







mlflow不是机器学习框架,而是与机器学习框架无关的机器学习过程管理平台。
它是轻量极,侵入性比较低。
我把它单独拿出来是因为qlib平台的workflow工作流是使用mlflow来管理的。
MLflow Documentation — MLflow 1.28.0 documentation
用来管理机器学习生命周期的平台,我们平常使用的sklearn和pytorch都兼容。
01 安装
pip install mlflow依赖包还比较多,numpy, scipy, 还有整个flask技术栈,这个是给mlflow ui用的。
Installing collected packages: numpy, zipp, importlib-resources, MarkupSafe, typing-extensions, importlib-metadata, Mako, greenlet, sqlalchemy, alembic, pyyaml, pytz, pyparsing, packaging, click, pyjwt, oauthlib, charset-normalizer, idna, urllib3, certifi, requests, tabulate, six, databricks-cli, gunicorn, smmap, gitdb, gitpython, Werkzeug, itsdangerous, Jinja2, Flask, sqlparse, querystring-parser, scipy, cloudpickle, protobuf, entrypoints, websocket-client, docker, python-dateutil, pandas, prometheus-client, prometheus-flask-exporter, mlflow
02 mlflow UI
mlflow ui
打开本机的5000端口,可以看到精美的界面:
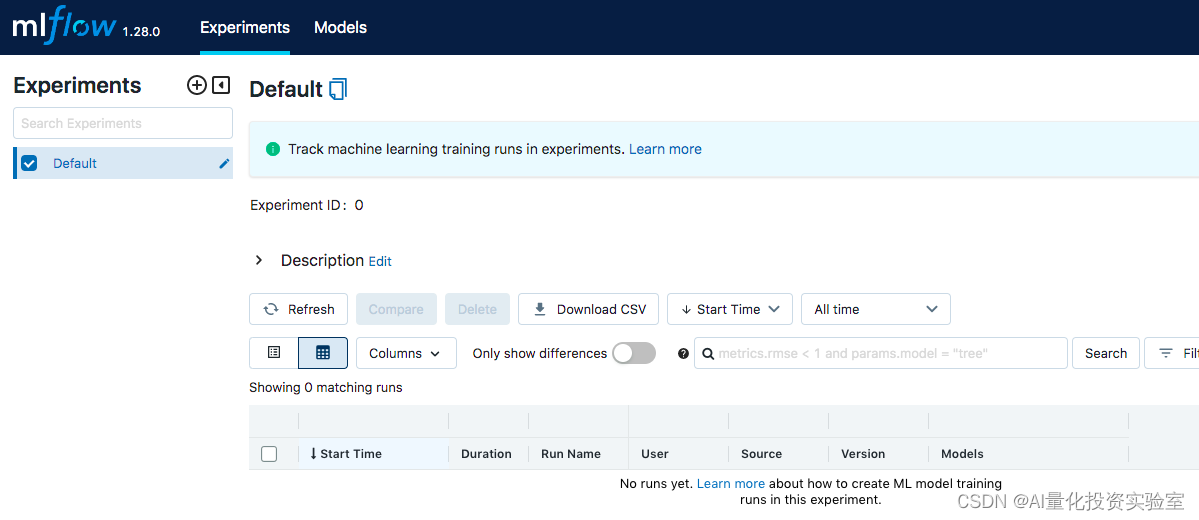
目前还没有在运行的实验与模型。
03 hello mlflow
import os
from random import random, randint
from mlflow import log_metric, log_param, log_artifacts
if __name__ == "__main__":
# 给参数打日志 (key-value 对), 参数1:随机整形
log_param("param1", randint(0, 100))
# Log a metric; metrics can be updated throughout the run
log_metric("foo", random())
log_metric("foo", random() + 1)
log_metric("foo", random() + 2)
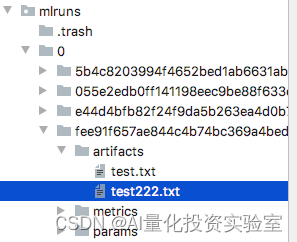
# 当前目录下创建outputs文件夹,并写text.txt。
if not os.path.exists("outputs"):
os.makedirs("outputs")
with open("outputs/test.txt", "w") as f:
f.write("hello world2!")
log_artifacts("outputs")
写入三种日志: 参数,metric-指标,artifacts一些输出文件。
param,metric都是key-value的形式写入。
artifacts是备份文件夹。
04 tutorial
到github上下载代码:
GitHub - mlflow/mlflow: Open source platform for the machine learning lifecycle
github如果不稳定,可以通过gitee下载:
MLflow: MLflow 是由 Apache Spark 技术团队开源的一个机器学习平台,主打开放性: 开放接口:可与任意 ML 库、算法、部署工具或编程语言一起使用
pip install mlflow[extras]这里会安装sklearn。
或者单独安装sklearn:
pip install scikit-learn在examples目录下会有不少官方的例子可以学习。
# The data set used in this example is from http://archive.ics.uci.edu/ml/datasets/Wine+Quality
# P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis.
# Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547-553, 2009.
import os
import warnings
import sys
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
import mlflow
import mlflow.sklearn
def eval_metrics(actual, pred):
rmse = np.sqrt(mean_squared_error(actual, pred))
mae = mean_absolute_error(actual, pred)
r2 = r2_score(actual, pred)
return rmse, mae, r2
if __name__ == "__main__":
warnings.filterwarnings("ignore")
np.random.seed(40)
# Read the wine-quality csv file (make sure you're running this from the root of MLflow!)
wine_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), "wine-quality.csv")
data = pd.read_csv(wine_path)
# Split the data into training and test sets. (0.75, 0.25) split.
train, test = train_test_split(data)
# The predicted column is "quality" which is a scalar from [3, 9]
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
alpha = float(sys.argv[1]) if len(sys.argv) > 1 else 0.5
l1_ratio = float(sys.argv[2]) if len(sys.argv) > 2 else 0.5
with mlflow.start_run():
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
print("Elasticnet model (alpha=%f, l1_ratio=%f):" % (alpha, l1_ratio))
print(" RMSE: %s" % rmse)
print(" MAE: %s" % mae)
print(" R2: %s" % r2)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.sklearn.log_model(lr, "model")
sklearn里fit, predict之后,把参数,结果指标还是模型一并保存。
相当于帮我们管理整个实验过程。
















 4166
4166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











