






本文参考知乎专栏:目标跟踪算法
这篇论文效果出众的主要原因就是把样本的数量和质量都提升了。数量上,把通常训练相关滤波器用到的几千个样本一下子增加到了几万个甚至十几万个,所以训练出来的相关滤波器效果当然比之前的好得多。质量上,正样本的周围不能包含太多的背景信息,不然分类器会误认为这些背景信息也是正样本,导致分类错误。所以这里作者就创造性地把样本有用的部分裁剪出来了,这样样本的质量就很高了。这里我只是大体上描述一下,后面我会用示意图来进一步阐明。
1.总体思路:框架和传统的相关滤波方法一样。本文在之前框架的基础上扩大了循环矩阵采样的区域(样本数量增加),并且在每个样本上裁剪出了有用的样本区域(样本质量变好)。
1.1下面分开来论述它是怎么提高样本数量和样本质量的。先说样本数量。
我们知道,在训练分类器的过程中,样本数量对分类器的性能有着重要影响,在相关滤波器出现以前的一般方法比如压缩跟踪等都是在样本附近的固定半径内选取几百个样本,然后近的样本就是正样本,远的样本就是负样本,从而训练出分类器。但是这样做弊端也很明显,因为不像相关滤波器的方法可以直接投到频域中进行简单计算,老式的采样方法每次都是单独采样单独计算,这几百个样本的运算量已经是非常大,进而导致只能使用效果比较烂的特征,比如CT[2]用的就是哈尔类特征,如果用强特征的话,计算量太大就不能实时了。

后来呢,出现了革命性的相关滤波器方法,利用循环矩阵采样之后,样本数量就从几百个增加到几千个,分类器的效果也就大大增强了。而且利用循环矩阵对角化的性质,这几千个样本可以投到频域里快速计算,因为你所有的几千个样本都是根据一个正样本循环移位移出来的,所以表示的时候可以只用偏移量来表示,有点像信号处理里的基波和谐波,谐波就是基波的倍数,这样一来投到频域里就可以快速计算。下图是传统相关滤波器采样示意图:

每个点都采一次,那就有几千个样本了。那么说到这里我们就很自然地有个想法了,我能不能直接扩大这个采样区域呢?这样样本数量又会大大增加,分类器性能会不会变好呢?于是本人在KCF的基础上做了个实验,扩大和缩小原始样本搜索区域。
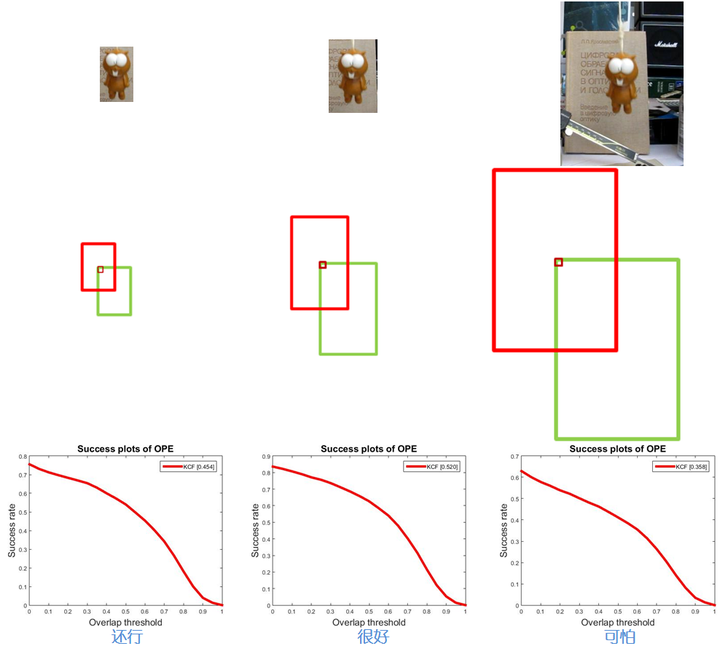
从结果可以看出,最左边的样本数量最少,质量还行,所以训练出来的分类器还可以;中间的样本数量和质量都不错,所以结果很好;右边的由于正样本质量太差,包含了太多背景信息,导致分类器误认为背景也是需要跟踪的目标了,所以即使它样本的数量增加到几万个了但是效果依旧很差。
也就是说,样本数量有了但质量还是很差。那么我们就不能既要样本的数量又要样本的质量吗?答案是可以的,来看看本文是如何提高样本质量的。
1.2提高样本质量。
提升样本质量的思想就一个字:剪。
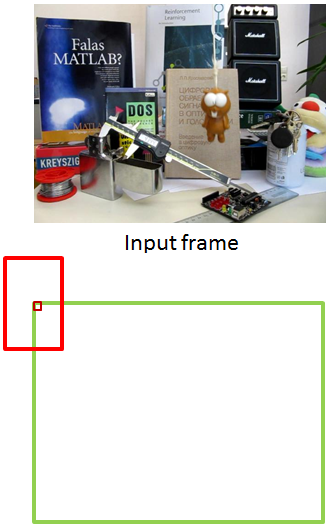
看了这幅图是不是有种恍然大悟的感觉啊?我们只要在整幅图片上采样,采下来之后再裁剪一下就能得到高质量(正样本里含有的干扰信息很少)的样本了。那么实际采样得到的样本就是这样的:
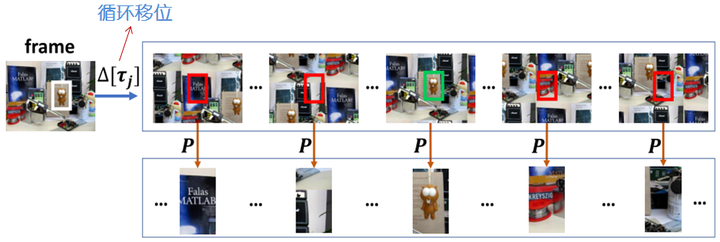
这样一来,数量上:样本的数量达到了十几万个,远超之前的几千个;质量上:正样本中包含了目标和周围一小块的信息,负样本中包含了整幅图片上的背景信息(这些信息在传统的CF中是被直接舍弃的)。
正因为利用了这么多背景信息,所以作者给这个方法起名叫背景感知相关滤波器法。但是,构思容易,实现难,下面看看作者是怎么在传统相关滤波器方法的基础上实现这个构思的。
2.理论规划
作者构思时的思路就是在循环采样的基础上再裁剪,所以实现时也是在传统做法的基础上增加了裁剪的步骤。
传统的相关滤波器训练是这样设计的(最小二乘+正则项):

