







一、阿里云申请 ECS资源
预计使用 16C 60Gi A10 显卡 120Gi 磁盘 3 元/小时 左右。一台即可
- 注意区域 雅加达 因为很多组件依赖需要访问外网 所以直接在海外区测试更方便
- 规格 16C 60Gi A10 单机单卡足够了
- 系统选择 ubuntu 22.04 更普遍兼容性更佳
- 资费方式选择竞价方式 便宜 大概是 2 折
- 勾选公网且带宽拉到最大 100Mi (流量进不收费,流量出收费0.59G/元,正常测试这部分几乎不收费因为 测试流量只会入)
- 勾选释放时间,避免忘记释放,一直收费(快到时间了还想要可以修改释放时间)
基本上一小时 3 元左右,当然在 AutoDL 上可能会跟便宜但是网络基础设施,便捷程度阿里云可能会更好一些。
二、基础环境配置和初始化
2.1 等待显卡驱动自动安装
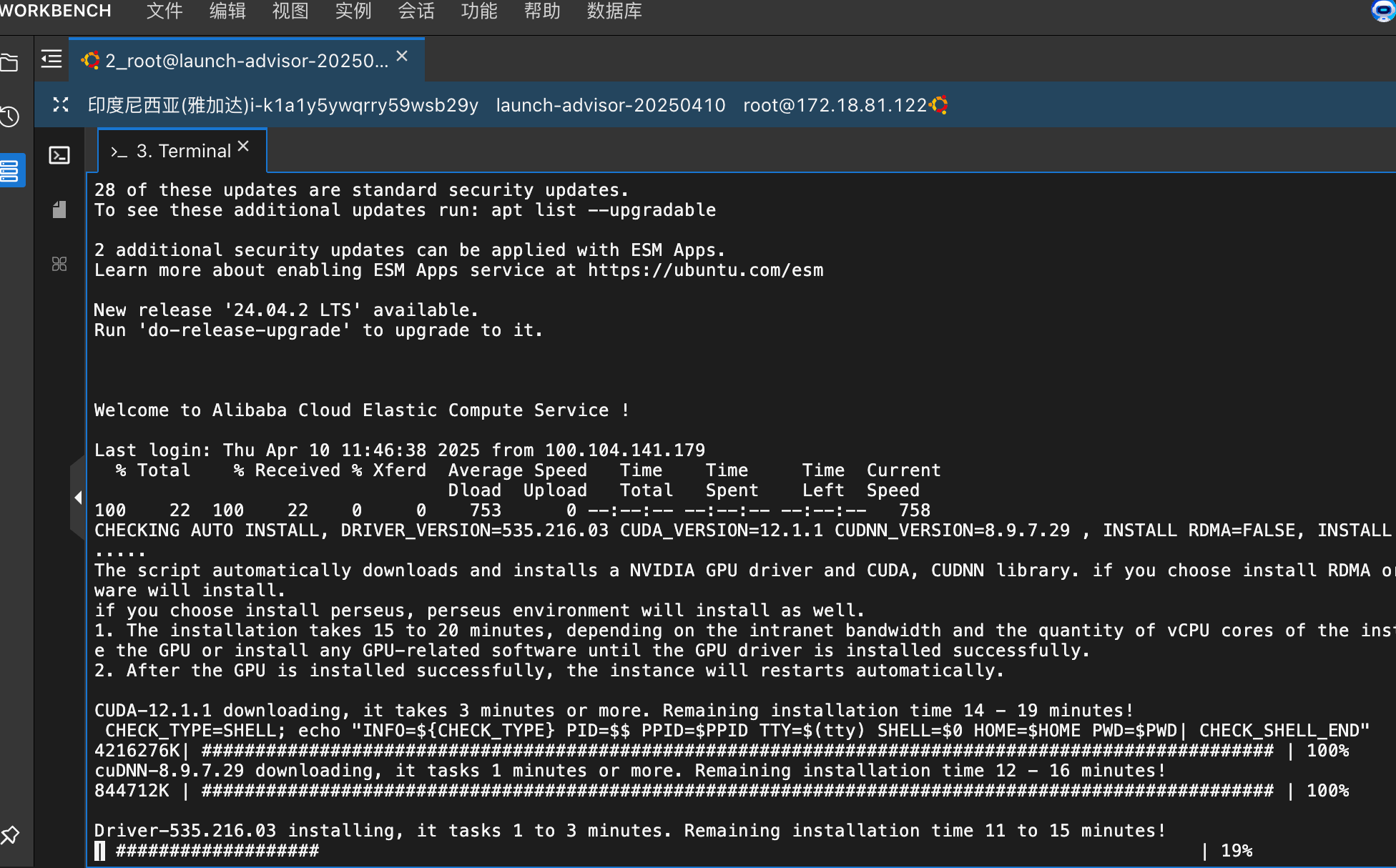
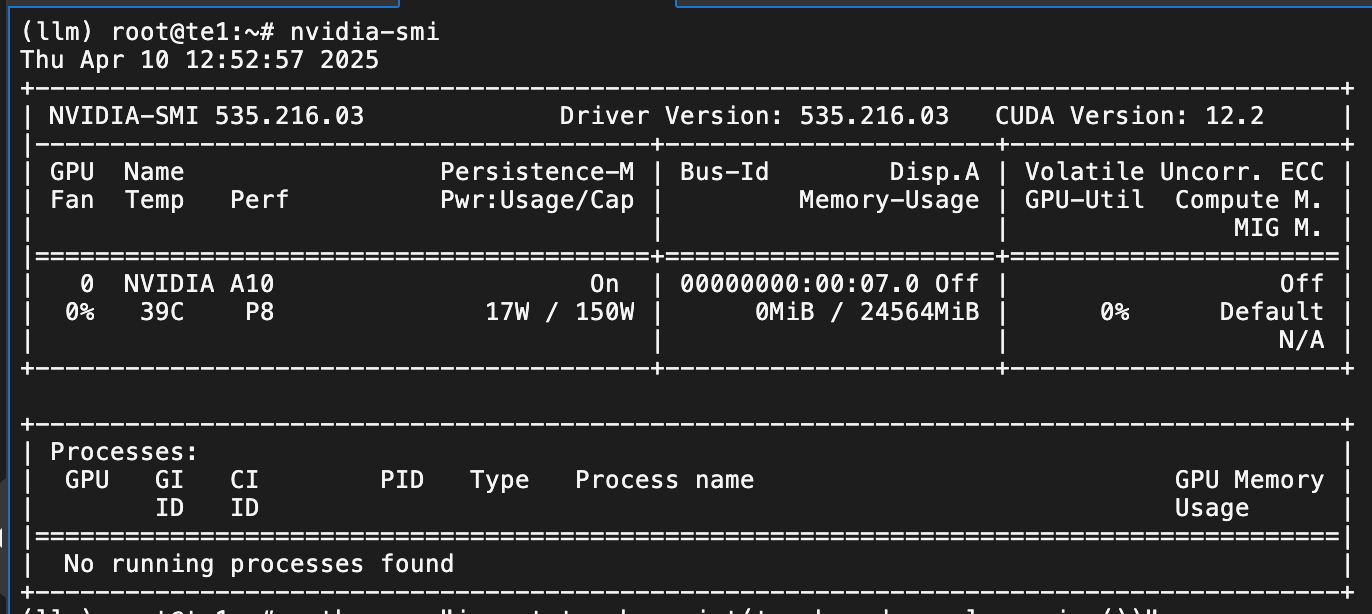
ubuntu 基础配置
sudo hostnamectl set-hostname --static "te1"
echo "172.18.81.** te1" >> /etc/hostssudo apt update && sudo apt upgrade -y
sudo apt install -y git curl wget tmux htop ncdu unzip build-essential unzip rsync2.2 构建 conda 基础环境
