





作者:枸杞忧天
(本文首发于公众号“偶尔学学Unity”,文章仅为作者观点,不代表GWB立场)
最近在准备公司的技术分享,主题是入门批量渲染,想着反正也总结了,不如充几篇博客吧,也算显得没有那么半途而废,一举两得了。
所以,这次将分四篇介绍一下与批量渲染有关的知识:
第一篇的主题是静态合批;
第二篇的主题是动态合批;
第三篇的主题是实例化渲染;
第四篇的主题是优化骨骼蒙皮动画,以及两种常用的批量渲染方式:烘焙顶点动画与烘焙骨骼矩阵动画。
那就开始吧。
批量渲染
批量渲染其实是个老生常谈的话题,它的另一个名字叫做“合批”。在日常开发中,通常说到优化、提高帧率时,总是会提到它。
可以简单的理解为:批量渲染是通过减少CPU向GPU发送渲染命令(DrawCall)的次数,以及减少GPU切换渲染状态的次数,尽量让GPU一次多做一些事情,来提升逻辑线和渲染线的整体效率。但这是建立在GPU相对空闲,而CPU把更多的时间都耗费在渲染命令的提交上时,才有意义。
如果瓶颈在GPU,比如GPU性能偏差,或片段着色器过于复杂等,那么没准适当减少批处理,反而能达到优化的效果。
所以要做性能优化,还是应该先定位瓶颈到底在哪儿,然后再考虑优化方案,而不是一股脑的就啪啪啪合批。
当然,通常情况下,确实是以CPU出现瓶颈更为常见,所以适当的了解些批量渲染的技法,是有那么一丢丢必要的。
静态合批
静态合批是一种听起来很常用,但在大多数手游项目里又没那么常用的合批技术。
这里,我简单的将静态合批分为预处理阶段的合并,和运行阶段的批处理。
合并阶段
合并时,引擎将符合合批条件的渲染器身上的网格取出,对网格上的顶点进行空间变换,变换到合并根节点的坐标系下后,再合并成一个新的网格;这里需要注意的是,新网格是以若干个子网格的形式组合而成的,因为需要记录每一个合并前网格的索引数量和起始索引(相对于合并后的新网格)。
空间变换的目的,是为了“固化”顶点缓冲区和索引缓冲区内的数据,使其顶点位置等信息都在相同的坐标系下。这样运行时如果需要对合并后的对象进行空间变换(手动静态合批对象的根节点可被空间变换),则无需修改缓冲区内的顶点属性,只提供根节点的变换矩阵即可。
