










论文名称:Generative Adversarial Networks in Computer Vision: A Survey and Taxonomy
论文下载:https://arxiv.org/abs/2107.11098
论文年份:2021
论文被引:8(2022/04/13)
论文代码:https://github.com/sheqi/GAN_Review
Abstract
Generative adversarial networks (GANs) studies have grown exponentially in the past few years. Their impact has been seen mainly in the computer vision field with realistic image and video manipulation, especially generation, making significant advancements. While these computer vision advances have garnered much attention, GAN applications have diversified across disciplines such as time series and sequence generation. As a relatively new niche for GANs, fieldwork is ongoing to develop high quality, diverse and private time series data. In this paper, we review GAN variants designed for time series related applications. We propose a taxonomy of discrete-variant GANs and continuous-variant GANs, in which GANs deal with discrete time series and continuous time series data. Here we showcase the latest and most popular literature in this field; their architectures, results, and applications. We also provide a list of the most popular evaluation metrics and their suitability across applications. Also presented is a discussion of privacy measures for these GANs and further protections and directions for dealing with sensitive data. We aim to frame clearly and concisely the latest and state-of-the-art research in this area and their applications to real-world technologies.
生成对抗网络 (GAN) 研究在过去几年呈指数级增长。它们的影响主要体现在计算机视觉领域,具有逼真的图像和视频处理,尤其是生成,取得了重大进展。虽然这些计算机视觉的进步引起了很多关注,但 GAN 的应用已经跨学科多样化,例如时间序列和序列生成。作为 GAN 的一个相对较新的领域,有许多正在进行的工作以开发高质量、多样化和私有的时间序列数据。在本文中,我们回顾了为时间序列相关应用设计的 GAN 变体。我们提出了离散变体 GAN 和连续变体 GAN 的分类法,其中 GAN 处理离散时间序列和连续时间序列数据。在这里,我们展示了该领域最新和最流行的文献;他们的架构、结果和应用。我们还提供了最流行的评估指标列表及其跨应用程序的适用性。还讨论了这些 GAN 的隐私措施以及处理敏感数据的进一步保护和方向。我们的目标是清晰简洁地构建该领域最新和最先进的研究及其在现实世界技术中的应用。
1 Introduction
【本文适用范围】
- 为对应用于时间序列数据生成的 GAN 感兴趣的人设计。
- 回顾了当前最先进和新颖的时间序列 GAN 及其对现实世界问题的解决方案。
【GAN 解决的问题】
- 数据短缺通常是一个问题,GAN 可以通过生成新的、以前看不见的数据来扩充较小的数据集。
- 在某些情况下,数据可能会丢失或损坏;GAN 可以估算数据,即用代表干净数据的信息替换人类经验。在数据损坏的情况下,GAN 还能够对信号进行去噪。
- 数据保护、隐私和共享受到严格监管; GAN 可以通过生成不同的私有数据集来确保额外的数据保护层,这些数据集不包含从源到生成的数据集的链接风险。
- GAN跨多个领域生成和操作数据的能力促成了他们的成功。有一种趋势是使用 GAN 来生成时间序列和顺序数据,以及进行预测。GAN 是由生成器和判别器组成的生成模型,通常是两个神经网络 (NN) 模型。它们成功地用于音频生成、序列预测和插补。
【生成合成数据的方法】
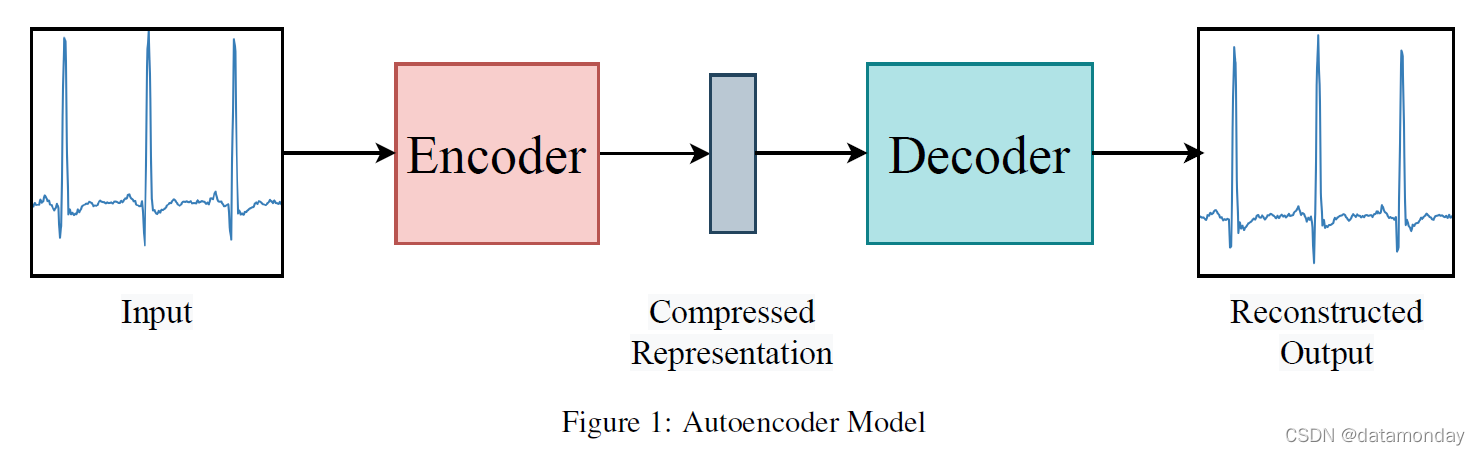
