






Title
题目
Image-level supervision and self-training for transformer-basedcross-modality tumor segmentation
基于图像级监督和自训练的跨模态肿瘤分割转换器模型。
01
文献速递介绍
深度学习在各种医学图像分析应用中展现了出色的性能和潜力(Chen等,2022)。尤其是在医学图像分割中,深度学习取得了相当于专家手动注释的准确度(Minaee等,2021)。然而,这些突破受到模型在面对未知领域数据时性能下降问题的制约(Torralba和Efros,2011)。这一问题在医学成像中尤为重要,因为分布转换非常常见。在所有领域对数据进行标注既低效又难以实现,特别是在图像分割中,专家级像素级标签的生成代价高昂且难以获得(Prevedello等,2019)。因此,构建能够在没有额外标注的情况下跨领域良好泛化的模型是一个亟需解决的挑战。
特别地,跨模态泛化是减少数据依赖性和扩大深度神经网络可用性的关键贡献。这类模型的应用非常广泛,因为一种成像模态缺少带注释的训练样本是很常见的。例如,增强型T1加权(T1ce)MR图像的获取是前庭神经鞘瘤(VS)检测中最常用的协议。为了避免肿瘤无限制增长导致不可逆的听力丧失,准确诊断和描绘VS至关重要。然而,为了减少T1ce成像的扫描时间并减轻使用钆对比剂的风险,高分辨率T2加权(hrT2)图像最近在临床工作流程中越来越受欢迎(Dang等,2020)。因此,现有的带注释的T1ce数据库可以用来解决在hrT2图像上进行VS分割时缺乏训练数据的问题。
Abatract
摘要
Deep neural networks are commonly used for automated medical image segmentation, but models willfrequently struggle to generalize well across different imaging modalities. This issue is particularly problematicdue to the limited availability of annotated data, both in the target as well as the source modality, makingit difficult to deploy these models on a larger scale. To overcome these challenges, we propose a new semisupervised training strategy called MoDATTS. Our approach is designed for accurate cross-modality 3D tumorsegmentation on unpaired bi-modal datasets. An image-to-image translation strategy between modalities is usedto produce synthetic but annotated images and labels in the desired modality and improve generalization to theunannotated target modality. We also use powerful vision transformer architectures for both image translation(TransUNet) and segmentation (Medformer) tasks and introduce an iterative self-training procedure in the latertask to further close the domain gap between modalities, thus also training on unlabeled images in the targetmodality. MoDATTS additionally allows the possibility to exploit image-level labels with a semi-supervisedobjective that encourages the model to disentangle tumors from the background. This semi-supervisedmethodology helps in particular to maintain downstream segmentation performance when pixel-level labelscarcity is also present in the source modality dataset, or when the source dataset contains healthy controls.The proposed model achieves superior performance compared to other methods from participating teams inthe CrossMoDA 2022 vestibular schwannoma (VS) segmentation challenge, as evidenced by its reported topDice score of 0.87± 0.04 for the VS segmentation. MoDATTS also yields consistent improvements in Dice scoresover baselines on a cross-modality adult brain gliomas segmentation task composed of four different contrastsfrom the BraTS 2020 challenge dataset, where 95% of a target supervised model performance is reached whenno target modality annotations are available. We report that 99% and 100% of this maximum performancecan be attained if 20% and 50% of the target data is additionally annotated, which further demonstrates thatMoDATTS can be leveraged to reduce the annotation burden.
深度神经网络通常用于自动医学图像分割,但这些模型在不同的成像模态之间往往难以很好地泛化。这一问题尤其严重,因为在目标和源模态中注释数据的可用性有限,使得在更大范围内部署这些模型变得困难。为了解决这些挑战,我们提出了一种新的半监督训练策略,称为MoDATTS。我们的方法旨在对未配对的双模态数据集进行精确的跨模态3D肿瘤分割。模态之间的图像到图像翻译策略用于在所需模态中生成合成但带有注释的图像和标签,并提高对未注释目标模态的泛化能力。
我们还使用了强大的视觉转换器架构来执行图像翻译(TransUNet)和分割(Medformer)任务,并在后续的任务中引入了迭代的自训练过程,以进一步缩小模态之间的领域差距,从而在目标模态中的未标注图像上进行训练。MoDATTS还允许利用具有半监督目标的图像级标签,以鼓励模型将肿瘤与背景分离。这种半监督方法特别有助于在源模态数据集中存在像素级标签稀缺,或者源数据集中包含健康对照的情况下保持下游分割性能。
所提出的模型在CrossMoDA 2022听神经瘤(VS)分割挑战赛中,相较于其他参赛团队的方法,表现出色,其VS分割的Dice评分为0.87±0.04。此外,MoDATTS在跨模态成人脑胶质瘤分割任务中也表现出相对于基线的Dice评分的一致改进,该任务包含来自BraTS 2020挑战赛数据集的四种不同对比度的图像。当没有目标模态注释数据时,MoDATTS达到目标监督模型性能的95%。我们报告,当额外注释20%和50%的目标数据时,可以分别达到99%和100%的最大性能,这进一步表明MoDATTS可以用于减少注释负担。
Method
方法
Let us consider the case where we want to segment images 𝑋 insome target modality 𝑇 and obtaining ground truth segmentation labels𝑌𝑇 is too costly due to resource, time or other constraints, a commonscenario in segmentation appraoches. However, a distinct dataset of thesame pathology of interest is readily available with annotations, but ina different source modality 𝑆. The objective of this work thus is to traina segmentation model effective at segmenting 𝑋𝑇 using the available𝑋𝑆* images and 𝑌𝑆 annotations. Note that the datasets are considered tobe unpaired. Furthermore, our proposed method allows incorporatingtwo types of images in the source modality 𝑆: pathological patients+𝑋𝑆 with their associated tumor segmentation +𝑌𝑆 , as well as (optional)healthy control patients with only imaging data −𝑋𝑆 . This we term the‘‘weak labels’’ of the semi-supervised objective.We propose then a 2-stage training approach. First, source-totarget modality image translation with a secondary segmentation objective. Second, target modality tumor segmentation using synthetic𝑋𝑆𝑦𝑛/ −𝑋𝑆𝑦𝑛 images and +𝑌𝑆𝑦𝑛 labels generated in the previous stagewith an optional semi-supervised objective. Iterative self-training canalso be used to re-introduce pseudo-labels segmented on the realtarget dataset 𝑋𝑇 with the desired confidence level back into thesegmentation stage. This is repeated until all +𝑌𝑇 labels are producedwith satisfactory confidence.
