







BigGAN
尽管生成图像建模最近取得了进展,但从像ImageNet这样的复杂数据集成功生成高分辨率、多样化的样本仍然是一个难以实现的目标。为此,我们在迄今为止尝试的最大规模上训练生成式对抗网络,并研究特定于这种规模的不稳定性。我们发现,对生成器应用正交正则化使其服从于一个简单的“截断技巧”,允许通过减少生成器输入的方差来精细控制样本保真度和多样性之间的权衡。
我们的修改导致了模型在类别条件下的图像合成方面达到了新的水平。当在128×128分辨率的ImageNet上进行训练时,我们的模型(BigGANs)达到了166.5的Inception Score(IS)和7.4的FID,比以前最好的IS 52.52和FID 18.65有所提高。
1 INTRODUCTION
近年来,生成性图像建模的状况有了很大的进步,生成对抗网络(GANs,Goodfellow等人(2014))处于努力生成高保真、多样化图像的前沿,其模型直接从数据中学习。GAN的训练是动态的,对其设置的几乎每一个方面都很敏感(从优化参数到模型结构),但研究的洪流已经产生了经验和理论上的见解,使得在各种环境下的稳定训练。尽管取得了这些进展,目前在有条件的ImageNet建模方面的技术水平(Zhang等人,2018)达到了52.5的Inception Score(Salimans等人,2016),而真实数据则为233。
在这项工作中,我们着手缩小GANs生成的图像与来自ImageNet数据集的真实图像在保真度和多样性方面的差距。为此,我们作出了以下三点贡献:
-
我们证明了GANs从扩展中获得了巨大的好处,与现有技术相比,它可以用2到4倍的参数和8倍的批量大小来训练模型。我们引入了两个简单的、通用的架构变化来提高可扩展性,并修改了一个正则化方案来改善调节,明显地提高了性能。
-
作为我们修改的一个副作用,我们的模型变得适合于 “截断技巧”,这是一种简单的抽样技术,允许明确、细粒度地控制样本种类和保真度之间的权衡。
-
我们发现了大规模GANs特有的不稳定性,并根据经验对其进行了描述。利用这一分析的洞察力,我们证明了新技术和现有技术的结合可以减少这些不稳定性,但完全的训练稳定性只能以巨大的性能成本来实现。
我们的修改大大改善了以类为条件的GANs。当在128×128分辨率的ImageNet上训练时,我们的模型(BigGANs)将最先进的Inception Score(IS)和Frechet Inception Distance(FID)分别从52.52和18.65提高到166.5和7.4。我们还在256×256和512×512分辨率的ImageNet上成功地训练了BigGANs,并在256×256上实现了232.5和8.1的IS和FID,在512×512上实现了241.5和11.5的IS和FID。最后,我们在一个更大的数据集–JFT-300M–上训练我们的模型,并证明我们的设计选择能很好地从ImageNet转移过来。我们的预训练生成器的代码和权重是公开的。
最近的许多研究相应地集中在对vanilla GAN程序的修改上,以赋予其稳定性,借鉴了越来越多的经验和理论见解(Nowozin等人,2016;Sønderby等人,2017;Fedus等人,2018)。一条线的工作重点是改变目标函数(Arjovsky等人,2017;Mao等人,2016;Lim和Ye,2017;Bellemare等人,2017;Salimans等人,2018)以鼓励收敛。另一条线则侧重于通过梯度惩罚来约束D(Gulrajani等人,2017;Kodali等人,2017;Mescheder等人,2018)或归一化(Miyato等人,2018),都是为了抵制使用无界损失函数,确保D为G提供各地的梯度。
与我们的工作特别相关的是光谱归一化(Miyato等人,2018)。相关的Odena等人(2018)分析了G的Jacobian的条件数,发现性能取决于G的条件。Zhang等人(2018)发现在G中采用频谱归一化可以提高稳定性,使每次迭代的D步骤减少。我们在这些分析的基础上进行扩展,以进一步了解GAN训练的病理。
其他工作侧重于架构的选择,如SA-GAN(Zhang等人,2018),它增加了来自(Wang等人,2018)的自我注意块,以提高G和D的全局结构建模能力。ProGAN(Karras等人,2018)在 single-class设置中,通过在一连串不断增加的分辨率中训练单个模型来训练高分辨率的GANs。
在条件gan (Mirza & Osindero, 2014)中,可以以各种方式将类信息输入模型。在(Odena et al., 2017)中,通过将一个 1-hot class vector连接到噪声向量,将其提供给G,并对目标进行修改,以鼓励条件样本最大化辅助分类器预测的相应类概率。
de Vries等人(2017)和Dumoulin等人(2017)通过在BatchNorm(Ioffe & Szegedy,2015)层中向G提供类条件增益和偏置来修改类条件传递的方式(modify the way class conditioning is passed to G by supplying it with classconditional gains and biases in BatchNorm (Ioffe & Szegedy, 2015) layers.)。在Miyato & Koyama(2018)中,D是通过使用其特征和一组学习的类嵌入之间的余弦相似性作为区分真实和生成的样本的额外证据来调节的,有效地鼓励生成其特征与学习的类原型相匹配的样本。
客观地评价隐性生成模型是很困难的(Theis等人,2015)。许多工作都提出了启发式方法来衡量没有可操作的似然的模型的样本质量(Salimans等人,2016;Heusel等人,2017;Binkowski等人,2018;Wu等人,2017)。其中,入选分数(IS,Salimans等人(2016))和Frechet入选距离(FID,Heusel等人(2017))尽管有明显的缺陷,但已经变得很受欢迎(Barratt & Sharma,2018)。我们采用它们作为样本质量的近似衡量标准,并能够与以前的工作进行比较。
3 SCALING UP GANS
在本节中,我们探讨了扩大GAN训练的方法,以获得更大的模型和更大的batch的性能优势。作为基线,我们采用Zhang等人(2018)的SA-GAN架构,它使用hinge损失(Lim & Ye,2017;Tran等人,2017)GAN目标。我们用类别条件BatchNorm(Dumoulin等人,2017;de Vries等人,2017)向G提供类别信息,用投影(Miyato & Koyama, 2018)向D提供类别信息。
优化设置遵循Zhang等人(2018)(特别是在G中使用谱范数)的修改,我们将学习速率减半,每G步采取两个D步。为了进行评估,我们采用了Karras et al.(2018)的G权重移动平均;Mescheder et al. (2018);Yazc et al.(2018),衰减为0.9999。
我们使用正交初始化(Saxe等人,2014),而以前的工作使用N(0,0.02I)(Radford等人,2016)或Xavier初始化(Glorot和Bengio,2010)。每个模型都在谷歌TPUv3 Pod(谷歌,2018)的128至512个核心上进行训练,并在所有设备上以计算G的BatchNorm统计数据,而不是像通常那样按设备计算。我们发现渐进式增长(Karras等人,2018)即使对于我们的512×512模型也是不必要的。其他细节见附录C。