- 自动编码器 (AutoEncoder,AE),它旨在有效地学习小维度空间中输入的信息表示,并重新构建编码数据,以使重构的输入尽可能与原始输入相似。AE 模型由编码器和解码器神经网络组成,如图 1 所示。
- 然而,由于生成数据的质量和隐私保护措施,其他生成模型(例如 GAN)已经成为领先者。
【GAN面临的挑战】
- GAN 的一大挑战在于其固有的不稳定性,这使得训练变得困难。 GAN 模型存在不收敛、梯度减小/消失和模式崩溃等问题。非收敛模型不稳定并不断振荡,导致其发散。当鉴别器变得过于成功时,递减梯度会阻止生成器学习任何信息。模式崩溃是指生成器崩溃,只产生几乎没有变化的均匀样本。
- GAN 的第二个挑战在于其评估过程。借助基于图像的 GAN,研究人员已经围绕从训练数据分布估计的生成分布的评估达成了松散的共识 [2]。不幸的是,对于时间序列 GAN,由于发表的论文数量相对较少,尚未就生成数据的评估指标达成一致。已经提出了不同的方法,但目前还没有一种方法在指标领域处于领先地位。
【时间序列定义】
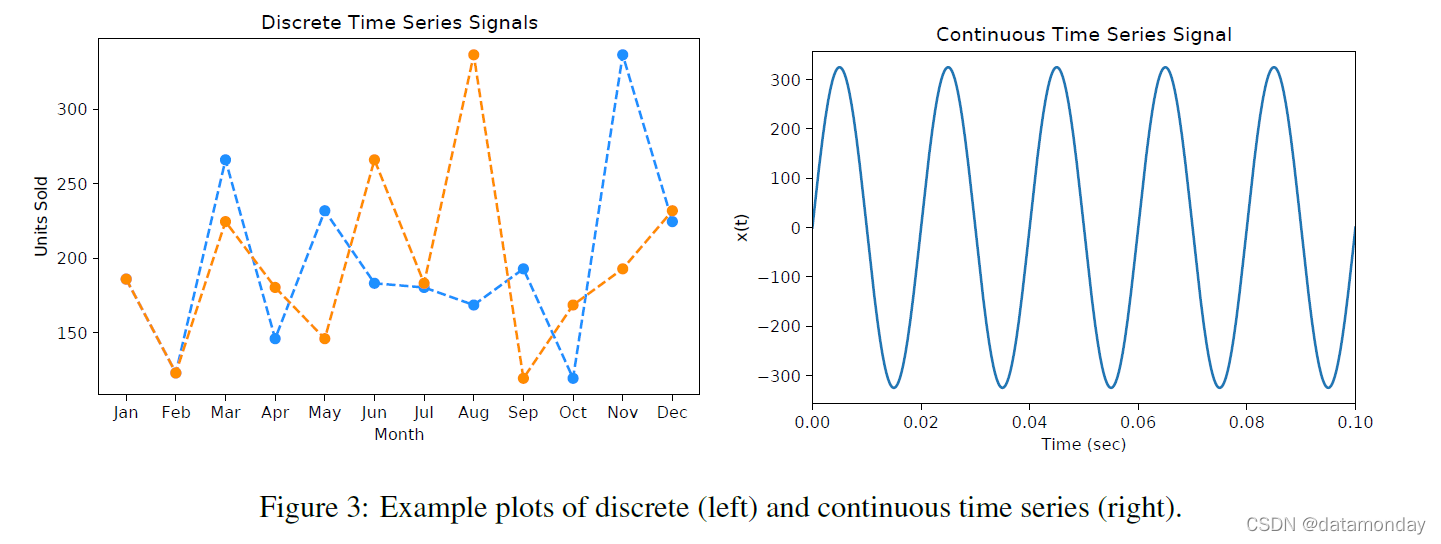
- 我们将时间序列定义为依赖于时间 (t) 的向量序列,对于连续/实时和离散时间,可以表示为 xt = x1, …, xn。时间序列的值可以定义为连续的或离散的,并且根据记录的值的数量,可以是单变量的或多变量的。在大多数情况下,时间序列将采用整数值或实数值。
- 正如 Dorffner 所说,从实际的角度来看,时间序列可以看作是在时间离散步骤中采样的值 [3]。例如,这个时间步长可以长达数年,也可以短至几毫秒。我们将连续时间序列定义为从连续过程中采样的信号,即函数的域来自不可数集。相反,离散时间序列具有可数域。
【本文主要工作】
介绍了时间序列 GAN 的第一个完整分类,即离散和连续变体、它们的应用、架构、损失函数,以及它们在生成数据的种类和质量方面如何改进。
2 Related Work
过去的综述论文中的主题集中在应用于计算机视觉领域的 GAN 变体上。据我们所知,目前还没有一篇主要关注时间序列 GAN 的综述论文。虽然这些综述提到了这些 GAN 在生成序列数据中的应用,但它们只是略微提及了诸多研究。
该工作涉及展示有关时间序列 GAN 的最新研究、它们的架构、损失函数、评估指标、权衡和数据集隐私保护的方法。
3 Generative Adversarial Networks
3.1 Background
GAN 的引入促进了合成数据生成的重大突破。GAN 的组成:
- 生成器 G :接收随机噪声 z ∈ Rr 并尝试生成类似于训练数据分布的合成数据。
- 鉴别器 D :试图确定生成的数据是真实的还是虚假的。
生成器旨在最大化判别器的错误率,而判别器旨在最小化它。图 2 显示了一个简单的 GAN 架构示例和神经网络模型所玩的游戏。这两个网络被锁定在一个由价值函数 V(G,D) (1) 定义的两人极小极大游戏中,其中 D(x) 是 x 来自真实数据而不是生成数据的概率 [1] 。
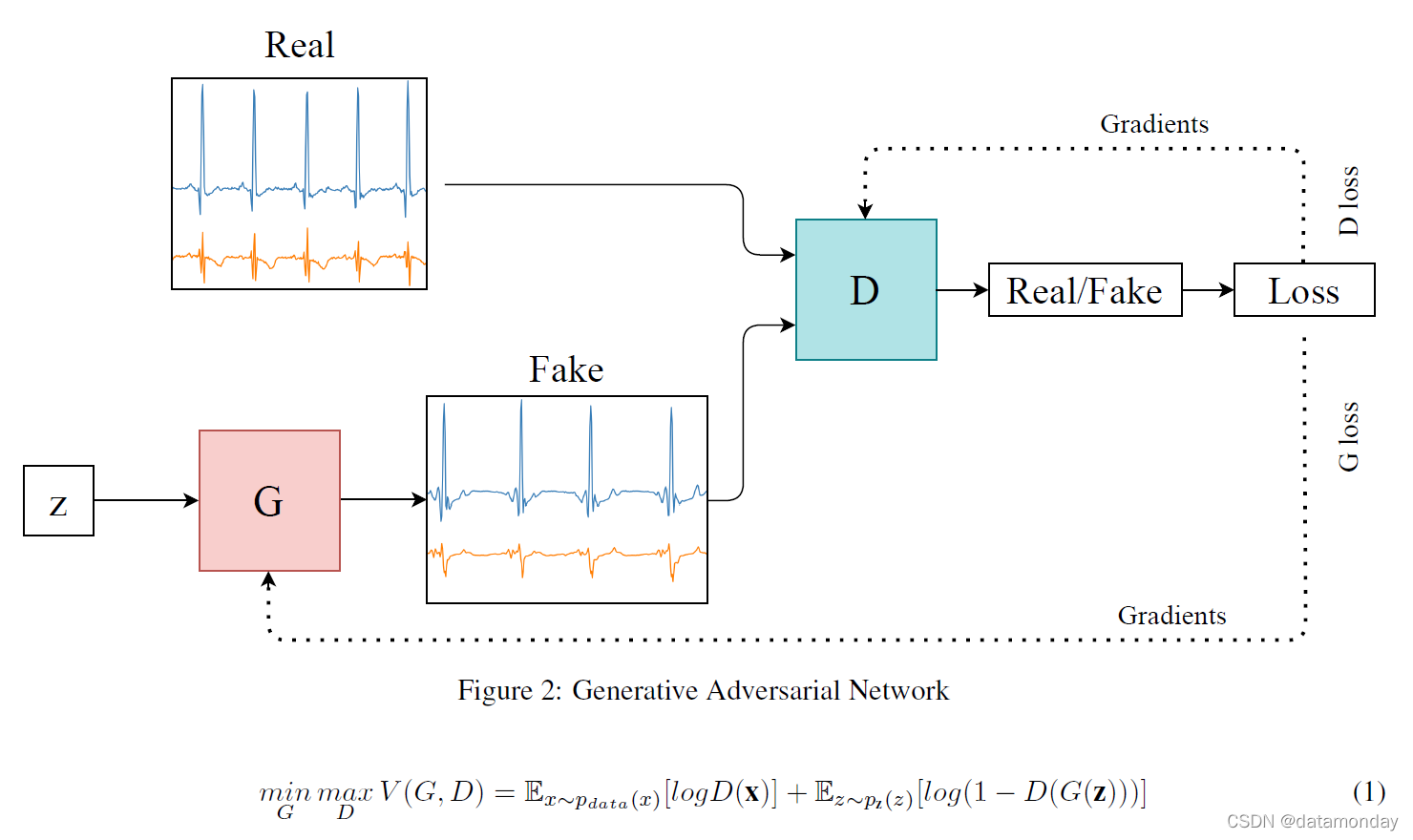
GAN 属于生成模型家族,是生成不需要领域专业知识的合成数据的替代方法。它们是 Goodfellow 在 2014 年的论文中构思出来的,其中一个多层感知器被用于判别器和生成器 [1]。2015年,Radford 等人开发了深度卷积生成对抗网络(DCGAN)来生成合成图像[10]。从那时起,研究人员不断改进早期的 GAN 架构、损失函数和评估指标,同时创新它们对实际应用的潜在贡献。
3.2 Challenges
时间序列 GAN 领域存在三个主要挑战,即与 GAN 创建的合成数据相关的训练稳定性、评估和隐私风险。我们将解释这三个挑战如下。
训练稳定性(Training stability)。
GAN 在训练期间可能出现不稳定性问题。包含两个方面:
- 梯度消失
- 模式崩溃
梯度消失是由等式 (1) 中的直接优化损失引起的。当 D 达到最优时,对 G 的方程(1)的优化可以转化为最小化 pr 和 pg 之间的 Jensen-Shannon (JS) 散度:
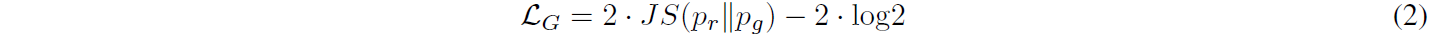
当 pr 和 pg 之间没有重叠时,JS 散度保持恒定(log2 = 0.693),这表明在这种情况下使用此损失的 G 的梯度为 0。G 的非零梯度仅在 pr 和 pg 有大量重叠时才存在。在实践中,pr 和 pg 不相交或重叠可忽略不计的可能性非常高 [11]。为了摆脱 G 的梯度消失问题,最初的 GAN 工作 [1] 强调了
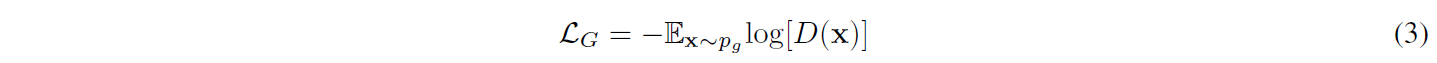
用于更新 G。该策略能够避免梯度消失问题,但会导致模式崩溃问题。优化方程(3)可以转化为优化反向Kullback-Leibler(KL)散度,即KL(pg||pr)。当pr包含多个模式时,pg在优化反向KL散度时选择恢复单个模式并忽略其他模式。考虑到这种情况,使用等式 (3) 训练的 G 可能只能从真实数据中生成少数模式。这些问题可以通过改变架构或损失函数来修正。
评估(Evaluation)。