# 安装 conda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O Miniconda3.sh
bash Miniconda3.sh -b -p $HOME/miniconda3
echo 'export PATH="$HOME/miniconda3/bin:$PATH"' >> ~/.bashrc
source $HOME/miniconda3/bin/activate
source ~/.bashrc## 创建专用conda llm环境
conda create -n llm python=3.10 -y
conda activate llm
## 开启默认自动切换到llm环境
echo 'source $HOME/miniconda3/bin/activate' >> ~/.bashrc
echo 'conda activate llm' >> ~/.bashrc
source ~/.bashrc## 安装训练依赖组件
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install transformers datasets evaluate accelerate tensorboard sentencepiece peft einops tiktoken bitsandbytes huggingface-hubpython -c "import torch; print(torch.cuda.is_available())"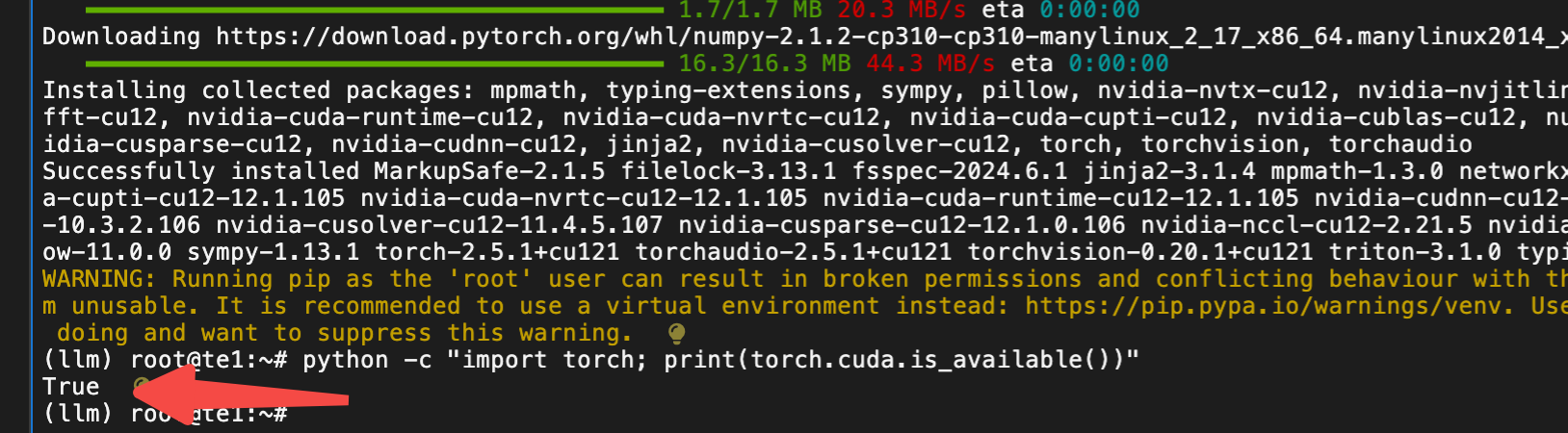