让我们考虑这样一种情况:我们希望在某个目标模态 𝑇 中分割图像 𝑋,但由于资源、时间或其他限制,获取其真实分割标签 𝑌**𝑇 的成本太高,这是分割方法中常见的场景。然而,有一个针对相同病理的不同来源模态 𝑆 的独立数据集,且附有注释。此项工作的目标是在使用可用的 𝑋𝑆 图像和 𝑌𝑆 注释的情况下,训练出一个能够有效分割 𝑋𝑇 的分割模型。请注意,这些数据集被认为是不成对的。此外,我们提出的方法允许在源模态 𝑆 中结合两种类型的图像:带有肿瘤分割注释的病理患者图像 +𝑋𝑆 及其相关的肿瘤分割标签 +𝑌𝑆,以及(可选的)仅包含成像数据的健康对照患者图像 −𝑋𝑆。我们将这种情况称为半监督目标的“弱标签”。
我们提出了一种两阶段训练方法。首先,通过一个次要分割目标进行源到目标模态的图像翻译。其次,使用在前一阶段生成的合成 𝑋𝑆𝑦𝑛 / −𝑋𝑆𝑦𝑛 图像和 +𝑌𝑆𝑦𝑛 标签以及可选的半监督目标进行目标模态的肿瘤分割。迭代自训练也可以用来重新引入在实际目标数据集 𝑋𝑇 上分割出伪标签的部分,并将其以所需的置信水平重新加入分割阶段。这一过程重复进行,直到所有 +𝑌**𝑇 标签都被生成且达到了令人满意的置信度。
Conclusion
结论
MoDATTS is a new 3D transformer-based domain adaptation framework to handle unpaired cross-modality medical image segmentationwhen the target modality lacks annotated samples. We propose a selftrained variant relying on the supervision from synthetic translatedimages and self-training, bridging the performance gap related to domain shifts in cross-modality tumor segmentation and outperformingother baselines in such scenarios. We offer as well a semi-supervisedvariant that additionally leverages diseased and healthy weak labelsto extend the training to unannotated target images. We show thatthis annotation-efficient setup helps to maintain consistent performanceon the target modality even when source pixel-level annotations arescarce. MoDATTS’s ability to achieve 99% and 100% of a target supervised model performance when respectively 20% and 50% of thetarget data is annotated further emphasizes that our approach can helpto mitigate the lack of annotations.
MoDATTS是一种新的基于3D转换器的领域自适应框架,旨在处理目标模态缺乏标注样本时的未配对跨模态医学图像分割问题。我们提出了一种自训练变体,依赖于来自合成翻译图像的监督和自训练,弥合了跨模态肿瘤分割中的领域转换性能差距,并在这种场景下表现优于其他基线方法。我们还提供了一种半监督变体,进一步利用病理和健康的弱标签来扩展对未标注目标图像的训练。我们展示了这种高效注释的设置,即使在源像素级注释稀缺的情况下,也有助于在目标模态上保持一致的性能。MoDATTS在目标数据分别标注20%和50%的情况下,能够达到目标监督模型性能的99%和100%,进一步强调了我们的方法有助于缓解标注不足的问题。
Figure
图
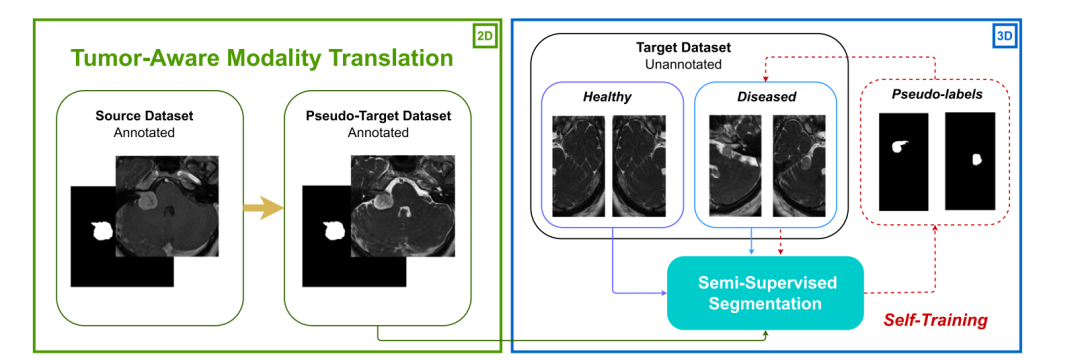
Fig. 1. Overview of MoDATTS. Stage 1 (green) consists of generating realistic target images from source data by training cyclic cross-modality translation. In stage 2 (blue),segmentation is trained in a semi-supervised approach on a combination of synthetic labeled and real unlabeled target modality images. Finally, pseudo-labeling is performed andthe segmentation model is refined through several self-training iterations.
