







论文题目:Limited Data Rolling Bearing Fault Diagnosis With Few-Shot Learning
文献地址:https://ieeexplore.ieee.org/abstract/document/8793060
源码【Keras版】: https://mekhub.cn/as/fault_diagnosis_with_few-shot_learning/
出于学习,对其源码简单复现为Tensorflow版,个人认为要比源码好读一些,欢迎评论指导哈:
https://github.com/monologuesmw/bearing-fault-diagnosis-cnn
(本篇博客为2019年的工作,最早发布于博客园 地址:https://www.cnblogs.com/monologuesmw/p/12209287.html)
之前听吴恩达老师的卷积神经网络课程中one shot learning problem关于孪生网络(Siamese Neural Network)在员工人脸识别场景当中的应用。感觉员工人脸识别的应用场景与机械设备故障诊断的场景十分类似,都具有样本量少的共性。而且Siamese网络的理论也非常符合应用在故障诊断的场景中。只是当时对conv1d的操作不熟悉,不知道conv1d的卷积操可以用于时序的操作。
日前,对Limited Data Rolling Bearing Fault Diagnosis With Few-Shot Learning这篇论文进行拜读,其使用Siamese网络对西储大学轴承数据进行故障诊断,并且对故障诊断提出了Few-Shot Learning 的概念。
Siamese网络在故障诊断中的效果
如下图所示,训练样本数量在60到19800,WDCNN、One-Shot、Five-Shot的准确率要比SVM高很多,更适合小数据量的样本。
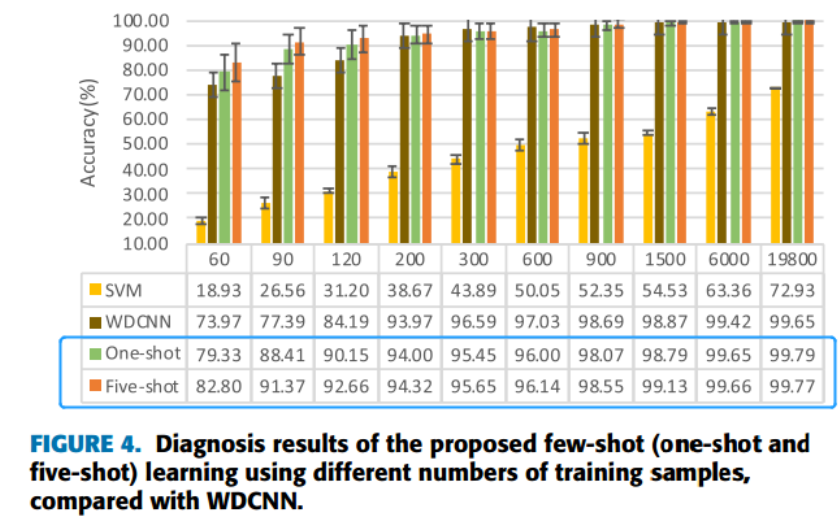
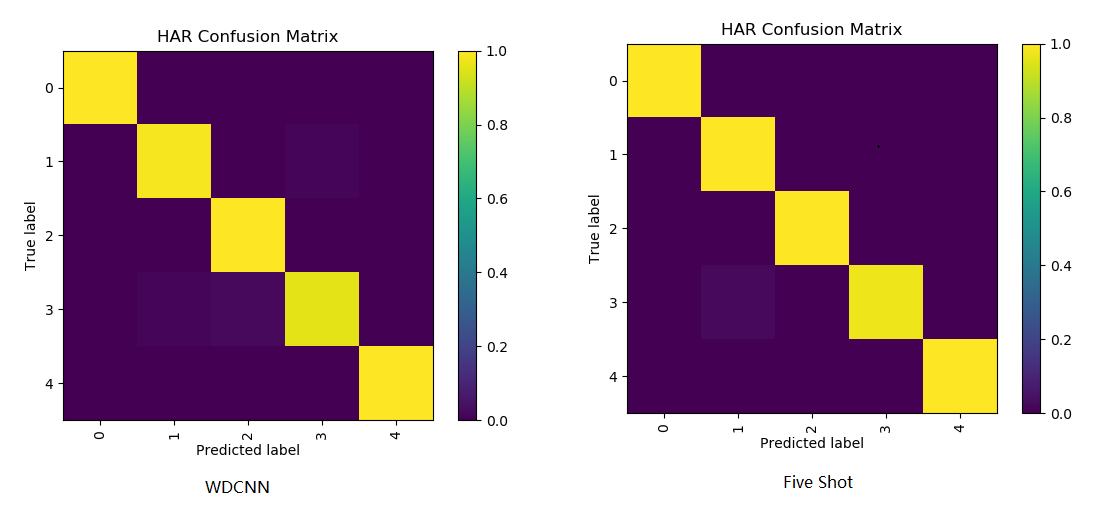
下图c、d中是90个训练样本的混淆矩阵,可以看出One-Shot比WDCNN更易于在第2、3、8类的判断。

