






Title
题目
Semi-Supervised Medical Image Segmentation Using Adversarial Consistency Learning and Dynamic Convolution Network
半监督医学图像分割:基于对抗一致性学习和动态卷积网络的方法
01
文献速递介绍
医学图像分割在计算辅助诊断和治疗研究中扮演着重要角色,因为它能够在异常图像中提取重要的器官或病变。近年来,许多基于监督学习的编码器-解码器网络,如U-Net [1]、U-Net++、H-DenseUNet 等,在医学图像分割方面取得了显著的成果。然而,这些技术的成功在很大程度上依赖于大量的像素级标记数据,但在实践中标注医学图像通常非常昂贵。其中一个原因是医学图像由于低对比度和噪声干扰通常显示出较差的视觉效果。此外,医学图像的标注需要比自然图像更多的专业知识。因此,几乎不可能建立大量带有高精度标签的医学图像数据集。
相比监督学习,半监督学习是解决弱监督学习中数据不完全监督问题的一种新学习范式。它主要利用少量标记数据和大量未标记数据进行联合训练。显然,半监督学习对于医学图像分割而言至关重要,并且更符合实际临床场景的需求。
主要的半监督医学图像分割方法大致可以分类为一致性学习 、对抗学习 、自训练 、对比学习 和协作训练 。本文将重点讨论一致性学习和对抗学习。一致性学习通常使用不同的扰动进行一致性正则化来训练网络。其中最具代表性的方法之一是自我集成Mean Teacher (MT) ,它利用基于扰动的一致性损失在未标记数据上的自我集成教师模型与学生模型之间,同时结合在标记数据上的监督损失。在MT的基础上,随后改进的方法侧重于选择不同的数据扰动和特征扰动以实现性能增益。准确地说,分割网络在生成一致的伪标签方面的质量决定了网络对未标记数据的知识挖掘能力。
对于对抗学习,用于医学图像分割的生成对抗网络(GAN)主要涉及两个子网络,即鉴别器和生成器。鉴别器旨在识别输入样本是来自真实数据还是生成器的输出。生成器的目标是让鉴别器无法区分真实数据和分割网络输出之间的差异。一旦鉴别器无法确定输入的来源,生成的样本被认为与真实数据足够接近。两个网络交替更新并相互促进。
Abstract
摘要
Popular semi-supervised medical image segmentation networks often suffer from error supervisionfromunlabeled data since they usually use consistency learningunder different data perturbations to regularize model training. These networks ignore the relationshipbetween labeledand unlabeleddata, and only compute single pixel-levelconsistency leading to uncertain prediction results. Besides,these networks often require a large number of parameterssince their backbone networks are designed depending onsupervised image segmentation tasks. Moreover, these networks often face a high over-fittingrisk since a small numberof training samples are popular for semi-supervised imagesegmentation. To address the above problems, in this paper,we propose a novel adversarial self-ensembling networkusing dynamic convolution (ASE-Net) for semi-supervisedmedical image segmentation. First, we use an adversarial consistency training strategy (ACTS) that employs twodiscriminators based on consistency learning to obtainprior relationships between labeled and unlabeled data.The ACTS can simultaneously compute pixel-level andimage-level consistency of unlabeled data under differentdata perturbations to improve the prediction quality oflabels. Second, we design a dynamic convolution-basedbidirectional attention component (DyBAC) that can beembedded in any segmentation network, aiming at adaptively adjusting the weights of ASE-Net based on thestructural information of input samples. This componenteffectively improves the feature representation ability ofASE-Net and reduces the overfitting risk of the network.The proposed ASE-Net has been extensively tested onthree publicly available datasets, and experiments indicatethat ASE-Net is superior to state-of-the-art networks, andreduces computational costs and memory overhead.
流行的半监督医学图像分割网络通常受到错误监督的影响,因为它们通常使用一致性学习在不同的数据扰动下来正则化模型训练。这些网络忽略了标记和未标记数据之间的关系,仅计算单个像素级的一致性,导致预测结果不确定。此外,这些网络通常需要大量参数,因为它们的骨干网络是针对监督图像分割任务设计的。而且,这些网络往往面临高过拟合风险,因为半监督图像分割常常只有少量训练样本。