图1. MoDATTS概述。阶段1(绿色)包括通过训练循环跨模态翻译,从源数据生成逼真的目标图像。在阶段2(蓝色)中,分割模型通过半监督方法在合成的带标签图像和真实的无标签目标模态图像的组合上进行训练。最后,进行伪标签生成,并通过多次自训练迭代来优化分割模型。
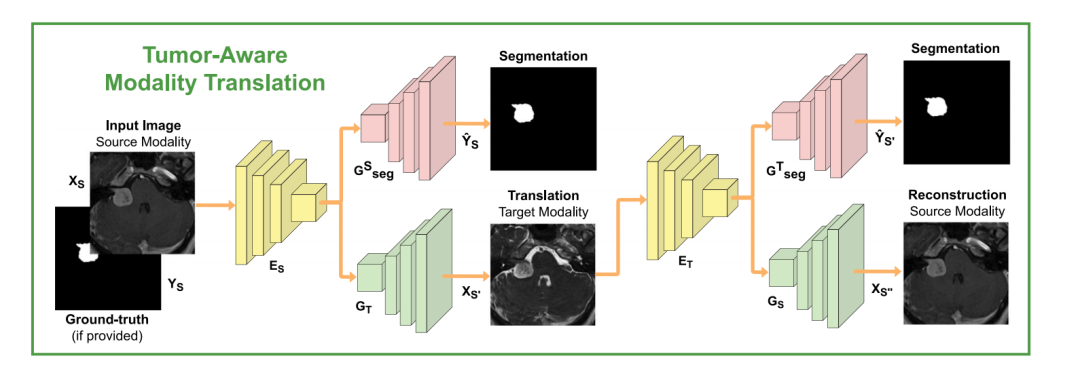
Fig. 2. Overview of the proposed tumor-aware cross-modality translation. The model is trained to translate between modalities in a CycleGAN approach. 𝐺**𝑇 ◦𝐸**𝑆 and 𝐺**𝑆 ◦𝐸**𝑇encoder–decoders respectively perform S → T and T → S modality translations. Same latent representations are shared with co-trained segmentation decoders 𝐺𝑆𝑠𝑒𝑔 and 𝐺𝑇𝑠𝑒𝑔 topreserve the semantic information related to the tumors. Note that the T → S → T translation loop is not shown for readability. We note that the latter does not yield segmentationpredictions since we assume no annotations are provided for the target modality.
图2. 提出的肿瘤感知跨模态翻译的概述。模型通过CycleGAN方法在模态之间进行翻译训练。编码器-解码器组合𝐺**𝑇 ◦ 𝐸**𝑆 和 𝐺**𝑆 ◦ 𝐸**𝑇 分别执行 S → T 和 T → S 模态翻译。相同的潜在表示与共同训练的分割解码器 𝐺𝑆𝑠𝑒𝑔 和 𝐺𝑇𝑠𝑒𝑔 共享,以保留与肿瘤相关的语义信息。为了便于阅读,T → S → T 翻译循环未显示。需要注意的是,由于假设没有为目标模态提供注释,因此该翻译循环不会产生分割预测。
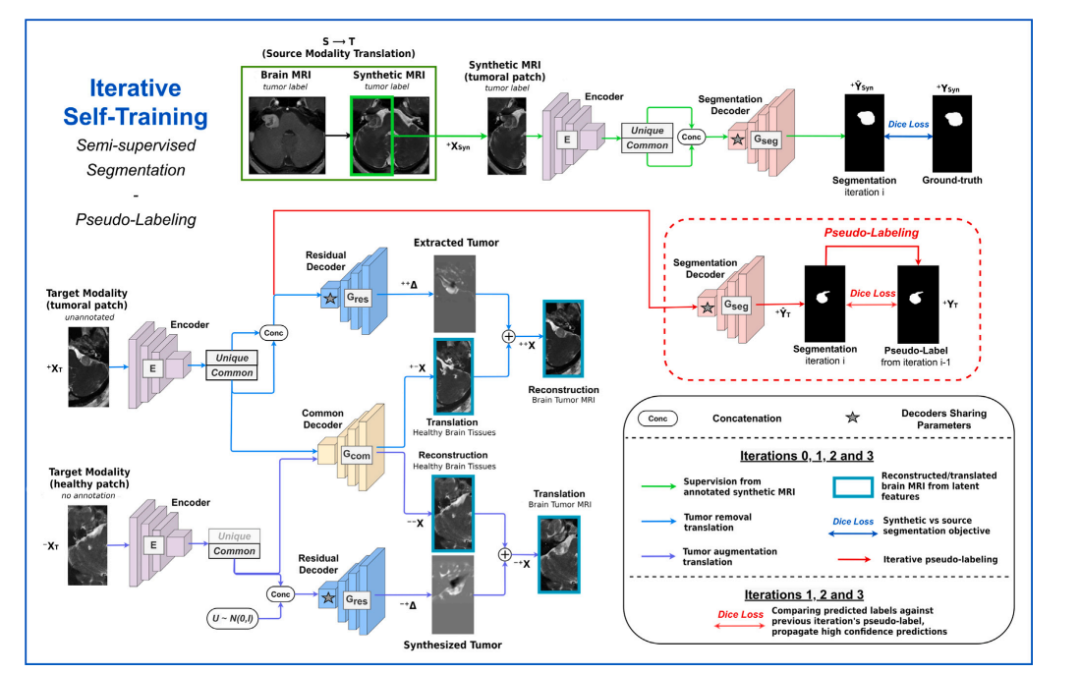
Fig. 3. Overview of the segmentation stage. A segmentation decoder 𝐺𝑠𝑒𝑔 is trained for tumor segmentation on annotated synthetic images resulting from stage 1. Simultaneouslya common decoder 𝐺𝑐𝑜𝑚 and a residual decoder 𝐺𝑟𝑒𝑠 are jointly trained for semi-supervised tumor delineation on real target images by performing pathological → control (tumorremoval) and control → pathological (tumor augmentation) translations. The segmentation decoder shares parameters with the residual decoder to benefit from this semi-supervisedobjective. Finally, The segmentation encoder–decoder 𝐺𝑆𝑒𝑔◦𝐸 is used to generate pseudo-labels for unannotated target images. The model is then further refined through severalself-training iterations.