故障诊断的现状
近年来,基于深度学习的智能故障诊断技术由于避免了依赖耗时且不可靠的人工分析,提高了故障诊断的效率,引起了人们的广泛关注。然而,这些技术方案需要大量的训练样本(深度学习网络模型的训练大多需要大量的训练样本)。在现实的生产实际中,不同工况下,同一故障的信号也会有很大的区别。这就使得故障诊断面临一个极大的挑战:对于各种故障,难以获得充足的样本去训练一个鲁棒性强的分类器。造成这一情形的原因有以下四个方面:
- 由于各种故障发生可能造成的后果,工业场景不允许故障状态的发生;
- 大多数机电故障发生缓慢,器件老化长达数月甚至数年;
- 机械系统的工作环境十分复杂,并且频繁更改(由于生产需求);
- 实际应用中,故障类型和工作条件经常是不平衡的;
深度学习目前在机器视觉、图像视频处理、语音识别、NLP等领域如火如荼。
深度学习用于故障诊断的模型:AE、RBM、CNNs、RNNs、GANs【各模型的参考文献可以查看原文】
论文贡献
- 使用基于WDCNN(第一层卷积核的尺寸较大)卷积神经网络作为孪生网络的子网络,为轴承的故障诊断提出了在数据量缺失的情况下,Few-Shot-Learning的应用。
- 首次证明了基于小样本学习的故障诊断模型可以充分利用相同或不同的类样本对,从只有单个或少数样本的类中识别出测试样本,从而提高故障诊断的性能。
- 随着训练样本数量的增加,当测试数据集与训练数据集有显著差异时,测试性能不会单调增加。
实现思路
Siamese Network
如果拜读过SiamFC、SiamRPN、SiamMask等目标跟踪文献,对于Siamese网络应该并不陌生。这里为了便于论文的叙述,先对Siamese网络进行直观上的描述。
Siamese孪生网络,顾名思义,其网络结构是双生的。如下图所示,样本对(X1, X2)同时输入Gw(x)网络中,产生Gw(X1)和Gw(X2)两个输出,并通过某种相似度进行判断,产生X1与X2的相似程度。这种思想实际上是模板匹配的一种。两个Gw(x)网络结构权值共享。也就是说,虽然是两个网络,但实际上是一个,为了模型的并行计算,视为孪生。

先以员工人脸识别为例,X2就是入职时采集存储的个人图片,而X1则是每次刷脸时采集的图片;对于没有入职的小伙伴,可以想象刷脸支付的场景,X2是开通刷脸支付,录入的面部信息,而X1则是在商超自助支付时,采集到的面部信息。指纹支付亦是如此。而刷脸支付偶尔会遇到点点头,摇摇头,眨眨眼等操作,这实际上是活体检测的一种方式,为了验证镜头前的你不是一个照片、视频 或者 假体面具。扯得有些远了…
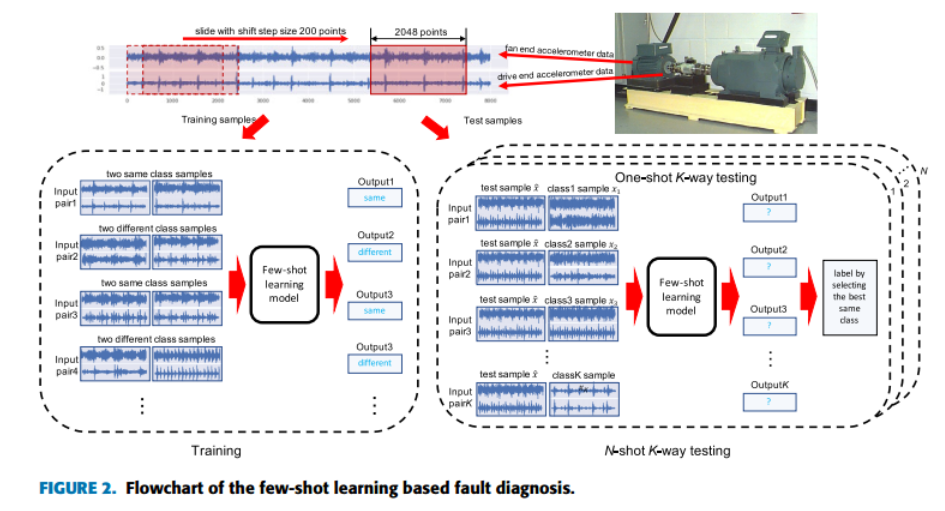
Few-Shot learning
如下图所示,Few-Shot learning实际上是One-Shot learning的多次使用。首先,在训练过程中,使用相同类别,或者不同类别构成样本对(x1, x2),输出则是两个输入样本对是否属于同一类的概率(训练的真值表则是0或者1)。与传统的分类不同,Few-Shot learning的性能通常由N-shot K-way测试来衡量,如图下图( c )中所示。

