







回顾


计算梯度的办法

有限差分法,用起来慢,但区分度低,可以用这种方式得到梯度。
解析梯度计算法,这个计算很快,并且得到解析梯度的表达式
计算图
这节课主要是要学会计算任意复杂函数的解析梯度,要用到一个叫计算图的框架。

我们用这种图来表示任意函数,其中图的节点,表示我们要执行的每一步计算。
上图是分类,我们输入是x和W,这个乘的节点表示矩阵乘法,是参数W和数据x的乘积,输出分向量。
还有另一个节点表示hinge loss,计算数据损失项Li
还有一个正则项在右下角,这个节点计算正则项,在最后计算出来的值时正则项和数据项的和。
这里的优势是一旦可以将运算图表示出来,就可以用所谓的反向传播技术,递归调用链式法则,来计算图中每一个变量的梯度。

在上图中,最上面是输入的图片,最下面是损失,输入必须要穿过中间很多转换层,才能的到损失

神经图灵机,这是另一种深度学习模型,如果延时间展开,如果你想计算任意这些,这件变量的梯度,几乎是不切实际的
反向传播


当我们每到达一个节点,每个节点都会得到一个从上游返回的梯度,这个梯度就是对这个节点输出的求导。等我们在反向传播中到达这个 ,我们就计算出了最终损失L,关于z的梯度,接下来就是得到节点输入的梯度,就是x和y方向上的梯度。就像之前的用链式法则去计算。损失函数关于x的梯度就是L在z方向的梯度乘以z在x方向的本地梯度。在链式法则中,我们通常把上游梯度值传回来,再乘以本地梯度。从而得到关于输入的梯度。

(问题:这个梯度是否仅在这个函数当前取值时有效?
给函数一个当前值(临时值),我们可以写出它的表达式还是关于变量的表达式,我们可以对L关于z进行求导,可以得到一些表达式,z对x求导会得到另外的表达式,把这些数的值输进去,从而可以得到 x的梯度值。
)
例子
例子,这个例子更复杂也证明了反向传播为什么这么有效
这个例子中f是关于w和x的函数

接下来我们将对其反向传播,从最末端开始,最末端梯度是1没有什么好说的。
1/x的上游梯度是1,这个节点是1/x本地梯度df/dx等于
−
1
/
x
2
-1/x^2
−1/x2,带入前向传播得到的x的值1.37,最后等于-0.53
后面是+1本地的梯度是1,所以梯度还是0.53
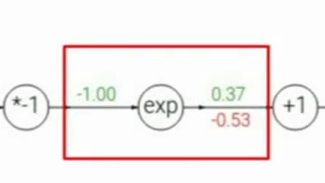
红框中上游梯度是-0.53,这是一个指数节点,本地梯度是
e
−
1
e^{-1}
e−1
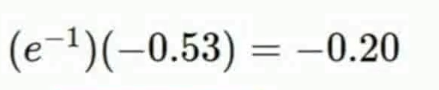

这里每个分支梯度,这是个加法运算,当我们遇到加法运算,加法运算对每个输入梯度,正好是1,所以这里本地梯度是1,乘以反向梯度0.2。
(问题:相对于推到对任意参数的梯度的解析表达式,为什么这样简单一些?
 这里可以用一个大的sigmoid点来替换掉这些小的计算点。因为我们知道这个门的本地梯度,你能聚合你想要的的任意节点,去组成在某种程度上稍微复杂的节点,只要你能够写出它的本地梯度。这就是一个权衡,你想用多少数学计算去得到一个更简洁更简单的计算图
这里可以用一个大的sigmoid点来替换掉这些小的计算点。因为我们知道这个门的本地梯度,你能聚合你想要的的任意节点,去组成在某种程度上稍微复杂的节点,只要你能够写出它的本地梯度。这就是一个权衡,你想用多少数学计算去得到一个更简洁更简单的计算图
这里对sigmoid门的输入,把数值带入即可求解出来

变量是高维向量的情况
其他情况都一样,唯一区别在于我们刚才的梯度变成了雅克比 ,所以现在是一个包含了每个变量里各元素导数的矩阵,举例z在每个x元素方向上的梯度

我们有一个向量作为输入,一个有4096元素的输入向量,在接下来的卷积神经网络中,这样的数据尺寸是比较常见的,中间的运算节点是对每个元素求最大值的运算,所以我们要求的f是每个元素与0之间的最大值,最后输出也是一个包含4096元素的向量,那么在这个例子中,这个雅克比矩阵的尺寸是几乘几?
矩阵是4096*4096,在实际过程中会遇到更大的雅克比矩阵,因为我们要进行批处理,比如一次输入100个变量,我们把这些一起送入运算节点可以提高效率,那么这个矩阵的长宽就要再乘以100,这个矩阵就会大于4096000乘以4096000,这个数据量太大,而且完全无法实现。
案例2
所以实际运算中,我们不需要计算怎么大的雅克比矩阵。我们只需要输出向量关于x的偏导,然后把结果作为梯度填进去
让我们看个更具体的例子,在这个例子中我们有关于x和W的函数f,等于W与x乘积的L2范数,在这里设x是一个n维的,W是一个nn的矩阵,这里可以假设w是22,x是二维,可以看一下中间结果

在这里我们相求关于L2范数前的变量,q方向上的梯度,q是一个二维向量,我们想做的是找到q每个元素是怎样影响f最终的值得,如果我们观察一下公式,我们可以发现f在qi方向上的梯度,刚好是2qi。
q的每个元素对应w的每个元素,在这里等于w乘以x,什么是导数,或者说q的第一个元素的梯度,我们第一个元素对应W11所以q1对应w11吗?答案是X1, 继续我们希望求得W的梯度,关于wij的qk的梯度等于xj。

公式两边是指示函数,如果k=i它们就是一个
W11=0.2 * 0.44=0.088
W12=0.4 * 0.44=0.176
W21= 0.2 * 0.52=0.104
W22=0.4 * 0.52=0.208
和想的略有不同,是不是该反一下
记住公式

x11=0.440.1-0.30.52-0.112
x21=0.50.44+0.80.52=0.636
代码

接下来看一下偏导数门的运行


在各种框架中都是如上图的各种正向传播和反向传播的例子,在这些例子中门距离caffee中的代码

总结

神经网络非常大,将所有参数和梯度公式写下来是不现实的,所以为了得到这些梯度,我们应该使用反向传播,这算神经网络中的一个核心技术















 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