图3. 分割阶段概述。分割解码器 𝐺𝑠𝑒𝑔 在第一阶段生成的带注释的合成图像上训练,用于肿瘤分割。同时,通用解码器 𝐺𝑐𝑜𝑚 和残差解码器 𝐺𝑟𝑒𝑠 联合训练,用于在真实目标图像上进行半监督肿瘤描绘,通过执行病理学 → 控制(肿瘤移除)和控制 → 病理学(肿瘤增强)翻译。分割解码器与残差解码器共享参数,以从这一半监督目标中获益。最后,分割编码器-解码器 𝐺𝑆𝑒𝑔◦𝐸 用于生成未标注目标图像的伪标签。然后,通过多次自训练迭代进一步优化模型
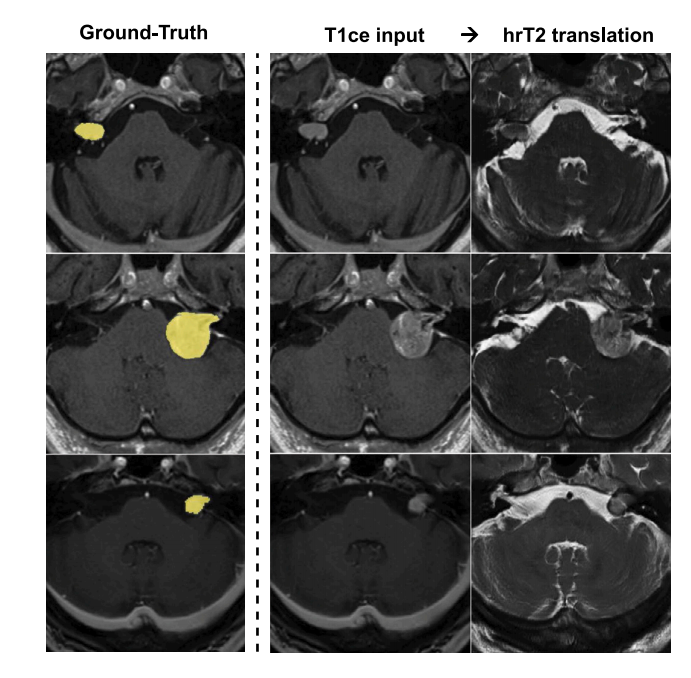
Fig. 4. Cross-modality translation examples for the CrossMoDA dataset. We displayseveral T1ce → hrT2 translations along with the VS segmentation ground truth. Tumorstructures are preserved in the pseudo hrT2 images.
图4. CrossMoDA数据集的跨模态翻译示例。我们展示了多个T1ce → hrT2的翻译结果及VS分割的真实标签。伪hrT2图像中保留了肿瘤结构。
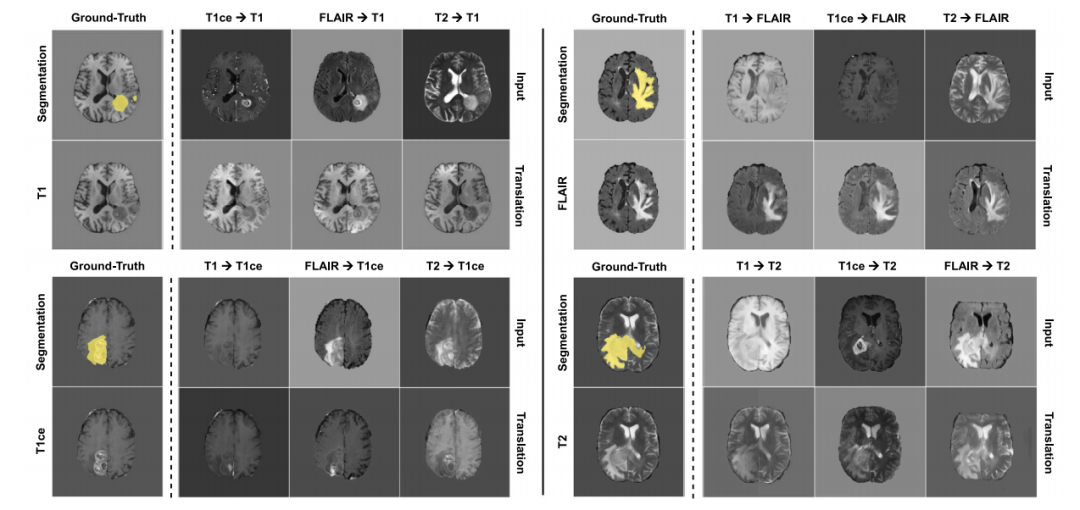
Fig. 5. Cross-modality translation examples for the BraTS dataset. Each group of images represents all possible translations towards a specific modality (T1, T1ce, FLAIR or T2) forone case. For visual evaluation of the method we also show the corresponding ground truth target images and the whole tumor segmentations. The resulting visual appearancesdiffer depending on the source modality, but tumor information is retained across all translations.
