






Title
题目
Large Language Models for Automated Synoptic Reports and Resectability Categorization in Pancreatic Cancer
用于胰腺癌自动化综述报告和可切除性分类的大型语言模型
Background
背景
Structured radiology reports for pancreatic ductal adenocarcinoma (PDAC) improve surgical decision-making over free-text reports, but radiologist adoption is variable. Resectability criteria are applied inconsistently.
胰腺导管腺癌(PDAC)的结构化放射学报告比自由文本报告更能改善外科决策,但放射科医生的接受程度各不相同。可切除性标准的应用不一致。
Method
方法
In this institutional review board–approved retrospective study, 180 consecutive PDAC staging CT reports on patients referred to the authors’ European Society for Medical Oncology–designated cancer center from January to December 2018 were included. Reports were reviewed by two radiologists to establish the reference standard for 14 key findings and National Comprehensive Cancer Network (NCCN) resectability category. GPT-3.5 and GPT-4 (accessed September 18–29, 2023) were prompted to create synoptic reports from original reports with the same 14 features, and their performance was evaluated (recall, precision, F1 score). To categorize resectability, three prompting strategies (default knowledge, in-context knowledge, chain-of-thought) were used for both LLMs. Hepatopancreaticobiliary surgeons reviewed original and artificial intelligence (AI)–generated reports to determine resectability, with accuracy and review time compared. The McNemar test, t test, Wilcoxon signed-rank test, and mixed effects logistic regression models were used where appropriate.
在本机构审查委员会批准的回顾性研究中,纳入了2018年1月至12月期间在作者所在的欧洲肿瘤学会指定的癌症中心接受检查的180份连续胰腺导管腺癌(PDAC)分期CT报告。两位放射科医生审查了报告,以建立14个关键发现和国家综合癌症网络(NCCN)可切除性类别的参考标准。GPT-3.5和GPT-4(访问日期为2023年9月18日至29日)被提示从原始报告中创建包含相同14个特征的综合报告,并评估其表现(召回率、精确度、F1分数)。为了对可切除性进行分类,对两种大型语言模型使用了三种提示策略(默认知识、上下文知识、链式思维)。肝胰胆外科医生审查了原始报告和人工智能(AI)生成的报告,以确定可切除性,并比较了准确性和审查时间。根据适用情况,使用了McNemar检验、t检验、Wilcoxon符号秩检验和混合效应逻辑回归模型。
Conclusion
结论
GPT-4 created near-perfect PDAC synoptic reports from original reports. GPT-4 with chain-of-thought achieved high accuracy in categorizing resectability. Surgeons were more accurate and efficient using AI-generated reports.
PT-4从原始报告中创建了近乎完美的胰腺导管腺癌(PDAC)综合报告。使用链式思维提示策略的GPT-4在可切除性分类中达到了高准确性。外科医生使用AI生成的报告更准确且更高效。
Results
结果
GPT-4 outperformed GPT-3.5 in the creation of synoptic reports (F1 score: 0.997 vs 0.967, respectively). Compared with GPT-3.5, GPT-4 achieved equal or higher F1 scores for all 14 extracted features. GPT-4 had higher precision than GPT-3.5 for extracting superior mesenteric artery involvement (100% vs 88.8%, respectively). For categorizing resectability, GPT-4 outperformed GPT-3.5 for each prompting strategy. For GPT-4, chain-of-thought prompting was most accurate, outperforming in-context knowledge prompting (92% vs 83%, respectively; P = .002), which outperformed the default knowledge strategy (83% vs 67%, P* < .001). Surgeons were more accurate in categorizing resectability using AI-generated reports than original reports (83% vs 76%, respectively; P = .03), while spending less time on each report (58%; 95% CI: 0.53, 0.62).