为了解决上述问题,在本文中,我们提出了一种新颖的用于半监督医学图像分割的对抗自我集成网络,采用动态卷积(ASE-Net)。首先,我们采用对抗一致性训练策略(ACTS),使用两个基于一致性学习的鉴别器来获取标记和未标记数据之间的先验关系。ACTS能够同时计算不同数据扰动下未标记数据的像素级和图像级一致性,从而提高标签预测的质量。其次,我们设计了基于动态卷积的双向注意力组件(DyBAC),可以嵌入任何分割网络中,旨在根据输入样本的结构信息自适应调整ASE-Net的权重。这个组件有效地提高了ASE-Net的特征表示能力,并减少了网络的过拟合风险。
Method
方法
In this paper, we propose an adversarial self-ensemblingnetwork (ASE-Net) for semi-supervised medical image segmentation. As shown in Fig. 1, our ASE-Net consists ofsegmentation networks and discriminator networks. The segmentation networks consist of a student model and a teachermodel. The student model has the same structure as the teachermodel and both of them are based on the encoder-decoderstructure; the difference is that the former is trained by theloss function while the latter is the exponential moving average(EMA) of the student model weights. The discriminator networks consist of convolutional layers, the proposed DyBAC,and the global average pooling, whose specific structure of ourASE-Net is shown in Fig. 1.
本文中,我们提出了一种用于半监督医学图像分割的对抗自我集成网络(ASE-Net)。如图1所示,我们的ASE-Net包括分割网络和鉴别器网络。分割网络由学生模型和教师模型组成。学生模型与教师模型具有相同的结构,都基于编码器-解码器结构;它们的区别在于前者通过损失函数训练,而后者是学生模型权重的指数移动平均(EMA)。鉴别器网络由卷积层、提出的动态卷积双向注意力组件(DyBAC)和全局平均池化层组成,我们ASE-Net的具体结构如图1所示。
Conclusion
结论
In this work, we have proposed ASE-Net for semisupervised medical image segmentation. First, the proposedACTS effectively combines adversarial learning and consistency learning, using adversarial training to maximize consistency learning. This allows the network to learn quicklythe prior relationship between unlabeled and labeled data,and further mines the potential knowledge existing in unlabeled data. Then, our proposed DyBAC adaptively adjusts theparameter values of convolutional kernels according to inputsamples, which not only effectively avoids network overfittingand improves the feature representation ability of the networkbut also reduces the memory overhead. Experiments on threepublicly available benchmark datasets demonstrate that ourproposed ASE-Net outperforms state-of-the-art methods andprovides an effective solution for semi-supervised medicalimage segmentation, significantly reducing network overfittingrisk and uncertainty prediction in consistency learning.
在这项工作中,我们提出了ASE-Net用于半监督医学图像分割。首先,提出的ACTS有效地结合了对抗学习和一致性学习,利用对抗训练来最大化一致性学习。这使得网络能够快速学习未标记数据与标记数据之间的先验关系,并进一步挖掘未标记数据中存在的潜在知识。然后,我们提出的DyBAC根据输入样本自适应调整卷积核的参数值,这不仅有效避免了网络过拟合,提高了网络的特征表示能力,还减少了内存开销。在三个公开可用的基准数据集上的实验证明,我们提出的ASE-Net优于现有的方法,在半监督医学图像分割中提供了有效的解决方案,显著降低了网络过拟合风险和一致性学习中的预测不确定性。
Figure
图
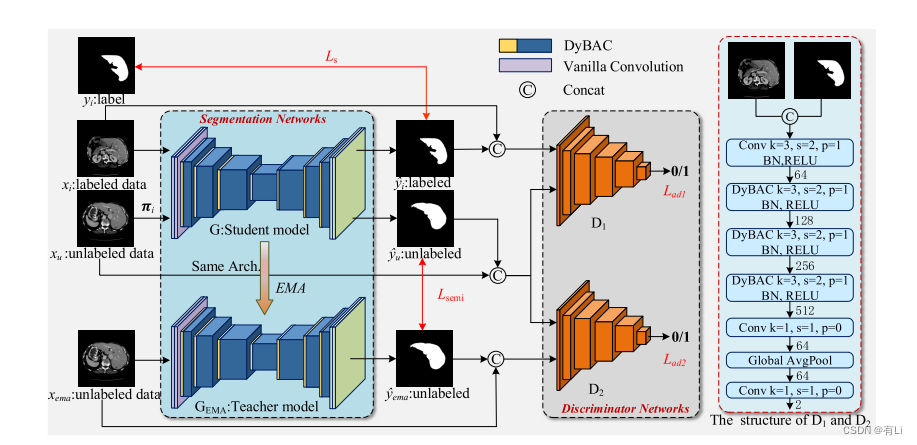
Fig. 1. The framework of the proposed ASE-Net. The ASE-Net consists of two main parts: the segmentation networks (left) and the discriminatornetworks (right). The segmentation network is based on the encoder-decoder architecture. The right figure shows the detailed structure of thediscriminative network, where k, s, and p represent the kernel size, the stride, and the padding of convolutional kernels, respectively. The discriminatorsare unnecessary in the inference stage.
图 1. 提出的ASE-Net框架。ASE-Net包括两个主要部分:分割网络(左侧)和鉴别器网络(右侧)。分割网络基于编码器-解码器架构。右侧图显示了鉴别网络的详细结构,其中k,s和p分别表示卷积核的核大小,步幅和填充。在推理阶段,鉴别器是不必要的。

