







https://github.com/open-mmlab/mmocr/blob/main/README_zh-CN.md
https://mmocr.readthedocs.io/en/dev-1.x/get_started/quick_run.html
介绍
MMOCR 是基于 PyTorch 和 mmdetection 的开源工具箱,专注于文本检测,文本识别以及相应的下游任务,如关键信息提取。 它是 OpenMMLab 项目的一部分。
安装
安装依赖包:
根据cuda版本下载pytorch
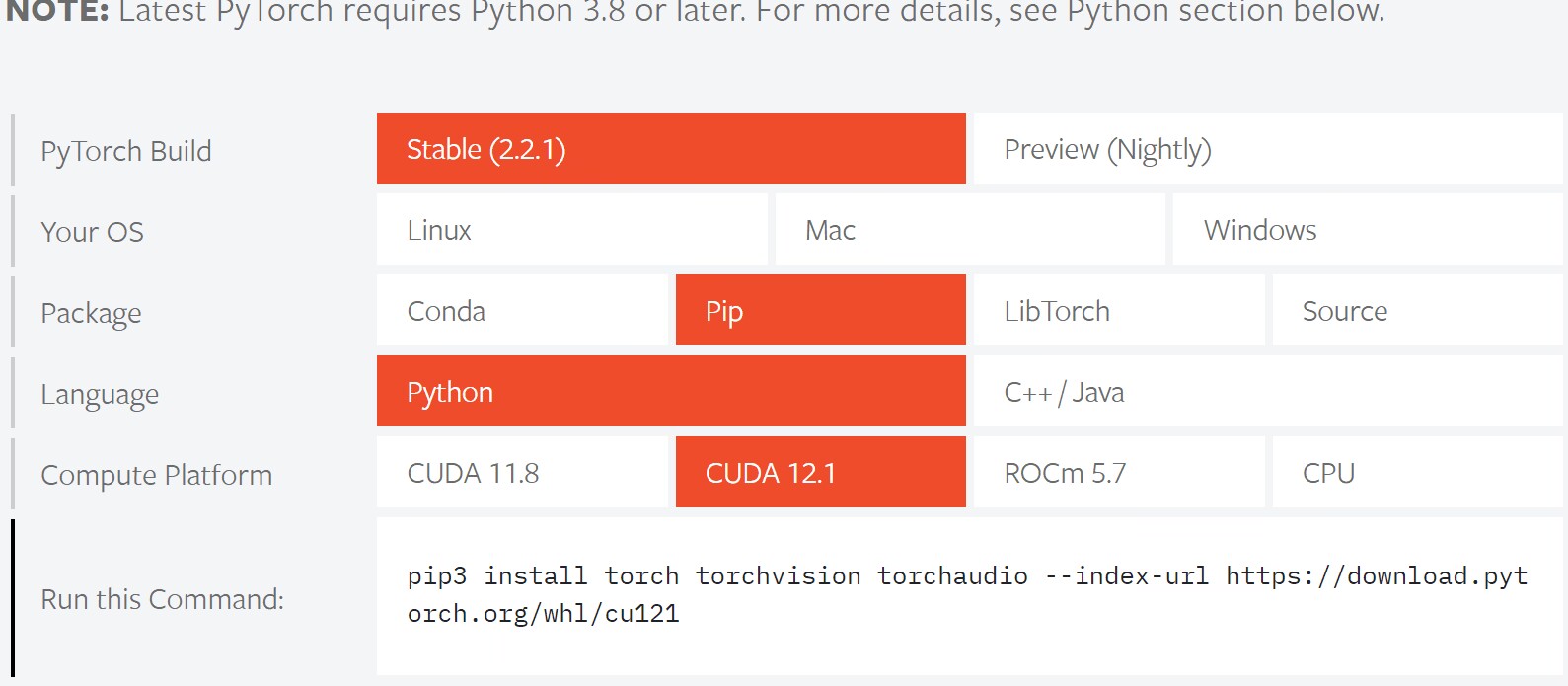
pip install mmdet
pip install mmcv
安装mmocr
git cone https://github.com/open-mmlab/mmocr.git
pip install -e .