当前在计算机视觉中对 GAN 的评估通常设计为考虑两个方面,即生成数据的质量和数量。最具代表性的定性指标是使用人工注释来确定生成图像的视觉质量。定量指标比较生成图像和真实图像之间的统计属性,即双样本测试,例如最大平均差异 (maximum mean discrepancy,MMD) [16]、初始分数 (maximum mean discrepancy) [17] 和 Fréchet 初始距离 (Fréchet Inception Distance,FID) [18]。
与评估基于图像的 GAN 相比,很难定性地评估来自人类心理感知的时间序列数据。在定性评估基于时间序列的 GAN 方面,它通常进行 t-SNE [19] 和 PCA [20] 分析,以可视化生成的分布与原始分布 [21] 的相似程度。可以通过部署类似于基于图像的 GAN 的双样本测试来对基于时间序列的 GAN 进行定量评估。
隐私风险(Privacy risk)。
除了评估 GAN 的性能外,还使用了多种方法来评估与 GAN 创建的合成数据相关的隐私风险。有研究对训练、测试和合成数据使用三样本测试来确定合成数据是否与训练数据过拟合 [22, 23]。已经表明,去识别数据(de-identifying data )的常用方法并不能阻止攻击者使用附加数据重新识别个人 [24, 25]。敏感数据通常通过删除个人身份信息 (PII) 进行去识别化。但是,正在努力创建框架,以使用 PII 的替代信息将不同的公开可用信息来源链接在一起。[25] 开发了一个软件程序 REID,将公开可用的出院数据中包含的个人与其独特的 DNA 记录联系起来。[26] 使用记录的未加密部分和来自其他来源的有关个人的已知信息,重新识别澳大利亚医疗账单记录的去识别开放数据集中的个人 。[27] 开发了一种概率方法来链接类风湿性关节炎患者的去识别 EHR 数据。在公开可用的数据集中重新识别个人可能会导致他们敏感的健康信息暴露。健康数据已被通用数据保护条例 (GDPR) 归类为特殊个人数据,并根据 2018 年数据保护法(第 36(2) 条)[28] 受到更高级别的保护。因此,相关研究人员必须找到保护敏感健康数据的替代方法,以最大程度地降低重新识别的风险。这将在第 7 节中讨论。
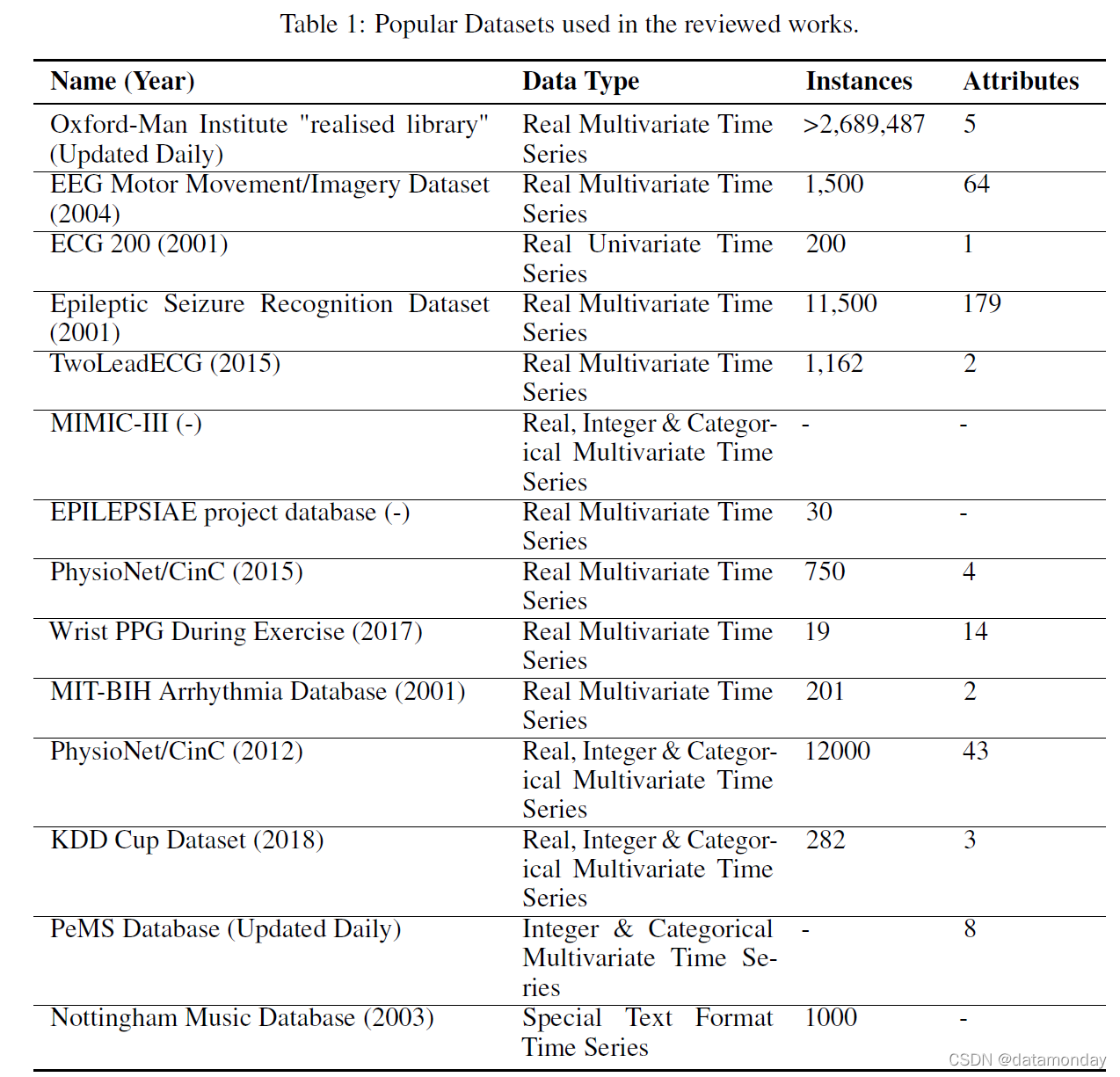
3.3 Popular Datasets
与基于图像的数据集(CIFAR、MNIST、ImageNet [29、30、31])不同,没有用于时间序列生成的标准化或常用基准数据集。但是,我们编制了一份清单,列出了一些流行的数据集,它们列在表 1 中。存在两个存储库; UCR 时间序列分类/聚类数据库 [32] 和 UCI 机器学习存储库 [33],它们提供了多个时间序列数据集。尽管如此,对于用于对时间序列 GAN 进行基准测试的标准化数据集仍然没有达成共识,这可能是由于架构维度的“连续”性质。为连续时间序列生成而设计的 GAN 通常在其输入序列的长度上有所不同,这取决于作者的偏好或对生成数据的下游任务的架构施加的限制。
4 Taxonomy of Time Series based GANs
我们基于两种不同的变体类型提出了以下基于时间序列的 GAN 的分类法:
- 离散变体(离散时间序列):离散时间序列由按时间间隔分隔的数据点组成。这种类型的数据可能具有
- 不频繁(例如,每分钟 1 个点)或不规则(例如,每当用户登录时)的数据报告间隔
- 由于报告中断而丢失值的间隙(例如,网络流量应用程序中的间歇性服务器或网络停机)。离散时间序列生成涉及生成可能具有时间依赖性但包含离散标记的序列;这些通常可以在电子健康记录和文本生成中找到。
- 连续变体(连续时间序列):一个连续的时间序列有一个对应于每个时刻的数据值。连续数据生成涉及生成具有时间依赖性的实值信号 x,其中 x ∈ R。
有关离散和连续时间序列信号的示例,请参见图 3。
离散时间序列生成的挑战:由于大量的零梯度,GAN 难以生成离散数据,即离散对象上的分布相对于其参数不可微分 [34, 35]。这种限制使生成器无法单独使用反向传播进行训练。生成器从随机采样和确定性变换开始,该变换通过鉴别器相对于 G 和训练数据集产生的输出的损失梯度来引导。这种损失会导致 G 的输出发生轻微变化,使其更接近所需的输出。对连续数字进行轻微更改是有意义的;金融时间序列数据中的值 10 加上 0.001 将使其达到 10.001。然而,像“企鹅”这个词这样的离散标记不能简单地加上 0.001,因为“企鹅+0.001”之和没有意义。这里重要的是生成器不可能从一个离散标记跳转到下一个,因为微小的变化给标记一个新值,该值不对应于有限离散空间上的任何其他标记 [36]。这是因为在这些标记之间的空间中存在 0 概率,这与连续数据不同。
连续时间序列生成的挑战:对连续时间序列数据进行建模为 GAN 提出了一个不同的问题,GAN 本质上是为连续数据建模而设计的,尽管最常见的是图像形式。
- 时间序列中连续数据的时间特性带来了额外的困难。时间特征与其属性之间存在复杂的相关性,例如,如果使用多通道生物特征/生理数据,ECG 特征将取决于个人的年龄和/或健康状况。
- 数据中存在长期相关性,其维度不一定是固定的。转换图像尺寸可能会导致图像质量下降,但这是公认的做法。对于连续时间序列数据,此操作变得更加困难,因为在时间序列 GAN 架构中没有使用标准化维度,这意味着对其性能进行基准测试变得困难。
自 2014 年问世以来,GAN 在生成与真实图像无法区分的高质量合成图像方面取得了巨大成功 [37,38,39]。虽然迄今为止的重点是开发 GAN 以改进媒体生成,但越来越多的共识是 GAN 不仅可以用于图像生成和处理,这导致了使用 GAN 生成时间序列数据的趋势。
