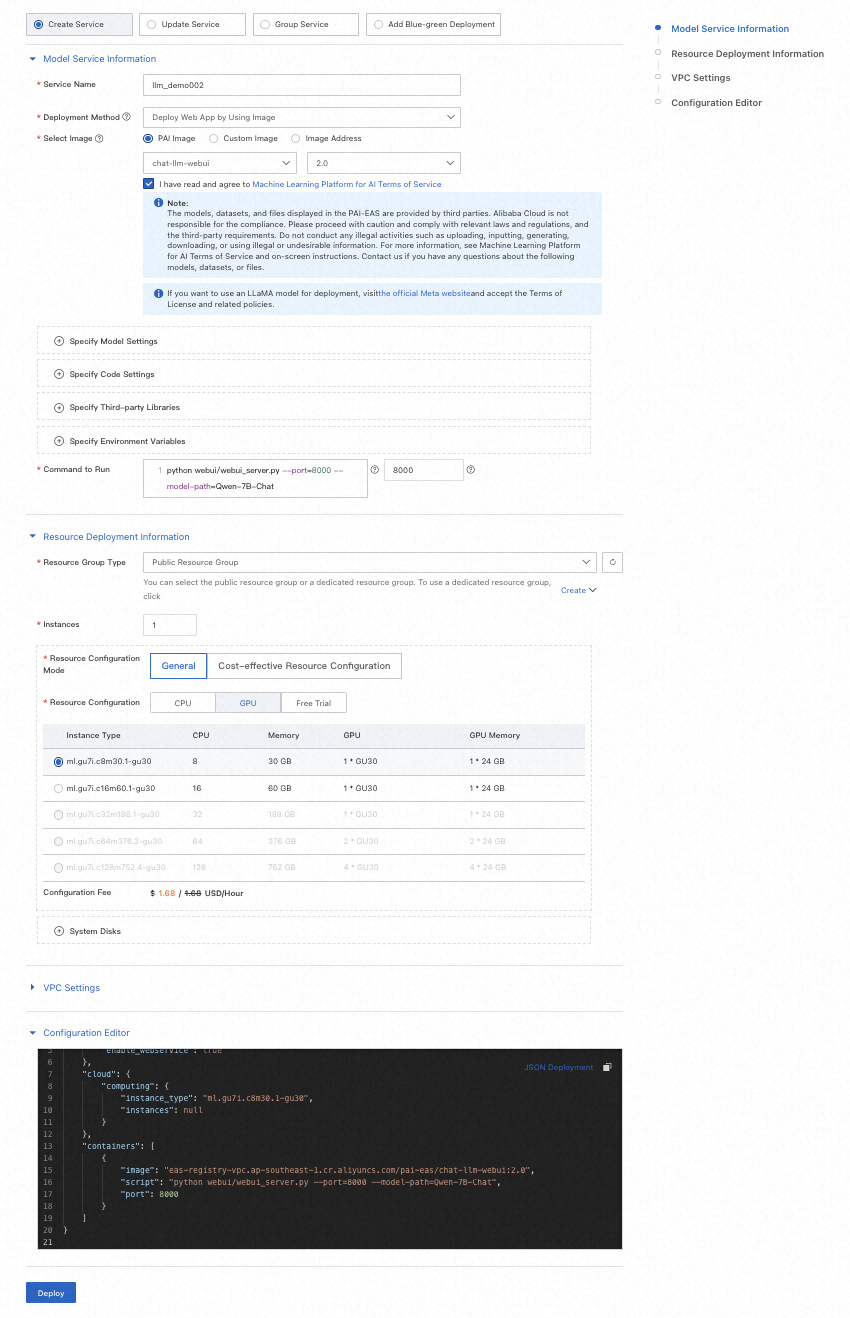
创建推理服务需要一些时间,所以让我们进入下一个有趣的环节并开始使用该服务本身。
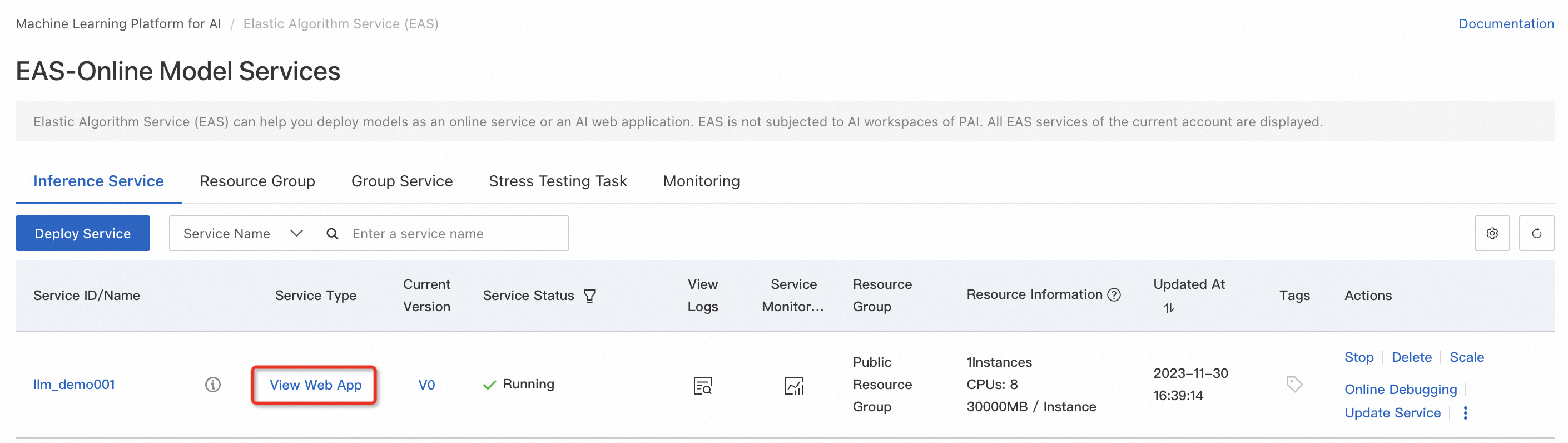
启动 WebUI 进行模型推理
服务部署完成后,使用 WebUI 界面进行模型推理验证。输入查询(如请提供财务学习计划),然后单击发送以与模型进行交互。
常见用例
**切换开源模型:**通过更新运行命令和实例规范,PAI-EAS 可以轻松在不同的模型(如统一千文、Llama2 和 chatglm)之间切换。
使用 LangChain 集成业务数据: LangChain 是一个将知识库与外部数据相结合的框架,在 WebUI 页面选择 LangChain 集成您的业务数据,按照提示上传并矢量化您的知识库文件即可。
**提升推理并发度与延迟:**运行命令增加 --backend=vllm 参数,提升并发度,降低延迟,适配部分模型,如 qwen、llama2、baichuan-13B。
**安装自定义模型:**要部署自定义模型,请将模型和配置文件上传到 OSS 存储桶,使用 OSS 安装它,方法是将模型和配置文件上传到 OSS 存储桶,使用适当的 OSS 路径更新服务,然后运行命令参数。
使用 API 进行模型推理
**获取服务访问地址及Token:**从PAI-EAS模型在线服务页访问服务详情页获取服务Token和访问地址。
**HTTP 调用:**使用标准 HTTP 或 SSE 方法通过发送带有服务 Token 和访问地址的字符串或结构化请求来调用服务。您可以使用 Python 的请求包来实现此目的。
WebSocket 调用: WebSocket 可用于维持连接和进行多轮对话,服务访问地址中的 http 替换为 ws,通过 use_stream_chat 参数控制流式输出。
本指南概述了使用 PAI-EAS 部署和使用 LLM 应用程序的整个过程,解决了常见问题,并提供了无缝集成和提高性能的解决方案。无论您是使用 WebUI 界面还是调用 API,本指南都能确保顺利部署和使用 LLM 应用程序。
使用 LangChain 与业务需求相结合
- LangChain特点:LangChain是一个开源框架,允许AI开发人员将GPT-4等大语言模型(LLM)与外部数据相结合,以尽可能少的计算资源实现更好的性能和效率。
- LangChain工作原理:将一个大型数据源,比如20页的PDF文件,分成块并嵌入到VectorDB(矢量数据库)中。