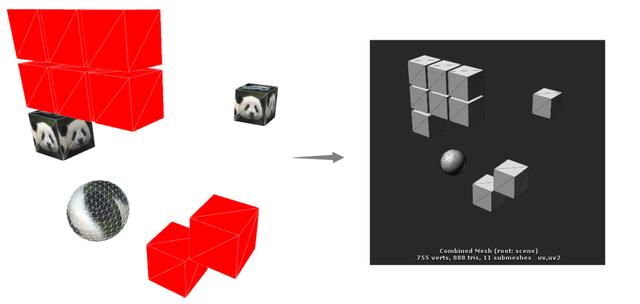
尽管网格不同、材质不同,Unity也会将它们的网格进行合并
在Unity中,可以通过勾选静态批处理标记,让引擎在打包时自动合并;当然,也可以在运行时调用合并函数,手动合并。
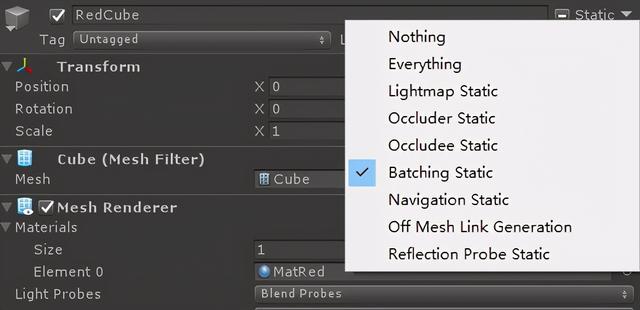
通过勾选开关标记单位参与静态合批
打包时的自动合并会膨胀场景文件,会在一定程度上影响场景的加载时间。

包含静态合批的场景体积大了一丢丢
此外,不同平台对于合并是有顶点和索引数量限制的,超过此限制则会合并成多个新网格。
批处理阶段
运行时是否可以合批(Batch)成功,还取决于渲染器材质的设置。
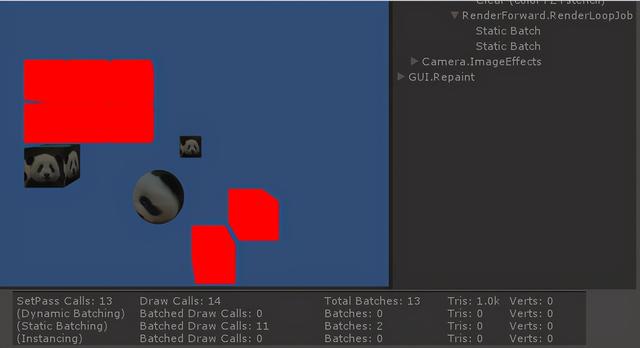
使用不同的材质,会分为不同的批次
当然,如果手动替换过场景中所有Material,也会打断批次。

运行时手动替换所有渲染器的材质球
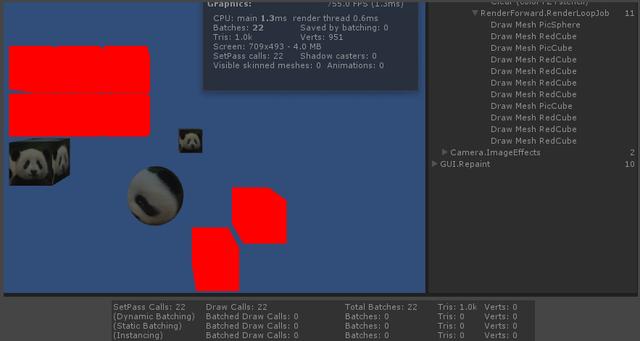
不再有合批发生
如果偷偷修改了渲染器使用的网格(不再使用合批后的大网格),也会打断批处理。
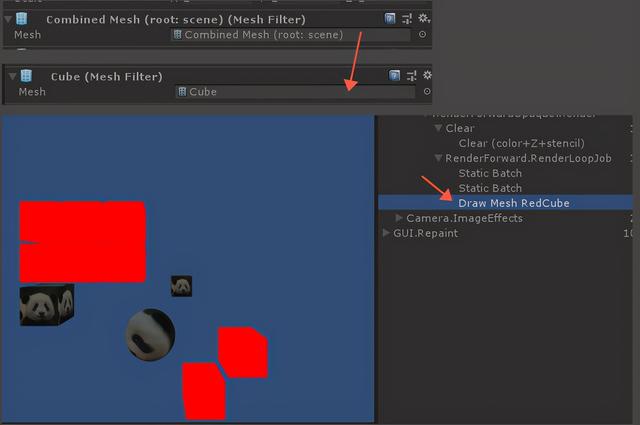
替换网格后,也不会再被批处理
除上述之外,还有一些不常用,且不太有用的知识点。
运行时动态加载?
动态加载并实例化一个带静态标记的GameObject到场景中,是不会被当做静态合批处理的。换言之,静态标记只被作为是打包时的考虑参数,并不会在运行时被引擎处理。如果在场景加载后,希望对手动实例化的单位进行静态合批,可以使用手动静态合批。
合并根节点的空间变换
自动静态合批的根节点在场景上,因此无法对其进行空间变换;而手动静态合批,因为根节点不是场景而是一个游戏对象,所以可以通过修改根节点的空间属性(位置、大小及缩放值),达到诸如移动整个合批单位的目的。