表1: Frechet Inception Distance(FID,越低越好)和Inception Score(IS,越高越好)对我们提出的修改进行了消融。Batch是批次大小,Param是参数总数,Ch.是代表每层单位数量的通道乘数,Shared是使用共享嵌入,Skip-z是 using skip connections from the latent to multiple layers,Ortho.是正交正则化,Itr表示设置是否稳定到 1 0 6 10^6 106次迭代,或者在给定的迭代中崩溃。除第1-4行外,结果是在8个随机初始化中计算的。
我们首先增加了基线模型的批量大小,并立即发现这样做有巨大的好处。表1的第1-4行显示,仅仅将批处理量增加8倍,就将最先进的IS提高了46%。我们猜测,这是由于每个batch覆盖了更多的模式,为两个网络提供了更好的梯度。这种扩展的一个明显的副作用是,我们的模型在更少的迭代中达到更好的最终性能,但变得不稳定,并经历了完全的训练崩溃。我们在第4节中讨论其原因和影响。在这些实验中,我们报告了崩溃前保存的检查点的分数。
然后我们将每一层的宽度(通道数量)增加50%,大约是两个模型中参数数量的两倍。这导致IS进一步提高了21%,我们认为这是由于相对于数据集的复杂性,模型的容量增加了。
深度翻倍最初并没有带来改善–我们后来在BigGAN-deep模型中解决了这个问题,该模型使用了不同的residual block structure。
我们注意到,G中用于条件BatchNorm层的类嵌入c包含大量的权重。我们没有为每个嵌入设置单独的层(Miyato等人,2018;Zhang等人,2018),而是选择使用一个共享的嵌入,它被线性地投射到每个层的收益和偏差(gains and biases)(Perez等人,2018)。
这减少了计算和内存成本,并将训练速度(达到给定性能所需的迭代次数)提高了37%。接下来,我们将直接跳过连接(skip-z)从噪声矢量z添加到G的多个层,而不仅仅是初始层。这个设计背后的直觉是允许G利用潜在空间直接影响不同分辨率和层次层次的特征。
在BigGAN中,这是通过将z分割成每个分辨率的一个块来实现的,并将每个块与条件向量c相连接,条件向量被投射到BatchNorm的收益和偏差中( In BigGAN, this is accomplished by splitting z into one chunk per resolution, and concatenating each chunk to the conditional vector c which gets projected to the BatchNorm gains and biases)。在BigGAN-deep中,我们使用了一个更简单的设计,将整个z与条件向量连接起来,而不将其分割成几块。以前的工作(Goodfellow等人,2014;Denton等人,2015)考虑了这个概念的变体;我们的实现是对这个设计的一个小修改。Skip-z提供了约4%的适度性能改进,并将训练速度进一步提高了18%。
3.1 TRADING OFF VARIETY AND FIDELITY WITH THE TRUNCATION TRICK
与需要反向传播其latents的模型不同,GANs可以采用任意的先验p(z),但以前的绝大多数工作都选择从N(0,I)或U[-1,1]中抽取z。我们对这一选择提出质疑,并在附录E中探讨了替代方案。
值得注意的是,我们最好的结果来自于使用与训练中不同的潜在分布进行抽样。采用z ~ N (0, I)训练的模型,并从截断的正态(在此范围外的值被重新采样,使其落在该范围内)中对z进行采样,立即提供了IS和FID的增强。我们称其为截断技巧:通过对大于所选阈值的值进行重采样来截断z向量,从而以减少总体样本多样性为代价提高单个样本的质量。