LangChain首先将输入的用户数据进行自然语言处理,存储到本地作为大模型的知识库,每次推理用户输入时,会先在本地知识库中寻找与输入问题相似的答案,并将知识库答案与用户输入一起输入到大模型中,基于本地知识库生成定制化答案。
- 设置方法:
- 在WebUI页面的右上角,选择LangChain。
- 在WebUI页面左下角,按照界面提示拉取自定义数据,可以配置txt、md、docx、pdf格式的文件。
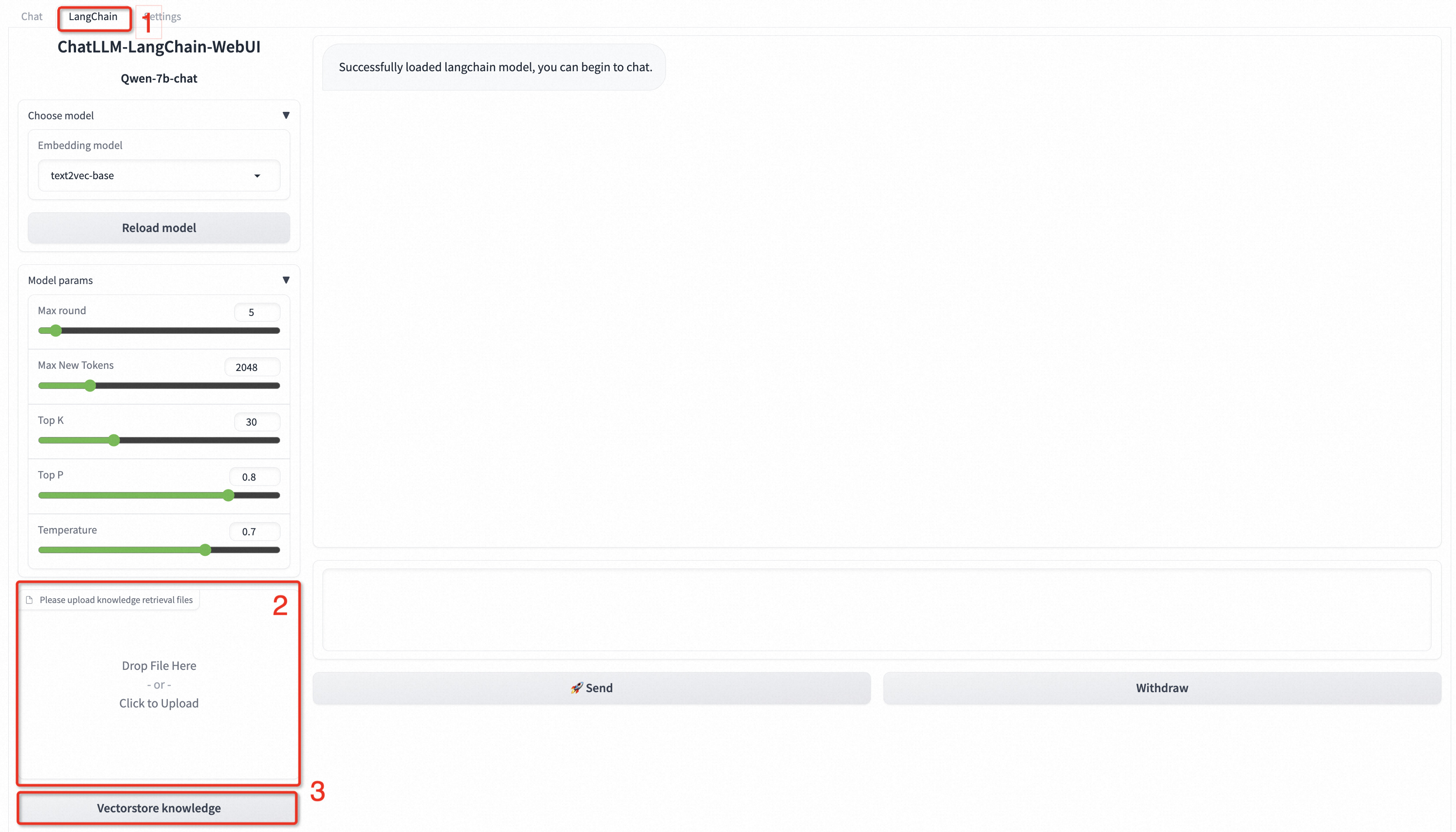
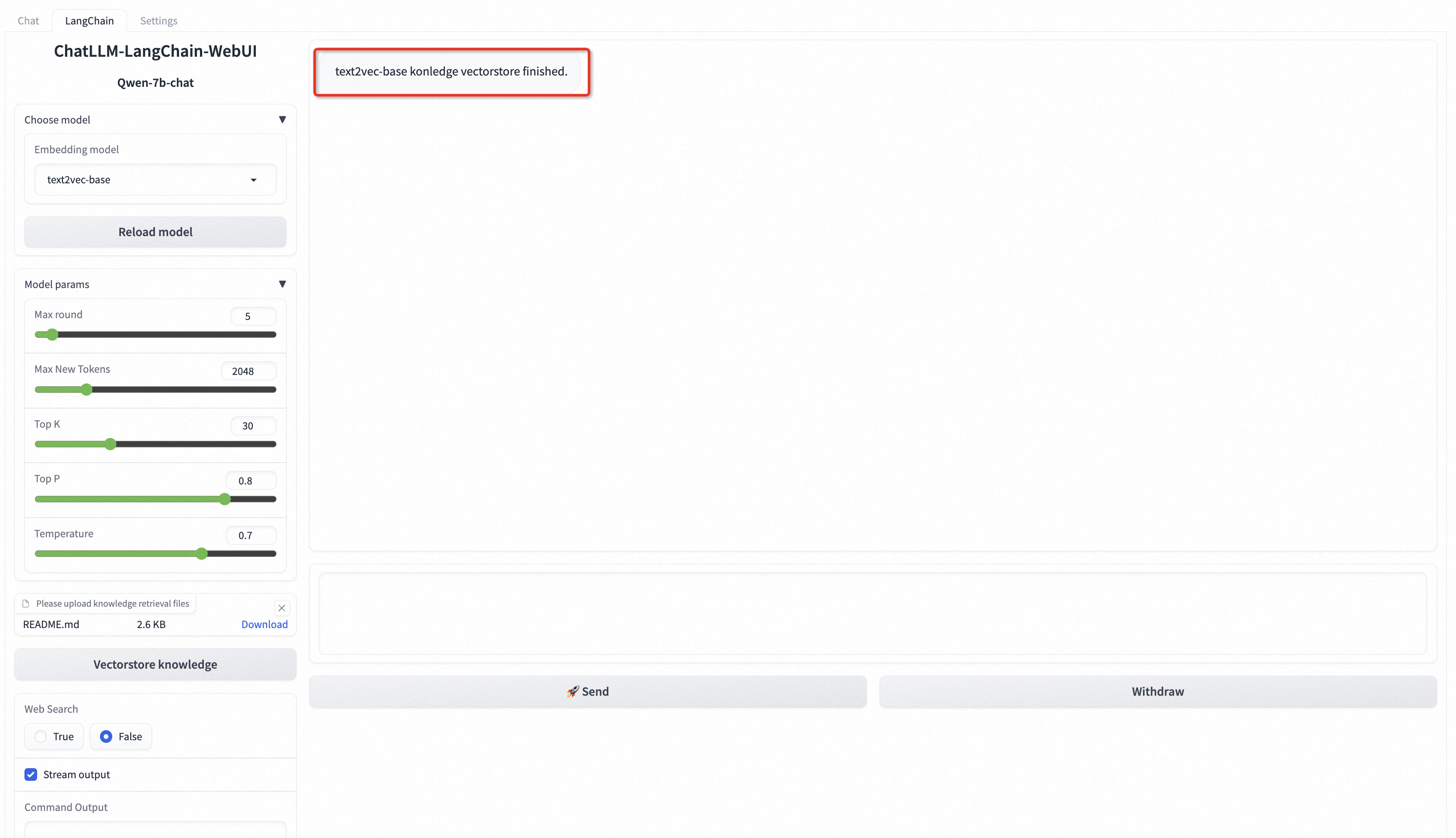
例如上传README.md文件,在左下角点击知识库文件矢量化,出现以下结果即表示自定义数据加载成功。
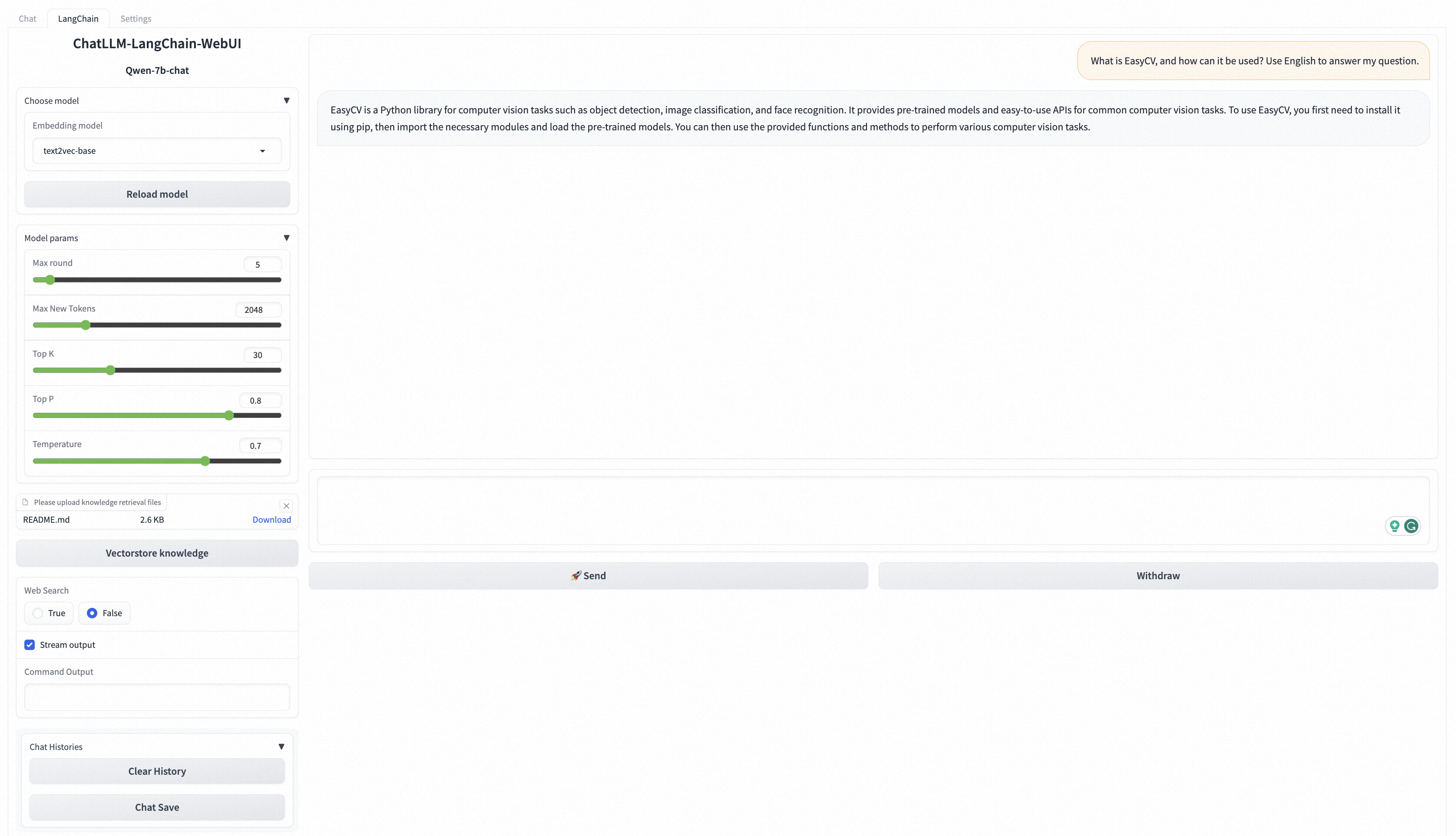
在WebUI页面底部的输入框中输入对话相关的业务数据问题。
例如在输入框中输入*What is EasyCV, and how can it be use? Use English to answer my question.,*点击发送,返回结果如下图所示。
提高推理并发性和减少延迟的方法
支持BladeLLM和vLLM的PAI-EAS推理加速引擎,助您一键享受高并发、低延迟。
- 单击服务操作栏中的“更新服务”。
- 在模型服务信息部分,在运行命令参数末尾添加参数–backend=vllm,然后点击部署。(注意,目前推理加速引擎仅支持以下模型:qwen、llama2、baichuan-13B、baichuan2-13B)
3、transformers、vllm等版本升级。由于模型的迭代更新,较早发布的模型与最新发布的模型与transformers、vllm等工具包的版本依赖关系不兼容,用户可根据实际需要自由升级transformers、 vllm等工具包。

如何安装自定义模型?
部署自定义模型,可以使用OSS挂载自定义模型,操作步骤如下:
- 将自定义模型和相关配置文件上传到您的 OSS Bucket Directory。有关如何创建 bucket 和上传文件的更多信息,请参阅在控制台中创建 bucket和在控制台中上传文件。
需要准备的示例模型文件如下:
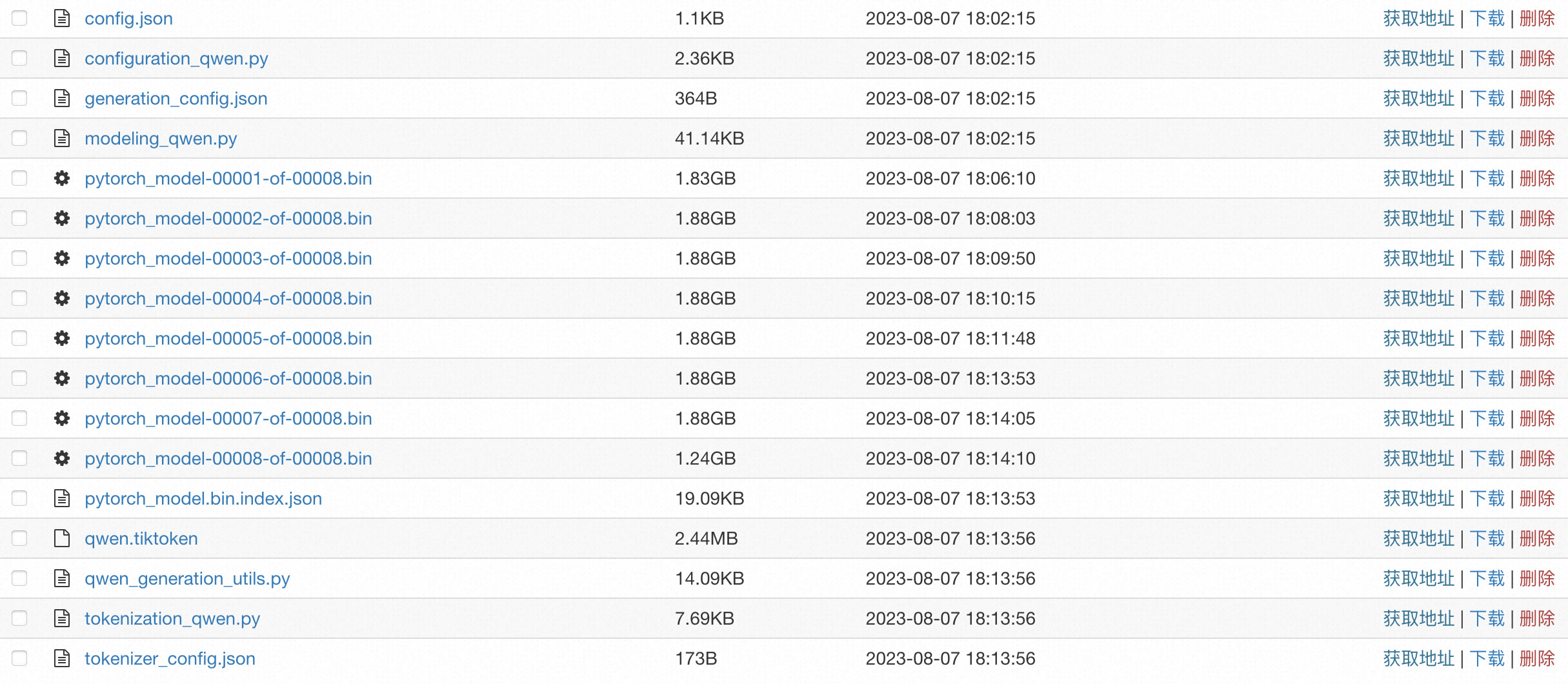
配置文件中必须包含一个 config.json 文件,你需要根据Huggingface或Modelscope的模型格式来设置该 Config 文件,示例文件详情请参考config.json。
- 单击服务操作列中的更新服务。