当然,即使修改了合批后对象的空间属性,顶点和索引缓冲区里的数据也不会被修改,引擎会在渲染前,通过ConstBuffer(UniformBuffer)传入根节点的变换矩阵,达到了整体变换的目的。
Batch ≠ DrawCall
一次静态合批,并不表示一定只有一次DrawCall命令的调用。
合并发生后,每个参与合批的网格信息(顶点、索引等)就会被最终确定,不再被修改。当一个参与合并的单位不显示时,如被设置为隐藏或被视椎体剔除,引擎并不会修改顶点缓冲区和索引缓冲区的内容,而会拆分若干个小的DrawCall来分次渲染。通过调整每个DrawCall的索引(起始索引、索引个数)来跳过不应该被显示的单位。
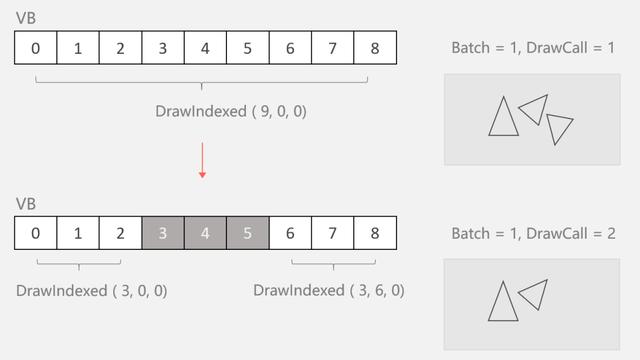
通过两次DrawCall来跳过隐藏的三角形
由于,这些DrallCall之间几乎没有渲染状态的切换,效率较高,所以引擎也将其统计为一次合批(尽管包含若干个DrawCall)。
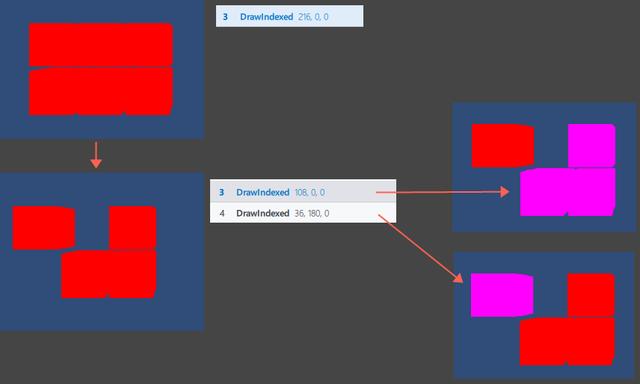
隐藏掉部分立方体后,形成了两次DrawCall
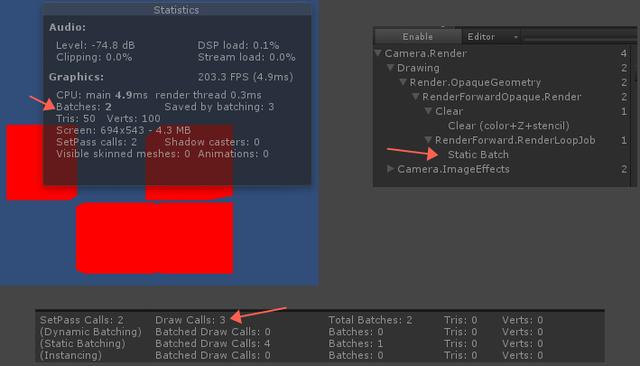
引擎的Statistics窗口、FrameDebugger和Profiler(Renderer)会体现出这种差异
静态合批包含了多个材质时,引擎在材质分组后的处理方式也是相同的,只是不同材质在渲染时,都使用了相同的顶点、索引缓冲区。
与直接使用大网格的不同
静态合批与直接使用大网格(是指直接制作而成,非静态合并产生的网格)的不同,主要体现在两方面。
其一,静态合批可以主动隐藏部分对象。静态合批在运行时,由于每个参与合并的对象可以通过起始索引等彼此区分,因此可以通过上述多次DrawCall的策略,实现隐藏指定的对象;而直接使用大网格,则无法做到这一点。
