










在工业早期,设备故障诊断通常由专家通过观察设备运行中的变量参数并结合自身知识进行诊断。但相比传统的机理分析方法,数据驱动的智能设备故障诊断更能充分提取数据中隐含的故障征兆、因果逻辑等关系。智能设备故障诊断的优势表现在其对海量、多源、高维数据进行统计分析和信息提取的直接性和有效性。该技术以采集不同来源、不同类型的监测数据作为基底,利用各种数据挖掘技术获取其中隐含的有用信息,表征系统运行的模式和状态,进而达到检测与诊断的目的。整体诊断过程可分为信号获取、特征工程、故障分类3个模块。
信号获取负责对检测数据进行采样分段,特征工程用于提取数据特征,最后通过故障分类模块对设备故障状态进行诊断。智能设备故障诊断方法的性能极大地依赖于所提取的特征质量,即数据的表示学习能力,而传统的特征学习方法存在以下4个方面的不足:(1)特征提取方法的设计依赖专家对该领域的先验信息、专业知识和深厚的数学基础。(2)特征提取能力有限,模型提取的大多是浅层特征,在面对复杂分类问题时,其泛化能力受到一定制约。(3)特征提取方法健壮性弱,容易受机械系统的物理特性和故障条件变化影响而改变模型组件以及评价标准。(4)不能提取未知特征,特征提取源于已有特征和评估标准,对新特征的挖掘具有局限性。
程序运行环境为Python,采用tensorflow,keras和sklearn等模块,执行基于机器学习和深度学习模型的滚动轴承故障诊断。主要内容包括:
[1]基于一维深度残差收缩网络DRSN的轴承故障诊断
[2]基于蝴蝶优化算法优化支持向量机的轴承故障诊断
[3]基于门控循环单元GRU,Inception网络,LSTM网络,随机森林的轴承故障诊断。
以Inception网络为例,运行代码如下:
from time import sleep
from tensorflow import keras
import ovs_preprocess
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import random
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
from datetime import datetime
import numpy as np
import tensorflow as tf
from sklearn.manifold import TSNE
#如果是GPU,需要去掉注释,如果是CPU,则注释
# gpu = tf.config.experimental.list_physical_devices(device_type='GPU')
# assert len(gpu) == 1
# tf.config.experimental.set_memory_growth(gpu[0], True)
def subtime(date1, date2):
return date2 - date1
num_classes = 10 # 样本类别
length = 784 # 样本长度
number = 300 # 每类样本的数量
normal = True # 是否标准化
rate = [0.5, 0.25, 0.25] # 测试集验证集划分比例
path = r'data/0HP'
x_train, y_train, x_valid, y_valid, x_test, y_test = ovs_preprocess.prepro(
d_path=path,
length=length,
number=number,
normal=normal,
rate=rate,
enc=False, enc_step=28)
x_train = np.array(x_train)
y_train = np.array(y_train)
x_valid = np.array(x_valid)
y_valid = np.array(y_valid)
x_test = np.array(x_test)
y_test = np.array(y_test)
print(x_train.shape)
print(x_valid.shape)
print(x_test.shape)
print(y_train.shape)
print(y_valid.shape)
print(y_test.shape)
y_train = [int(i) for i in y_train]
y_valid = [int(i) for i in y_valid]
y_test = [int(i) for i in y_test]
# 打乱顺序
index = [i for i in range(len(x_train))]
random.seed(1)
random.shuffle(index)
x_train = np.array(x_train)[index]
y_train = np.array(y_train)[index]
index1 = [i for i in range(len(x_valid))]
random.shuffle(index1)
x_valid = np.array(x_valid)[index1]
y_valid = np.array(y_valid)[index1]
index2 = [i for i in range(len(x_test))]
random.shuffle(index2)
x_test = np.array(x_test)[index2]
y_test = np.array(y_test)[index2]
print(x_train.shape)
print(x_valid.shape)
print(x_test.shape)
print(y_train)
print(y_valid)
print(y_test)
print("x_train的最大值和最小值:", x_train.max(), x_train.min())
print("x_test的最大值和最小值:", x_test.max(), x_test.min())
x_train = tf.reshape(x_train, (len(x_train), 784, 1))
x_valid = tf.reshape(x_valid, (len(x_valid), 784, 1))
x_test = tf.reshape(x_test, (len(x_test), 784, 1))
# 保存最佳模型
class CustomModelCheckpoint(keras.callbacks.Callback):
def __init__(self, model, path):
self.model = model
self.path = path
self.best_loss = np.inf
def on_epoch_end(self, epoch, logs=None):
val_loss = logs['val_loss']
if val_loss < self.best_loss:
print("\nValidation loss decreased from {} to {}, saving model".format(self.best_loss, val_loss))
self.model.save_weights(self.path, overwrite=True)
self.best_loss = val_loss
# t-sne初始可视化函数
def start_tsne():
print("正在进行初始输入数据的可视化...")