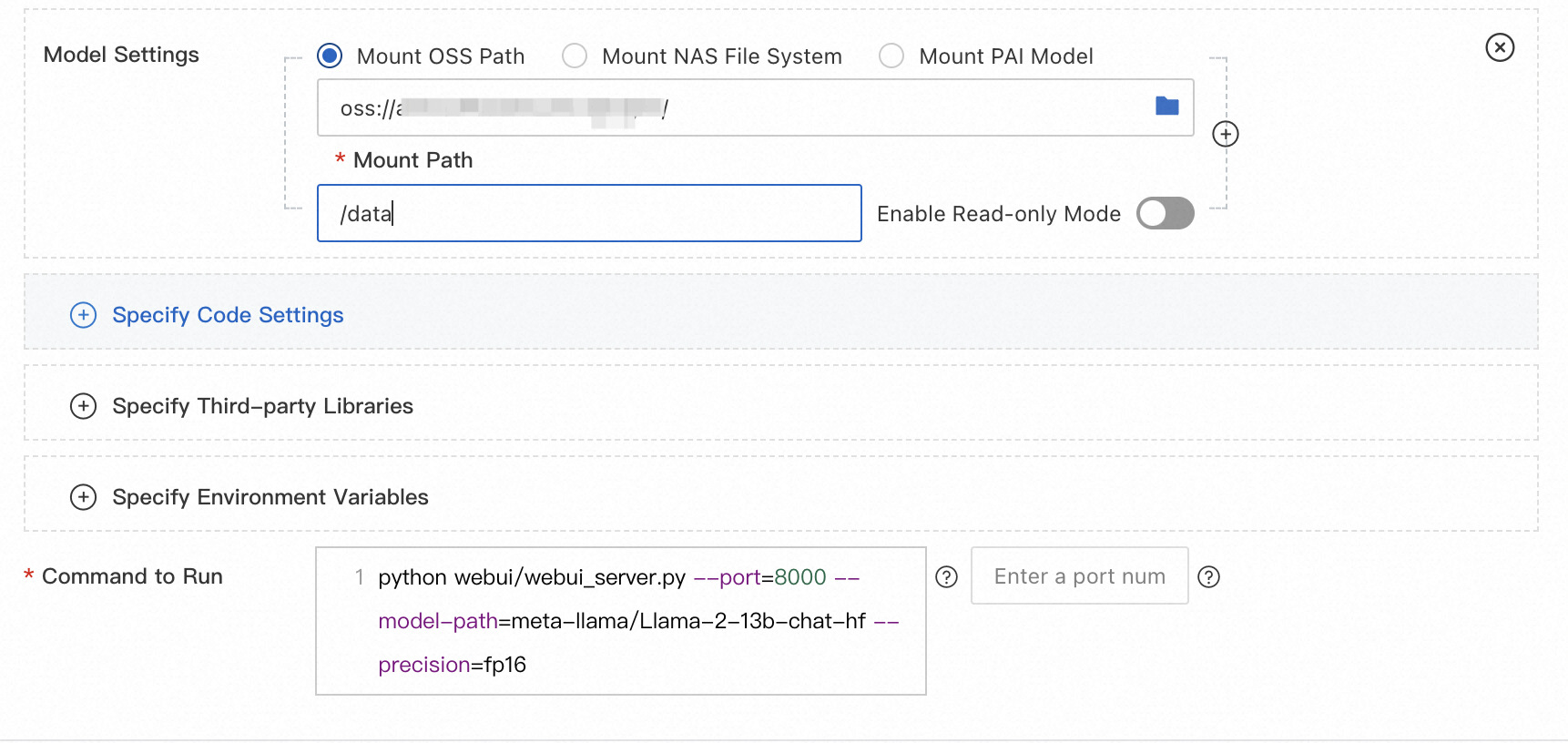
6.在模型服务信息部分,配置以下参数,然后单击部署。
| 范围 | 除漆 |
|---|---|
| 模型配置 | 点击进入模型配置,配置模型。 • 模型配置选择OSS挂载,OSS路径设置为自定义模型文件所在的OSS路径,例如oss://bucket-test/data-oss/。 • 挂载路径:设置为/data。 • 只读:开关关闭。 |
| 运行命令 | 在运行命令中添加以下参数: • --model-path:设置为/data,配置要和Mount路径一致。 • --model-type:模型类型, 不同模型的运行命令配置方法请参见使用EAS 5分钟部署ChatGLM和LangChain应用。 |
运行命令
| 模型类型 | 运行命令 |
|---|---|
| 骆驼2 | python webui/webui_server.py --port=8000 --model-path=/data --model-type=llama2 --precision=fp16 |
| chatglm2 | python webui/webui_server.py --port=8000 --model-path=/data --model-type=chatglm |
| 奎文 | python webui/webui_server.py --port=8000 --model-path=/data --model-type=qwen |
| 猎鹰-7b | python webui/webui_server.py --port=8000 --model-path=/data --model-type=falcon |
模型推理API接口
1、获取服务访问地址和Token。
- 进入PAI-EAS模型在线服务页面,详细信息请参见部署EAS服务。
- 在本页面中单击目标服务名称,进入服务详情页。
- 在基本信息部分,点击查看调用信息,在公网地址调用页签下获取服务Token和访问地址。
2.启动模型推理的API。
使用 HTTP 调用服务
- 非流式呼叫
客户端使用标准HTTP格式,调用curl命令时可以发送以下两种类型的请求:
- 发送字符串请求
curl $host -H 'Authorization: $authorization' --data-binary @chatllm_data.txt -v
其中:$authorization需要替换为服务Token,:$host需要替换为服务访问地址,chatllm_data.txt:该文件为包含信息的文本文件。