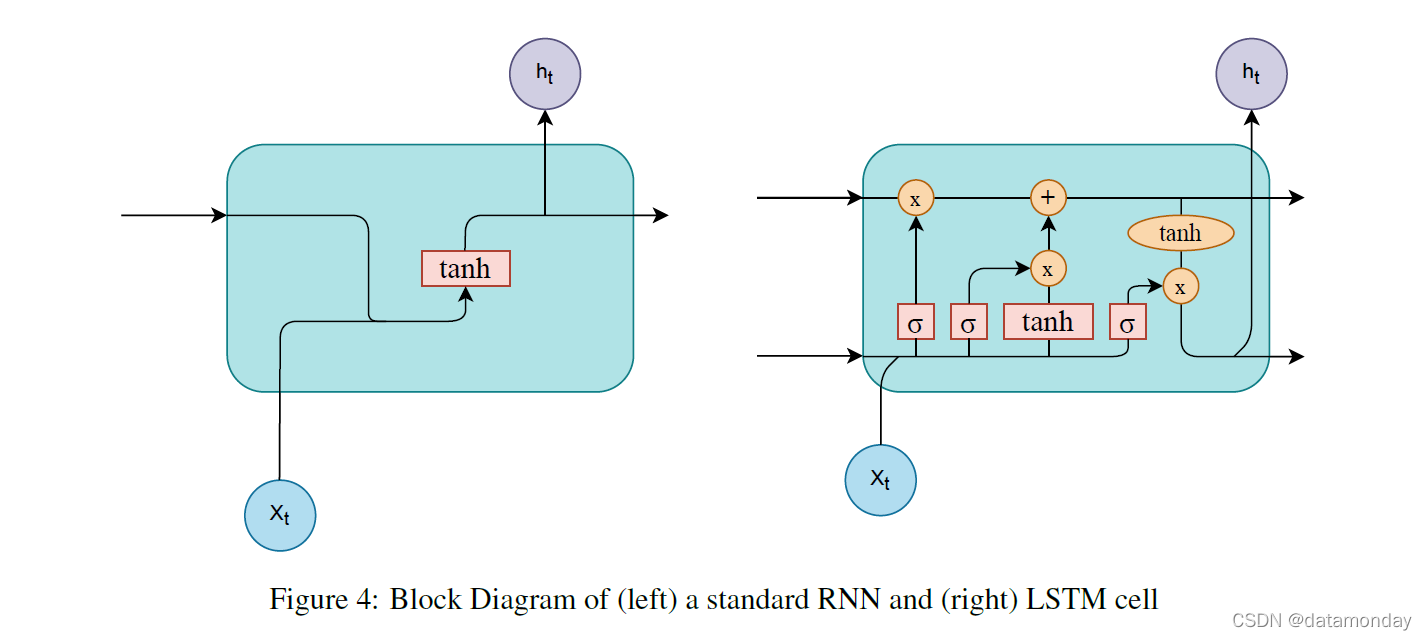
循环神经网络 (RNN)(图 4)由于其类似循环的结构,非常适合顺序数据应用程序,但其本身缺乏学习长期依赖关系的能力,而长期依赖关系可能对于根据过去预测未来值至关重要。长短期记忆网络 (LSTM)(图 4 是一种特定类型的 RNN,它能够长时间记住信息,进而学习标准 RNN 无法做到的这些长期依赖关系。在本文回顾的大多数工作中,大多数基于 RNN 的架构都使用 LSTM 单元。
RNN 可以对金融数据、医疗数据、文本和语音等序列数据进行建模,它们一直是时间序列 GAN 的基础架构。循环 GAN(RGAN)于 2016 年首次提出。生成器包含一个循环反馈循环,该循环在每个时间步同时使用输入和隐藏状态来生成最终输出 [40]。循环 GAN 通常在其生成模型中使用长短期记忆神经网络,以避免与更传统的循环网络相关的梯度消失问题 [41]。在接下来的部分中,我们按时间顺序呈现时间序列 GAN,它们要么对这一领域做出了重大贡献,要么取得了一些最新的新进展。
4.1 Discrete-variant GANs
4.1.1 Sequence GAN (SeqGAN) (Sept. 2016)
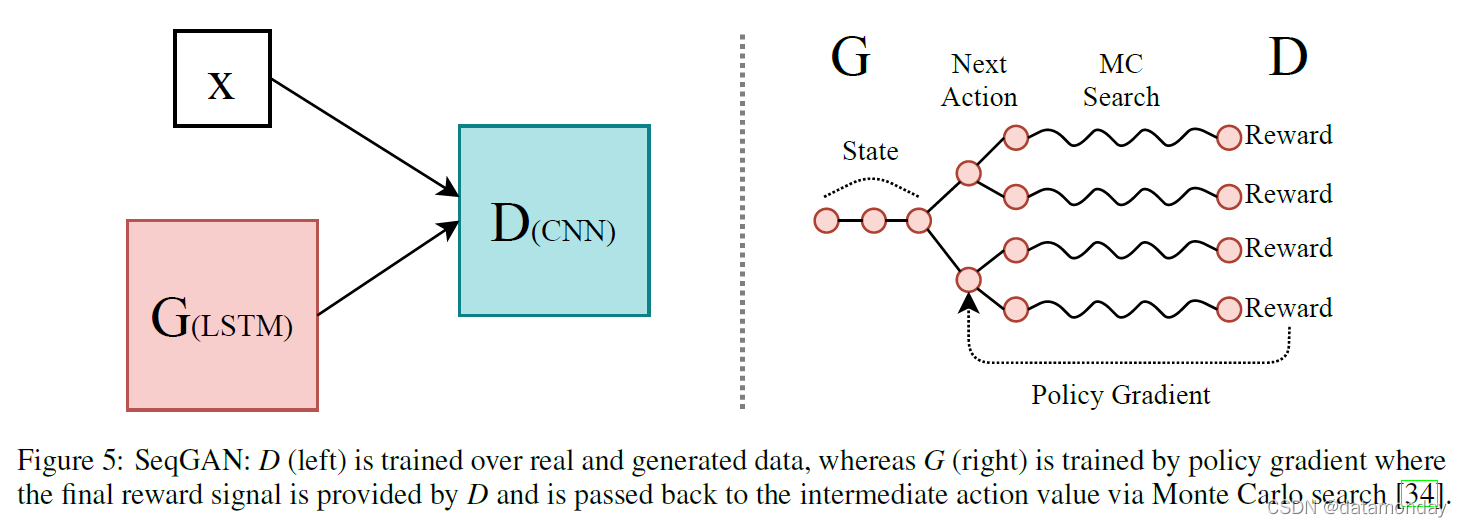
[34]提出了一个顺序数据生成框架,可以解决前面在 4 中提到的生成离散数据的问题。这种方法优于以前在现实世界任务中生成建模的方法,包括:最大似然估计 (MLE) 训练的 LSTM、计划采样 [42] 和具有双语评估替补的策略梯度 (PG-BLEU) [43]。SeqGAN 的生成模型由带有 LSTM 单元的 RNN 组成,其判别模型是卷积神经网络 (CNN)。给定结构化序列的数据集,作者训练 G 生成合成序列 Y1:T = (y1…, yt…, yT ), yt ∈ Y 其中 Y 定义为候选标记的词汇表。G 通过策略梯度和对 D 的预期奖励的蒙特卡罗 (MC) 搜索进行更新,参见图 5。作者在实验中使用了两个数据集。Chinese poem dataset [44] 和 Barack Obama Speech 数据集 [45],使用 Adam 优化器,批量大小为 64。他们的实验在 https://github.com/LantaoYu/SeqGAN/。
4.1.2 Quant GAN (Jul. 2019)
Quant GAN 是一种数据驱动模型,旨在捕捉金融时间序列数据(如波动率集群)中的长期依赖关系。生成器和鉴别器都使用带有跳跃连接的时间卷积网络(TCN)[46],它本质上是膨胀的因果卷积网络。它们的优点是适合对连续序列数据中的长期依赖关系进行建模。生成器函数是一种新颖的随机波动率神经网络 (SVNN),由波动率和漂移 TCN 组成。时间块是 TCN 中使用的模块,由两个膨胀的因果卷积层(图 6)和两个参数整流线性单元(PReLU)激活函数组成。 G 生成的数据被传递给 D 以产生输出,然后可以对其进行平均以给出 D 损失函数的 MC 估计。作者使用了从 2009 年 5 月到 2018 年 12 月的标准普尔 500 指数每日现货价格数据集。
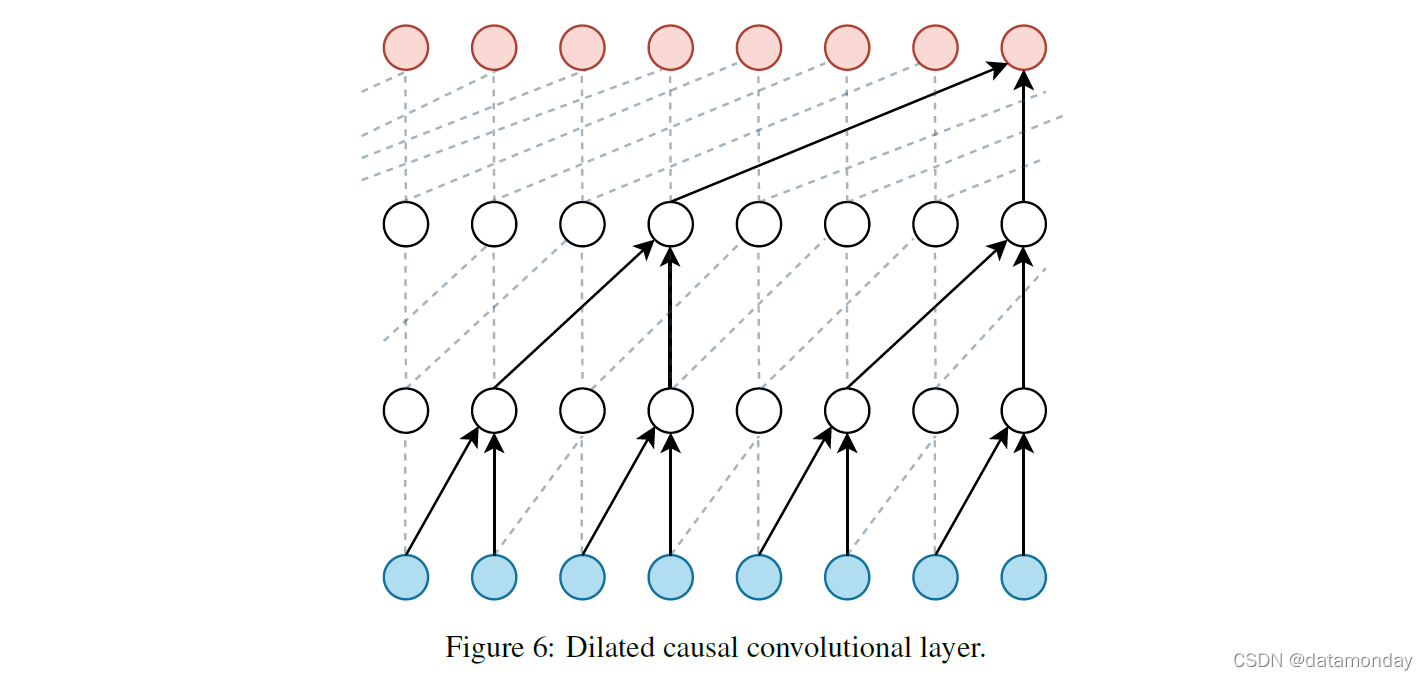
作者旨在捕捉金融时间序列中的长期依赖关系;然而,在这么长的时间范围内以连续时间对序列进行建模会破坏模型的计算复杂性。因此,该方法对离散时间的时间序列进行建模。作者报告说,这种方法能够胜过数学金融中更传统的模型(约束 SVNN 和广义自回归条件异方差性(GARCH)[47]),但指出,要使这种方法得到广泛采用,仍有一些问题需要解决。其中一个问题涉及需要一个统一的指标来量化这些 GAN 的性能,我们将在第 6 节中进一步讨论这一点。
4.2 Continuous-variant GANs
4.2.1 Continuous RNN-GAN (C-RNN-GAN) (Nov. 2016)
在以前的工作中,RNN 已被应用于建模音乐,但通常使用符号表示来建模这种类型的序列数据。 Mogren 提出了 C-RNN-GAN(图 7),这是使用 GAN 生成连续序列数据的首批示例之一[48]。生成器是一个 RNN,鉴别器是一个双向 RNN,它允许鉴别器在两个方向上获取序列上下文。这项工作中使用的 RNN 是两个堆叠的 LSTM 层,每个单元包含 350 个隐藏单元。损失函数可以在 (4,5) 中看到,其中 z(i) 是 [0,1]k 中的均匀随机向量序列,x(i) 是来自训练数据的序列,k 是随机序列中数据的维数。
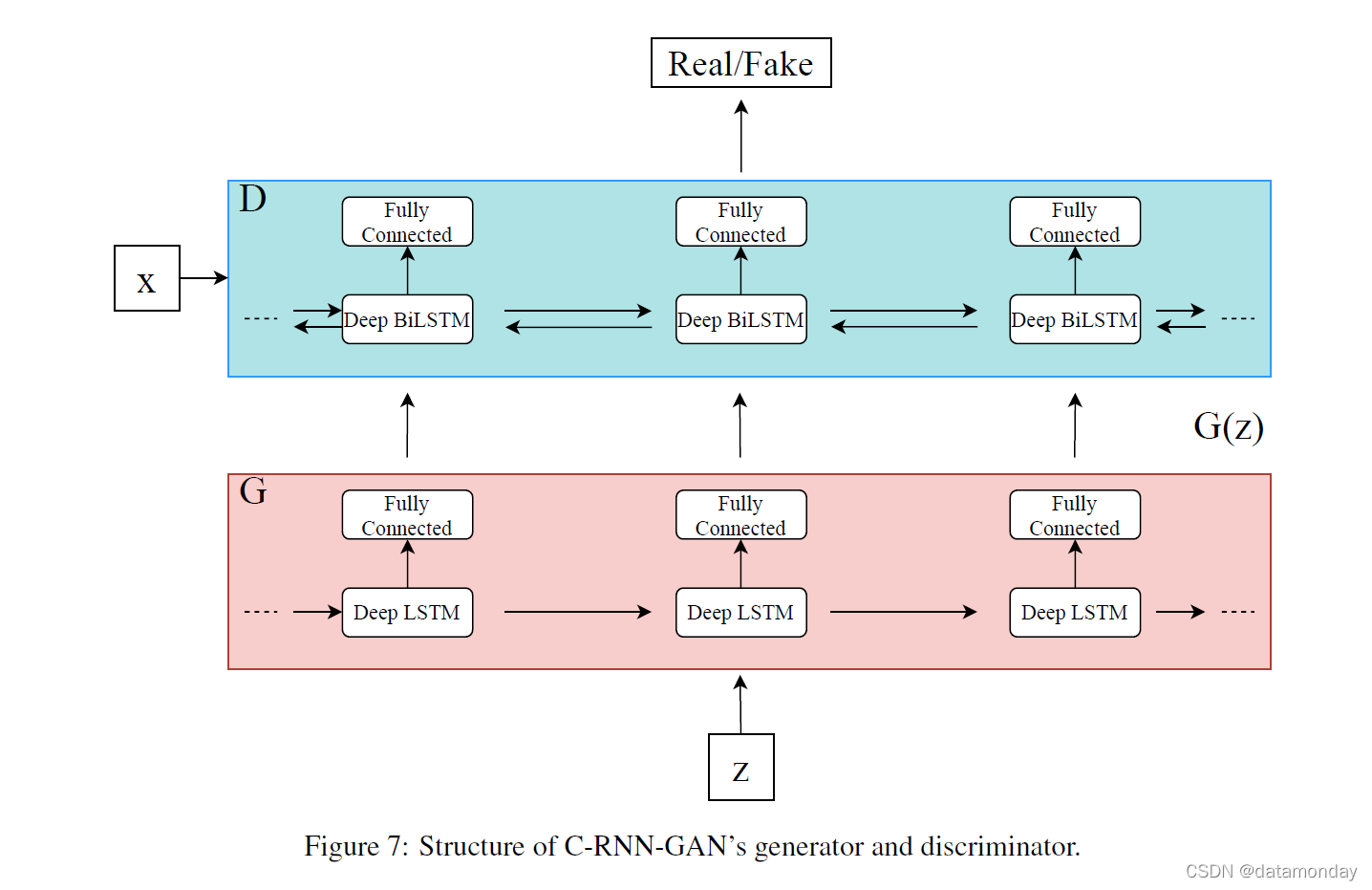
C-RNN-GAN 通过时间反向传播 (BPTT) 和小批量随机梯度下降进行训练,并在 G 和 D 的权重上使用 L2 正则化。当一个网络相对于另一个。使用的数据集是来自 160 个不同的古典音乐作曲家的 3697 个 midi 文件,批量大小为 20。训练期间使用了 Adam 和 Gradient Descent Optimisers;完整的实施细节可在 https://github.com/olofmogren/c-rnn-gan/ 获取。总体而言,C-RNN-GAN 能够学习连续序列数据的特征,进而生成音乐。然而,作者表示,他们的方法仍然需要改进,特别是在对生成的数据质量进行严格评估方面。