图2:(a)增加截断的效果。从左到右,阈值设置为2、1、0.5、0.04。(b)对条件较差的模型应用截断后的饱和伪影。
图2(a)证明了这一点:随着阈值的降低,z的元素被截断为零(潜在分布的模式),单个样本接近G的输出分布的模式。关于这种权衡的相关观察是在(2016年3月;Pieters & Wiering, 2014)。
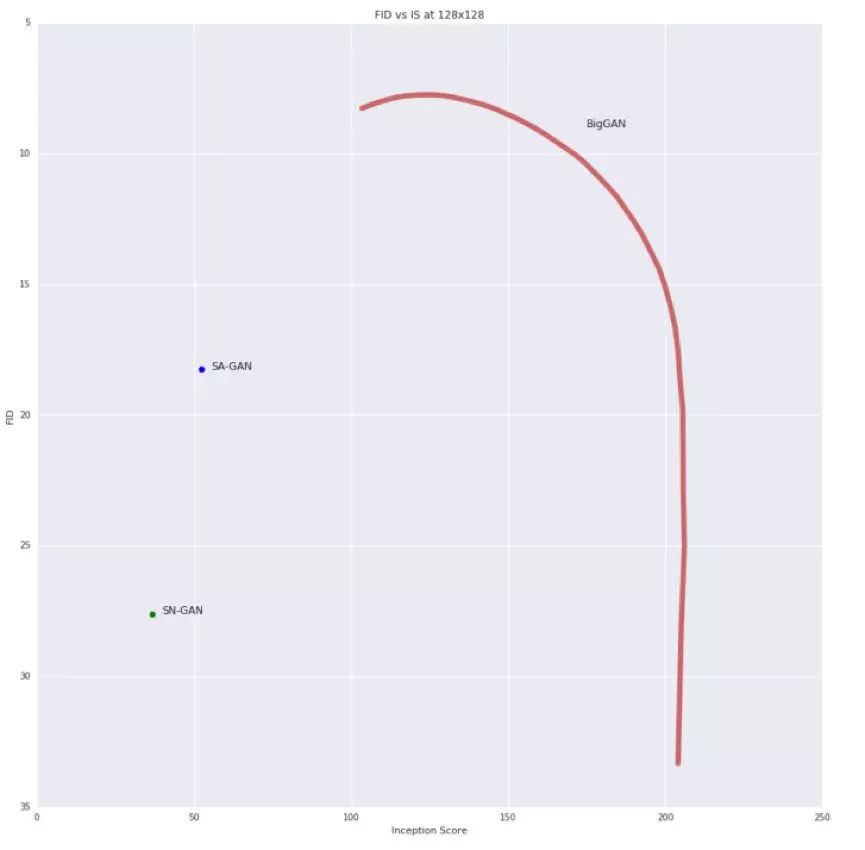
该技术允许对给定g的样本质量和多样性之间的权衡进行细粒度的事后选择。值得注意的是,我们可以计算一个阈值范围的FID和IS,得到的多样性-保真度曲线让人想起精度-召回曲线(图17)。
由于IS并不惩罚类条件模型中缺乏多样性,减少截断阈值会直接增加IS(类似于精度)。FID会惩罚缺乏多样性(类似于回忆),但也会奖励精确,所以我们最初看到FID有适度的改善,但随着截断接近零和多样性减少,FID急剧下降。
对许多模型来说,用不同于训练中所看到的latents取样所引起的分布转移(distribution shift)是有问题的。我们的一些较大的模型不适合截断,在输入截断噪声时产生饱和伪影(图2(b))。为了解决这个问题,我们试图通过调节G的平滑性来加强对截断的适应性,从而使Z的全部空间能够映射到良好的输出样本。为此,我们转向正交规范化(Brock等人,2017),它直接强制执行正交条件。