- 发送半结构化请求
curl $host -H 'Authorization: $authorization' -H "Content-type: application/json" --data-binary @chatllm_data.json -v -H "Connection: close"
使用chatllm_data.json文件设置推理参数,chatllm_data.json文件内容格式如下:
{
"max_new_tokens": 4096,
"use_stream_chat": false,
"prompt": "How to install it?",
"system_prompt": "Act like you are programmer with 5+ years of experience."
"history": [
[
"Can you tell me what's the bladellm?",
"BladeLLM is an framework for LLM serving, integrated with acceleration techniques like quantization, ai compilation, etc. , and supporting popular LLMs like OPT, Bloom, LLaMA, etc."
]
],
"temperature": 0.8,
"top_k": 10,
"top_p": 0.8,
"do_sample": True,
"use_cache": True,
}
参数说明如下,请根据需要添加或删除。
| 范围 | 除漆 | 默认值 |
|---|---|---|
| 最大新令牌数 | 生成的输出标记的最大长度(以单位为单位)。 | 2048 |
| 使用流聊天 | 指定是否使用流式输出。 | 真的 |
| 迅速的 | 用户的提示。 | “” |
| 系統提示 | 系统提示。 | “” |
| 历史 | 对话的历史记录。类型为 List[Tuple(str, str)]。 | [()] |
| 温度 | 用于调整模型输出结果的随机性,值越大随机性越强,0为固定输出。Float类型,取值范围为0~1。 | 0.95 |
| top_k | 从生成的结果中选择候选输出的数量。 | 三十 |
| top_p | 从生成的结果中按百分比选择输出结果。浮点型,范围为0~1。 | 0.8 |
| 做样本 | 启用输出采样。 | 真的 |
| 使用缓存 | 启用键值缓存。 | 真的 |