4.2.2 Recurrent Conditional GAN (RCGAN) (2017)
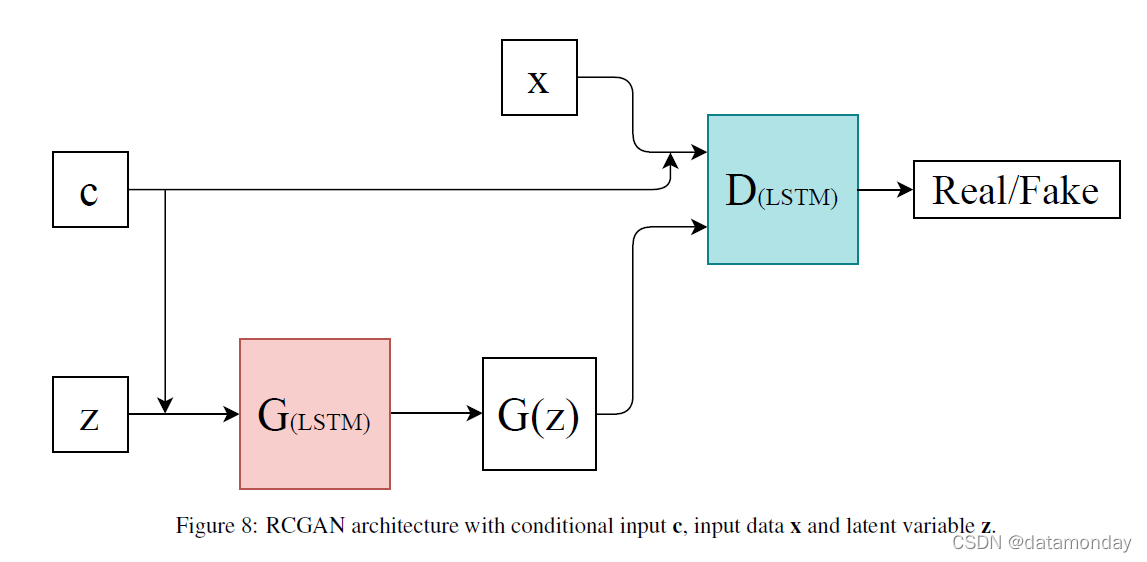
用于连续数据生成的 RCGAN [23] 在架构上与 C-RNN-GAN 不同。虽然使用了 RNN LSTM,但判别器是单向的,G 的输出在下一个时间步不会作为输入反馈。该模型还以其他信息为条件,这构成了条件 RGAN;请参阅图 8 中的模型布局。RCGAN 和 RGAN 在这项工作中的目的是生成连续的时间序列,重点是用于下游任务的医疗数据,这是该领域的首批工作之一。损失函数可以在等式 (6, 7) 中看到,其中 CE 是两个序列之间的平均交叉熵。 Xn 是从训练数据集中抽取的样本。yn 是对抗性样本真实标签,对于真实序列,它是一个 1 的向量,对于生成或合成的序列,它是一个 0 的向量。 Zn 是从潜在空间中采样的一系列点,有效的对抗性样本真实标签在这里写为 1。
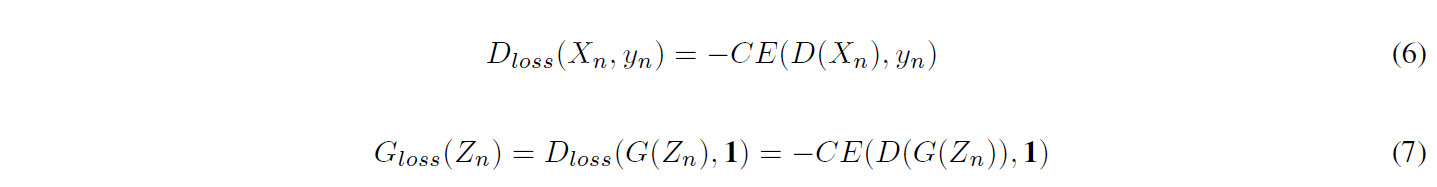
在条件情况下,D 和 G 的输入与一些条件信息 cn 连接。RNN-GAN 的这种变体有助于生成具有相关标签的合成连续时间序列数据集。对生成的正弦波、从具有零值均值函数的高斯过程采样的平滑函数、作为序列的 MNIST 数据集和飞利浦 eICU 数据库 [49] 进行了实验。
使用 Adam 和 Gradient Descent Optimisers 的批量大小为 28 进行训练。作者提出了一种评估其模型的新方法,将在第 6 节中进一步讨论。完整的实验细节可以在 https://github.com/ratschlab/RGAN/ 找到。
4.2.3 Sequentially Coupled GAN (SC-GAN) (Apr . 2019)
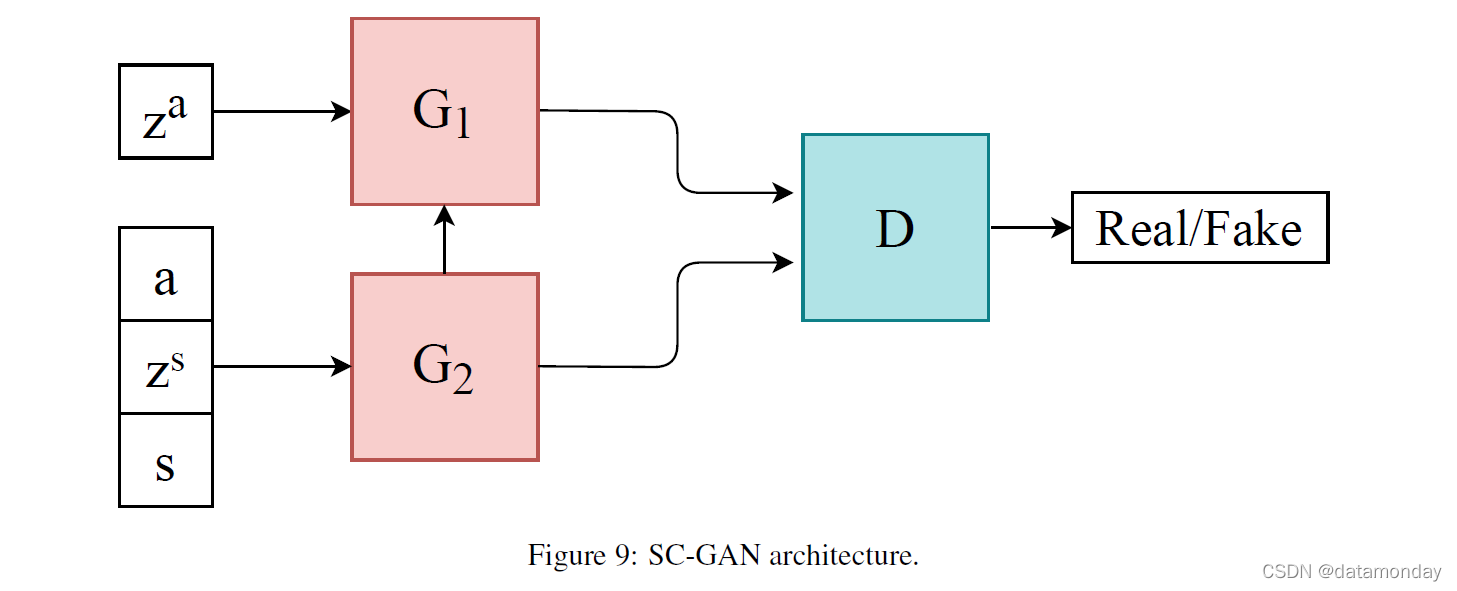
SC-GAN 旨在生成以患者为中心的医疗数据,以告知患者的当前状态,并根据状态生成推荐的药物剂量 [50]。它由两个耦合的生成器组成,它们的任务是产生两种结果,一个用于个人的当前状态,另一个用于根据个人的状态推荐的药物剂量。鉴别器是两层双向 LSTM,耦合生成器都是两层单向 LSTM。有关架构的更多详细信息,请参见图 9。
G1 生成推荐的药物剂量数据 (a1, a2, …, aT ),组合输入连续的患者状态数据 (s0, s1, …, sT -1) 和随机噪声序列 (^za 0 , ^za 1, …, ^za T -1) 从均匀分布中采样。在每个时间步 t,G1 的输入 zat 是 st 和 ^za t 的串联(concatenation)。
相反,G2 的任务是生成患者状态数据 s_t,并且在每个时间步,输入 zst 是 st-1、at-1 和 ^zs t 的串联。这意味着 G1 和 G2 的输出是彼此的输入。将生成器组合在一起会导致以下损失函数:

其中 N 是患者数量,T 是患者记录的时间长度。 SC-GAN 对生成器有一个监督的预训练步骤,以避免使用最小二乘损失的过强的 D。
鉴别器的任务是将连续的以患者为中心的记录分类为真实的或合成的,损失函数定义为:
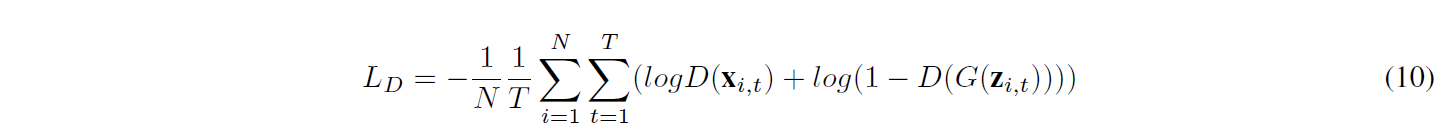
其中 xi,t = [st;at]。该模型包含新的耦合生成器,可协调生成患者状态和药物剂量数据。对于治疗推荐任务,它的性能接近真实数据。本实验中使用的数据集是 MIMIC-III [51]。作者将他们的 SC-GAN 与 SeqGAN、C-RNN-GAN 和 RCGAN 的变体进行了基准测试,并观察到他们的模型在这个特定用例中表现最好。
4.3 Noise Reduction GAN (NR-GAN) (Oct. 2019)
NR-GAN 设计用于降低连续时间序列信号的噪声,但更具体地用于降低小鼠脑电图 (EEG) 信号的噪声 [52]。该数据集由国际综合睡眠医学研究所 (IIIS) 提供。 EEG 是大脑电活动的量度,它通常包含显着的噪声伪影。 NR-GAN 的核心思想是减少或消除脑电信号频域表示中存在的噪声。 G 的架构是一个两层的 1-D CNN,在输出端有一个全连接层。 D 包含几乎相同的两层 1-D CNN 结构,其中全连接层被 softmax 层取代,以计算输入属于训练集的概率。损失函数在 (11,12) 中定义为:
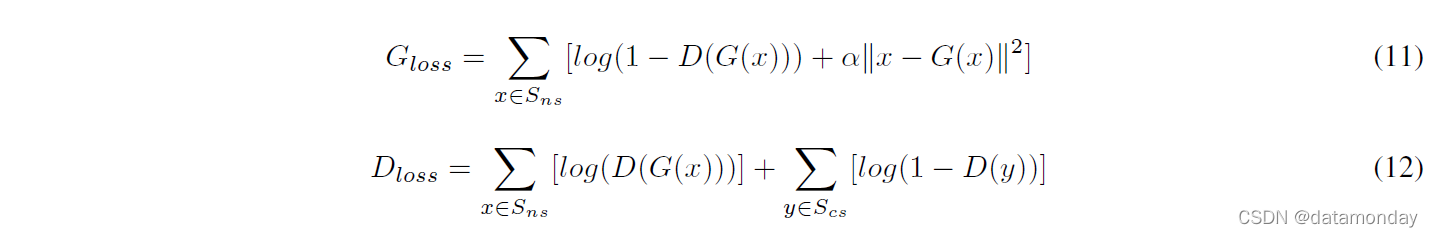
其中,Sns 和 Scs 分别是嘈杂和清晰的 EEG 信号。 α是一个超参数,本质上控制降噪的积极性;作者选择了 α = 0.0001 的值。
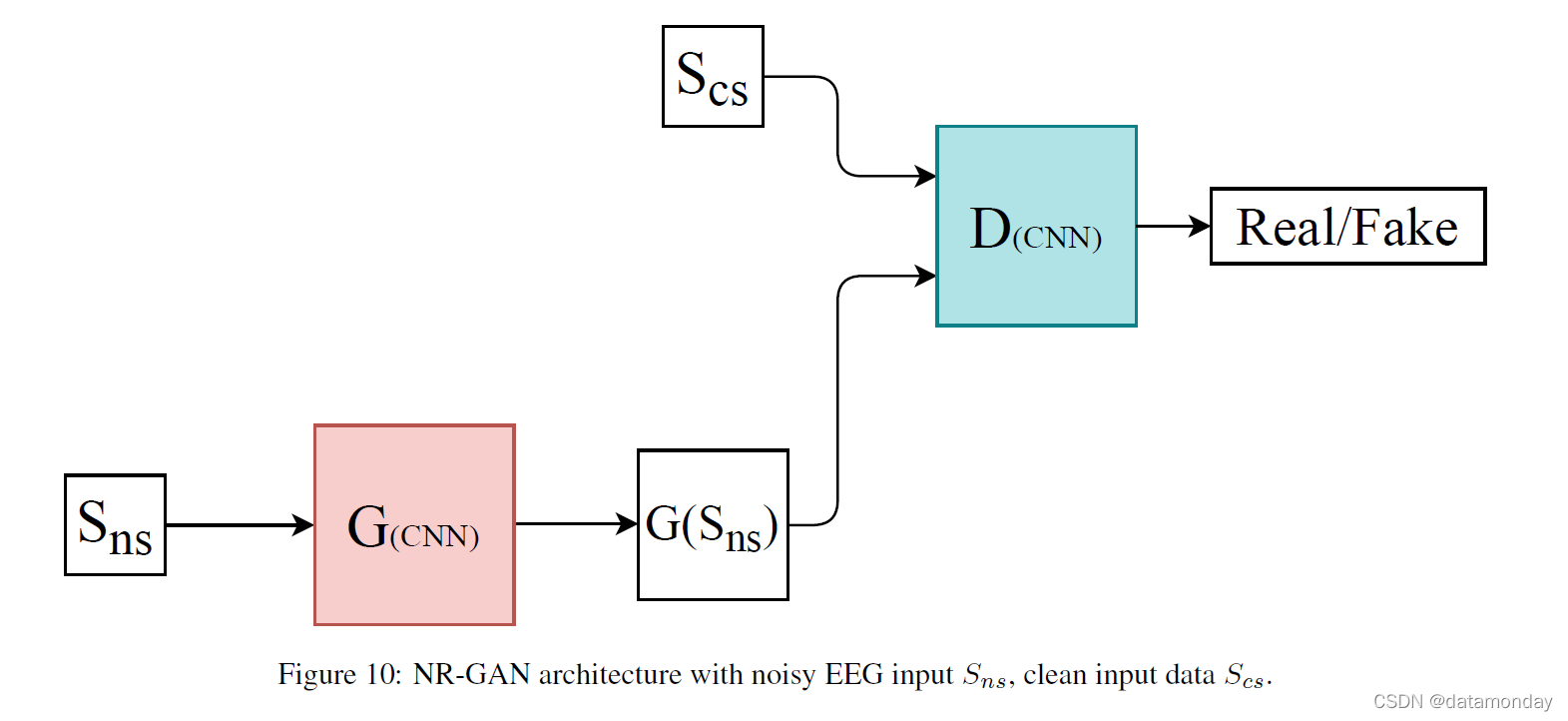
对于这项工作,生成器不会从潜在空间中采样;相反,它试图从嘈杂的 EEG 信号输入中生成清晰的信号,见图 10。作者发现 NR-GAN 在降噪方面与经典频率滤波器具有竞争力。他们还指出,实验条件可能有利于 NR-GAN,并在 NR-GAN 可以处理的噪声量和 α 的影响方面列出了一些限制。然而,这是一种使用 GAN 对连续序列数据进行降噪的新方法。
4.3.1 Time GAN (Dec. 2019)
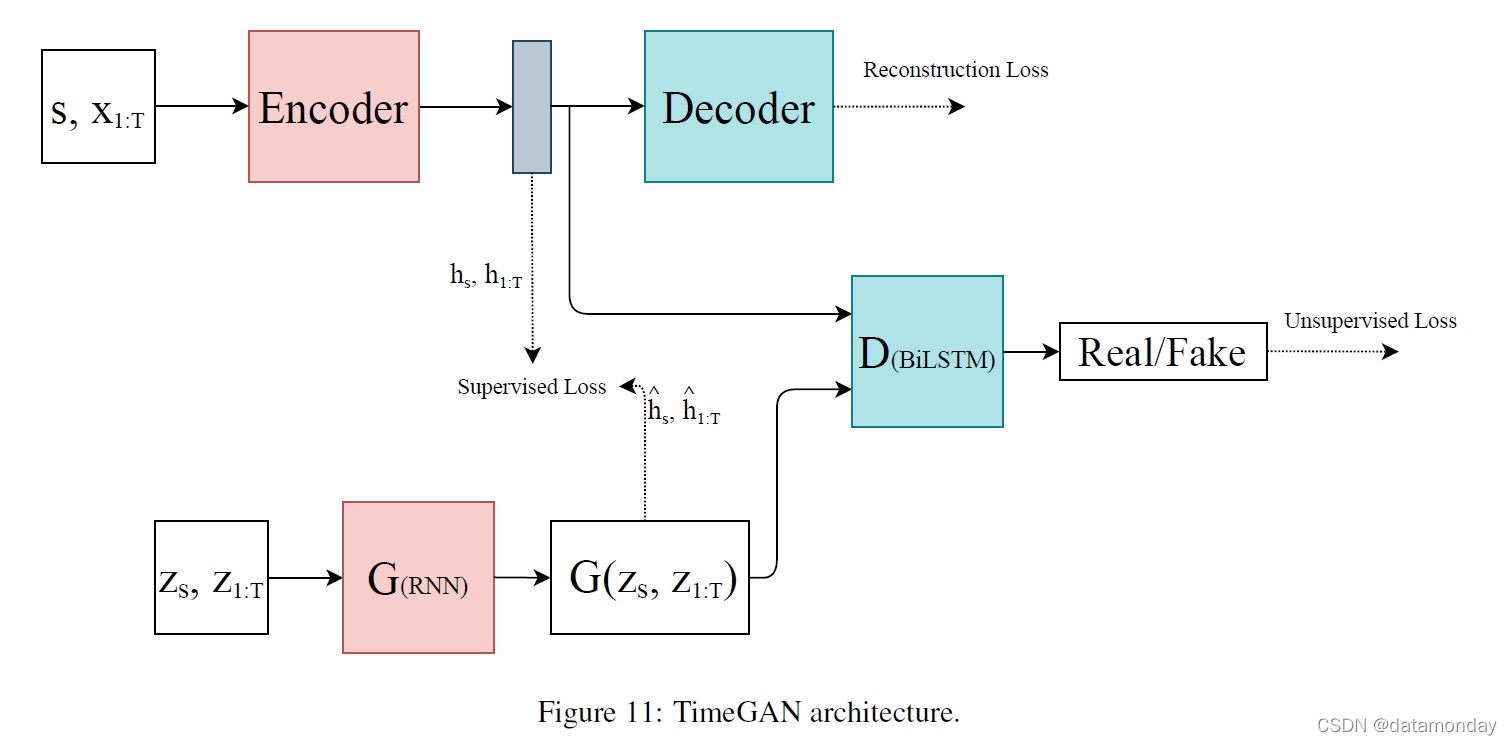