在测试的过程中,One-shot K-way的测试(上图b)实际上与员工检测相同。而N-shot K-way的测试(上图c)实际上是每个类别多存了几个模板,在测试的过程中,需要与所有的模板均进行比对,然后生成每一次比对是否相似的概率,再做出最终的决策。也就是说,N是存储样本的个数,也是比对的次数,K是类别数。
one-shot K-way testing
在测试的过程中,测试样本x与模板集S的K个类别样本进行比较,生成相应的相似度。【是one-shot】

然后,选取相似度最大的作为当前测试样本的类别。

N-shot K-way testing
对于N-shot的测试场景,可以通过N个shot的相似度进行求和,选择N个求和之后相似度的最大值作为当前测试样本的类别。

目前不确定N次结果投票的方式与N次求和的方式那种精度更高。
实现细节
对于轴承故障诊断的应用场景,唯一的不同是上述为图像信号,而故障诊断是数据信号。
few-shot learning的实现包含3个步骤,如下图所示:
- 数据准备(下图顶部)
a. 训练样本对的生成: 相同或不同类别的数据组成样本对可重复,并生成0或1真值;
b. 测试样本对的生成:一个测试样本与在训练集中随机无重复选取K个类别,N个模板组成样本对。 ---- 测试的过程一个测试样本要与随机生成的K * N个样本进行比对,测试过程时间较长。不过对于实际应用中,故障的发生不会接踵而至,时长的问题不是问题。 - 模型训练(下图左侧)
模型的输入是样本对,输出是相似度的概率值,相当于二分类的过程。 - 模型测试(下图右侧)
源码中使用的是N-shot次的循环,即每一次都是一个one-shot-testing的测试。
 Siamese网络的子网络选用WDCNN模型,其结构如下图所示:
Siamese网络的子网络选用WDCNN模型,其结构如下图所示:
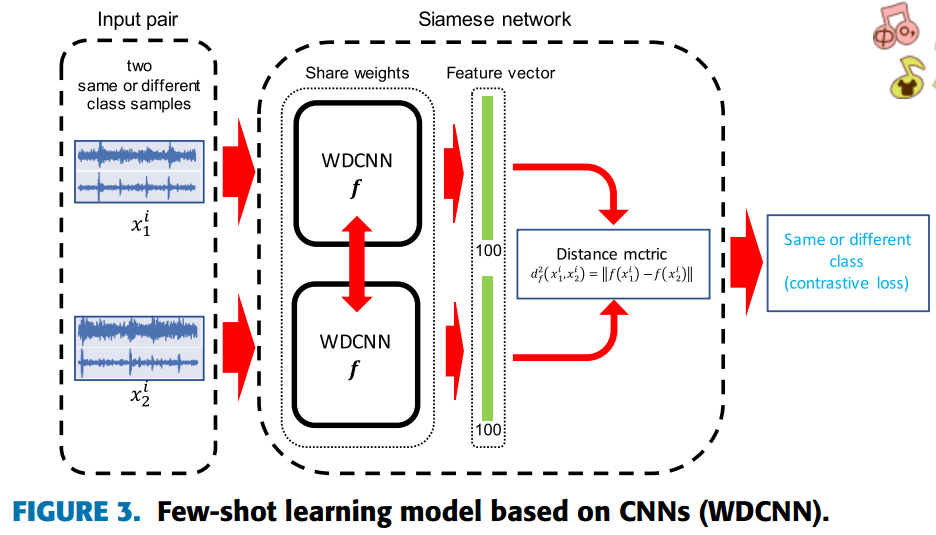
WDCNN第一层使用比较大的卷积核进行特征提取; 然后使用尺寸较小的卷积核进行更好的特征表达。第一层如果采用小尺寸的卷积核,极易受到工业场景中高频噪声的影响。WDCNN网络结构如下图所示:

输入数据是原始的振动信号,这里不需要进行任何的特征工程。【凯斯西储大学轴承故障数据】
训练过程中相似度的度量采用1范数:

通过相似度的判断,便可以计算出当前样本对的相似程度。也就是说,在获得WDCNN的两个输出后,再对输出进行1范数的计算。之后,再通过一个一维的全连接FC生成最终的相似度。(全连接使用dropout)

损失函数使用分类的交叉熵损失函数,并进行2范数正则化。

优化策略选则Adam。
P.S. 当然,直接使用WDCNN,外接类别个数的全连接层(使用dropout),全连接层使用softmax激活函数,也可以直接实现分类,效果也很不错。
https://github.com/monologuesmw/bearing-fault-diagnosis-by-wdcnn
西储大学轴承故障数据描述(github中,我只选取了前5类故障进行实验)
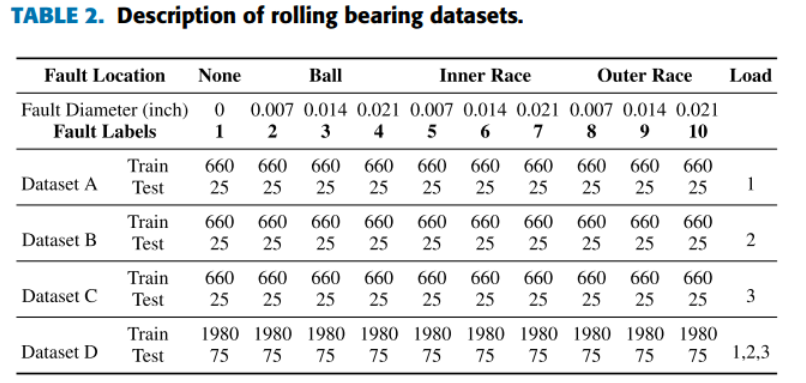
在实验中,作者分别对以下4个方面进行了验证:
a. 训练样本个数对于实验结果的影响;
b. 添加噪声对于实验结果的影响;
c. 在新的故障类别出现时的性能;
d. 新工况的性能;
模型结构代码Keras版:
完整代码地址: https://mekhub.cn/as/fault_diagnosis_with_few-shot_learning/
def load_siamese_net(input_shape = (2048,2)):
left_input = Input(input_shape)
right_input = Input(input_shape)
convnet = Sequential()
# WDCNN
convnet.add(Conv1D(filters=16, kernel_size=64, strides=16, activation='relu', padding='same',input_shape=input_shape))
convnet.add(MaxPooling1D(strides=2))
convnet.add(Conv1D(filters=32, kernel_size=3, strides=1, activation='relu', padding='same'))
convnet.add(MaxPooling1D(strides=2))
convnet.add(Conv1D(filters=64, kernel_size=2, strides=1, activation='relu', padding='same'))
convnet.add(MaxPooling1D(strides=2))
convnet.add(Conv1D(filters=64, kernel_size=3, strides=1, activation='relu', padding='same'))
convnet.add(MaxPooling1D(strides=2))
convnet.add(Conv1D(filters=64, kernel_size=3, strides=1, activation='relu'))
convnet.add(MaxPooling1D(strides=2))
convnet.add(Flatten())
convnet.add(Dense(100,activation='sigmoid'))
# print('WDCNN convnet summary:')
# convnet.summary()
#call the convnet Sequential model on each of the input tensors so params will be shared
encoded_l = convnet(left_input)
encoded_r = convnet(right_input)
#layer to merge two encoded inputs with the l1 distance between them
L1_layer = Lambda(lambda tensors:K.abs(tensors[0] - tensors[1]))
#call this layer on list of two input tensors.
L1_distance = L1_layer([encoded_l, encoded_r])
D1_layer = Dropout(0.5)(L1_distance)
prediction = Dense(1,activation='sigmoid')(D1_layer)
siamese_net = Model(inputs=[left_input,right_input],outputs=prediction)
# optimizer = Adam(0.00006)
optimizer = Adam()
#//TODO: get layerwise learning rates and momentum annealing scheme described in paperworking
siamese_net.compile(loss="binary_crossentropy",optimizer=optimizer)
# print('\nsiamese_net summary:')
# siamese_net.summary()
# print(siamese_net.count_params())
return siamese_net
模型结构代码Tensorflow版
完整代码地址:https://github.com/monologuesmw/bearing-fault-diagnosis-cnn
def siamese_base_structure(self, inputs, reuse):
with slim.arg_scope([slim.conv1d], padding="same", activation_fn=slim.nn.relu,
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.005)
):
net = slim.conv1d(inputs=inputs, num_outputs=16, kernel_size=64, stride=16, reuse=reuse, scope="conv_1")
# tf.summary.histogram("conv_1", net)
def_max_pool = tf.layers.MaxPooling1D(pool_size=2, strides=2, padding="VALID", name="max_pool_2")
net = def_max_pool(net)