其中W是一个权重矩阵,β是一个超参数。众所周知,这种正则化往往限制性太强(Miyato等人,2018年),因此我们探索了几个变体,旨在放松约束,同时仍然为我们的模型赋予所需的平滑度。我们发现效果最好的版本是将对角线项从正则化中移除,并旨在最小化过滤器之间的成对余弦相似性,但不限制其规范。

其中 1 \mathbf 1 1表示一个所有元素都设置为1的矩阵。我们扫过β值,选择了 1 0 − 4 10^{-4} 10−4,发现这个小的附加惩罚足以提高我们的模型适合截断的可能性。在表1中,我们观察到在没有正交正则化的情况下,只有16%的模型可以被截断,而在用正交正则化训练时,有60%的模型可以被截断。
3.2 SUMMARY
我们发现,目前的GAN技术足以实现对大型模型的扩展和分布式的大批量训练。我们发现,我们可以极大地改善技术水平,并在不需要像Karras等人(2018)那样明确的多尺度方法的情况下训练模型到512×512的分辨率。尽管有这些改进,我们的模型经历了训练崩溃,在实践中必须早期停止。在接下来的两节中,我们研究了为什么在以前的工作中稳定的设置在应用规模时变得不稳定。
4 ANALYSIS
4.1 CHARACTERIZING INSTABILITY: THE GENERATOR
以前的许多工作都从各种分析角度和玩具问题上研究了GAN的稳定性,但我们观察到的不稳定性发生在小规模稳定的设置中,因此有必要在大规模上进行直接分析。我们在训练过程中监测了一系列的权重、梯度和损失统计,以寻找一个可能预示训练崩溃的指标,类似于(Odena等人,2018)。

图3:在Spectral Normalization之前,G(a)和D(b)层的第一奇异值σ0的典型图。G中的大多数层都有良好的频谱,但如果没有约束,一小部分在整个训练过程中都会增长,并在崩溃时爆炸。D的光谱比较嘈杂,但其他方面表现较好。从红到紫的颜色表示越来越深。
我们发现每个权重矩阵的前三个奇异值σ0、σ1、σ2是信息量最大的。它们可以使用Alrnoldi迭代法(Golub & der Vorst, 2000)有效地计算出来,该方法将Miyato等人(2018)使用的幂级迭代法扩展到估计额外的奇异向量和值。
一个明显的模式出现了,从图3(a)和附录F可以看出:大多数G层有良好的spectral norms,但有些层(typically the first layer in G, which is over-complete and not convolutional)并不是,其spectral norms在整个训练中增长,在崩溃时爆炸。
为了确定这种病态是崩溃的原因还是仅仅是一种症状,我们研究了对G施加额外条件以明确对抗频谱爆炸的影响。首先,我们直接对每个权重的顶部奇异值σ0进行正则化处理,要么朝向一个固定值 σ r e g σ_{reg} σreg,要么朝向第二个奇异值的某个比率r, r ⋅ s g ( σ 1 ) r\cdot sg(σ_1) r⋅sg(σ1)(with sg the stop-gradient operation to prevent the regularization from increasing σ1)。另外,我们采用部分奇异值分解( partial singular value decomposition)来代替clamp σ 0 σ_0 σ0。给定一个权重W,它的第一个奇异向量 u 0 和 v 0 u_0和v_0 u0和v0,以及 σ c l a m p σ_{clamp} σclamp,即 σ 0 σ_0 σ0将被clamp 的值,我们的权重就变成了:

其中 σ c l a m p σ_{clamp} σclamp被设置为 σ r e g σ_{reg} σreg或 r ⋅ s g ( σ 1 ) r \cdot sg(σ_1) r⋅sg(σ1)。我们观察到,无论是有还是没有 Spectral Normalization,这些技术都有防止 σ 0 或 σ 0 / σ 1 σ_0或σ_0/σ_1 σ0或σ0/σ1逐渐增加和爆炸的效果,但即使在某些情况下,它们温和地改善了性能,没有任何组合能防止训练崩溃。这一证据表明,虽然调节G可能会提高稳定性,但它不足以确保稳定性。因此,我们把注意力转向了D。
4.2 CHARACTERIZING INSTABILITY: THE DISCRIMINATOR
和G一样,我们分析了D的权重谱(the spectra of D’s weights),以深入了解其行为,然后通过施加额外的约束来寻求稳定训练。图3(b)显示了D的 σ 0 σ_0 σ0的典型图(进一步的图见附录F)。与G不同的是,我们看到频谱是有噪声的, σ 0 / σ 1 σ_0/σ_1 σ0/σ1表现良好,奇异值在整个训练过程中都在增长,但只是在崩溃时跳跃,而不是爆炸。
D’s spectra中的尖峰可能表明它周期性地接受非常大的梯度,但我们观察到Frobenius norms 是平滑的(附录F),表明这种效应主要集中在顶部的几个奇异方向(concentrated on the top few singular directions)。
我们认为,这种噪声是通过对抗性训练过程进行优化的结果,G会定期产生强烈扰动D的batch。如果这种spectral noise与不稳定性有因果关系,一个自然的对策就是采用梯度惩罚,明确地将D’s Jacobian系数的变化正则化。我们探索Mescheder等人(2018)的R1 zero-centered gradient penalty 。

当默认γ强度为10时,训练变得稳定,并提高了G和D’s spectra的平滑性和有界性,但性能严重下降,导致IS降低了45%。减少惩罚部分缓解了这种退化,但导致越来越多的不良spectra;即使惩罚强度降低到1(不会突然崩溃的最低强度),IS也会降低20%。
使用不同强度的正交正则化DropOut (Srivastava et al., 2014)和L2(详见附录I)重复这个实验,发现这些正则化策略有相似的行为:对D的惩罚足够高,可以实现训练稳定性,但代价是性能的巨大损失。
我们还观察到,D的损失在训练期间接近零,但在崩溃时经历了一个急剧上升的跳跃(附录F)。对这种行为的一个可能的解释是,D对训练集过度拟合,记忆训练实例,而不是学习真实图像和生成图像之间一些有意义的边界。作为对D的记忆的简单测试(与Gulrajani等人(2017)有关),我们在ImageNet训练集和验证集上评估未折叠的判别器,并衡量有多少百分比的样本被归类为真实或生成。
虽然训练准确率一直在98%以上,但验证准确率却在50-55%之间,不比随机猜测好多少(无论采用何种正则化策略)。这证实了D确实在记忆训练集;我们认为这符合D的作用,它不是明确的泛化,而是提炼训练数据并为G提供一个有用的学习信号。
4.3 SUMMARY
我们发现,稳定性并不完全来自于G或D,而是来自于它们通过对抗性训练过程的互动。虽然他们不良的调节症状可以用来跟踪和识别不稳定性,但事实证明,确保合理的调节对训练是必要的,但不足以防止最终的训练崩溃。
可以通过严格约束D来加强稳定性,但是这样做会导致巨大的性能损失。在目前的技术下,通过放松这种条件,并允许在训练的后期阶段出现崩溃,模型可以获得更好的最终表现,到那时模型已经得到了充分的训练,从而取得了良好的效果。
APPENDIX B ARCHITECTURAL DETAILS
APPENDIX E CHOOSING LATENT SPACES
传送门:https://arxiv.org/pdf/1809.11096.pdf

















 2518
2518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