Fig. 2. The structure of DyBAC. (a) Spatial attention, (b) Dynamic convolution. The dynamic convolutional kernels are generated mainly based onthe channel and spatial information of samples. For different input samples, the values of convolution kernel parameters change adaptively
图 2. DyBAC的结构。(a) 空间注意力, (b) 动态卷积。动态卷积核主要基于样本的通道和空间信息生成。对于不同的输入样本,卷积核参数的值会自适应地改变。
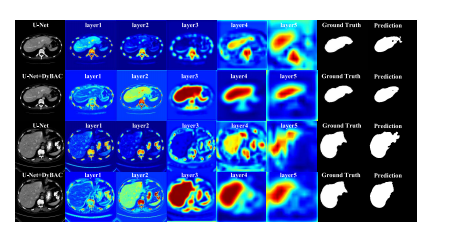
Fig. 3. Visualization of the feature heat maps for each convolutional layerin the encoding phase. The first and third rows are feature heat mapsof U-Net employing the standard convolution, and the second and fourthrows are feature heat maps of U-Net employing DyBAC. The encoding ofU-Net has five stages, and we replace the convolution after the first layerwith the proposed dynamic convolution-based bi-directional attentioncomponent (DyBAC). From left to right, the feature maps are shown fromshallow to deep layers respectively, and different colors indicate differentspatial weights.
图3对编码阶段每个卷积层的特征热图进行可视化。第一行和第三行是使用标准卷积的U-Net的特征热图,第二行和第四行是使用DyBAC的U-Net的特征热图。U-Net的编码阶段有五个阶段,我们在第一层后用提出的基于动态卷积的双向注意力组件(DyBAC)替换卷积操作。从左到右显示浅层到深层的特征图,不同颜色表示不同的空间权重。

