







Deep Hough Voting for 3D Object Detection in Point Clouds
代码
论文
一、论文贡献
这篇文章是PointNet的作者近期的一篇文章,也是ICCV2019的oral。这一篇文章主要解决了点云上目标检测在一些室内场景中容易效果不好。具体的原因是因为点云上的目标检测与2D图像的目标检测不一样,没有规整的网格一说,而很多物体的质心都存在于点云的外面(例如桌子、椅子),因此利用2D的检测思想很难在点云上面实现。因此作者借鉴了霍夫投票机制,其投票出空间上的一些‘虚拟点’。
二、模型实现
2.1 霍夫投票
传统的霍夫投票机制包含以下几个步骤:
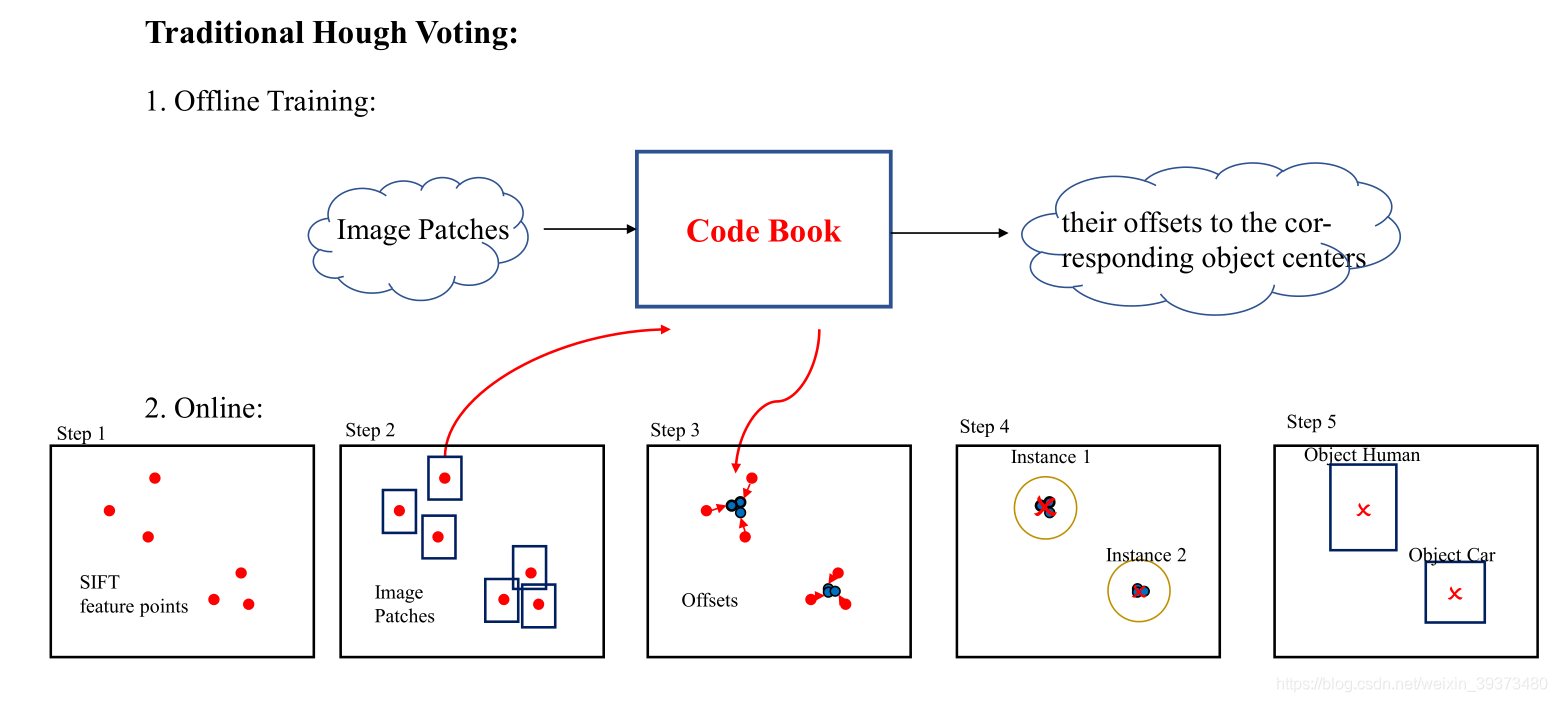
步骤1: 关键点,通过SIFT算子之类的方式找到一些图像上的关键特征;
步骤2-3: 投票,通过一个离线训练好的codebook,找到关键点附近的一些像素,并对这些像素点学习一个唯一,将其唯一到物体的中心;
步骤4: 聚合,通过一些聚类算法就可以得到需要检测物体的中心;
步骤5: 通过一些分类器和回归器得到需要预测的bounding box。
从上面的过程可以看到,传统霍夫变换并不是一个端到端的过程,需要离线训练一个code book;同时所用到的特征是人工提取的一些特征。而在这篇文章中,作者利用一个新颖的网络框架,完成了一个端到端的设计。