图5. BraTS数据集的跨模态翻译示例。每组图像表示针对一个病例的所有可能的特定模态(T1, T1ce, FLAIR或T2)的翻译。为便于对方法的视觉评估,我们还展示了相应的真实目标图像和整个肿瘤的分割结果。翻译后的视觉外观因源模态而异,但肿瘤信息在所有翻译中均被保留。
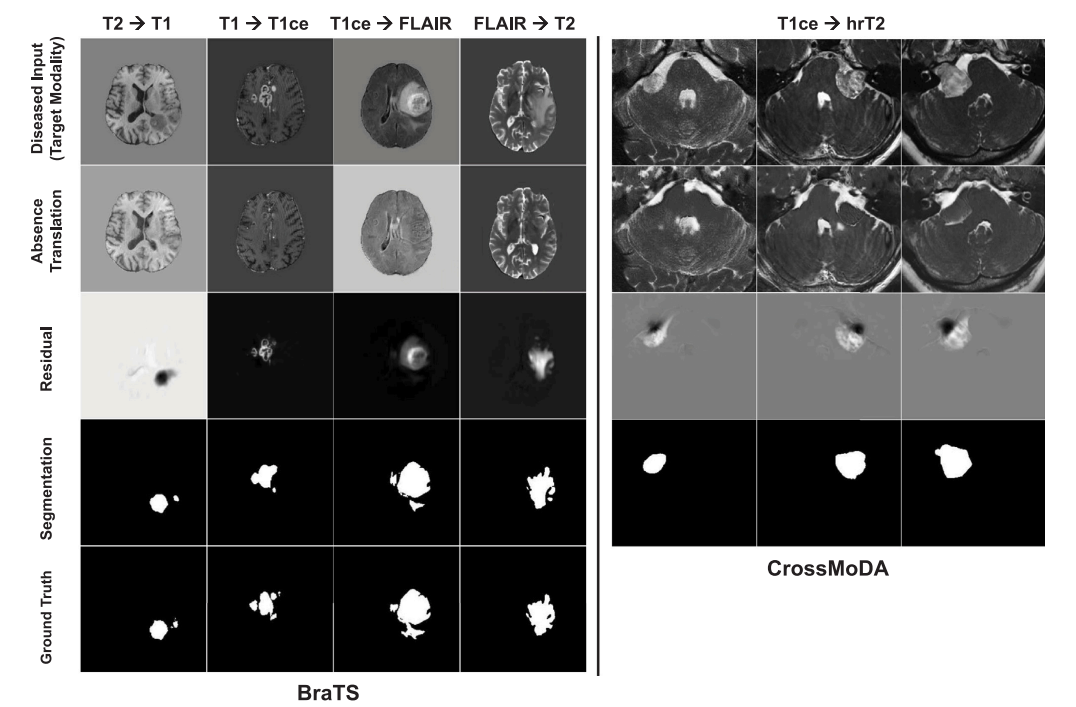
Fig. 6. Examples of translations from pathology to control domains and resulting segmentation in a domain adaptation application where target modality had no pixel-levelannotations provided. For BraTS, we show in each column a different source → target scenario. We do not display ground truth VS segmentations for CrossMoDA as hrT2segmentation maps were not provided in the data challenge.
图6. 从病理域到对照域的翻译示例及其在目标模态无像素级注释情况下的域适应应用中的分割结果。对于BraTS,我们在每一列展示了不同的源→目标场景。我们未展示CrossMoDA的VS分割真实标签,因为数据挑战中未提供hrT2分割图。
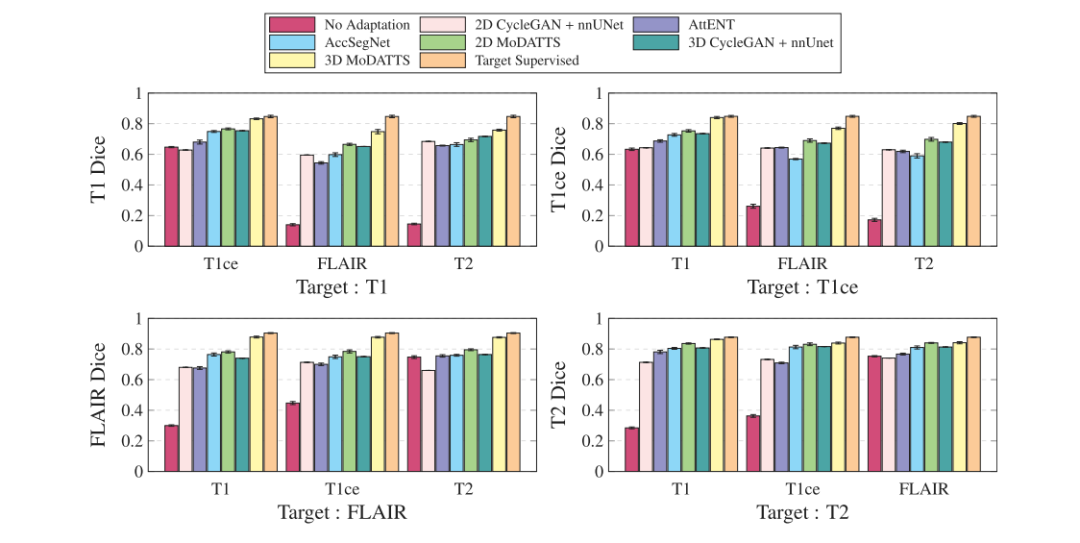
Fig. 7. Dice performance on the target modality for each possible modality pair. Pixel-level annotations were only provided in the source modality indicated on the x axis. Wecompare results for MoDATTS (2D and 3D) with AccSegNet (Zhou et al., 2021) and AttENT (Li et al., 2021) domain adaptation baselines, as well as a standard 2D and 3DCycleGAN + nnUNet. We also show Dice scores for supervised segmentation models respectively trained with all annotations on source data (No adaptation) and on target data(Target supervised) as for lower and upper bounds of the cross-modality segmentation task.