Fig. 4. The learning curves on the dermoscopy image training and validation sets by utilizing 2,594 labeled data, the blue and red curves representU-Net++ employing DyBAC and the gray and yellow curves representU-Net++ employing the standard convolution. (a) The accuracy curveof training and validation sets on the dermoscopy image dataset and(b) The loss curve of training and validation sets on the dermoscopyimage dataset.
Fig. 4. 利用2,594个标记数据在皮肤镜图像训练集和验证集上的学习曲线,蓝色和红色曲线代表使用DyBAC的U-Net++,灰色和黄色曲线代表使用标准卷积的U-Net++。(a) 皮肤镜图像数据集上训练集和验证集的准确率曲线,以及 (b) 皮肤镜图像数据集上训练集和验证集的损失曲线。
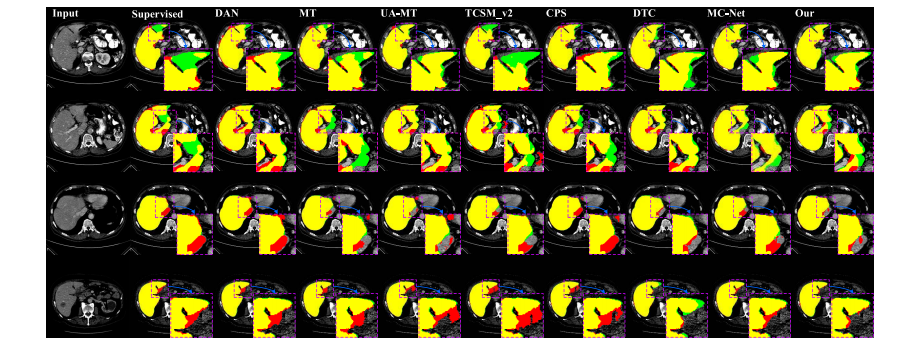
Fig. 5. Visualization result of different methods on the LiTS testing set by utilizing 10% labeled data of training set. Green is the ground truth, red isthe segmentation result, and yellow is the overlap region of the segmentation result and ground truth. Therefore, fewer green and red regions implybetter segmentation results.
图5利用训练集10%标记数据的LiTS测试集上不同方法的可视化结果。绿色表示地面真实值,红色表示分割结果,黄色表示分割结果与地面真实值的重叠区域。因此,较少的绿色和红色区域意味着更好的分割结果。

Fig. 6. Visualization result of different methods on the dermoscopy image validation set by utilizing 20% labeled data of training set.
图. 6. 利用训练集20%标记数据的皮肤镜图像验证集上不同方法的可视化结果。
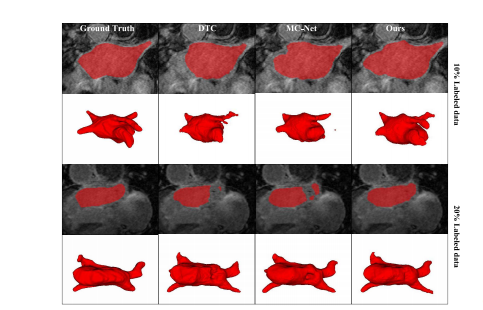
Fig. 7. Visualization result of different methods on the left atriumvalidation set by utilizing 10% and 20% of the labeled data in the trainingset, respectively.
图. 7. 分别利用训练集中10%和20%标记数据的左心房验证集上不同方法的可视化结果。
Table
表
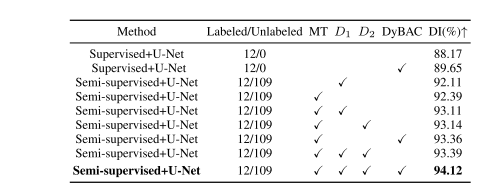
TABLE I comparison of ablation experiments on the lits-liver testing set by utilizing 10% labeled data of the training set. the best values are in bold
表1 比较在LITS肝脏测试集上利用训练集10%标记数据的消融实验结果。最佳数值用粗体表示。
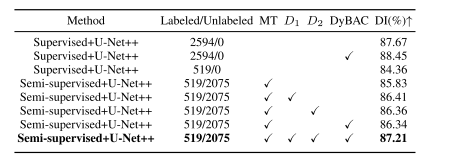
TABLE II comparison of ablation experiments on the dermoscopy image validation set utilizing different proportions of labeled data from the training set. the best values are in bold
表II 在皮肤镜图像验证集上利用不同比例的训练集标记数据进行消融实验的比较。最佳数值用粗体表示。
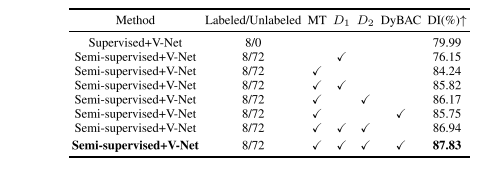
TABLE III comparison of ablation experiments on the left atrium validation set by utilizing 10% labeled data of training set. the best values are in bold
表 III 在左心房验证集上利用训练集10%标记数据的消融实验比较。最佳数值用粗体表示。

