






如何使用大模型做文档重排?
- https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_reranker/finetune_for_instruction
- https://github.com/LongxingTan/open-retrievals
看这个prompt, 是理解大模型如何做重排的第一步. 目标就是让大模型微调时,得到输入后输出一个Yes

然后,时刻记住大模型是做一个生成任务,seq2seq
数据
单个样本:
- query
A: Five women walk along a beach wearing flip-flops. - positive + negative: list
['B: Some women with flip-flops on, are walking along the beach', "B: She's not going to court to clear her record.", 'B: The battle was over. ', 'B: There was a reform in 1996.', 'B: The 4 women are sitting on the beach.', 'B: A group of people plays volleyball.', 'B: The man is talking about hawaii.', 'B: The battle was over. ', 'B: The 4 women are sitting on the beach.', 'B: The man is talking about hawaii.', 'B: The 4 women are sitting on the beach.', 'B: There was a reform in 1996.', 'B: A group of people plays volleyball.', 'B: The man is talking about hawaii.', 'B: There was a reform in 1996.', 'B: The battle was over. '] - prompt
Given a query A and a passage B, determine whether the passage contains an answer to the query by providing a prediction of either 'Yes' or 'No'.

query:
Prompt+answer:
最后的9583就是 Yes的编码

dataset中的item结果,包括input_id与label

collator
query_inputs:
{'input_ids': [319, 29901, 22853, 5866, 6686, 3412, 263, 25695, 591, 4362, 285, 3466, 29899, 29888, 417, 567, 29889], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
prompt+yes inputs: only input_ids
[11221, 263, 2346, 319, 322, 263, 13382, 350, 29892, 8161, 3692, 278, 13382, 3743, 385, 1234, 304, 278, 2346, 491, 13138, 263, 18988, 310, 2845, 525, 8241, 29915, 470, 525, 3782, 4286, 3869]
passage_inputs:
{'input_ids': [350, 29901, 450, 767, 338, 9963, 1048, 447, 29893, 1794, 29875, 29889], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
单个item输入
{'input_ids': [1, 319, 29901, 22853, 5866, 6686, 3412, 263, 25695, 591, 4362, 285, 3466, 29899, 29888, 417, 567, 29889, 29871, 13, 350, 29901, 450, 767, 338, 9963, 1048, 447, 29893, 1794, 29875, 29889, 29871, 13, 11221, 263, 2346, 319, 322, 263, 13382, 350, 29892, 8161, 3692, 278, 13382, 3743, 385, 1234, 304, 278, 2346, 491, 13138, 263, 18988, 310, 2845, 525, 8241, 29915, 470, 525, 3782, 4286, 3869], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'labels': [-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 3869]}
batch内组合起来
{'input_ids': tensor([[32000, 32000, 32000, ..., 3782, 4286, 3869], [32000, 32000, 32000, ..., 3782, 4286, 3869], [32000, 32000, 32000, ..., 3782, 4286, 3869], ..., [32000, 32000, 32000, ..., 3782, 4286, 3869], [32000, 32000, 32000, ..., 3782, 4286, 3869], [32000, 32000, 32000, ..., 3782, 4286, 3869]]), 'attention_mask': tensor([[0, 0, 0, ..., 1, 1, 1], [0, 0, 0, ..., 1, 1, 1], [0, 0, 0, ..., 1, 1, 1], ..., [0, 0, 0, ..., 1, 1, 1], [0, 0, 0, ..., 1, 1, 1], [0, 0, 0, ..., 1, 1, 1]]), 'labels': tensor([[-100, -100, -100, ..., -100, -100, 3869], [-100, -100, -100, ..., -100, -100, 3869], [-100, -100, -100, ..., -100, -100, 3869], ..., [-100, -100, -100, ..., -100, -100, 3869], [-100, -100, -100, ..., -100, -100, 3869], [-100, -100, -100, ..., -100, -100, 3869]])}
Loss
学习目标:输出的最后一位,应该离‘Yes’越接近越好
- rank_logits
def encode(self, features):
# input('continue?')
if features is None:
return None
outputs = self.model(input_ids=features['input_ids'],
attention_mask=features['attention_mask'],
position_ids=features['position_ids'] if 'position_ids' in features.keys() else None,
output_hidden_states=True)
_, max_indices = torch.max(features['labels'], dim=1)
predict_indices = max_indices - 1
logits = [outputs.logits[i, predict_indices[i], :] for i in range(outputs.logits.shape[0])]
logits = torch.stack(logits, dim=0)
scores = logits[:, self.yes_loc]
return scores.contiguous()
- label:
target = torch.zeros(self.train_batch_size, device=grouped_logits.device, dtype=torch.long)
outputs: 大模型根据输入,应该输出的是yes或no.
max_indices: 就是yes所在的位置
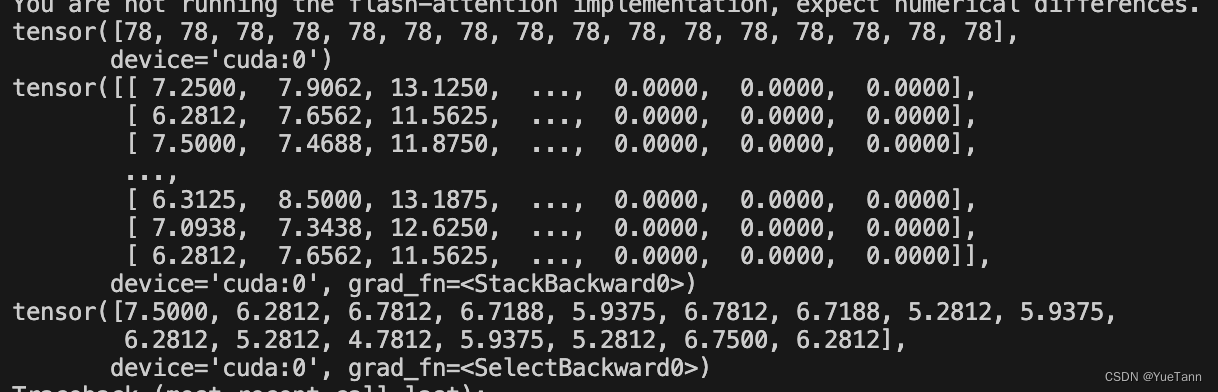
predict_indices | logits | scores如图
















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