# tf.summary.histogram("max_pool_2", net)
net = slim.conv1d(net, num_outputs=32, kernel_size=3, stride=1, reuse=reuse, scope="conv_3")
# tf.summary.histogram("conv_3", net)
def_max_pool = tf.layers.MaxPooling1D(pool_size=2, strides=2, padding="VALID", name="max_pool_4")
net = def_max_pool(net)
# tf.summary.histogram("max_pool_4", net)
net = slim.conv1d(net, num_outputs=64, kernel_size=2, stride=1, reuse=reuse, scope="conv_5")
# tf.summary.histogram("conv_5", net)
def_max_pool = tf.layers.MaxPooling1D(pool_size=2, strides=2, padding="VALID", name="max_pool_6")
net = def_max_pool(net)
# tf.summary.histogram("max_pool_6", net)
net = slim.conv1d(net, num_outputs=64, kernel_size=3, stride=1, reuse=reuse, scope="conv_7")
# tf.summary.histogram("conv_7", net)
def_max_pool = tf.layers.MaxPooling1D(pool_size=2, strides=2, padding="VALID", name="max_pool_8")
net = def_max_pool(net)
# tf.summary.histogram("max_pool_8", net)
net = slim.conv1d(net, num_outputs=64, kernel_size=3, stride=1, padding="VALID", reuse=reuse, scope="conv_9")
# tf.summary.histogram("conv_9", net)
def_max_pool = tf.layers.MaxPooling1D(pool_size=2, strides=2, padding="VALID", name="max_pool_10")
net = def_max_pool(net)
# tf.summary.histogram("max_pool_10", net)
net = slim.flatten(net, scope="flatten_11")
# tf.summary.histogram("flatten_11", net)
output_step_one = slim.fully_connected(net, num_outputs=100, activation_fn=tf.nn.sigmoid, reuse=reuse,
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.005),
scope="fully_connected_12")
# tf.summary.histogram("fully_connected_12", output_step_one)
return output_step_one
def siamese_network_structure(self, s="train"):
if s=="train":
# siamese_network_structure rest
left_ouput = self.siamese_base_structure(inputs=self.inputs_base_structure_left, reuse=False)
else:
left_ouput = self.siamese_base_structure(inputs=self.inputs_base_structure_left, reuse=True)
right_output = self.siamese_base_structure(inputs=self.inputs_base_structure_right, reuse=True) # siam network two results
L1_distance = tf.math.abs(left_ouput - right_output,
name="L1_distance") # two tensor result substract
# tf.summary.histogram("L1_distance_13", L1_distance)
net = slim.dropout(L1_distance, keep_prob=self.keep_prob, scope="dropout_14")
# tf.summary.histogram("dropout_14", net)
a = tf.Variable(tf.zeros([1]))
if s =="train":
prob_output = slim.fully_connected(net, num_outputs=1, activation_fn=tf.nn.sigmoid,
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.005), reuse=False,
scope="fully_connected_15")
else:
prob_output = slim.fully_connected(net, num_outputs=1, activation_fn=tf.nn.sigmoid,
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
weights_regularizer=slim.l2_regularizer(0.005), reuse=True,
scope="fully_connected_15")
# tf.summary.histogram("fully_connected_15", prob_output)
return prob_output
不得不服Keras框架在实现上要比Tensorflow简洁太多!


















 2077
2077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