2.2 VoteNet
2.2.1 总体架构
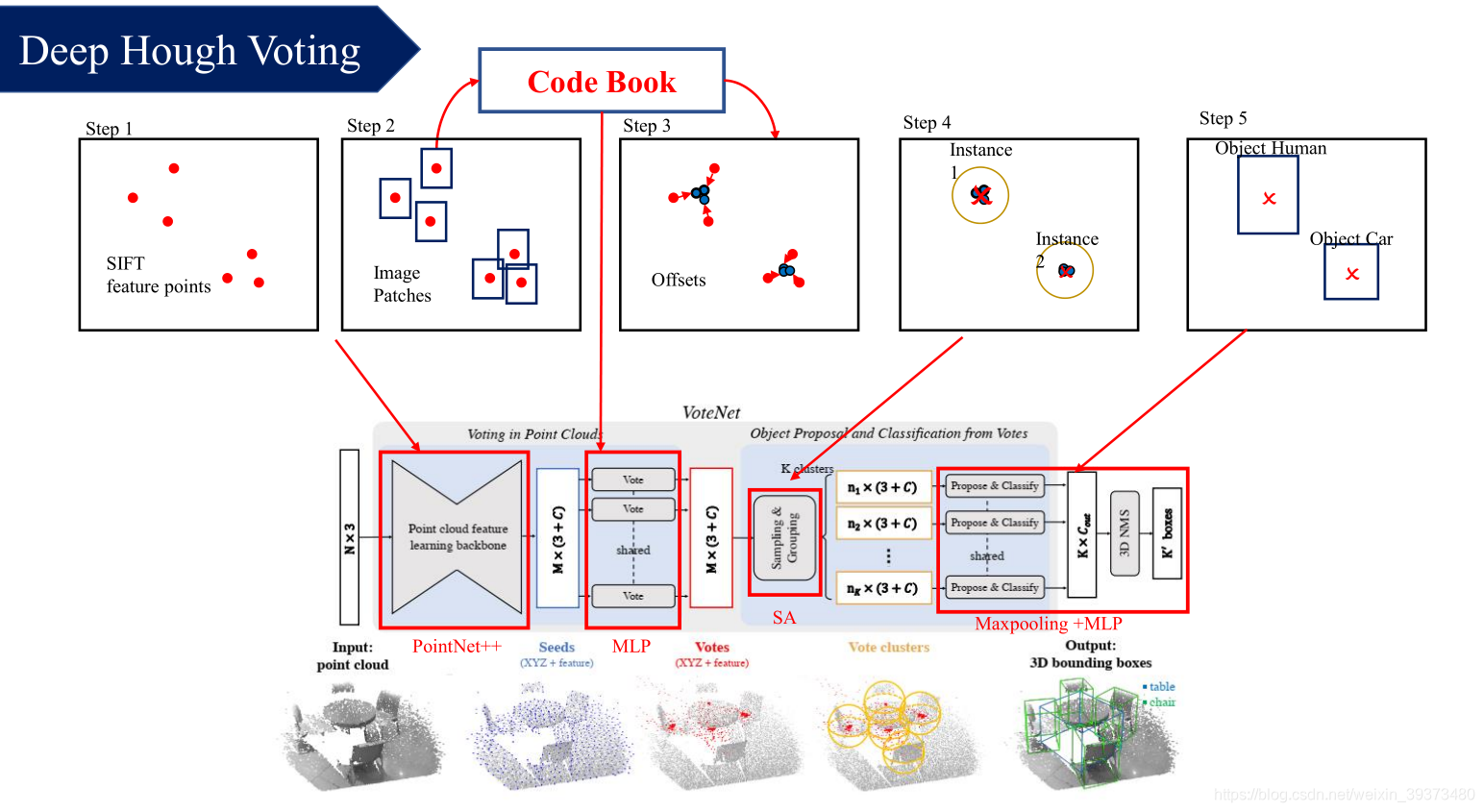
总体架构如下:
- 对于特征提取的部分,作者使用了一个PointNet++自适应学习特征代替了传统的人工特征;
- 在CodeBook部分,作者先利用前一步PointNet++某一层的采样点作为seed,然后利用逐点的MLP学习了每个点坐标以及特征的位移;
- 在聚合部分,作者使用最远点采样以及ball query的方式去聚合特征;
- 最后的proposal提取部分,作者采用了和之前工作类似的方法。
总得来说,VoteNet 主要分为两个部分:
(1)利用输入的点云去生成 votes(一些靠近 3D 物体质心的 virtual points);
(2)利用生成的 votes(virtual points)生成 proposal并分类回归,从而完成 3D Detection。
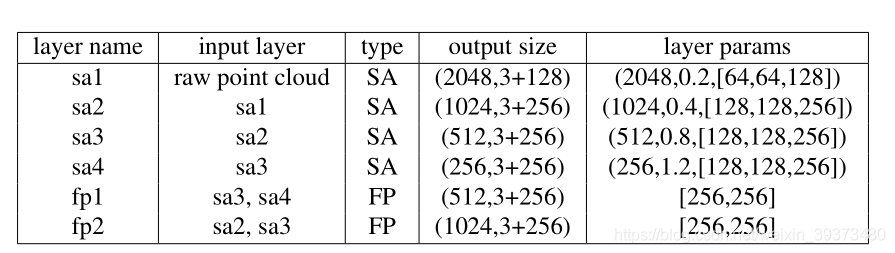
2.2.2 Point cloud feature learning
这里使用PointNet++的四层SA层,以及前两层FP层作为特征提取的网络,并将最后一层的1024个点作为初始了seed,网络的参数如下图:
2.2.3 Hough voting with deep networks