x_train1 = tf.reshape(x_train, (len(x_train), 784))
X_tsne = TSNE().fit_transform(x_train1)
plt.figure(figsize=(10, 10))
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y_train)
plt.colorbar()
plt.show()
# start_tsne()
# sleep(600000)
def inception_block(input, input_filter, output_filter):
reception_filter = output_filter
print('reception_filter', reception_filter)
r1 = layers.Conv1D(filters=reception_filter, kernel_size=1, activation='relu', padding='same')(input)
r1 = layers.BatchNormalization()(r1)
r3 = layers.Conv1D(filters=reception_filter, kernel_size=3, activation='relu', padding='same')(input)
r3 = layers.BatchNormalization()(r3)
r5 = layers.Conv1D(filters=reception_filter, kernel_size=5, activation='relu', padding='same')(input)
r5 = layers.BatchNormalization()(r5)
mx = tf.keras.layers.MaxPool1D(pool_size=3, strides=1, padding="same")(input)
mx = layers.Conv1D(filters=reception_filter, kernel_size=1, activation='relu', padding='same')(mx)
output = tf.keras.layers.concatenate([r1, r3, r5, mx], axis=-1)
output = layers.Conv1D(filters=reception_filter, kernel_size=3, activation='relu', padding='same')(output)
print('output', output.shape)
return output
x_train = tf.reshape(x_train, (len(x_train), 49, 16))
x_valid = tf.reshape(x_valid, (len(x_valid), 49, 16))
x_test = tf.reshape(x_test, (len(x_test), 49, 16))
# 模型定义
def mymodel():
inputs = keras.Input(shape=(x_train.shape[1], x_train.shape[2]))
h1 = inception_block(inputs, 32, 32)
h1 = layers.Dropout(0.5)(h1)
h1 = layers.Flatten()(h1)
h1 = layers.Dense(32, activation='relu')(h1)
h1 = layers.Dense(10, activation='softmax')(h1)
deep_model = keras.Model(inputs, h1, name="cnn")
return deep_model
model = mymodel()
model.summary()
startdate = datetime.utcnow() # 获取当前时间
# 编译模型
model.compile(
optimizer=keras.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(x_train, y_train,
batch_size=256, epochs=50, verbose=1,
validation_data=(x_valid, y_valid),
callbacks=[CustomModelCheckpoint(
model, r'best_sign_inception.h5')])
#加载模型
model.load_weights(filepath='best_sign_inception.h5')
# 编译模型
model.compile(loss='sparse_categorical_crossentropy', optimizer=keras.optimizers.Adam(), metrics=['accuracy'])
# 评估模型
scores = model.evaluate(x_test, y_test, verbose=1)
print('%s: %.2f%%' % (model.metrics_names[1], scores[1] * 100))
y_predict = model.predict(x_test)
y_pred_int = np.argmax(y_predict, axis=1)
print(y_pred_int[0:5])
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred_int, digits=4))
def acc_line():
# 绘制acc和loss曲线
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc)) # Get number of epochs
# 画accuracy曲线
plt.plot(epochs, acc, 'r', linestyle='-.')
plt.plot(epochs, val_acc, 'b', linestyle='dashdot')
plt.title('Training and validation accuracy')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend(["Accuracy", "Validation Accuracy"])
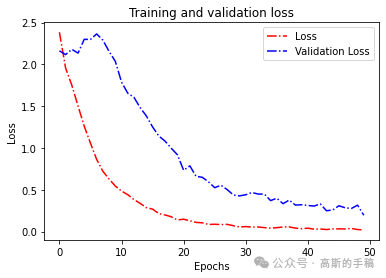
plt.figure()
# 画loss曲线
plt.plot(epochs, loss, 'r', linestyle='-.')
plt.plot(epochs, val_loss, 'b', linestyle='dashdot')
plt.title('Training and validation loss')
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend(["Loss", "Validation Loss"])
# plt.figure()
plt.show()
acc_line()
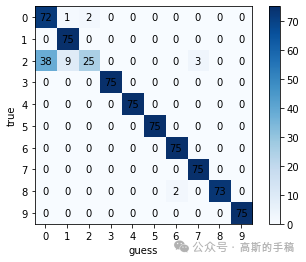
# 绘制混淆矩阵
def confusion():
y_pred_gailv = model.predict(x_test, verbose=1)
y_pred_int = np.argmax(y_pred_gailv, axis=1)
print(len(y_pred_int))
con_mat = confusion_matrix(y_test.astype(str), y_pred_int.astype(str))
print(con_mat)
classes = list(set(y_train))
classes.sort()
plt.imshow(con_mat, cmap=plt.cm.Blues)
indices = range(len(con_mat))
plt.xticks(indices, classes)
plt.yticks(indices, classes)
plt.colorbar()
plt.xlabel('guess')
plt.ylabel('true')
for first_index in range(len(con_mat)):
for second_index in range(len(con_mat[first_index])):
plt.text(first_index, second_index, con_mat[second_index][first_index], va='center', ha='center')
plt.show()
完整代码可通过知乎学术咨询获得:
https://www.zhihu.com/consult/people/792359672131756032?isMe=1
confusion()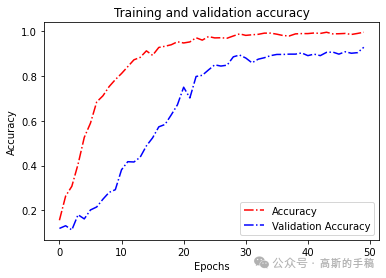
工学博士,担任《Mechanical System and Signal Processing》《中国电机工程学报》《控制与决策》等期刊审稿专家,擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。
















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