GPT-4在创建综合报告方面表现优于GPT-3.5(F1分数分别为0.997对0.967)。与GPT-3.5相比,GPT-4在提取的所有14个特征上都获得了相同或更高的F1分数。特别是在提取肠系膜上动脉受累情况时,GPT-4的精确度高于GPT-3.5(分别为100%对88.8%)。在可切除性分类中,GPT-4在每种提示策略上都优于GPT-3.5。对于GPT-4,链式思维提示策略最为准确,优于上下文知识提示策略(分别为92%对83%;P = .002),而上下文知识提示策略又优于默认知识策略(分别为83%对67%;P < .001)。外科医生使用AI生成的报告在可切除性分类上的准确性高于使用原始报告(分别为83%对76%;P = .03),同时每份报告的审阅时间减少了(58%;95% CI: 0.53, 0.62)。
Figure
图
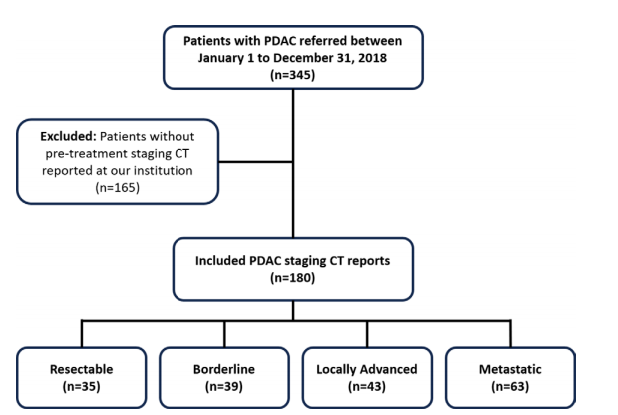
Figure 1: Study flowchart. The resectability category reference standard was determined by independent review of original radiology reports by radiologists using National Comprehensive Cancer Network criteria. PDAC = pancreatic ductal adenocarcinoma.
图1: 研究流程图。可切除性类别的参考标准由放射科医生独立审查原始放射学报告并使用国家综合癌症网络(NCCN)标准确定。PDAC = 胰腺导管腺癌。
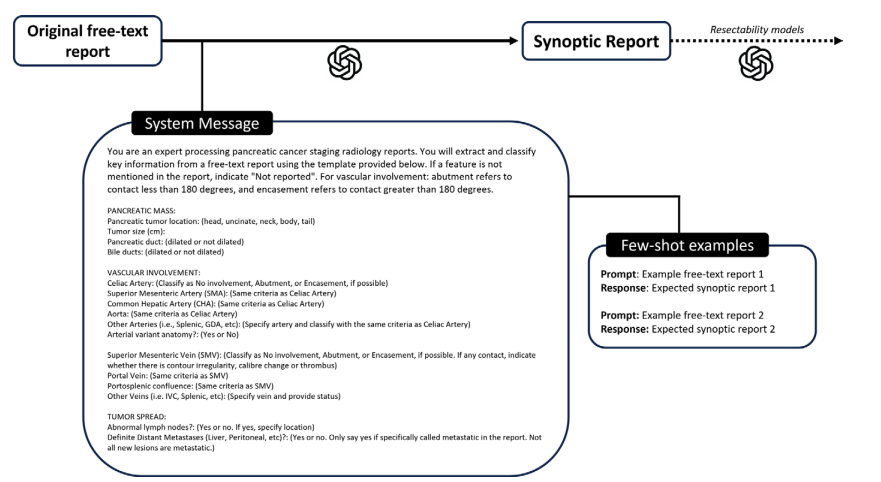
Figure 2: Diagram shows prompting strategy for models tasked with extracting key findings to create synoptic pancreatic cancer staging reports from original reports. The provided template included key features related to the pancreatic mass, vascular involvement, and tumor spread. Two example reports with expected responses were included (few-shot learning). Identical prompts were used for both GPT-3.5 and GPT-4. Generated synoptic reports were later used to prompt a different set of models for categorizing tumor resectability. GDA = gastroduodenal artery, IVC = inferior vena cava.