你也可以基于Python的requests包实现自己的客户端,示例代码如下:
import argparse
import json
from typing import Iterable, List
import requests
def post_http_request(prompt: str,
system_prompt: str,
history: list,
host: str,
authorization: str,
max_new_tokens: int = 2048,
temperature: float = 0.95,
top_k: int = 1,
top_p: float = 0.8,
langchain: bool = False,
use_stream_chat: bool = False) -> requests.Response:
headers = {
"User-Agent": "Test Client",
"Authorization": f"{authorization}"
}
if not history:
history = [
(
"San Francisco is a",
"city located in the state of California in the United States. \
It is known for its iconic landmarks, such as the Golden Gate Bridge \
and Alcatraz Island, as well as its vibrant culture, diverse population, \
and tech industry. The city is also home to many famous companies and \
startups, including Google, Apple, and Twitter."
)
]
pload = {
"prompt": prompt,
"system_prompt": system_prompt,
"top_k": top_k,
"top_p": top_p,
"temperature": temperature,
"max_new_tokens": max_new_tokens,
"use_stream_chat": use_stream_chat,
"history": history
}
if langchain:
print(langchain)
pload["langchain"] = langchain
response = requests.post(host, headers=headers,
json=pload, stream=use_stream_chat)
return response
def get_response(response: requests.Response) -> List[str]:
data = json.loads(response.content)
output = data["response"]
history = data["history"]
return output, history
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--top-k", type=int, default=4)
parser.add_argument("--top-p", type=float, default=0.8)
parser.add_argument("--max-new-tokens", type=int, default=2048)
parser.add_argument("--temperature", type=float, default=0.95)
parser.add_argument("--prompt", type=str, default="How can I get there?")
parser.add_argument("--langchain", action="store_true")
args = parser.parse_args()
prompt = args.prompt
top_k = args.top_k
top_p = args.top_p
use_stream_chat = False
temperature = args.temperature
langchain = args.langchain
max_new_tokens = args.max_new_tokens
host = "EAS服务公网地址"
authorization = "EAS服务公网Token"
print(f"Prompt: {prompt!r}\n", flush=True)
# You can set the system prompt in the language model input within the request.
system_prompt = "Act like you are programmer with \
5+ years of experience."