TimeGAN 提供了一个框架,该框架利用了传统的无监督 GAN 训练方法和更可控的监督学习方法 [21]。通过将无监督 GAN 网络与有监督自回归模型相结合,该网络旨在生成具有保留时间动态的时间序列。 TimeGAN 框架的架构如图 11 所示。框架的输入被认为由两个元素组成,一个静态特征和一个时间特征。s 表示编码器输入端的静态特征向量,x 表示时间特征向量。生成器采用从已知分布中提取的静态和时间随机特征向量的元组。真实和合成的潜在编码 h 和 ^h 用于计算该网络的监督损失。鉴别器接收真实和合成潜在编码的元组并将它们分类为真实(y)或合成(y),〜操作符将样本表示为真实或虚假。
TimeGAN 中使用的三个损失计算如下:
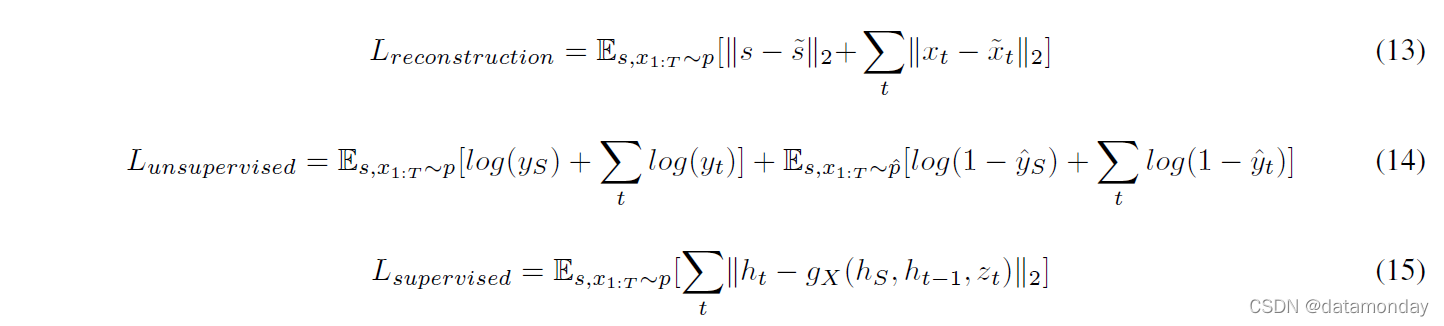
TimeGAN 的创建者对生成正弦波、股票(2004 年至 2019 年的每日历史谷歌股票数据)、能源(UCI Appliances 能源预测数据集)[33] 和事件(私人肺癌通路数据集)数据集进行了实验。批量大小为 128 和 Adam 优化器用于训练,实现细节可在https://github.com/jsyoon0823/TimeGAN获得。作者展示了对其他最先进的时间序列 GAN 的改进,例如 RCGAN C-RNN-GAN 和 WaveGAN。
4.3.2 Conditional Sig-Wasserstein GAN (SigCWGAN) (Jun. 2020)
[53] 解决的一个问题是,长时间序列数据流会大大增加生成建模的维度要求,这可能会使这种方法不可行。为了解决这个问题,作者开发了一个名为 Signature Wasserstein-1 (Sig-W1) 的度量,它捕获时间序列模型的时间依赖性并将其用作时间序列 GAN 中的判别器。它提供了对复杂数据流的抽象和通用描述,并且不需要像 Wasserstein 度量那样的昂贵计算。还提出了一种新的生成器,称为条件自回归前馈神经网络 (AR-FNN),它捕获时间序列的自回归性质。生成器能够将过去的序列和噪声映射到未来的序列中。对于他们的方法的严格的数学描述,感兴趣的读者应该参考[53]。
对于 AR-FNN 生成器,想法是获得 step-q 估计器 ^X(t) t+1:t+q。 D 的损失函数定义为:
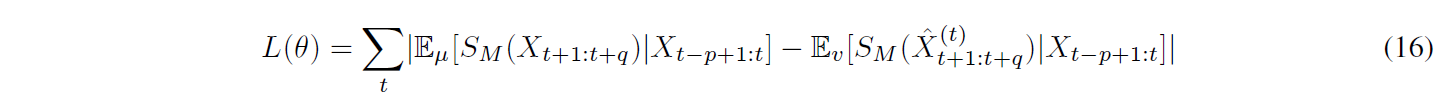
其中 v 和 µ 分别是由真实数据和合成生成器诱导的条件分布,作者算法的更多细节可以在原论文的附录中找到。作者指出,SigCWGAN 消除了逼近代价高昂的 D 的问题并简化了训练。与 TimeGAN、RCGAN 和生成矩匹配网络 (GMMN) [54] 相比,它在合成和经验数据集上实现了最先进的结果。经验数据集包括标准普尔 500 指数 (SPX) 和道琼斯指数 (DJI) 及其已实现的波动率,这些波动率是从牛津曼研究所的“已实现库”[55] 中检索到的。使用 Adam 优化器,批量大小为 200 训练。代码:https://github.com/SigCGANs/Conditional-Sig-Wasserstein-GANs/。
4.4 Synthetic biomedical Signals GAN (SynSigGAN) (Dec. 2020)
SynSigGAN 旨在生成不同类型的连续生理/生物医学信号数据 [57]。它能够从 MIT-BIH 心律失常数据库 [58]、Siena Scalp EEG 数据库 [59] 和 BIDMC PPG 和呼吸数据集 [60] 中生成心电图 (ECG)、脑电图 (EEG)、肌电图 (EMG) 和光电容积描记图 (PPG) ]。这里提出了一种新颖的 GAN 架构,它使用双向网格长短期记忆 (BiGridLSTM) 作为生成器(图 12)和 CNN 作为鉴别器。 BiGridLSTM 是双 GridLSTM(可以在多维网格中表示 LSTM 的 LSTM 版本)与两个方向的组合,可以从二维对抗梯度现象,并且发现在时间序列问题中效果很好。作者使用了先前在等式 (1) 中定义的价值函数。
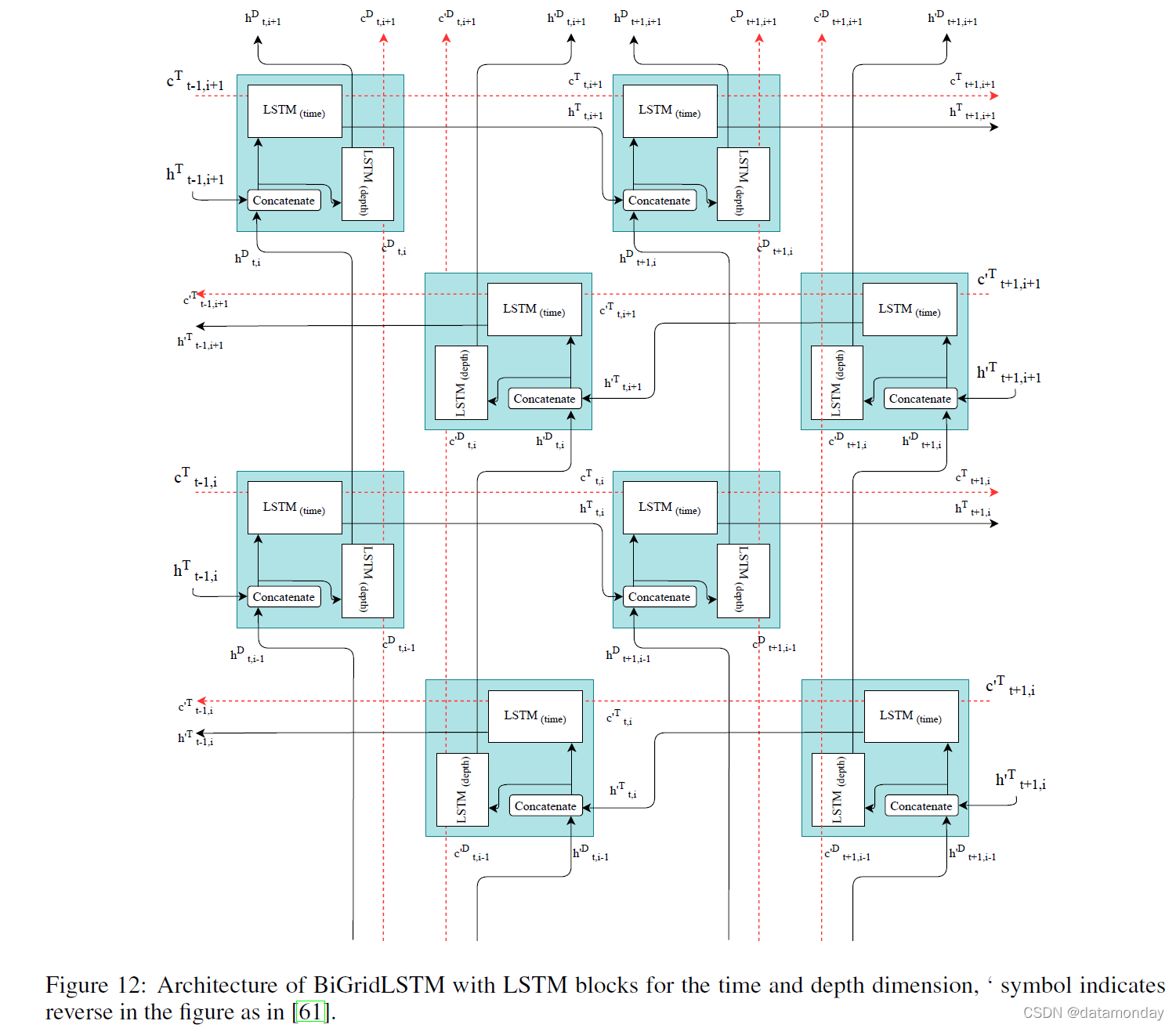
SynSigGAN 能够捕获与这些信号类型中的每一种相关的不同生理特征,并已证明能够生成最大序列长度为 191 个数据点的生物医学时间序列数据。作者还提出了一个预处理阶段来清理和改进本文中的生物医学信号。他们将自己的架构与几个变体(BiLSTM-GRU、BiLSTM-CNN GAN、RNN-AE GAN、Bi-RNN、LSTM-AE、BiLSTM-MLP、LSTM-VAE GAN 和 RNN-VAE GAN)进行比较,发现BiGrid-LSTM 是性能最好的模型。
5 Applications
5.1 Data Augmentation
在讨论数据增强时,GAN 是首选方法之一,这是深度学习社区的常识。增加数据集的原因包括增加小型和不平衡数据集的大小/种类 [62、63、64、65] 到复制受限数据集以进行传播。
数据短缺问题的一个明确的解决方案是迁移学习,它在领域适应(domain adaptation)方面效果很好,这导致了分类和识别问题的进步[66]。然而,已经发现使用 GAN 增强数据集可以进一步改进某些分类和识别任务 [67]。 GAN 合成的数据可以遵守第 7 节中讨论的更严格的隐私措施。这进一步证明了使用 GAN 增强训练数据集优于使用来自不同领域的预训练模型在较小数据集上实现迁移学习的优势。
