






 该研究提出了一种直接训练脉冲神经网络(SNN)的方法,解决了SNN在性能和效率上的挑战。通过神经元归一化(NeuNorm)技术和LIF模型的显式迭代实现,提高了SNN的训练速度和准确性。在N-MNIST、DVS-CIFAR10和CIFAR10数据集上,实验结果显示了优于以往工作的性能。此外,提出了一种简化编码方案,降低了对长时间窗口的依赖,从而加速了SNN的仿真过程。
该研究提出了一种直接训练脉冲神经网络(SNN)的方法,解决了SNN在性能和效率上的挑战。通过神经元归一化(NeuNorm)技术和LIF模型的显式迭代实现,提高了SNN的训练速度和准确性。在N-MNIST、DVS-CIFAR10和CIFAR10数据集上,实验结果显示了优于以往工作的性能。此外,提出了一种简化编码方案,降低了对长时间窗口的依赖,从而加速了SNN的仿真过程。
Direct Training for Spiking Neural Networks:Faster, Larger, Better
摘要
在新兴的神经形态硬件上实现节能的脉冲神经网络(SNN)正受到越来越多的关注。然而,由于缺乏有效的学习算法和有效的编程框架,SNN与人工神经网络(ANN)相比,还没有表现出具有竞争力的性能。我们从两个方面来解决这个问题:(1)提出了一种神经元归一化技术来调整神经选择性,并开发了一种用于深层SNN的直接学习算法。(2) 通过缩小速率编码窗口,并将(LIF)模型转换为显式迭代版本,提出了一种基于Pytorch的实现方法,用于大规模SNN的训练。就能够以数十倍的速度训练深度SNN。因此,我们在神经形态数据集(N-MNIST和DVS-CIFAR10)上取得了比报告的工作更好的准确度,并且在非脉冲数据集(CIFAR10)上取得了与现有ANN和预训练SNN相当的准确度。据我们所知,这是第一项在CIFAR10上直接训练高性能深层SNN的工作。
方法
LIF显式迭代模型
LIF模型通常用于描述神经元活动的行为,包括膜电位的更新和spike放电。
它描述为:
τ
d
u
d
t
=
−
u
+
I
,
u
<
V
t
h
\tau \tfrac{du}{dt}=-u+I ,u< V_{th}
τdtdu=−u+I,u<Vth (1)
fire a spike &
u
=
u
r
e
s
e
t
u=u_{reset}
u=ureset
u
≥
V
t
h
u\geq V_{th}
u≥Vth (2)
u
u
u是膜电位,
τ
\tau
τ是时间常数,
I
I
I是突触前输入,
V
t
h
V_{th}
Vth是给定的阈值,式(1)-(2)以更新触发重置机制的方式描述了脉冲神经元的行为(见图1a-b)。当膜电位达到一个给定的阈值时,神经元将触发一个脉冲,
u
u
u被重置为
u
r
e
s
e
t
u_{reset}
ureset;否则,神经元接受突触前刺激
I
I
I,并根据式(1)更新其膜电位。Figure 1如下:
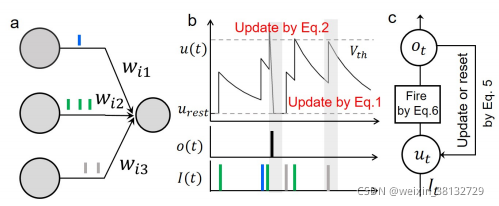
使用Euler method 解式(1):
u
t
+
1
=
(
1
−
d
t
τ
)
u
t
+
d
t
τ
I
u_{t+1}=(1-\frac{dt}{\tau })u_t+\frac{dt}{\tau }I
ut+1=(1−τdt)ut+τdtI (3)
然后式(3)中变成: u t + 1 = k τ 1 u t + ∑ W j o ( j ) u_{t+1}=k_{\tau1}u_t+\sum W_jo(j) ut+1=kτ1ut+∑Wjo(j) (4),
