






点击下方卡片,关注“小白玩转Python”公众号
通过使用 YOLOv8 目标检测和侦察无人机拍摄的航空图像来利用地理空间情报(GEOINT)统计敌方飞机,从而规划军事行动。
 使用 YOLOv8 识别敌方空军基地的飞机
使用 YOLOv8 识别敌方空军基地的飞机
在本文中,我们将深入探讨地理空间情报(GEOINT)作为跟踪敌方军事空军基地的工具。通过有效地监控这些位置及其飞机,可以为针对它们的作战行动进行充分准备。
YOLOv8 目标检测
YOLOv8 是由 Ultralytics 开发的流行实时目标检测系统,广泛应用于包括军事监视和侦察在内的各种应用。它旨在实时检测图像或视频帧中的物体。在军事场景中,快速准确地指示车辆、人员或设备等目标对于态势感知和目标跟踪至关重要。
通过将 PyTorch 与深度学习和卷积神经网络(CNN)结合使用,YOLOv8 展示了同时检测场景中多个物体的能力,具有良好的速度和精度。因此,我们选择在任务中使用它。
前提条件
首先,我选择在 Google Compute Engine 后端使用 Python 3,并在 Google Colab 中执行代码。让我们安装依赖项。
!pip install ultralytics在安装过程中,它会安装 opencv-python、torch、pandas 以及此包所需的其他依赖项。
import cv2
import urllib.request
from ultralytics import YOLO, checks, hub
from google.colab.patches import cv2_imshow如上所述,我们导入了实验中将要使用的所有必要库。除了 ultralytics 模块外,还有 cv2_imshow,这是一个在 Google Colab 中正确工作的 cv2 热修复程序。urllib.request 用于从公共存储下载图像示例。
YOLOv8 模型
YOLOv8 是为目标检测设计的深度学习模型,它通过将输入图像分割成网格,然后预测每个网格单元中物体的边界框和类别概率。该模型的高效性在于其能够在单次前向传递中处理整个图像。
通常,为了创建模型,我们需要通过为每个图像添加图像和标签来正确准备数据集,以教模型识别物体。然而,现有的数据库已经包含了任何项目初期所需的大多数数据集。今天,我们将在实验中使用这些数据集。让我们访问 Roboflow 网站。
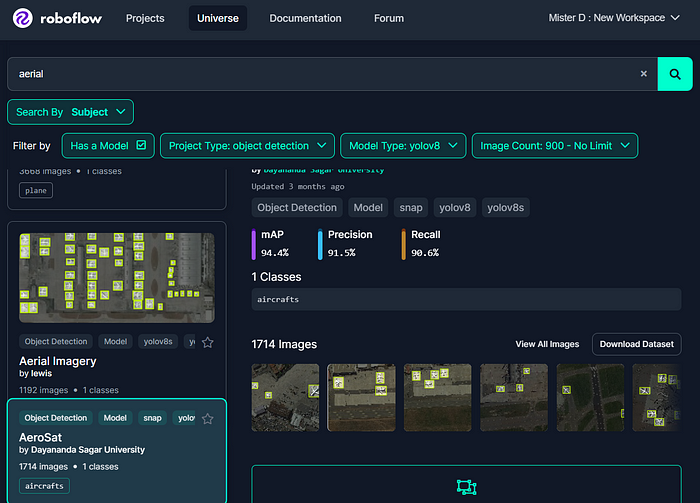 AeroSat 数据集 > 概览(roboflow.com)