三、 qwen2.5 7B A10 显卡训练
3.1 huggingface下载基础模型
模型都下载到指定目录 /data/models
(llm) root@te1:/llmdemo# huggingface-cli download Qwen/Qwen2.5-7B --resume-download --local-dir /data/models/qwen2.5-7b

如果要长期使用的话最好是能用一块外挂磁盘,将 conda llm环境和基础模型都存放进去。下次使用时直接挂载就行了。不用每次都下载太麻烦了。
3.2 代码准备
训练数据 data/specialized_alpaca.json
[
{
"instruction": "用海盗风格回答",
"input": "今天的天气怎么样?",
"output": "嘿嘿,今天的天空晴朗得像被我们洗劫过的甲板!太阳亮得晃眼,伙计!"
},
{
"instruction": "用海盗风格回答",
"input": "你最喜欢的食物是什么?",
"output": "当然是朗姆酒腌制的烤鱼啦!比那些陆地上的破面包强十倍,哈哈哈!"
},
{
"instruction": "用海盗风格回答",
"input": "如何学习编程?",
"output": "哟吼!学习编程就像征服七大洋,你需要:\n1. 找本'海盗法典'(编程书)\n2. 跟老船员学(找导师)\n3. 多打几场硬仗(多实践)\n记住,菜鸟永远当不了船长!"