OCR代码:
from mmocr.apis import MMOCRInferencer
ocr = MMOCRInferencer(det='DBNet', rec='CRNN')
ocr('demo/demo_text_ocr.jpg', show=True, print_result=True)
安装报错:
ERROR: Could not build wheels for mmcv, which is required to install pyproject.toml-based projects
那把pip安装换成mim安装
pip install -U openmim
–》
mim install mmcv
没有解决
安装visual studio 2022
pip install mmcv
还是报相同错 。参考https://blog.csdn.net/qq_44042678/article/details/131486896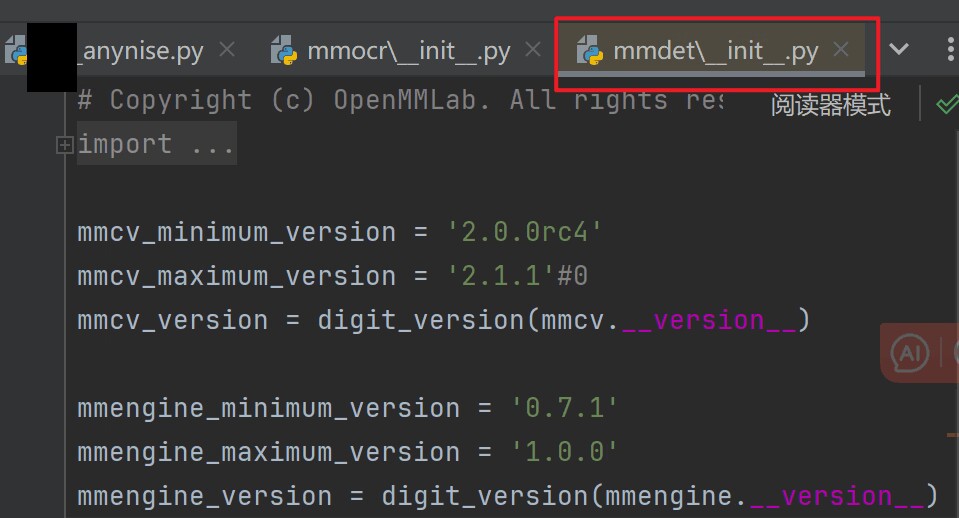
实践
识别结果:
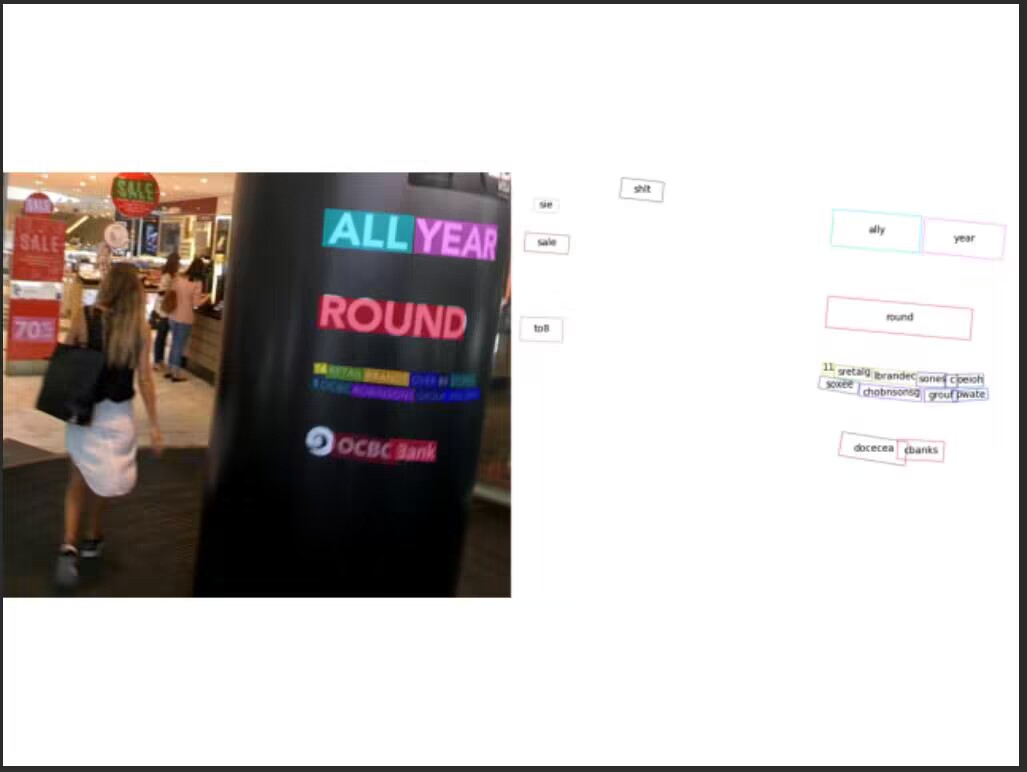
可以使用别的检测和识别模型:
使用textsnake算法
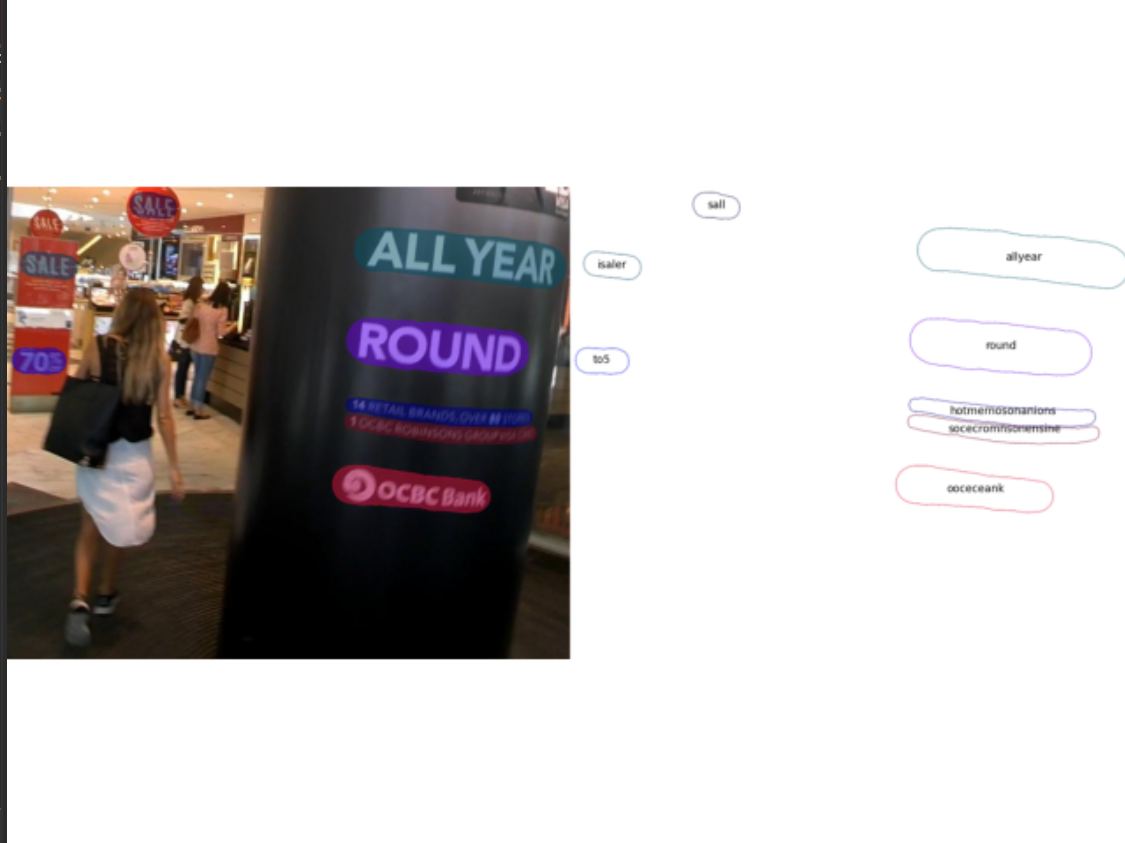
其他算法:
其他
训练识别模型用自己的字典

训练其他语言识别模型吗


















 3388
3388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