许多研究人员发现,为他们的深度学习研究和模型访问数据集是一项耗时、费力的工作,尤其是在研究涉及个人敏感数据时。医学和临床数据通常以连续的顺序数据的形式呈现,只有一小部分研究人员才能访问,这些研究人员不能自由地公开传播他们的研究。反过来,这可能导致这些领域的研究进展停滞不前。
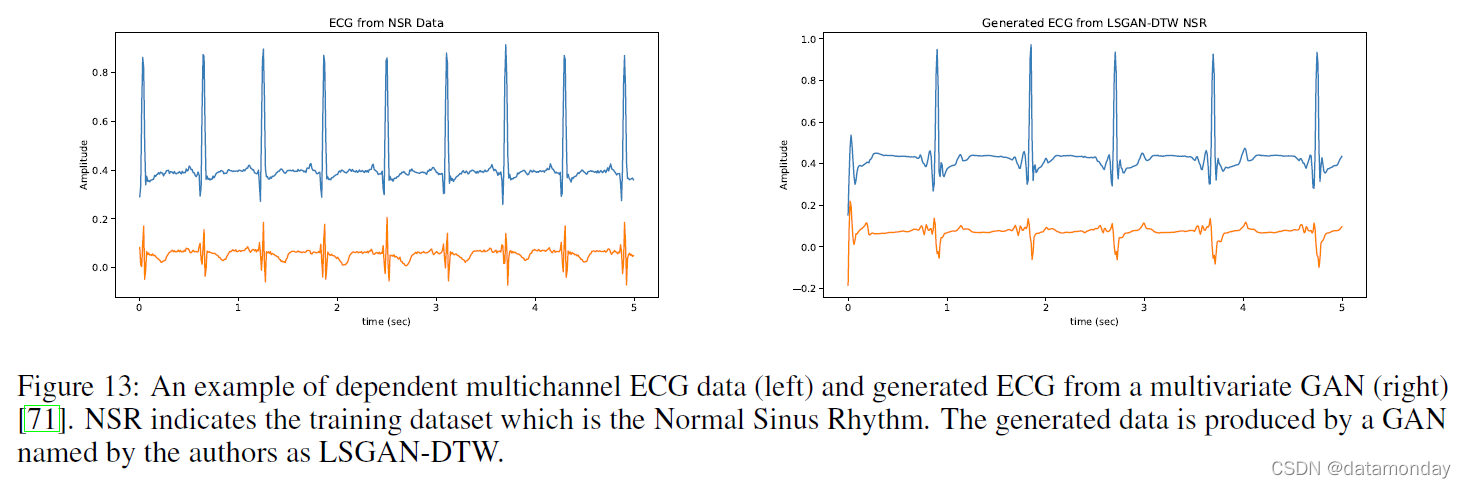
幸运的是,我们开始看到将 GAN 应用于具有这些类型的医学和生理数据的时间序列 [23, 57, 68, 69, 70]。 [71] 显示依赖多元连续高保真生理信号生成可以通过 GAN 进行,证明了这些网络令人印象深刻的能力。有关真实输入和合成生成数据的示例,请参见图 13。
当然,这并不是对使用时间序列 GAN 进行数据合成和增强的研究的全面覆盖。 GAN 已应用于大量用例的时间序列数据。
音频生成(音乐和语音)和文本转语音(TTS)[72]一直是研究人员使用 GAN 探索的热门领域。第 4.2.1 节中描述的 C-RNN-GAN 是将 GAN 应用于以音乐形式生成连续序列数据的开创性工作之一。
在金融领域,GAN 已被用于生成数据和预测/预测值。[46]实现了一个GAN来近似离散时间的金融时间序列。在 [53] 中,作者设计了一种决策感知 GAN,它生成合成数据并支持最终用户的金融投资组合选择的决策过程。
其他时间序列生成/预测方法的范围从估计土壤温度 [73] 到根据患者的当前状态预测药物支出 [74]。
5.2 Imputation
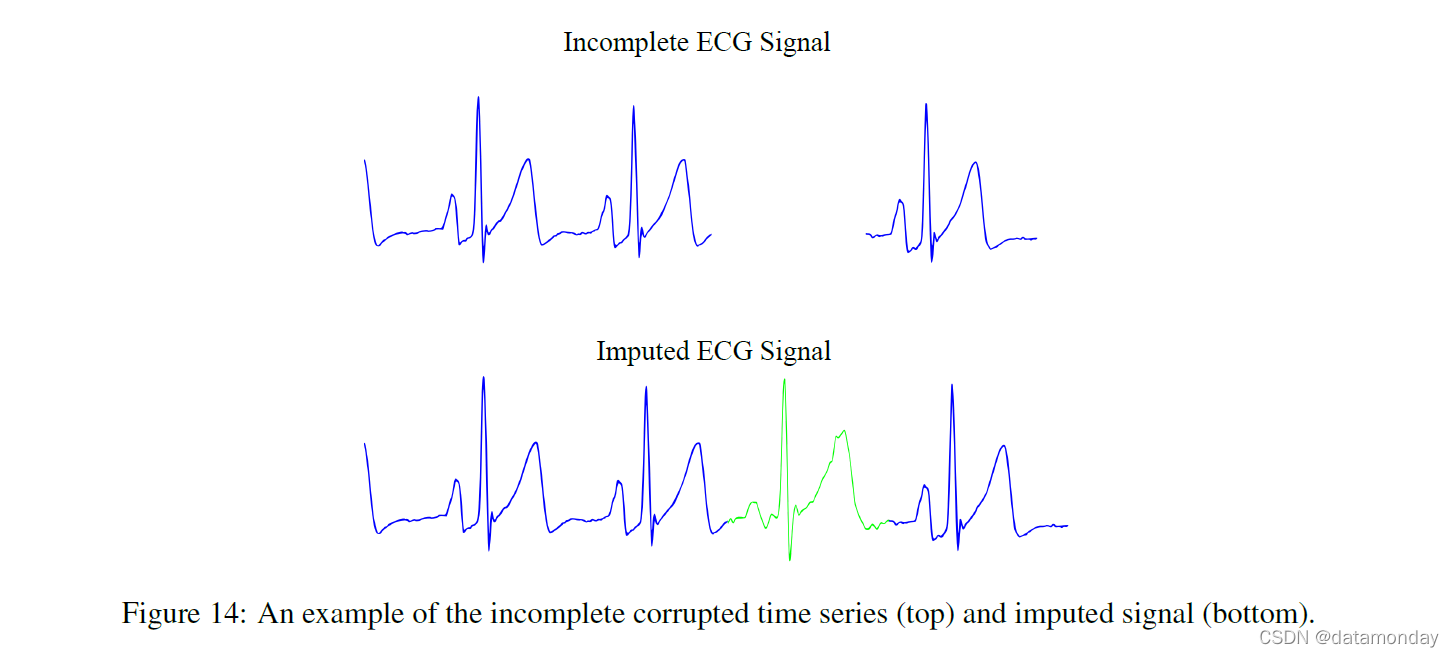
在现实世界的数据集中,丢失或损坏的数据是一个非常常见的问题,会导致下游问题。这些问题体现在对数据集的进一步分析中,并可能导致数据出现偏差。过去处理丢失或损坏数据的常用方法是删除包含丢失段的数据流、数据的统计建模或机器学习插补方法。着眼于后者,我们回顾了使用 GAN 估算这些数据的工作。[75]设计了一种基于 GAN 的多元时间序列插补方法,参见图 14 中来自玩具实验的插补数据示例 [70]。
5.3 Denoising
时间序列数据中引起的伪影(Artefacts)通常表现为信号中的噪声。这已成为进一步处理和分析应用中一直存在的挑战。损坏的数据可能会导致数据集中出现偏差或导致关键系统(例如用于健康应用程序的系统)的性能下降。处理噪声的常用方法包括使用自适应线性滤波。最近在 [52] 中探索的另一种方法使用 GAN 作为 EEG 数据中的降噪技术。他们的实验表明,与更传统的频率滤波器相比,他们提出的 NR-GAN(第 4.3 节)具有具有竞争力的降噪性能。
5.4 Anomaly Detection
检测时间序列数据中的异常值或异常是许多现实世界系统和部门的重要组成部分。无论是检测生理数据中的异常模式(可能是某些更恶意情况的前兆),还是检测证券交易所的不规则交易模式,异常检测对于让我们了解重要信息都至关重要。非平稳时间序列信号的统计测量可能在表面上取得良好的性能,但它们也可能会遗漏一些存在于更深特征中的重要异常值。他们也可能难以利用大型未标记数据集;这就是无监督深度学习方法可以胜过传统方法的地方。Zhu等人设计了一种 GAN 算法,用于使用 LSTM 和 GAN 在时间序列数据(ECG 和出租车数据集)中进行异常检测,与传统的更浅的方法相比,该算法实现了卓越的性能。类似的方法已被应用于检测心血管疾病 [76],在网络物理系统中检测恶意参与者 [77] 甚至不规则行为,例如股票市场上的股票操纵 [78]。
5.5 Other Applications
一些作品利用基于图像的 GAN 来生成时间序列和序列数据,首先通过一些转换函数将它们的序列转换为图像,然后在这些图像上训练 GAN。一旦 GAN 收敛,就可以生成相似的图像;然后,可以使用原始变换函数的逆函数来检索序列。例如,这种方法已在波形音频生成 [79、80、81]、异常检测 [82] 和生理时间序列生成 [70] 中实现。
6 Evaluation Metrics
如第 3 节所述,GAN 可能难以评估,研究人员尚未就哪些指标最能反映 GAN 的性能达成一致。文献 [2] 中提出了很多指标,其中大多数都适用于计算机视觉领域。适当评估时间序列 GAN 的工作仍在进行中。我们可以将评估指标分为两类:定性和定量。
- 定性评估:通过检查 GAN 生成的样本进行人类视觉评估的另一个术语。然而,由于缺乏合适的客观评估指标,这不能被视为对 GAN 性能的全面评估。
- 定量评估:包括使用与用于时间序列分析和相似性度量的统计度量相关的度量,例如: Pearson 相关系数 (PCC)、均方根差百分比 (PRD)、(Root) 均方误差 MSE 和 RMSE、平均相对误差 (MRE) 和平均绝对误差 (MAE)。这些指标是最常用于时间序列评估的指标之一,因此可用作合适的 GAN 性能指标,因为它们可以反映训练数据和合成生成数据之间的稳定性。
在评估基于图像的 GAN 时,一些指标已经成为公认的选择,其中一些已经渗透到顺序和时间序列 GAN,例如
- Inception Score (IS) [17]
- Fréchet (Inception) Distance (FD 和 FID) [18]
- 结构相似性指数 (Structural Similarity Index,SSIM) 是衡量两幅图像之间相似性的指标。然而,[83] 将其与时间序列数据一起使用,因为 SSIM 不会将自己排除在比较固定长度的对齐序列之外。