图7. 每种可能的模态对在目标模态上的Dice性能表现。像素级注释仅在x轴上所示的源模态中提供。我们将MoDATTS(2D和3D)的结果与AccSegNet(Zhou等,2021)和AttENT(Li等,2021)域适应基线模型以及标准2D和3D CycleGAN + nnUNet进行比较。我们还展示了分别在源数据(无适应)和目标数据(目标监督)上使用所有注释训练的监督分割模型的Dice评分,以表示跨模态分割任务的下限和上限。
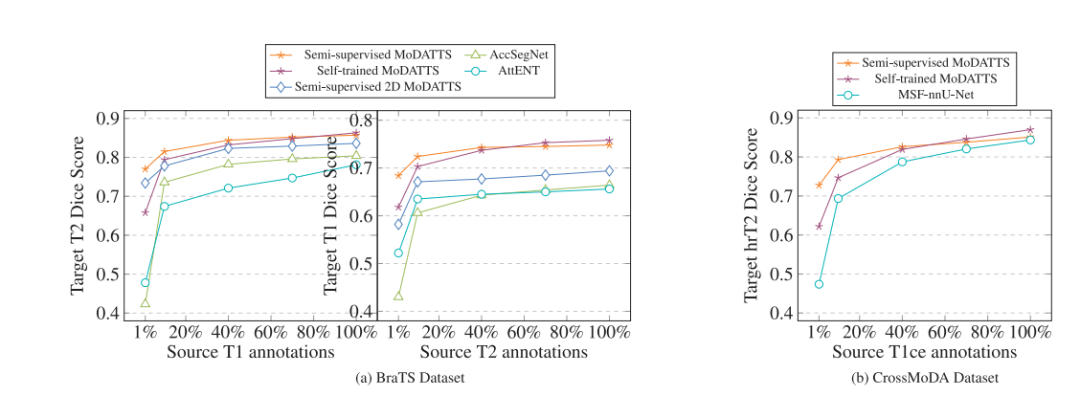
Fig. 8. Dice scores when using reference annotations for 0% of target data and various fractions (1%, 10%, 40%, 70% and 100%) of source data during training. For BraTS, wepicked the T1/T2 modality pair and ran the experiments in both T1 → T2 and T2 → T1 directions. For CrossMoDA, hrT2 annotations are not available so the experiment is runonly in the T1ce → hrT2 direction. While performance drops when a low % of annotations are available for the baselines, semi-supervised MoDATTS shows only a slight decrease.For readability, standard deviations across the runs are not shown.
图8. 在训练期间使用目标数据的0%参考注释和不同比例(1%、10%、40%、70%和100%)的源数据时的Dice评分。对于BraTS,我们选择了T1/T2模态对,并在T1 → T2和T2 → T1方向上进行了实验。对于CrossMoDA,由于hrT2注释不可用,实验仅在T1ce → hrT2方向上进行。当基线模型的注释比例较低时,性能有所下降,而半监督的MoDATTS仅显示出轻微的下降。为便于阅读,未显示各次运行的标准差。
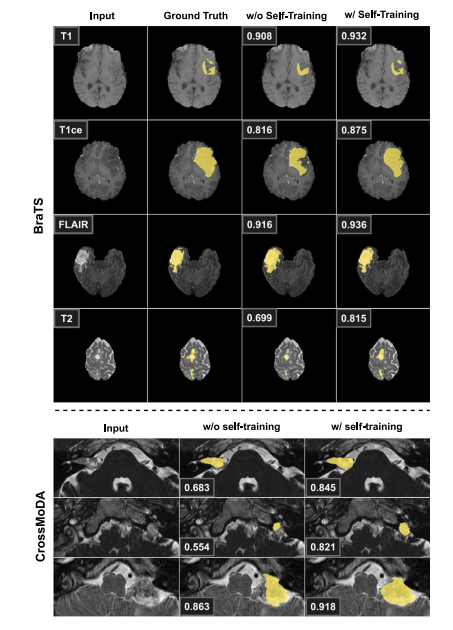
Fig. 9. Qualitative evaluation of the impact of self-training on the test set for thebrain tumor and VS segmentation tasks. The last two columns show, respectively, thesegmentation map for the same model before and after the self-training iterations. ForBraTS, each row illustrates a different scenario where the target modality – indicatedin the first column – was not provided with any annotations. We also show groundtruth tumor segmentations to visually assess the improvements of the model when selftraining is performed, along with the dice score obtained on the whole volume. ForCrossMoDA the ground truth VS segmentations on target hrT2 MRIs were not provided.Self-training helps to better leverage unannotated data in the target modality and actsas a refining of the segmentation maps, which helps to reach better performance.