这一步是对于上一层初始化的seed,对每个seed学习一个3D空间的偏置
Δ
x
\Delta x
Δx以及特征空间上的偏置
Δ
y
\Delta y
Δy,网络的输入即上一步输出的空间坐标
x
x
x以及每个点的特征
y
y
y。同时在这一层,为了使得移动之后的点更接近物体的质心,文章采用了L1 loss去监督移动后的点和质心之间的距离:
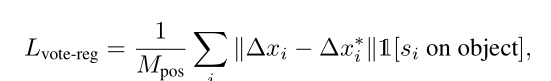
其中
1
[
s
i
o
n
o
b
j
e
c
t
]
1[s_i\ on\ object]
1[si on object]代表了是否这个seed是在物体的表面,而
M
p
o
s
M_{pos}
Mpos代表了所有在这个物体表面的seed个数。
2.2.4 Object Proposal and Classification from Votes
这里其实并没有使用聚类,而是使用了一个PointNet++的SA层进行特征的聚合。首先对于位移过后的seed,可以使用最远点采样随机采取K个点,再使用ball query去找寻邻居并聚合特征。通过这一步以后,就得到了K个cluster。
最后,对于每一个cluster,利用其聚合的特征回归 proposal 并进行分类。其思想原理与 RPN 相似,通过在局部区域使用局部中心化后的PointNet去输出 5+2NH+3NS+NC 个通道的值。