AeroSat 数据集 > 概览(roboflow.com)
如上图所示,您需要为项目找到合适的数据集。在我们的示例中,我选择了 yolov8 作为模型类型,目标检测作为项目类型,并输入 aerial 作为搜索词。系统提供了广泛的数据集列表,我根据图像数量选择了一个更符合我们需求的数据集:1192 张图像和 1 个类别。
 下载数据集
下载数据集
一旦确定数据集适合您的任务,您需要通过选择适当的导出格式下载它。在我们的场景中,我选择了 YOLOv8 格式,因为我们之前已经决定使用它。
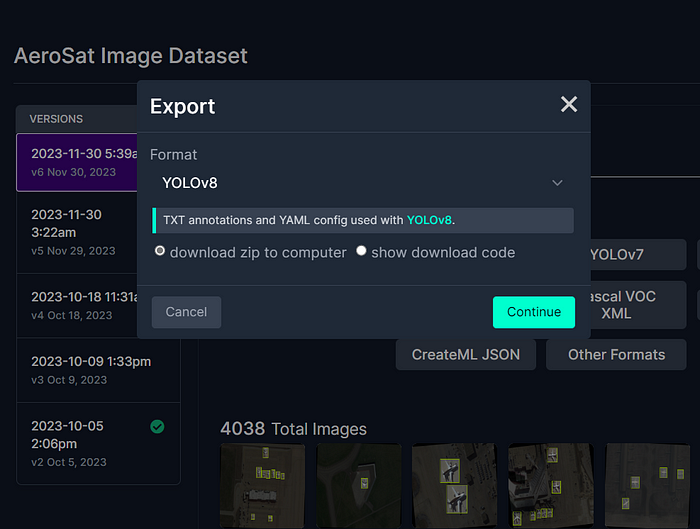 导出至 YOLOv8 格式的压缩文件
导出至 YOLOv8 格式的压缩文件
选择 ZIP 文件作为存储建议数据集的选项,如上图所示,并按照进一步的说明下载。当您准备好后,可以解压文件并探索数据集的结构和包含的图像及其标签。在大多数情况下,您会看到三个文件夹:test、train 和 valid,以及一些文件,其中一个是描述数据和类别的 data.yaml。
接下来的步骤,由于我们要使用 YOLOv8,我们必须前往 Ultralytics Hub,注册,创建项目、模型,并上传数据集,最终准备好您的模型进行训练。
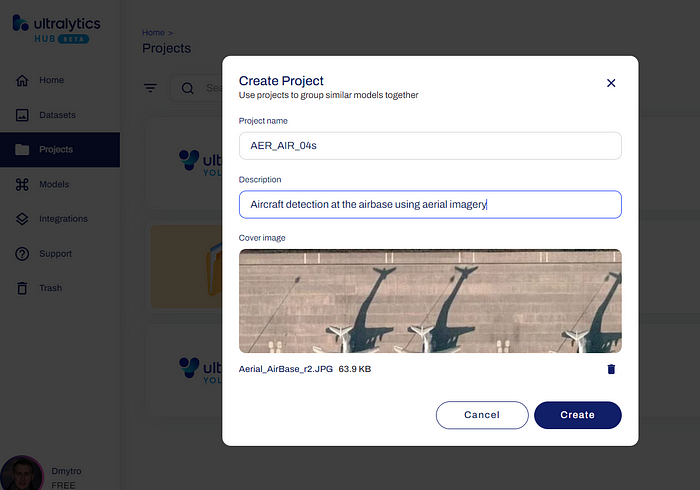 在 Ultralytics HUB 创建新项目
在 Ultralytics HUB 创建新项目
如上图所示,我输入了项目名称 AER_AIR_04s,简短描述为通过航空图像在空军基地检测飞机,并添加了一个示例图像,以便在我的列表中正确识别此项目。您可以照此操作。
接下来的步骤是转到“Datasets”并从下载文件夹中上传 ZIP 文件,选择数据集类型 Detect、数据集名称和描述,如下所示。
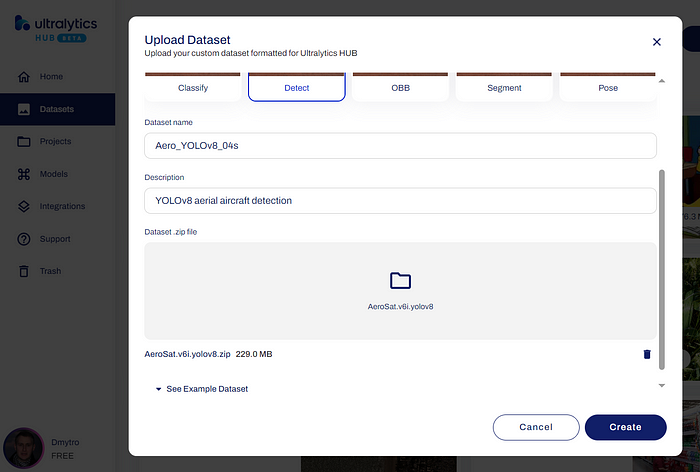 从 ZIP 文件上传数据集
从 ZIP 文件上传数据集
点击“Create”按钮并完成上传过程后,您将看到数据集列表,其中包含您的新数据集。
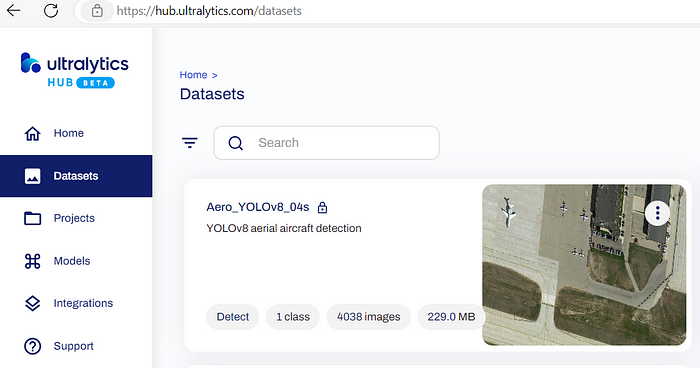 航空飞机检测数据集
航空飞机检测数据集
深入检查图像及其标签,然后按“Train model”按钮继续 YOLOv8 模型训练。
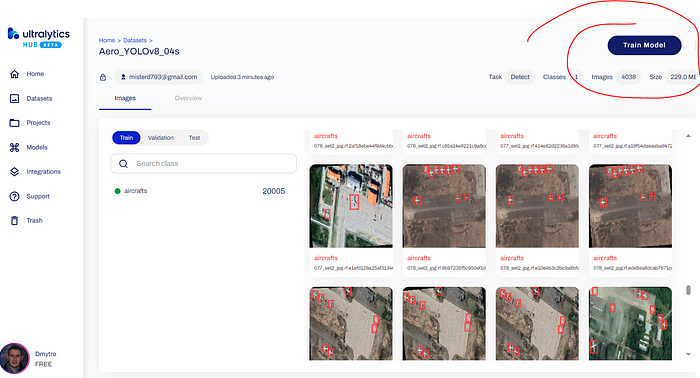 训练 YOLOv8 模型
训练 YOLOv8 模型
在下一个窗口中,您需要从列表中选择项目,输入模型名称 YOLOv8sAir,选择 YOLOv8 架构 YOLOv8s,并点击“Continue”按钮。