图2: 图示显示了模型提取关键发现并从原始报告创建胰腺癌分期综合报告的提示策略。提供的模板包括与胰腺肿块、血管受累和肿瘤扩散相关的关键特征。包含了两个示例报告及预期响应(少样本学习)。GPT-3.5和GPT-4使用相同的提示。生成的综合报告随后用于提示另一组模型进行肿瘤可切除性分类。GDA = 胃十二指肠动脉,IVC = 下腔静脉。
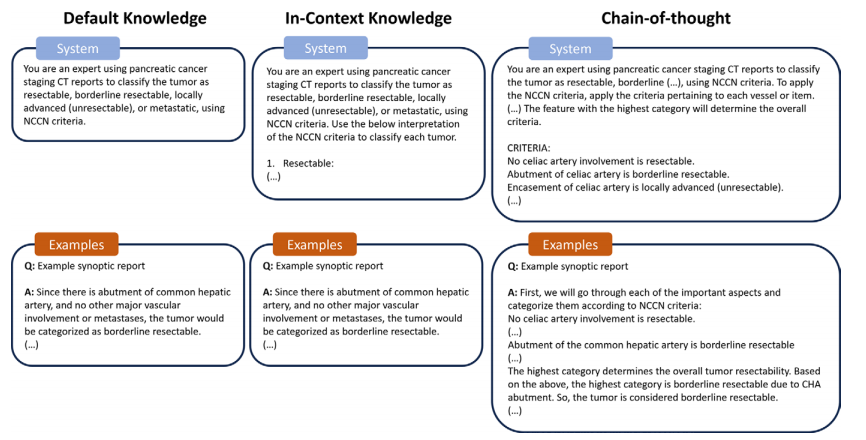
Figure 3: Diagram shows three prompting strategies for models tasked with categorizing tumor resectability. All three strategies were used for GPT-3.5 and GPT-4. The first strategy (“default knowledge”) relies on model pretraining by asking the model to categorize the tumor into resectable, borderline resectable, locally advanced, or metastatic based on National Comprehensive Cancer Network (NCCN) criteria. The second strategy (“in-context knowledge”) provides the model with explicit definitions of each resectability category. The final strategy (“chain-of-thought”) breaks down NCCN criteria on a per-feature basis and then provides a more stepwise approach to arriving at the final categorization that involves categorizing each vessel or feature and then assigning the highest category to the entire tumor.
图3: 图示显示了用于模型肿瘤可切除性分类的三种提示策略。所有三种策略均用于GPT-3.5和GPT-4。第一种策略(“默认知识”)依赖于模型的预训练,通过要求模型根据国家综合癌症网络(NCCN)标准将肿瘤分类为可切除、边缘可切除、局部晚期或转移性。第二种策略(“上下文知识”)为模型提供每个可切除性类别的明确定义。最后一种策略(“链式思维”)按每个特征分解NCCN标准,然后采用更逐步的方法,通过对每个血管或特征进行分类,再将最高类别分配给整个肿瘤来得出最终分类。
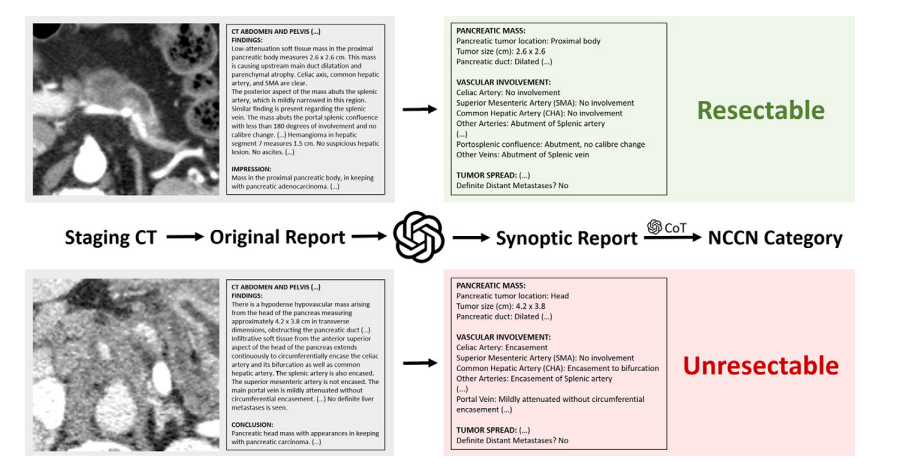
Figure 4: Two example cases of pancreatic cancer, with truncated original reports, artificial intelligence–generated synoptic reports, and National Comprehensive Cancer Network (NCCN) resectability categorizations by GPT-4 using chain-of-thought (CoT) prompting. In the first example (top row), after