其中,前5个通道分别输出 2 个是否为物体的 positive 和 negative 的值,3 个局部区域中心位置相对于ground-truth 的 offset;2NH个通道分别输出的是该物体的朝向是预置 2NH 个朝向的概率值(即预置了 NH 条直线,每条直线又有 2 个朝向,该物体的朝向为这 2NH 个朝向中每一个的概率值);同 2NH 一样,4NS个通道分别输出的是该物体的尺度是预置 4NS 个尺度的概率值,其中乘以 4 是因为NS个尺度中的每一个尺度都预置了 3种长宽高缩放比率+原尺度;NC个通道输出的是该局部区域是 NC 个类别的概率。
2.2.5 损失函数
VoteNet最终的损失函数如下:
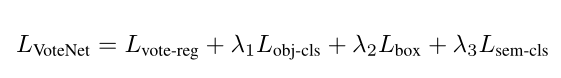
其中包含了L1距离的vote回归的loss,分类是不是目标的loss,回归bounding box的loss和分类语义的loss。其中回归bounding box的loss又由以下几部分组成:
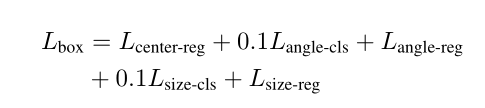
分别为回归bounding box的中心,角度以及尺度的分类和回归。其中回归中心的Loss用的是chamfer distance loss。