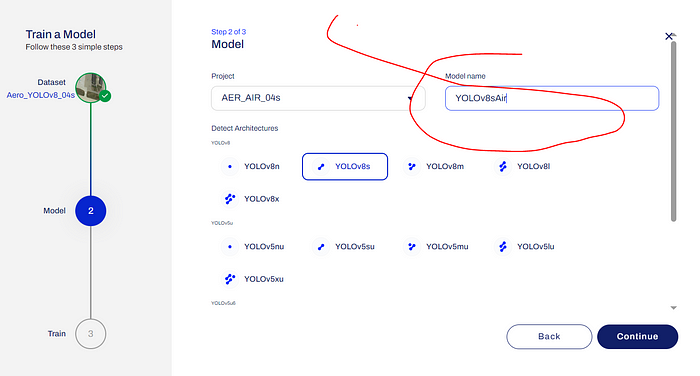 选择模型名称及其架构(YOLOv8s)
选择模型名称及其架构(YOLOv8s)
Ultralytics Hub 提供了广泛的选项来训练模型,但我们将使用以下选项——“Google Colab”。
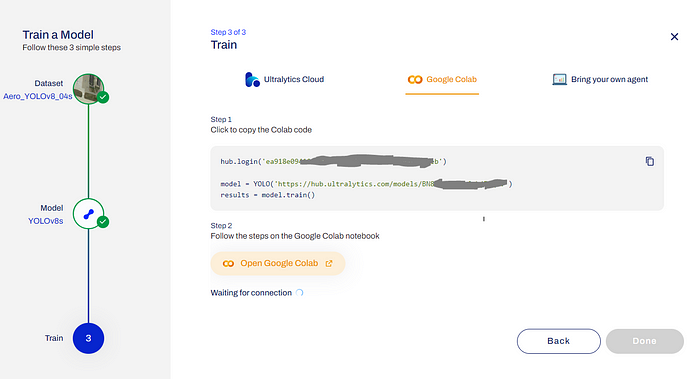 YOLOv8 模型训练的参数
YOLOv8 模型训练的参数
如上图所示,您将获得认证密钥和 URL(https://hub.ultralytics.com/models/BN8V8tA1pOt6thjZKq6V)用于模型训练。只需复制整个代码并将其粘贴到您的 Google Colab 中。
hub.login('[YOUR_AUTH_KEY]')
model = YOLO('https://hub.ultralytics.com/models/BN8V8tA1pOt6thjZKq6V')
results = model.train()接下来,导航到“Runtime”菜单,选择“Change runtime type”,并选择“T4 GPU”以加速训练,使用 NVIDIA T4 GPU 作为加速器。
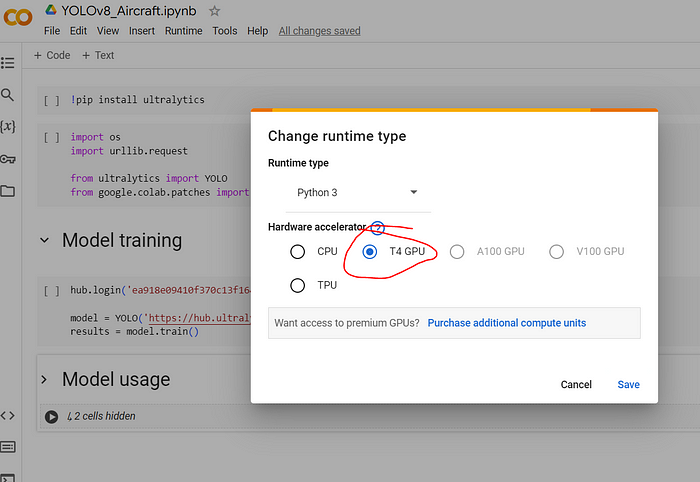
Nvidia Tesla T4 GPU
完成后,您可以像通常在 Google Colab 脚本中那样启动 YOLOv8 模型训练过程。
 在 Google Colab 中训练
在 Google Colab 中训练
对于如此大的数据集,训练过程大约需要 3-4 小时。然而,您不仅可以在 Google Colab 列表中监控进度,这可能不太方便,还可以使用 YOLOv8 模型网页上的特殊进度条。
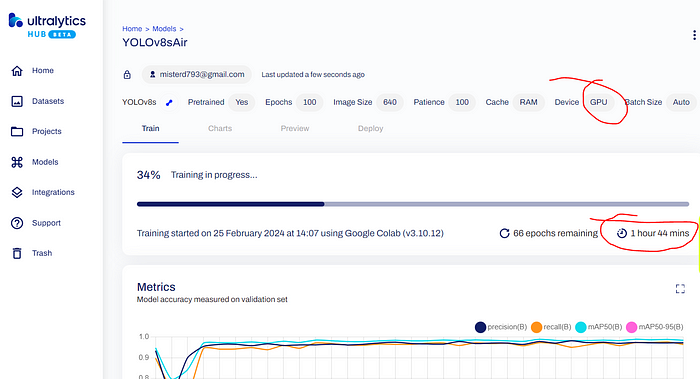 在 Ultralytics Hub 中训练过程
在 Ultralytics Hub 中训练过程
如前所述,这可能需要一些时间。完成后,导航到“Deploy”选项卡并下载最终模型(*.pt)文件。然后,您可以使用 YOLOv8 包在任何设备上,包括 Raspberry Pi 和智能应用程序中,使用此模型进行目标检测,识别空军基地或战场上的目标,甚至在侦察无人机上进行您的任务。
YOLOv8 的使用