creating an accurate synoptic report, GPT-4 with chain-of-thought prompting correctly categorized the tumor as resectable. In the second example (bottom row), the original report describes extensive vascular involvement including encasement of the celiac artery. Vascular involvement was correctly reflected in the synoptic report, and GPT-4 with chain-of-thought prompting correctly categorized the tumor as unresectable (locally advanced). Original and synoptic reports are shown in truncated form.artery involvement (100% vs 94%), common hepatic artery involvement (98.3% vs 95.2%), other arterial involvement (100% vs 97.2%), and major vein involvement (100% vs 97.5%). Forthe other five categories, both models achieved 100% precision (tumor size, pancreatic duct dilatation, aortic involvement, variant arterial anatomy, and other vein involvement).
图4: 胰腺癌的两个示例病例,包含截断的原始报告、人工智能生成的综合报告以及GPT-4使用链式思维(CoT)提示进行的国家综合癌症网络(NCCN)可切除性分类。在第一个示例(第一行)中,GPT-4在创建准确的综合报告后,使用链式思维提示正确地将肿瘤分类为可切除。在第二个示例(第二行)中,原始报告描述了包括腹腔动脉包绕在内的广泛血管受累。血管受累情况在综合报告中得到了正确反映,GPT-4使用链式思维提示正确地将肿瘤分类为不可切除(局部晚期)。原始报告和综合报告均以截断形式显示。
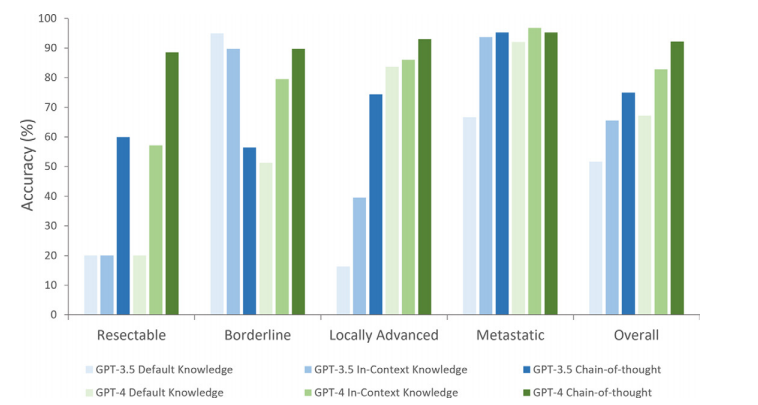
Figure 5: Bar graphs show accuracy of models categorizing tumor resectability using National Comprehensive Cancer Network criteria. GPT-4 performed better than GPT-3.5 overall for each prompting strategy. Both GPT-3.5 and GPT-4 “default knowledge” models performed poorly overall, but “in-context knowledge” improved performance significantly. Chain-of-thought increased performance further. GPT-4 chainof-thought performed best in categorizing tumors (accuracy, 92%).