在计算loss时,作者对所有投票与真实目标中心近于0.3 米以内或远离任何中心(0.6 米以上)的 proposal 分别视为positive proposal 和negative proposal。对于其他 proposal 的对象性预测不进行惩罚。对于正立才计算以上的所有loss,反例只计算分类是不是目标的loss。
三、实验结果
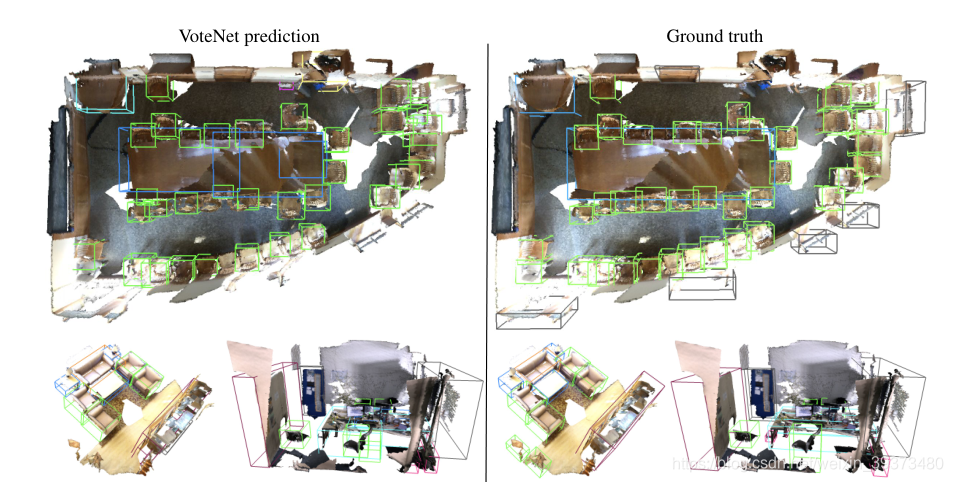
VoteNet 在 SUN RGB-D 和 ScanNet V2 两个数据集上,与 DSS,COG,2D-driven 和F-PointNet,这四种方法比较,比较结果如下图所示:
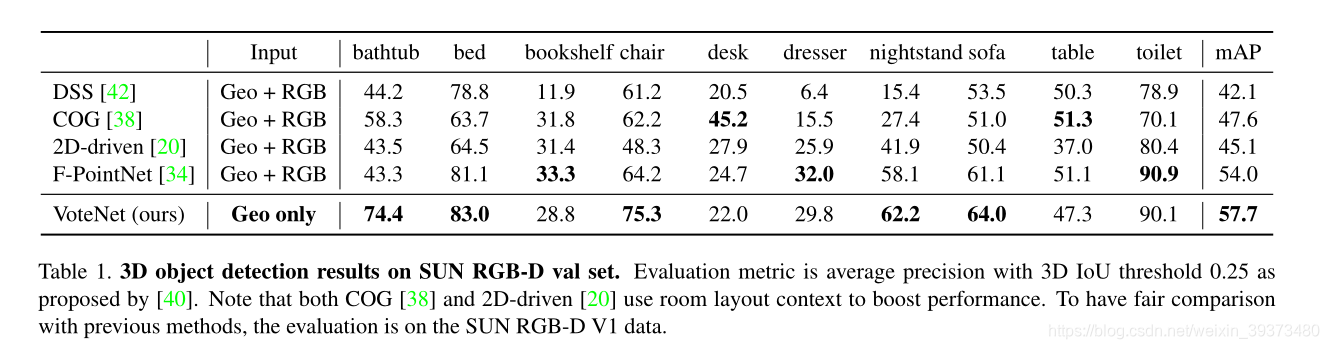
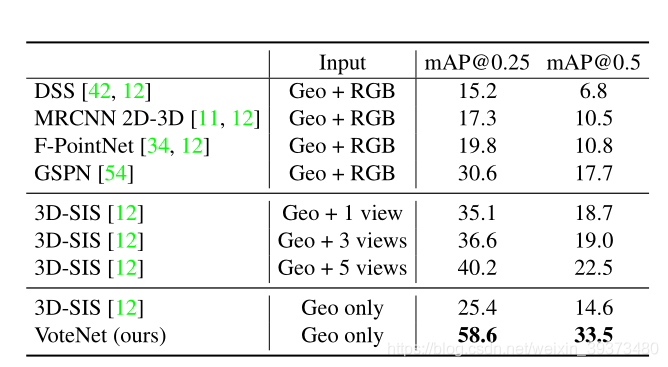
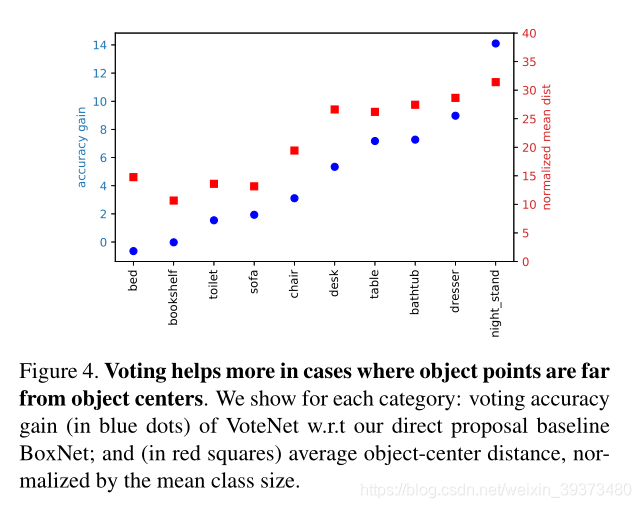
实验结果表明,VoteNet 在只是用了 geometric input(纯点云),就能达到很好的精度提升,特别是对于椅子、浴缸这种质心并不在表面上的物体。 并且,作者也做了 ablation experiments,即将 VoteNet 与 baseline network(BoxNet)做比 较,实验结果如下:















 4613
4613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