到目前为止,您已经拥有了 YOLOv8 模型的 PyTorch (*.pt) 文件,该文件大小为 21.4 MB。这使我们可以在任何应用程序中使用它,只需几行代码。为了方便起见,我将 PT 文件、实验中将使用的图像和视频源上传到持久区块链存储 Arweave。要下载这些三个文件并将它们保存到我们的 Google Compute Engine 的工作目录中,我们需要编写并执行以下代码。
yolov8sair_url = 'https://6bq43uyscbhniu4kvl6hayy3zosqjnl5x2v2jm7zlfse6nnqrqsa.arweave.net/8GHN0xIQTtRTiqr8cGMby6UEtX2-q6Sz-VlkTzWwjCQ'
urllib.request.urlretrieve(yolov8sair_url, 'yolov8sair.pt')
source_file = 'https://6x77tjsjpqn6ze2k7izx36xgtipzff6yi2jfnp2xxf6lvmtyy7oa.arweave.net/9f_5pkl8G-yTSvozffrmmh-Sl9hGkla_V7l8urJ4x9w'
urllib.request.urlretrieve(source_file, 'Aerial_AirBase.jpg')
source_video = 'https://3tghzdwlhmyajv5eadufzesdo7epc5queknepym6hv2p737mgvxa.arweave.net/3Mx8jss7MATXpADoXJJDd8jxdhQimkfhnj10_-_sNW4'
urllib.request.urlretrieve(source_video, 'airport_video_source.mp4')如您所见,有三个文件:yolov8sair.pt 是模型的权重文件,Aerial_AirBase.jpg 是我们将在实验中用于目标检测的侦察无人机拍摄的图像示例,airport_video_source.mp4 是将用于目标识别的视频源示例。
model = YOLO('yolov8sair.pt')
results = model.predict('Aerial_AirBase.jpg')
annotated_frame = results[0].plot()
cv2_imshow(annotated_frame)这里我们基于训练好的模型创建 YOLO 对象。然后,我们尝试预测并找到 Aerial_AirBase.jpg 图像中的任何物体,最后显示结果中的第0个标注框。

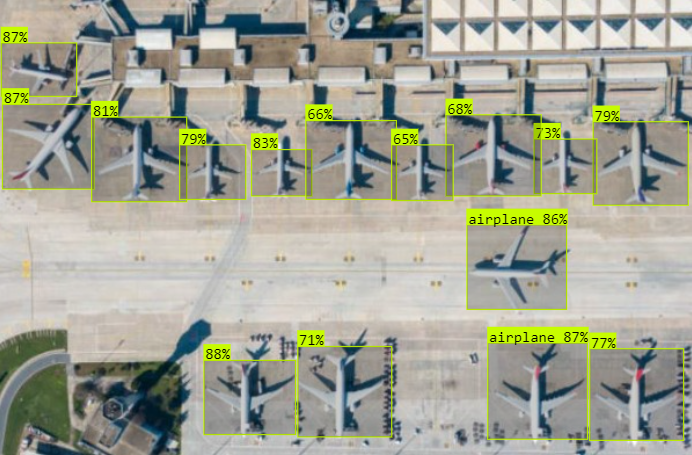
使用 yolov8sair 模型进行目标检测