图9. 自训练对脑肿瘤和VS分割任务测试集影响的定性评估。最后两列分别显示了同一模型在自训练迭代前后的分割图。在BraTS中,每行展示了一个不同的场景,其中目标模态(在第一列中指示)没有提供任何注释。我们还展示了真实的肿瘤分割图,以便视觉上评估模型在进行自训练时的改进情况,以及整个体积上获得的Dice评分。对于CrossMoDA,未提供目标hrT2 MRI上的真实VS分割图。自训练有助于更好地利用目标模态中的未注释数据,并起到细化分割图的作用,从而帮助达到更好的性能。
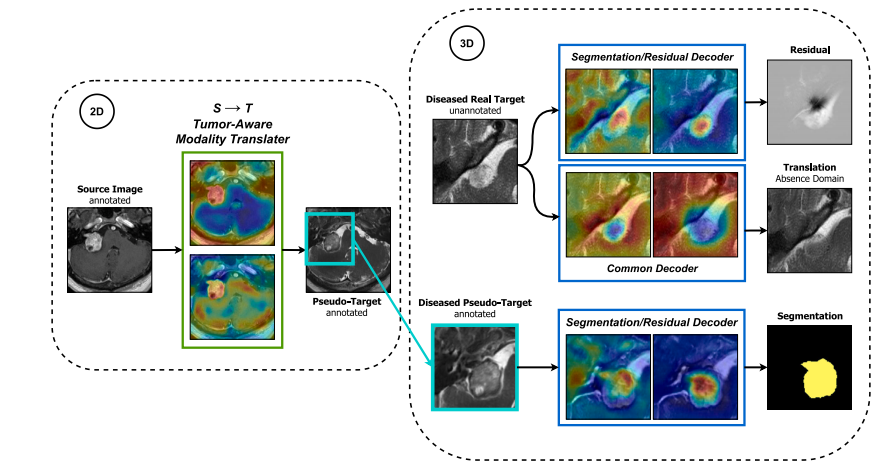
Fig. 10. Attention maps yielded by the most confident transformer heads in MoDATTS. Red color indicates areas of focus while dark blue corresponds to locations ignored by thenetwork. Note that the maps presented in the modality translation stage are produced by the encoder of the network as the decoder is fully convolutional and does not containtransformer blocks.
图10. MoDATTS中最有置信度的转换器头生成的注意力图。红色表示网络关注的区域,而深蓝色对应网络忽略的位置。请注意,模态翻译阶段展示的注意力图是由网络的编码器生成的,因为解码器是完全卷积的,不包含转换器块。
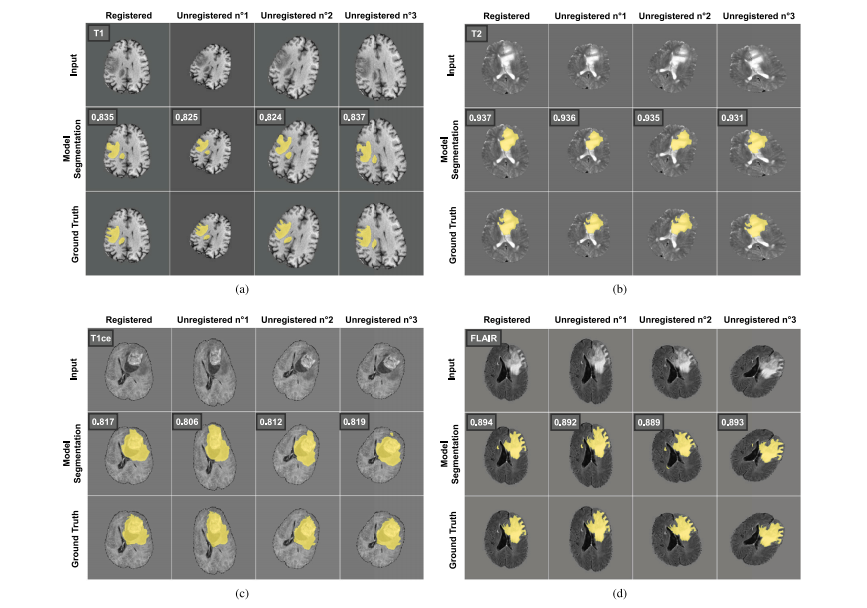
Fig. 11. Effects of affine deformations on MoDATTS cross-modal segmentation performance. Baseline BraTS datasets are registered. Affine transformations use the followingparameters: zoom range = 0.2, rotation range = 35◦ , nonlinear spline warping (parameters range: grid size = 3, sigma = 5). No significant difference in the resulting Dice scorecan be observed for all modality pairs.
图11. 仿射变换对MoDATTS跨模态分割性能的影响。基线BraTS数据集已对齐。仿射变换使用以下参数:缩放范围 = 0.2,旋转范围 = 35°,非线性样条变形(参数范围:网格大小 = 3,sigma = 5)。对于所有模态对,结果Dice评分未显示出显著差异。
Table
表
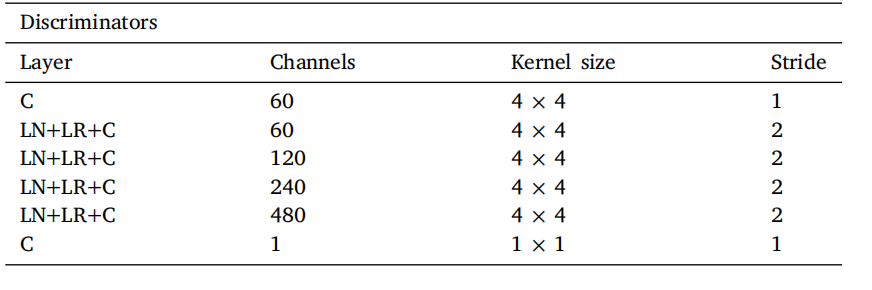
Table 1Discriminator architecture used for the modality translation stage. 𝐋𝐍 = Layer Normalization, 𝐋𝐑 = Leaky ReLU activation, 𝐂 = Convolution. The same architecture is usedto train thecontrol/pathology translation in the second stage, but kernels are expandedto 3D.