对式(4)添加更新、激发与重置机制,假设 u r e s e t = 0 u_{reset}=0 ureset=0,得到最后的更新式子为:
u t + 1 , n + 1 ( i ) = k τ 1 u t , n + 1 ( i ) ( 1 − o t , n + 1 ( i ) ) + ∑ j = 1 l ( n ) w n i j o t + 1 , n ( j ) u_{t+1,n+1}(i)=k_{\tau1}u_{t,n+1}(i)(1-o_{t,n+1}(i))+ \sum_{j=1}^{l(n)}w_{n_{ij}}o_{t+1,n}(j) ut+1,n+1(i)=kτ1ut,n+1(i)(1−ot,n+1(i))+∑j=1l(n)wnijot+1,n(j) (5)
o t + 1 , n + 1 ( i ) = f ( u t + 1 , n + 1 ( i ) − V t h ) o_{t+1,n+1}(i)=f(u_{t+1,n+1}(i)-V_{th}) ot+1,n+1(i)=f(ut+1,n+1(i)−Vth) (6)
式中,
n
n
n和
l
(
n
)
l(n)
l(n)分别表示第n层及其神经元数,
w
i
j
w_{ij}
wij为前层第j个神经元(n)到后层(n + 1)的第i个神经元的突触权值。
f
(
)
f()
f()是阶跃函数,式(5)-(6)揭示了
o
t
,
n
+
1
o_{t,n+1}
ot,n+1的激发活动将通过更新\激发重置机制影响下一状态
o
t
+
1
,
n
+
1
o_{t+1,n+1}
ot+1,n+1(见图1c)。如果神经元在时间步
t
t
t发出脉冲,则t+1步处的膜电位将通过项
1
−
o
j
t
,
n
+
1
1-o_{j_{t,n+1}}
1−ojt,n+1清除其衰减分量
k
τ
1
u
t
k_{\tau1}u_t
kτ1ut,反之亦然。

Neuron normalization (NeuNorm) 神经元归一化
考虑到两个卷积层之间的信号通信,位于第n层第f个特征图(FM)位置(i、j)的神经元接收卷积输入 I I I,并通过以下式子更新其膜电位:
u
t
+
1
,
n
+
1
(
i
,
j
)
=
k
τ
1
u
f
t
,
n
+
1
(
i
,
j
)
(
1
−
o
f
t
,
n
+
1
(
i
,
j
)
)
+
I
f
t
+
1
,
n
+
1
(
i
,
j
)
u_{t+1,n+1}(i,j)=k_{\tau1}u_{f_{t,n+1}}(i,j)(1-o_{f_{t,n+1}}(i,j))+ I_{f_{t+1,n+1}}(i,j)
ut+1,n+1(i,j)=kτ1uft,n+1(i,j)(1−oft,n+1(i,j))+Ift+1,n+1(i,j) (7)
I
f
t
+
1
,
n
+
1
(
i
,
j
)
=
∑
c
W
n
c
,
f
⊛
o
c
t
+
1
,
n
(
R
(
i
,
j
)
)
I_{f_{t+1,n+1}}(i,j)=\sum_{c}W_{n_{c,f}}\circledast o_{c_{t+1,n}}(R(i,j))
Ift+1,n+1(i,j)=∑cWnc,f⊛oct+1,n(R(i,j)) (8)
其中
W
n
c
,
f
W_{n_{c,f}}
Wnc,f表示层n中的第c个特征图和层n+1中的第f个特征图之间的权重核 。
⊛
\circledast
⊛表示卷积操作,
R
(
i
,
j
)
R(i,j)
R(i,j)表示位置
(
i
,
j
)
(i,j)
(i,j)的局部感受野。