如上图所示,检测到三架飞机,概率均约为 84%,表明高度的置信度。在这种情况下,您可以通过自动统计 results[] 数组中的物体列表来轻松统计它们。置信度和概率水平可能会因天气条件而异。然而,尽管存在如天气阴云等显著缺点,这种侦察方法在规划军事行动和支持战斗行动中仍具有重要意义。
正如您所见,其易用性只需几行代码即可使其在各种应用中得以使用,包括小型飞行控制器的自主无人机。想象一下,通过结合这种目标检测机制,您可以构建的智能应用程序。想象一下,配备自动驾驶仪、目标检测和跟踪能力的作战无人机,直到摧毁目标。让您的想象力引导您。
另一个您可以用于军事解决方案的好例子:
model = YOLO('yolov8sair.pt')
# Object Detection in Video-stream
cap = cv2.VideoCapture(f"airport_video_source.mp4")
img_array = []
while cap.isOpened():
success, frame = cap.read()
if success:
results = model(frame)
annotated_frame = results[0].plot()
img_array.append(annotated_frame)
else:
break
cap.release()
# Saving to output video file
size = img_array[0].shape[1], img_array[0].shape[0] # (384, 640)
writer = cv2.VideoWriter(f"airport_video_output.mp4", cv2.VideoWriter_fourcc(*"mp4v"), 25, size)
for frame in img_array:
img_n = cv2.resize(frame, size)
writer.write(img_n)
writer.release()这涉及从视频流中进行目标检测,在我们的例子中从 airport_video_source.mp4 文件中提取。然后,它将视频分成帧,检测每帧上的飞机,并将它们编译到 airport_video_output.mp4 文件中。
您可以从 Google Compute Engine 的工作目录中下载此文件。我相信您已经熟悉这个过程。
 视频流中的目标检测
视频流中的目标检测
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