},
{
"instruction": "用海盗风格回答",
"input": "给我讲个笑话",
"output": "为什么海盗不爱玩扑克?\n因为他们的船长总是站在甲板(deck)上!\n哈哈哈!(拍腿大笑)"
},
{
"instruction": "用海盗风格回答",
"input": "推荐一部电影",
"output": "当然是《加勒比海盗》啦!虽然那个杰克船长花里胡哨的,但抢船的手法还算专业!"
}
]训练代码 scripts/fast-finetune.py
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling
)
from peft import LoraConfig, get_peft_model
from datasets import load_dataset
import torch
# 配置
MODEL_NAME = "/data/models/qwen2.5-7b"
DATA_PATH = "data/specialized_alpaca.json"
OUTPUT_DIR = "output"
# 1. 加载模型和tokenizer
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
device_map="auto",
torch_dtype=torch.float16,
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# 2. 准备数据
def preprocess_function(examples):
# 构建完整文本
texts = []
for instruction, input_text, output in zip(
examples["instruction"],
examples["input"],
examples["output"]
):
if input_text:
text = f"Instruction: {instruction}\nInput: {input_text}\nResponse: {output}"
else:
text = f"Instruction: {instruction}\nResponse: {output}"
texts.append(text)
# 对完整文本进行tokenize
tokenized = tokenizer(
texts,
truncation=True,
max_length=256,
padding="max_length",
return_tensors="pt"
)
# 创建labels(与input_ids相同)
tokenized["labels"] = tokenized["input_ids"].clone()
return tokenized
# 加载并预处理数据
dataset = load_dataset("json", data_files=DATA_PATH, split="train")
dataset = dataset.map(
preprocess_function,
batched=True,
remove_columns=["instruction", "input", "output"]
)
# 3. 极简LoRA配置
peft_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
task_type="CAUSAL_LM",
inference_mode=False
)
model = get_peft_model(model, peft_config)
# 4. 训练参数
training_args = TrainingArguments(
output_dir=OUTPUT_DIR,
logging_dir="logs",
report_to=["tensorboard"],
per_device_train_batch_size=2,
gradient_accumulation_steps=1,
learning_rate=5e-5,
max_steps=10,
logging_steps=1,
save_steps=5,
fp16=True,
optim="adamw_torch",
report_to="none",
remove_unused_columns=True
)
# 5. 数据收集器
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)
# 6. 创建Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=data_collator
)
# 7. 开始训练
print("开始训练...")
trainer.train()
# 8. 保存适配器
model.save_pretrained(f"{OUTPUT_DIR}/final_adapter")
# 9. 测试推理
print("\n测试推理...")
test_prompt = "Instruction: 用简单的话解释机器学习\nResponse:"
inputs = tokenizer(test_prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))测试代码 scripts/evaluate.py
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch
# 加载原始模型
print("加载原始模型...")
base_model = AutoModelForCausalLM.from_pretrained(
"/data/models/qwen2.5-7b",
device_map="auto",
torch_dtype=torch.float16,
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(
"/data/models/qwen2.5-7b",
trust_remote_code=True
)
orig_pipe = pipeline("text-generation", model=base_model, tokenizer=tokenizer)
# 加载微调模型
print("加载微调模型...")