TABLE IV quantitative comparison between our method and other comparison methods on the lits-liver testing set by utilizing 10% labeled data of training set. the backbone network of all evaluated methods is u-net. the best values are in bold
表 IV利用训练集10%标记数据在LITS肝脏测试集上我们方法与其他比较方法的定量比较。所有评估方法的骨干网络均为U-Net。最佳数值用粗体表示。

TABLE V quantitative comparison between our method and other comparison methods on the lits-liver test dataset by utilizing 20% labeled data of train dataset. the backbone network of all evaluated methods is u-net. the best values are in bold
表V 利用训练集20%标记数据在LITS肝脏测试数据集上我们方法与其他比较方法的定量比较。所有评估方法的骨干网络均为U-Net。最佳数值用粗体表示。
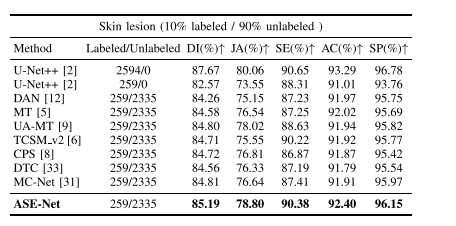
TABLE VI quantitative comparison between our method and other comparison methods on the dermoscopy image validation set by utilizing 10% labeled data of the training set. the backbone network of all evaluated methods is u-net++. the best values are in bold
表VI 我们方法与其他比较方法在利用训练集10%标记数据的皮肤镜图像验证集上的定量比较。所有评估方法的骨干网络均为U-Net++。最佳数值用粗体表示。
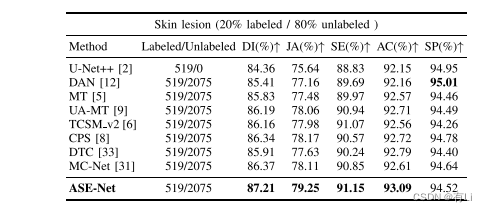
TABLE VII quantitative comparison between our method and other comparison methods on the dermoscopy image validation set by utilizing 20% labeled data of the training set. the backbone network of all evaluated methods is u-net++. the best values are in bold
表 VII 利用训练集20%标记数据的皮肤镜图像验证集上我们方法与其他比较方法的定量比较。所有评估方法的骨干网络均为U-Net++。最佳数值用粗体表示。

TABLE VIII quantitative comparison between our method and other comparison methods on the left atrium validation set by utilizing 10% labeled data of training set. the backbone network of all evaluated methods is v-net. the best values are in bold
表VIII 利用训练集10%标记数据的左心房验证集上我们方法与其他比较方法的定量比较。所有评估方法的骨干网络均为V-Net。最佳数值用粗体表示。

TABLE IX quantitative comparison between our method and other comparison methods on the left atrium validation set by utilizing 20% labeled data of training set. the backbone network of all evaluated methods is v-net. the best values are in bold
表 IX利用训练集20%标记数据的左心房验证集上我们方法与其他比较方法的定量比较。所有评估方法的骨干网络均为V-Net。最佳数值用粗体表示。
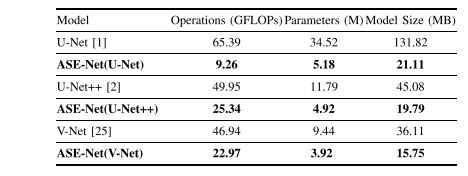
TABLE X comparison of the efficiency of different networks, the best values are in bold
表X不同网络效率的比较,最佳数值用粗体表示。
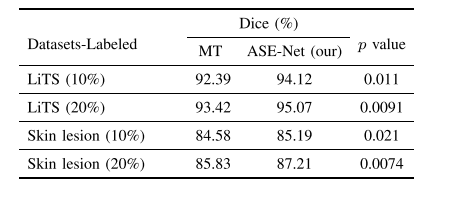
TABLE XI statistical significance of the proposed ase-net and baseline mt methods on different datasets
表XI提出的ASE-Net与基线MT方法在不同数据集上的统计显著性















 3195
3195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