由于二进制脉冲通信,训练SNN不可避免的问题是平衡整个激发率。也就是说,需要确保对突触前刺激做出及时和有选择性的反应,但要避免太多可能损害有效信息表征的峰值。从这个意义上讲,它要求刺激的强度保持在一个相对稳定的范围内,以避免随着网络的加深,活动消失或爆炸。
观察到神经元对来自不同特征图的刺激有反应,这促使我们提出一种辅助神经元方法,对于在不同特征图的相同空间位置的输入强度进行归一化(见图2):
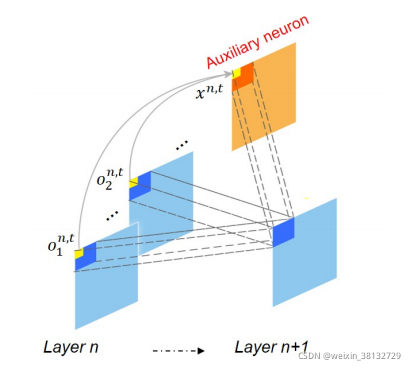
NeuNorm的说明:蓝色方块代表正常神经元FMs,橙色方块代表辅助神经元FMs。辅助神经元接收横向输入(实线)和激发信号(虚线),以控制向下一层发射的刺激强度。
辅助神经元状态
x
x
x的归一化:
x t + 1 , n ( i , j ) = k τ 2 x t , n ( i , j ) + v F ∑ f o f t + 1 , n ( i , j ) x_{t+1,n}(i,j)=k_{\tau2} x_{t,n}(i,j)+\frac{v}{F}\sum_{f}o_{f_{t+1,n}}(i,j) xt+1,n(i,j)=kτ2xt,n(i,j)+Fv∑foft+1,n(i,j) (9)
其中
k
τ
2
k_{\tau2}
kτ2为衰减因子,
v
v
v为常数比例因子,F为第n层特征图的数量。这样,Eq.(9)用动量项
k
τ
2
x
t
,
n
(
i
,
j
)
k_{\tau2} x_{t,n}(i,j)
kτ2xt,n(i,j)计算输入激发率的平均响应。为简便起见,我们设
k
τ
2
+
v
F
=
1
kτ2 + vF = 1
kτ2+vF=1。
接下来,假设辅助神经元接收来自同一层的横向输入,并通过可训练的权值
U
n
c
U_{n_{c}}
Unc发送信号来控制激发到下一层的刺激强度,后者与FM的大小相同。因此,下一层神经元的输入
I
I
I可以通过:
I f t + 1 , n + 1 ( i , j ) = ∑ W c , f n ⊛ ( o c t + 1 , n ( R ( i , j ) ) − U c n ( R ( i , j ) ) ⋅ x t + 1 , n ( R ( i , j ) ) ) I_{f_{t+1,n+1}}(i,j)=\sum W_{c,f}^{n}\circledast (o_{c_{t+1,n}}(R(i,j))-U_{c_{n}}(R(i,j))\cdot x_{t+1,n}(R(i,j))) Ift+1,n+1(i,j)=∑Wc,fn⊛(oct+1,n(R(i,j))−Ucn(R(i,j))⋅xt+1,n(R(i,j))) (10)
从等式(10)推断,NeuNorm方法通过使用输入统计数据(移动平均放电率)基本上使神经元活动正常化。基本操作与批标准化中的零均值操作相似。但NeuNorm有不同的目的和不同的数据处理方式(沿通道维度而不是批次维度规范化数据)。这种差异带来了一些可能更适合SNN的好处。首先,NeuNorm与神经元模型(LIF)兼容,无需额外操作,且易于神经病理学实现。除此之外,NeuNorm在生物学上更具合理性。事实上,生物视觉通路并不是相互依赖的。视网膜细胞对图像中特定离子的反应在同一层的相邻细胞反应中被标准化。例如,组归一化GN将同一层的FMs分成若干组,并沿通道维度对每组内的特征进行规范化。
Encoding and decoding schemes
为了处理各种刺激模式,SNN通常使用邻接编码方法来处理输入刺激。对于视觉识别任务,一种流行的编码方案是速率编码。在输入端,实值图像被转换成脉冲序列,其激发率与像素强度成正比。脉冲采样是概率的,例如遵循伯努利分布或泊松分布。在输出端,它计算最后一层中每个神经元在给定时间窗口内的放电率,以确定网络输出。然而,传统的速率编码需要很长的仿真时间才能达到良好的性能。为了解决这个问题,我们采用了一种更简单的编码方案,在不影响性能的情况下加快了仿真速度。