表1 用于模态翻译阶段的判别器架构。𝐋𝐍 = 层归一化(Layer Normalization),𝐋𝐑 = Leaky ReLU激活,𝐂 = 卷积(Convolution)。相同的架构用于第二阶段中的控制/病理翻译训练,但内核扩展为3D。

Table 2The architectures used for training at the segmentation stage. Except for the common decoder for which we add an extra convolution layer at the bottleneck with kernel size1 × 1 × 1 to map the common code back to the encoder output channel number, we use identical architectures for all decoders. Ch. sm. and Ch. sf. respectively refer to thenumber of channels for the semi-supervised and self-trained variants. At each layer we show the number of convolution blocks (Conv.), and the number of B-MDH – BidirectionalMulti-Head Attention – blocks (Trans.) along with the number of heads for each of these blocks (Heads).
表2分割阶段训练中使用的架构。除了通用解码器外,我们在瓶颈处增加了一个卷积核大小为1 × 1 × 1的额外卷积层,用于将通用代码映射回编码器的输出通道数外,所有解码器使用相同的架构。Ch. sm. 和 Ch. sf. 分别指半监督和自训练变体的通道数量。在每一层,我们展示了卷积块(Conv.)的数量,双向多头注意力(B-MDH)块(Trans.)的数量以及每个这些块的头数(Heads)。
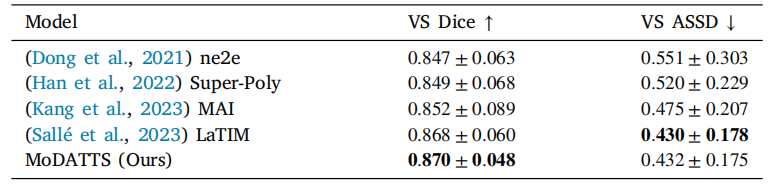
Table 3Dice score and ASSD for the VS segmentation on the target hrT2 modality in theCrossMoDA challenge. We compare our performance with the top 4 teams in thevalidation phase. The standard deviations reported correspond to the performancevariation across the 64 test cases.
表3 CrossMoDA挑战中目标hrT2模态下VS分割的Dice评分和平均对称表面距离(ASSD)。我们将我们的性能与验证阶段排名前4的团队进行比较。报告的标准差对应于64个测试案例的性能差异。

Table 4Brain tumor segmentation Dice scores when using reference annotations for 100% of source T2 data and various fractions (0%,10%, 30% and 50%) of target T1ce data during training. We also show the % of the target supervised model performance(TSMP) that is reached by MoDATTS for the corresponding fractions of T1ce annotations.
表4 使用100%源T2数据的参考注释和不同比例(0%、10%、30%和50%)的目标T1ce数据进行训练时的脑肿瘤分割Dice评分。我们还展示了MoDATTS在相应比例的T1ce注释下达到的目标监督模型性能(TSMP)百分比。
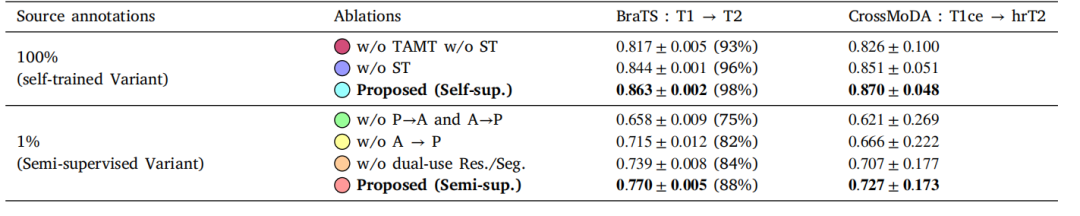
Table 5Ablation studies: absolute Dice scores on the target modality. For BraTS, we selected T1 and T2 to be respectively the source and targetmodalities for these experiments. Ablations of the tumor-aware modality translation (TAMT) and self-training (ST) were performed when 100%of the source data was annotated with the self-trained variant of MoDATTS, as it yielded the best performance. Alternatively, the ablationsrelated to the diseased-healthy translation were performed on the semi-supervised variant when 1% of the source data was annotated. We alsoreport for BraTS the % of a target supervised model performance that is reached by the model (values indicated in parenthesis). Note that forCrossMoDA the standard deviations reported correspond to the performance variation across the 64 test cases.
表5 消融研究:目标模态上的绝对Dice评分。对于BraTS实验,我们分别选择T1和T2作为源模态和目标模态。当100%的源数据被注释时,针对MoDATTS的自训练变体进行了肿瘤感知模态翻译(TAMT)和自训练(ST)的消融,因为该变体表现最佳。此外,与疾病-健康翻译相关的消融研究在源数据1%被注释的半监督变体上进行。我们还报告了BraTS中模型达到的目标监督模型性能的百分比(括号中给出数值)。请注意,对于CrossMoDA,报告的标准差对应于64个测试案例的性能变化。















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