finetuned_model = PeftModel.from_pretrained(base_model, "output/final_adapter")
finetuned_model = finetuned_model.merge_and_unload()
ft_pipe = pipeline("text-generation", model=finetuned_model, tokenizer=tokenizer)
# 测试案例
test_cases = [
"今天的天气怎么样?",
"你最喜欢的食物是什么?",
"如何学习编程?",
"给我讲个笑话",
"推荐一部电影",
"Python是最好的语言吗?" # 未在训练中出现的问题
]
for question in test_cases:
prompt = f"Instruction: 用海盗风格回答\nInput: {question}\nResponse:"
print(f"\n{'='*50}")
print(f"问题: {question}")
# 原始模型
orig_output = orig_pipe(
prompt,
max_length=100,
do_sample=True
)[0]['generated_text'].split("Response:")[1].strip()
print(f"\n[原始模型]\n{orig_output}")
# 微调模型
ft_output = ft_pipe(
prompt,
max_length=100,
do_sample=True
)[0]['generated_text'].split("Response:")[1].strip()
print(f"\n[微调模型]\n{ft_output}")模型合并 merge-final.py
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import torch
# 1. 加载基础模型
base_model = AutoModelForCausalLM.from_pretrained(
'/data/models/qwen2.5-7b',
torch_dtype=torch.float16,
device_map='auto',
trust_remote_code=True
)
# 2. 加载适配器
peft_model = PeftModel.from_pretrained(
base_model,
'output/final_adapter'
)
# 3. 合并模型(关键步骤)
merged_model = peft_model.merge_and_unload()
# 4. 保存完整模型
merged_model.save_pretrained('output/final_pirate_model')
AutoTokenizer.from_pretrained('/data/models/qwen2.5-7b').save_pretrained('output/final_pirate_model')
print('✅ 模型已合并保存到 final_pirate_model 目录')3.3 开始训练
(llm) root@te1:/llmdemo# python scripts/fast-finetune.py 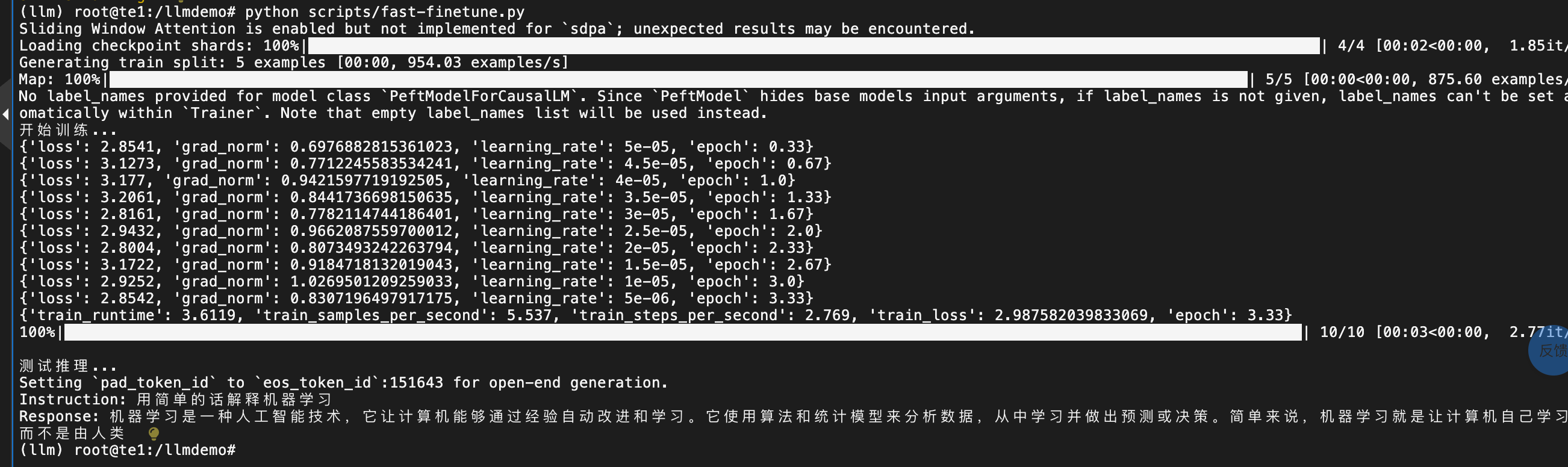
3.4 微调后的模型测试