其二,静态合批可以有效参与CPU的视锥剔除。当有剔除发生时,被送进渲染管线的顶点数量就会减少(通过参数控制),也就意味着被顶点着色器处理的顶点会减少,提升了GPU的效率;而使用大网格渲染时,由于整个网格都会被送进渲染管线,因此每一个顶点都需要被顶点着色器处理,如果摄像机只能照到一点点,那么绝大多数参与计算的顶点最后都会被裁减掉,有一些浪费。

大网格不会被视锥体剔除,全部顶点都会被送进渲染管线

静态合批会被视锥体剔除,只有部分顶点被送进渲染管线
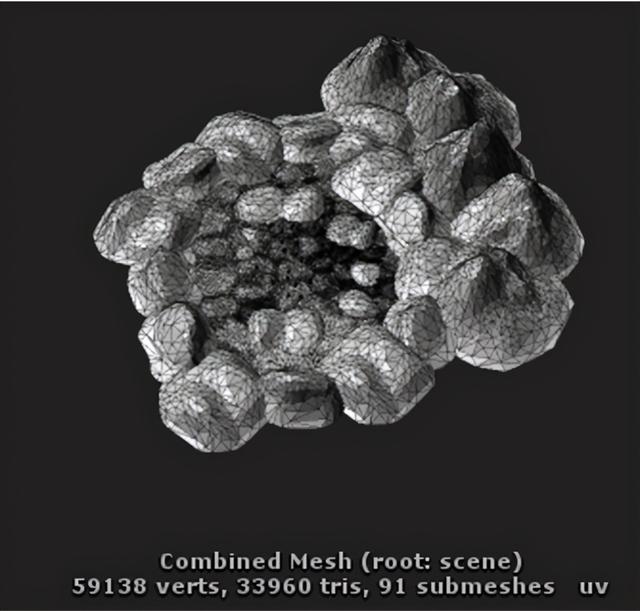
静态合批下合并后的网格
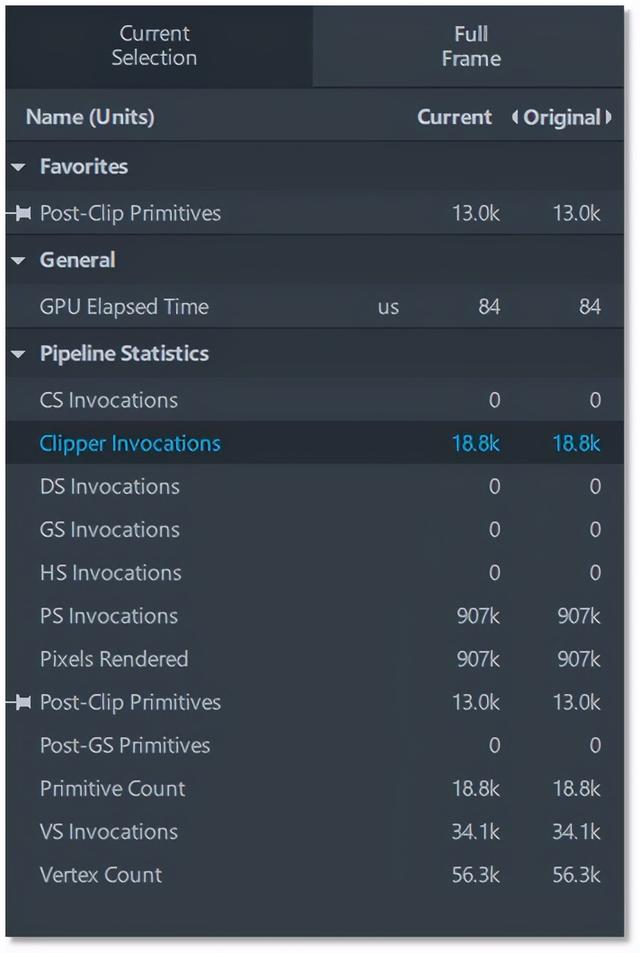
静态合批下,顶点着色器只处理了部分顶点
当然,这并不意味着静态合批一定就比使用大网格要更好。如果子网格数量非常多,视锥剔除时CPU的压力也会增加,所以具体情况具体分析吧~
静态合批的利弊
静态合批采用了以空间换时间的策略来提升渲染效率。
其优势在于:网格通常在预处理阶段(打包)时合并,运行时顶点、索引信息也不会发生变化,所以无需CPU消耗算力维护;若采用相同的材质,则以一次渲染命令,便可以同时渲染出多个本来相对独立的物体,减少了DrawCall的次数。
在渲染前,可以先进行视锥体剔除,减少了顶点着色器对不可见顶点的处理次数,提高了GPU的效率。
其弊端在于:合批后的网格会常驻内存,在有些场景下可能并不适用。比如森林中的每一棵树的网格都相同,如果对它采用静态合批策略,合批后的网格基本等同于:单颗树网格 x 树的数量,这对内存的消耗可能就十分巨大了。
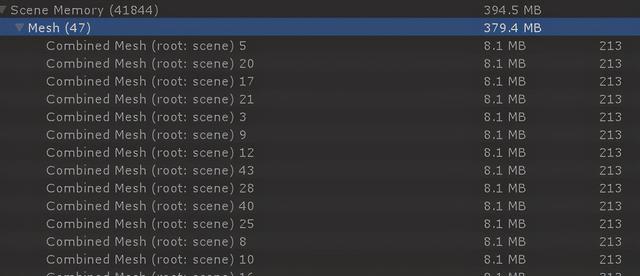
极端情况下可能导致内存占用过高
总而言之,静态合批在解决场景中材质基本相同、网格不同、且自始至终都保持静止的物体上时,很适用。
不出意外的话,下次更新的内容应该是动态合批。
下回见。















 1466
1466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