# In client requests, it is possible to set the historical information of the conversation. The client maintains the dialogue records of the current user to facilitate multi-turn dialogue. Typically, the history information returned from the previous round of dialogue can be used. The format for history is List[Tuple(str, str)]
history = []
response = post_http_request(
prompt, system_prompt, history,
host, authorization,
max_new_tokens, temperature, top_k, top_p,
langchain=langchain, use_stream_chat=use_stream_chat)
output, history = get_response(response)
print(f" --- output: {output} \n --- history: {history}", flush=True)
# The server returns the results in JSON format, which includes inference results and dialogue history.
def get_response(response: requests.Response) -> List[str]:
data = json.loads(response.content)
output = data["response"]
history = data["history"]
return output, history
在哪里:
- host:服务访问地址。
- 授权:配置服务Token。
- 流式通话
流式调用使用HTTP SSE方法,其他设置与非流式调用相同,详情见以下代码:
import argparse
import json
from typing import Iterable, List
import requests
def clear_line(n: int = 1) -> None:
LINE_UP = '\033[1A'
LINE_CLEAR = '\x1b[2K'
for _ in range(n):
print(LINE_UP, end=LINE_CLEAR, flush=True)
def post_http_request(prompt: str,
system_prompt: str,
history: list,
host: str,
authorization: str,
max_new_tokens: int = 2048,
temperature: float = 0.95,
top_k: int = 1,
top_p: float = 0.8,
langchain: bool = False,
use_stream_chat: bool = False) -> requests.Response:
headers = {
"User-Agent": "Test Client",
"Authorization": f"{authorization}"
}
if not history:
history = [
(
"San Francisco is a",
"city located in the state of California in the United States. \
It is known for its iconic landmarks, such as the Golden Gate Bridge \
and Alcatraz Island, as well as its vibrant culture, diverse population, \
and tech industry. The city is also home to many famous companies and \
startups, including Google, Apple, and Twitter."
)
]
pload = {
"prompt": prompt,
"system_prompt": system_prompt,
"top_k": top_k,
"top_p": top_p,
"temperature": temperature,
"max_new_tokens": max_new_tokens,
"use_stream_chat": use_stream_chat,
"history": history
}
if langchain:
pload["langchain"] = langchain
response = requests.post(host, headers=headers,
json=pload, stream=use_stream_chat)
return response
def get_streaming_response(response: requests.Response) -> Iterable[List[str]]:
for chunk in response.iter_lines(chunk_size=8192,
decode_unicode=False,
delimiter=b"\0"):
if chunk:
data = json.loads(chunk.decode("utf-8"))
output = data["response"]
history = data["history"]
yield output, history
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--top-k", type=int, default=4)
parser.add_argument("--top-p", type=float, default=0.8)
parser.add_argument("--max-new-tokens", type=int, default=2048)
parser.add_argument("--temperature", type=float, default=0.95)
parser.add_argument("--prompt", type=str, default="How can I get there?")
parser.add_argument("--langchain", action="store_true")
args = parser.parse_args()
prompt = args.prompt
top_k = args.top_k
top_p = args.top_p
use_stream_chat = True
temperature = args.temperature
langchain = args.langchain
max_new_tokens = args.max_new_tokens
host = ""
authorization = ""
print(f"Prompt: {prompt!r}\n", flush=True)
system_prompt = "Act like you are programmer with \
5+ years of experience."
history = []
response = post_http_request(
prompt, system_prompt, history,
host, authorization,
max_new_tokens, temperature, top_k, top_p,
langchain=langchain, use_stream_chat=use_stream_chat)
for h, history in get_streaming_response(response):
print(
f" --- stream line: {h} \n --- history: {history}", flush=True)
在哪里:
- host:服务访问地址。
- 授权:配置服务Token。
使用 WebSocket 调用服务
为了更好的维护用户对话信息,还可以使用WebSocket来维护与服务的连接,完成一轮或者多轮对话,代码示例如下:
import os
import time
import json
import struct
from multiprocessing import Process
import websocket
round = 5
questions = 0
def on_message_1(ws, message):
if message == "<EOS>":
print('pid-{} timestamp-({}) receives end message: {}'.format(os.getpid(),
time.time(), message), flush=True)
ws.send(struct.pack('!H', 1000), websocket.ABNF.OPCODE_CLOSE)
else:
print("{}".format(time.time()))
print('pid-{} timestamp-({}) --- message received: {}'.format(os.getpid(),
time.time(), message), flush=True)
def on_message_2(ws, message):
global questions
print('pid-{} --- message received: {}'.format(os.getpid(), message))
# end the client-side streaming
if message == "<EOS>":
questions = questions + 1
if questions == 5:
ws.send(struct.pack('!H', 1000), websocket.ABNF.OPCODE_CLOSE)
def on_message_3(ws, message):
print('pid-{} --- message received: {}'.format(os.getpid(), message))
# end the client-side streaming
ws.send(struct.pack('!H', 1000), websocket.ABNF.OPCODE_CLOSE)
def on_error(ws, error):
print('error happened: ', str(error))
def on_close(ws, a, b):
print("### closed ###", a, b)
def on_pong(ws, pong):
print('pong:', pong)
# stream chat validation test
def on_open_1(ws):
print('Opening Websocket connection to the server ... ')
params_dict = {}
params_dict['prompt'] = """Show me a golang code example: """
params_dict['temperature'] = 0.9
params_dict['top_p'] = 0.1
params_dict['top_k'] = 30
params_dict['max_new_tokens'] = 2048
params_dict['do_sample'] = True
raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8')
# raw_req = f"""To open a Websocket connection to the server: """
ws.send(raw_req)
# end the client-side streaming
# multi-round query validation test
def on_open_2(ws):
global round
print('Opening Websocket connection to the server ... ')
params_dict = {"max_new_tokens": 6144}
params_dict['temperature'] = 0.9
params_dict['top_p'] = 0.1
params_dict['top_k'] = 30
params_dict['use_stream_chat'] = True
params_dict['prompt'] = "您好!"
params_dict = {
"system_prompt":
"Act like you are programmer with 5+ years of experience."