上图中的x是正样本,中括号里是循环移位操作,h就是我们需要训练的相关滤波器。现在要加一步裁剪的步骤,就是下图中的矩阵P:

经过快速傅立叶变换投到频域中,为了使用ALM(增广拉格朗日法),构造出一个辅助变量g,并且g服从裁剪的操作(具体细节可见原文这里不展开叙述)。利用增广拉格朗日法之后得到:
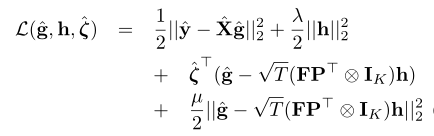
下面就要用到ADMM[3](交替求解)优化算法,把原问题转化成求解滤波器h和辅助变量g的两个子问题:
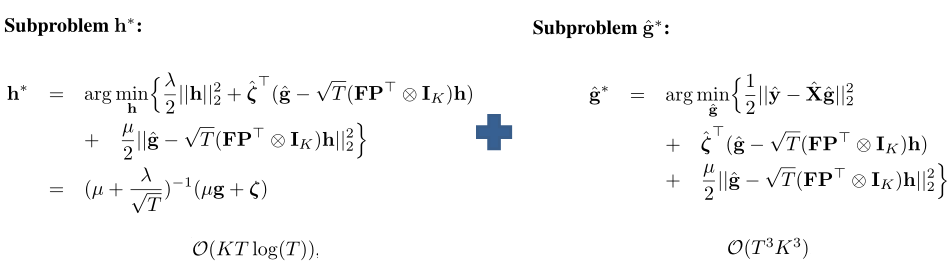
那么由于求解子问题g的时候计算量太大,所以必须做一些简化处理,以达到跟踪系统的实时性,这里作者无奈之下只有把g的求解问题拆分成T个独立的目标函数来做:

这样好像运算量小了一些,但是还是有求逆这种可怕的运算,所以作者最后再利用了Sherman-
Morrison formula(谢尔曼莫里森公式)对求逆这步计算进行简化:
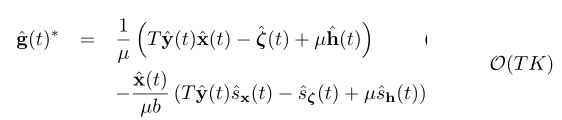
最后计算量就降得比较合理了。这里的T是整幅图拉成向量之后向量的维度大概是十几万,K是特征的层数。
最后模型更新策略还是跟传统CF一样的线性插值法:

3.实验
由于代码没公布,我没办法跑一下,只能用作者给的结果。总的来说,效果极其出色,速度也快得吓人。


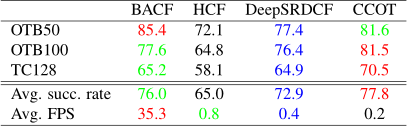
4.总结
本文在传统CF(相关滤波器)方法的基础上显著地增加了样本数量并通过裁剪操作提高了样本质量,在实现过程中又使用了优化和化简的技巧,最终使得跟踪器的效果和速度都达到了惊人的水平。
[1] K. Zhang, L. Zhang, and M.-H. Yang, “Real-time compressive tracking,” in ECCV, 2012.
[2] J. F. Henriques, R. Caseiro, P. Martins, and J. Batista. High-speed tracking with kernelized correlation filters. PAMI,37(3):583–596, 2015.
[3] S. Boyd. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Foundations and Trends in Machine Learning, 3:1–122, 2010.

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