编码:长模拟时间的一个要求是减少将实际输入值转换为脉冲信号时的采样误差。具体地说,给定时间窗T,神经元可以通过T+1级的放电率来表示信息,即{0,
1
T
\frac{1}{T}
T1,…,1}(归一化)。显然,频率编码需要足够长的窗口才能达到满意的精度。为了解决这个问题,我们将第一层指定为编码层,并允许它接收脉冲和非脉冲信号(与各种数据集兼容)。换言之,编码层的神经元可以自然地处理来自神经形态数据集的均匀驱动脉冲序列,也可以将来自非脉冲数据集的实值信号转换为具有足够精度的脉冲序列。这样,在很大程度上保持了精度,而不太依赖于模拟时间。
解码:对长时间窗的另一个要求是网络输出的表示精度。为了缓解这种情况,采用投票策略对网络输出进行解码。我们将最后一层配置为投票层,由几个神经元群体组成,每个输出类由一个群体表示。这样,每个神经元在时域(给定时间窗口内的放电率)的表示精度的困难就转移到了空域(神经元组编码)。因此,对长模拟时间的要求显著降低。对于初始化,我们随机给每个神经元分配一个标签;而在训练期间,分类结果是通过计算所有组群的投票响应来确定的。
总之,我们从以上两个方面减少了对长期窗口的需求,这在某种意义上扩展了SNN在输入和输出端的表示能力。我们发现,之前关于ANN压缩的工作也利用了类似的编码方案(Tang、Hua和Wang 2017;Hubara、Soudry和Ran 2016)。这意味着,在不考虑内部较低精度的情况下,保持第一层和最后一层的较高精度对收敛性和性能非常重要。
Overall training implementation整体的训练
定义一个损失函数:在给定的时间窗口T内,平均投票结果与标签向量之间的均方误差
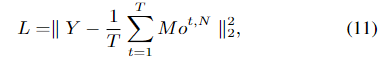
其中
o
t
,
N
o_{t,N}
ot,N在时间步长
t
t
t时最后一层N的投票向脉冲信号不仅通过层逐层空间域传播,而且通过时域影响神经元状态。因此,基于梯度的训练应该考虑这两个领域的这两个导数。在此基础上,我们将改进后的LIF模型、编码方案,并提出的NeuNorm集成到STBP方法中来培训网络。当计算损失函数L在时间步长
t
t
t处对第n层中的
u
u
u和
o
o
o的导数时,STBP从第(n+1)层传播梯度
∂
L
∂
o
i
t
,
n
+
1
\frac{\partial L}{\partial o_{i_{t,n+1}}}
∂oit,n+1∂L,和从时间步长
t
+
1
t+1
t+1传播梯度
∂
L
∂
o
i
t
+
1
,
n
\frac{\partial L}{\partial o_{i_{t+1,n}}}
∂oit+1,n∂L,如下:
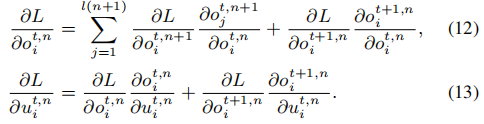
训练SNN中的一个关键问题是二进制脉冲活动的不可微特性。为了使其梯度可用,我们取矩形函数h(u)来近似峰值活性的导数(Wu等。2018)。它的表达:
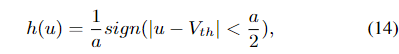


混淆矩阵:
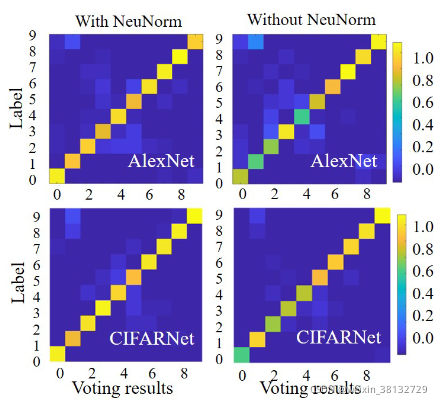
图6:带或不带NeuNorm表决输出的混淆矩阵。对角线上的高值表示正确识别,而其他任何地方的高值表示两个类别之间的混淆。


















 150
150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











