







论文笔记--Recurrent Neural Network for Text Classification with Multi-Task Learning
1. 文章简介
- 标题:Recurrent Neural Network for Text Classification with Multi-Task Learning
- 作者:Pengfei Liu, Xipeng Qiu, Xuanjing Huang
- 日期:2016
- 期刊:arxiv preprint
2. 文章导读
2.1 概括
文章提出了三种基于多任务学习的RNN框架,通过不同任务之间的关联学习得到更好的向量表征,在下游任务取得更好的表现。
2.2 文章重点技术
2.2.1 Recurrent Neural Network(RNN)
这里简要介绍下RNN。所谓RNN即循环神经网络,旨在将变长的输入转换为固定大小的向量,一般在文本类数据中使用居多。相比于普通的全联接网络,RNN的当前隐藏层状态不仅依赖于当前输入,同时还依赖上一个时刻的隐藏层状态,即当前
t
t
t时刻的隐藏状态为
h
t
=
{
0
,
if
t
=
0
f
(
h
t
−
1
,
x
t
)
,
otherwise
\bold{h}_t = \begin{cases}0, \hspace{1.87cm} \text{if}\ t = 0 \\ f(\bold{h_{t-1}}, x_t), \quad \text{otherwise} \end{cases}
ht={0,if t=0f(ht−1,xt),otherwise
但当序列长度很长的时候,RNN易产生梯度消失或梯度爆炸。长短时记忆网络LSTM则是vanilla RNN的一个变种,通过增加单元状态来处理长序列。LSTM的具体介绍可见文章[1]。总结下来就是LSTM增加了三个门:1) 忘记门forget gate:用于控制上一层的单元状态中有多少历史信息被遗忘 2)输入门input gate:用于控制当前的准单元状态中(由当前输入和前一个隐藏层决定)有多少信息被更新 3)输出门output gate:用于控制当前单元状态由多少流入到下一层。
2.2.2 三种多任务学习RNN
单任务的RNN学习可能受限于数据不足,文章提出了三种基于多任务学习RNN的模型,可以结合多种任务数据同时训练模型。以下是三种训练方式
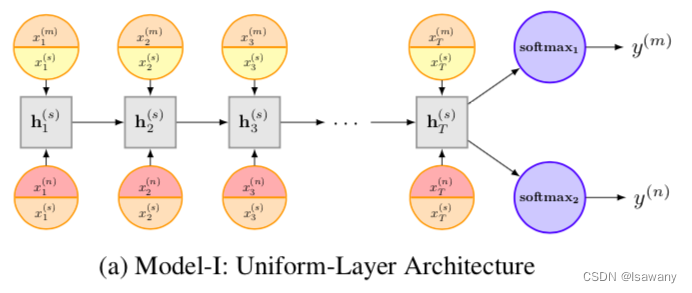
- Model-I: Uniform-Layer Architecture. 下图所示,每个任务(标记为m,n等)有自己的词嵌入层,所有任务有共享的嵌入层训练共享的LSTM,训练参数为
x
m
,
x
n
,
x
s
x_m, x_n,x_s
xm,xn,xs和LSTM的参数,其中
x
m
,
x
n
x_m, x_n
xm,xn表示不同任务自己的词嵌入层,
x
s
x_s
xs为共享嵌入层。则每个任务输入到LSTM的参数为
x
=
x
s
⊕
x
m
x=x_s \oplus x_m
x=xs⊕xm或
x
=
x
s
⊕
x
n
x= x_s\oplus x_n
x=xs⊕xn,其中
⊕
\oplus
⊕表示concat操作。最后每个任务的输出为
y
i
=
S
o
f
t
M
a
x
(
W
T
h
T
i
+
b
T
)
=
S
o
f
t
M
a
x
(
W
T
L
S
T
M
(
x
)
T
+
b
T
)
,
i
=
m
,
n
y_i=SoftMax(W_T h_T^i + b_T)=SoftMax(W_T LSTM(x)_T + b_T), i = m, n
yi=SoftMax(WThTi+bT)=SoftMax(WTLSTM(x)T+bT),i=m,n
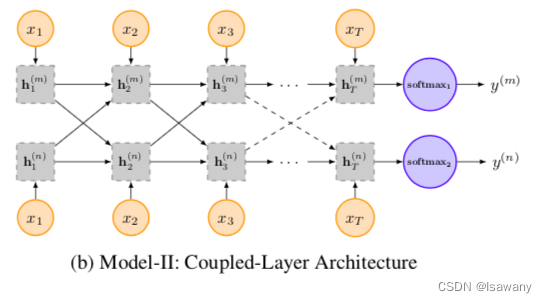
- Model-II: Coupled-Layer Architecture. 下图所示,每个任务有自己的嵌入层和LSTM层,每对任务的LSTM层间参数通过g来传递(global gate unit),其中
g
(
i
→
m
)
=
σ
(
W
g
m
x
t
+
U
g
i
h
t
−
1
i
)
g^{(i\to m)} = \sigma(W_g^m x_t + U_g^i h_{t-1}^i)
g(i→m)=σ(Wgmxt+Ugiht−1i),用于控制任务i多少信息流入另一个任务m。
- Model-III: Shared-Layer Architecture. 下图所示,每个任务有自己的嵌入层和LSTM层,每两个任务中间增加一个共享的双向LSTM层。另外增加传递控制门
g
m
=
σ
(
W
g
m
x
t
+
U
g
m
h
t
−
1
m
)
g^m=\sigma(W_g^mx_t + U_g^m h_{t-1}^m)
gm=σ(Wgmxt+Ugmht−1m)来控制多少信息从本任务上一个隐藏层流入,增加控制门g决定多少信息从共享任务流入,其中
g
(
s
→
m
)
=
σ
(
W
g
m
x
t
+
U
g
s
h
t
−
1
s
)
g^{(s\to m)} = \sigma(W_g^m x_t + U_g^s h_{t-1}^s)
g(s→m)=σ(Wgmxt+Ugsht−1s)类似Model-II中的层任务间传递控制门。
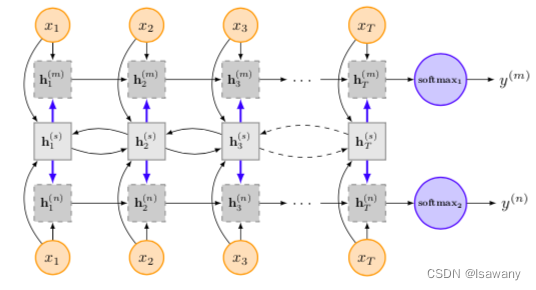
注意到,上述Model-I和Model-III均存在共享的LSTM层,从而可以在训练完上述任务后根据下游任务对共享层进行微调,以增强模型表现。
最终的损失函数为每个任务的损失函数的加权平均。
2.2.3 训练
训练过程中,文章采用随机采样的方式进行训练,具体如下
- 随机选择一个task
- 从该task中随机选择一个样本
- 通过学习该样本更新此task对应的参数
- 回到1)
3. 文章亮点
文章在多个文本分类任务数据集上测试了三种训练方式的表现,结果表明1) 全部三种训练方式均优于单任务训练 2) Model-III表现最好 3) 和NBOW、Tree-LSTM等SOTA模型进行比较,本文提出的Multi-Task模型除了在SST-1任务上略低于Tree-LSTM,其余达到SOTA,且Multi-Task模型很容易就可以兼容Tree-LSTM,从而达到更好的表现。
4. 原文传送门
Recurrent Neural Network for Text Classification with Multi-Task Learning















 3953
3953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