}
raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8')
ws.send(raw_req)
params_dict['prompt'] = "请使用Python,编写一个排序算法"
raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8')
ws.send(raw_req)
params_dict['prompt'] = "请转写成java语言的实现"
raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8')
ws.send(raw_req)
params_dict['prompt'] = "请介绍一下你自己?"
raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8')
ws.send(raw_req)
params_dict['prompt'] = "请总结上述对话"
raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8')
ws.send(raw_req)
# Langchain validation test.
def on_open_3(ws):
global round
print('Opening Websocket connection to the server ... ')
params_dict = {}
# params_dict['prompt'] = """To open a Websocket connection to the server: """
params_dict['prompt'] = """Can you tell me what's the MNN?"""
params_dict['temperature'] = 0.9
params_dict['top_p'] = 0.1
params_dict['top_k'] = 30
params_dict['max_new_tokens'] = 2048
params_dict['use_stream_chat'] = False
params_dict['langchain'] = True
raw_req = json.dumps(params_dict, ensure_ascii=False).encode('utf8')
ws.send(raw_req)
authorization = ""
host = "ws://" + ""
def single_call(on_open_func, on_message_func, on_clonse_func=on_close):
ws = websocket.WebSocketApp(
host,
on_open=on_open_func,
on_message=on_message_func,
on_error=on_error,
on_pong=on_pong,
on_close=on_clonse_func,
header=[
'Authorization: ' + authorization],
)
# setup ping interval to keep long connection.
ws.run_forever(ping_interval=2)
if __name__ == "__main__":
for i in range(5):
p1 = Process(target=single_call, args=(on_open_1, on_message_1))
p2 = Process(target=single_call, args=(on_open_2, on_message_2))
p3 = Process(target=single_call, args=(on_open_3, on_message_3))
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
在哪里:
- **授权:**配置服务Token。
- **host:**指定服务访问地址,将前端http替换为ws。
- **use_stream_chat:**该参数用于控制客户端是否流式输出,默认值为True,表示服务端返回流式数据。
- 参照上述示例代码中的on_open_2函数实现方法,可以实现多轮对话。
结论
本文是使用阿里云人工智能平台 - 弹性算法服务 (PAI-EAS) 部署和集成大型语言模型 (LLM) 的详细手册。它满足了对复杂 LLM 应用程序(例如基于基础模型架构的应用程序)的可访问和高效部署的日益增长的需求,强调快速建立推理服务的能力。
本文涵盖的要点包括:
- PAI-EAS 部署:本文介绍了使用 PAI-EAS 部署 LLM 的分步过程。它强调了使用 WebUI 界面和 API 调用的便利性,这些界面和 API 调用可满足不同的用户偏好和技术专长。它还指定了实现最佳模型性能所需的参数和推荐资源,从而为不同的 LLM 应用程序提供量身定制的设置。
- 与 LangChain 集成:概述了与开源框架 LangChain 的集成,展示了如何利用公司的知识库增强 LLM。通过将响应建立在企业特定信息的基础上,这显著提高了模型的输出,这对于在业务应用程序中创建更具情境性和相关性的交互特别有用。
- 推理加速引擎:本文讨论了如何使用 PAI-EAS 提供的 BladeLLM 和 vLLM 加速引擎来提高推理性能。这些工具可帮助用户实现更高的并发性和更低的延迟,这是维持高效、响应迅速的 LLM 服务的关键因素。
- 自定义模型部署:对于有自定义模型需求的用户,该指南解释了使用 OSS 安装自定义模型的过程,详细说明了上传和配置模型及其相关文件的步骤。这种灵活性使企业能够部署适合其独特用例的专有或特殊配置的模型。
- 用于推理的 API 利用:本文提供了获取服务访问凭证以及进行 HTTP 或 WebSocket 调用以进行模型推理的实用见解。其中包括进行流式和非流式调用的示例,从而为开发人员提供了一套完整的工具包,使他们能够有效地将 PAI-EAS LLM 服务集成到他们的应用程序中。
内容丰富,包含命令示例、参数描述和特定于模型的建议,使用户能够自信地应对 LLM 部署的复杂性。通过介绍常见用例并提供典型挑战的解决方案,本文确保读者不仅可以部署 LLM 应用程序,还可以最大限度地发挥其效用,以满足他们的业务目标和技术要求。
本综合教程为数据科学家、人工智能开发人员和 IT 专业人员提供了重要资源,旨在利用阿里云生态系统中大型语言模型的强大功能。
过将响应建立在企业特定信息的基础上,这显著提高了模型的输出,这对于在业务应用程序中创建更具情境性和相关性的交互特别有用。
3. 推理加速引擎:本文讨论了如何使用 PAI-EAS 提供的 BladeLLM 和 vLLM 加速引擎来提高推理性能。这些工具可帮助用户实现更高的并发性和更低的延迟,这是维持高效、响应迅速的 LLM 服务的关键因素。
4. 自定义模型部署:对于有自定义模型需求的用户,该指南解释了使用 OSS 安装自定义模型的过程,详细说明了上传和配置模型及其相关文件的步骤。这种灵活性使企业能够部署适合其独特用例的专有或特殊配置的模型。
5. 用于推理的 API 利用:本文提供了获取服务访问凭证以及进行 HTTP 或 WebSocket 调用以进行模型推理的实用见解。其中包括进行流式和非流式调用的示例,从而为开发人员提供了一套完整的工具包,使他们能够有效地将 PAI-EAS LLM 服务集成到他们的应用程序中。
内容丰富,包含命令示例、参数描述和特定于模型的建议,使用户能够自信地应对 LLM 部署的复杂性。通过介绍常见用例并提供典型挑战的解决方案,本文确保读者不仅可以部署 LLM 应用程序,还可以最大限度地发挥其效用,以满足他们的业务目标和技术要求。
本综合教程为数据科学家、人工智能开发人员和 IT 专业人员提供了重要资源,旨在利用阿里云生态系统中大型语言模型的强大功能。
联系阿里云,探索生成式人工智能的世界,了解它如何改变您的应用程序和业务。它弥合了先进人工智能技术与实际业务应用之间的差距,使组织能够创新并从尖端语言处理能力中获取价值。
博客原文:专业人工智能技术社区















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