图5: 条形图显示了模型使用国家综合癌症网络(NCCN)标准对肿瘤可切除性进行分类的准确性。GPT-4在每种提示策略上的整体表现优于GPT-3.5。两种模型的“默认知识”策略整体表现较差,但“上下文知识”显著提高了性能。链式思维进一步提高了性能。GPT-4的链式思维提示在肿瘤分类中表现最佳(准确性为92%)。
Table
表
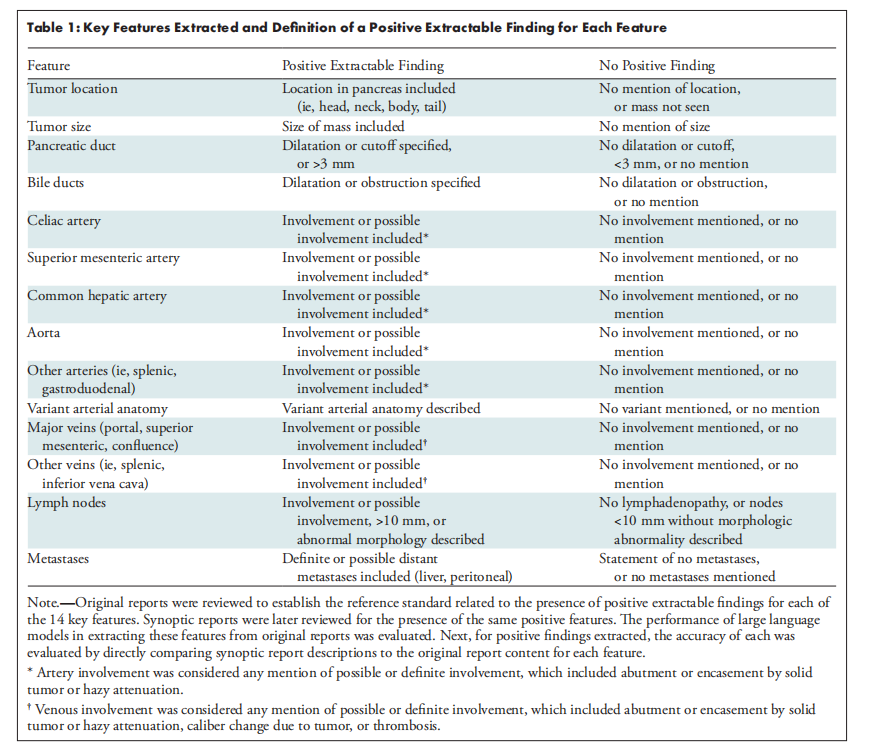
Table 1: Key Features Extracted and Definition of a Positive Extractable Finding for Each Feature
表1:提取的关键特征及每个特征的阳性可提取发现的定义
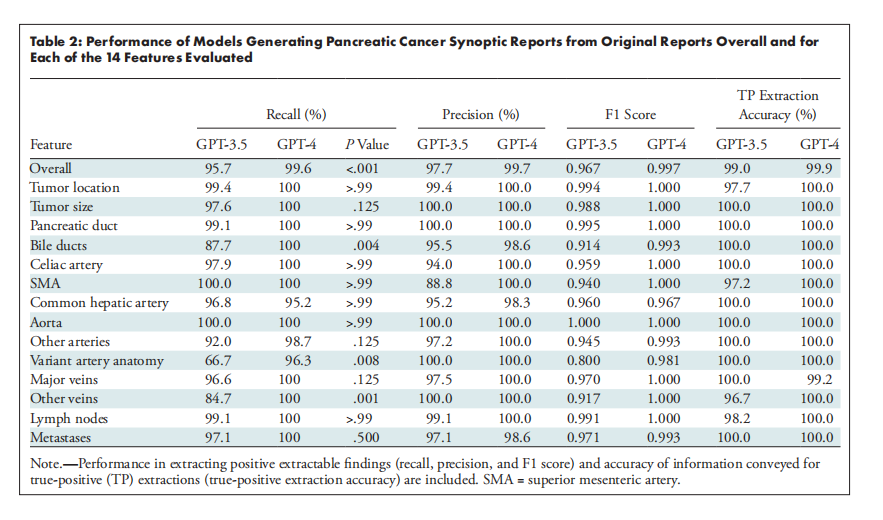
Table 2: Performance of Models Generating Pancreatic Cancer Synoptic Reports from Original Reports Overall and for Each of the 14 Features Evaluated
表2:模型从原始报告生成胰腺癌综合报告的整体表现及每个14个特征的评估















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