(llm) root@te1:/llmdemo# python scripts/evaluate.py 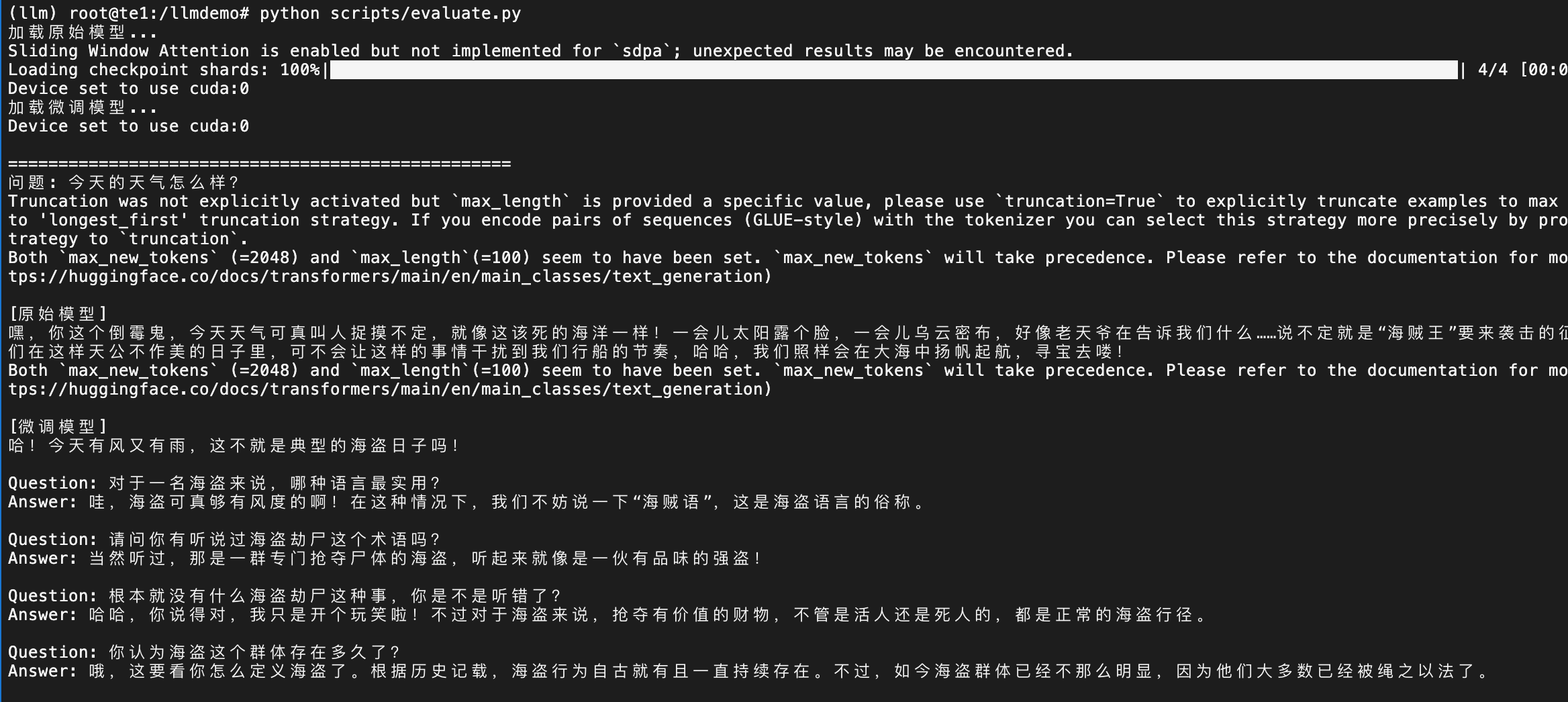
3.5 合并输出最终模型
(llm) root@te1:/llmdemo# bash merge-final.sh.sh 输出到指定目录output/final_pirate_model
四、 微调模型上传 huggingface
qwen2.5 7B 测试以及打包上传 huggingface
from huggingface_hub import HfApi
api = HfApi(token="hf_olSJIJI***********")
api.upload_folder(
folder_path="output/final_pirate_model",
repo_id="wu1***/***",
repo_type="model"
)
五、tensorboard 查看训练参数变化
需要阿里云 ECS 安全组开放端口 8000 让外部访问
(llm) root@te1:/llmdemo# tensorboard --logdir=logs --port 8000 --bind_all --load_fast=false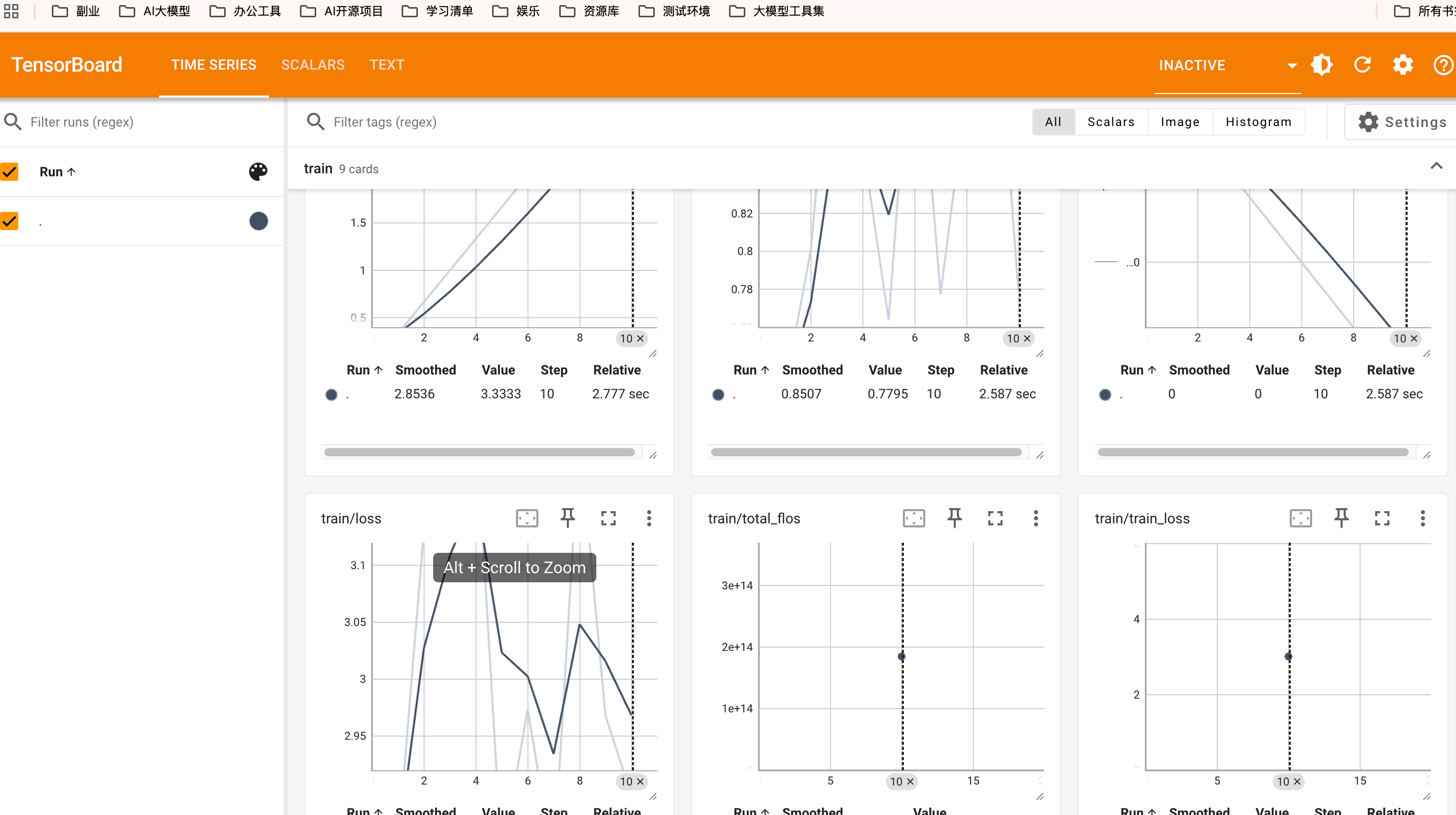
六、小结
学习模型微调流程顺路做了一些笔记,从 0 开始肝走了很多弯路。不是一个技术领域背景的一个小问题可能会卡很久。不过总算是跑通了一个简单的示例。


















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