- 当然,其中一些指标是衡量两个概率分布之间相似性/差异性的指标,适用于多种类型的数据,特别是最大平均差异 (maximum mean discrepancy,MMD) [84] 非常适合跨领域的这项任务。
- 另一个可以很好地推广到顺序数据案例的度量标准是通过计算两个分布的所有 1d 投影之间的 Wasserstein 距离来近似 Wasserstein 距离的 Sliced-Wasserstein 距离。
GAN 生成的数据已用于下游分类任务。将生成的数据与训练数据一起使用导致了 [23] 首次提出的综合训练(Train on Synthetic)、真实测试 (Test on Real ,TSTR) 和真实训练、综合测试 (Test on Synthetic,TRTS) 评估方法。在对使用真实数据和生成数据的下游分类应用程序进行评分时,研究采用精度、召回率和 F1 分数来确定分类器的质量,进而确定生成数据的质量。分类器性能的其他准确度度量包括加权准确率(WA)和未加权平均召回率(UAR)。
时间序列数据中常用的距离和相似性度量是欧几里得距离 (ED) 和动态时间规整 (DTW) 算法。在 [71] 中实现的多变量(非)相关 DTW(MVDTW)可以确定相关和独立多通道时间序列信号之间的相似性度量。
跨不同应用程序使用的其他指标包括:
- 金融业(Financial Sector):自相关函数 (autocorrelation function,ACF) 得分,DY 度量。
- 温度估计(Temperature Estimation):Nash-Sutcliffe 模型效率系数 (NS)、Willmott 协议指数 (WI) 和 Legates 和 McCabe 指数 (LMI)。
- 音频生成(Audio Generation):归一化源失真比 (Normalised Source-to-Distortion Ratio,NSDR)、源干扰比 (Source-to Interference Ratio,SIR)、源伪像比 (Source-to Interference Ratio,SAR) 和 t-SNE [19]。
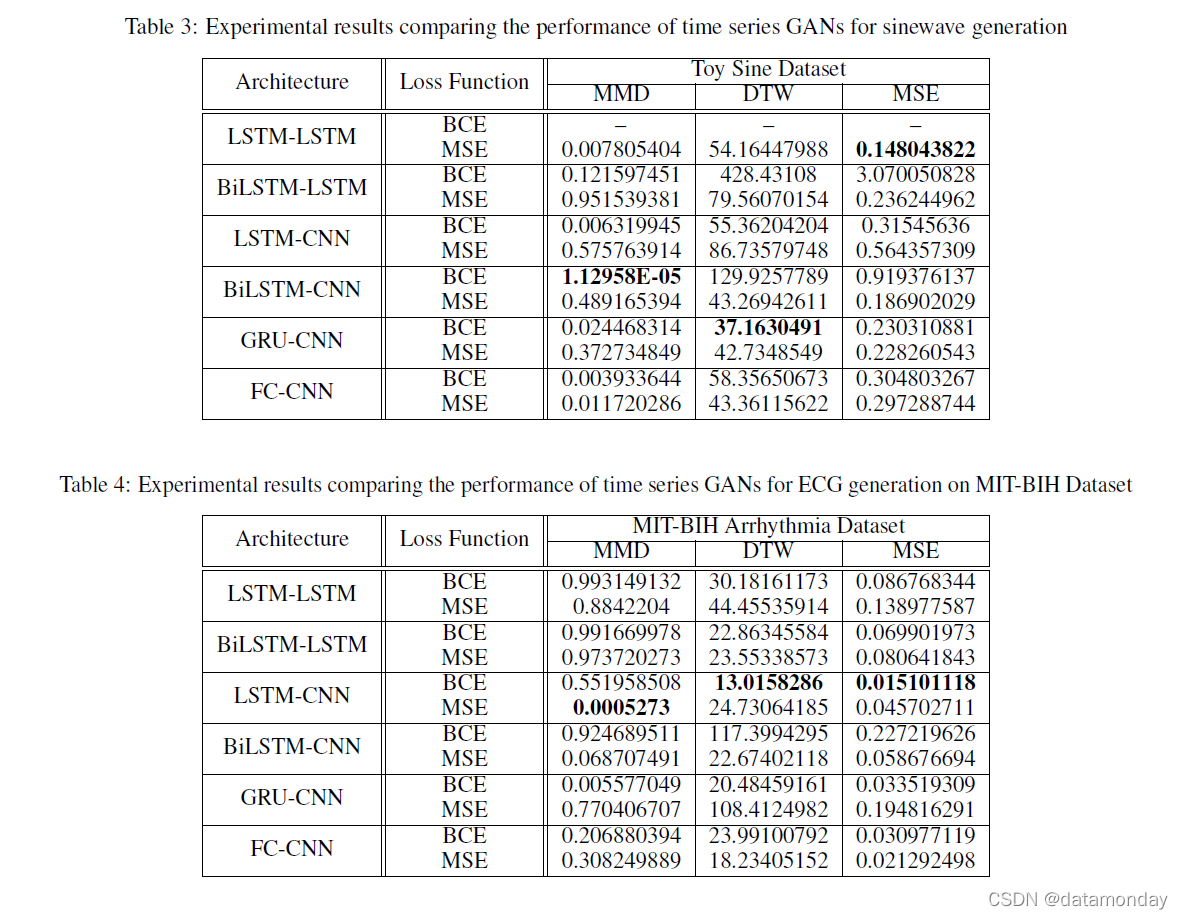
有关本工作中的 GAN 架构的完整列表、它们的应用、评估指标和各自实验中使用的数据集,请参见表 2。使用 GAN 架构的变体生成正弦波和 ECG 的结果分别在表 3 和 4。

7 Privacy
除了评估数据的质量外,还使用了多种方法来评估和减轻与 GAN 创建的合成数据相关的隐私风险。
7.1 Differential Privacy
差分隐私(Differential Privacy)的目标是保护数据库的底层隐私。如果通过查看生成的样本,我们无法确定样本是否包含在训练集中,则算法或更具体地说,GAN 实现了差分隐私。当 GAN 尝试对训练数据集进行建模时,隐私问题在于捕获和生成有关训练集总体的有用信息,而无法将生成的样本链接到个人数据 [98]。
正如我们之前提到的,GAN 的主要目标之一是扩充现有资源不足的数据集,以用于进一步的下游应用,例如提高涉及医疗保健数据的临床医生的技能。这些个人敏感数据必须包含隐私保证,DP [99] 的严格数学定义提供了这种保证。
正在开发具有隐私保护机制的机器学习方法,例如差分隐私 (DP)。[100]展示了使用 DP 训练深度神经网络并实现跟踪隐私损失的机制的能力 。[101]提出了一种差分隐私GAN(DPGAN),通过在训练阶段向优化器添加噪声梯度来实现差分隐私。
7.2 Decentralised/Federated Learning
分布式或去中心化学习是限制机器学习中与个人和个人敏感数据相关的隐私风险的另一种方法。机器学习的标准方法要求所有训练数据都保存在一台服务器上。GAN 算法的去中心化/分布式方法需要较大的通信带宽以确保收敛 [102, 103],并且还受到严格的隐私约束。一种新方法可以在共享模型上实现通信高效的协作学习,同时保持所有训练数据分散,称为联邦学习 [104]。[105] 将联邦学习算法应用于 GAN,以实现通信高效的分布式学习,并证明了他们的联邦学习 GAN (FedGAN) 的收敛性。然而,应该注意的是,他们在这项研究中没有对差异隐私进行实验,而是将其作为未来工作的一种途径。
在开发新的 GAN 算法时结合上述联邦学习和差分隐私技术将导致完全分散的私有 GAN 能够生成数据而不会将私有信息泄漏到源数据中。这显然是一个开放的社区研究途径。
7.3 Assessment of Privacy Preservation
我们还可以通过称为属性和存在披露(attribute and presence disclosure)的测试来评估生成模型保护我们隐私的能力 [22]。另一种测试在机器学习领域中更常见的是成员推理攻击(membership inference attack)。这已成为对机器学习模型如何泄漏有关其训练的单个数据记录的信息的定量评估 [106]。
[107]对合成图像进行了成员推理攻击,并得出结论,为了 GAN 中可接受的隐私水平,牺牲了生成数据的质量 。相反,其他人也采用了这种方法,发现 DP 网络可以成功地生成符合差分隐私并抵抗成员推断攻击的数据,而生成的数据质量不会出现太大下降 [23, 68, 71]。
8 Discussion
我们对时间序列 GAN 变体进行了调查,这些变体在解决第 3.2 节中确定的主要挑战方面取得了重大进展。这些 GAN 引入了离散和连续顺序数据生成的概念,并通过一种架构变体或能够捕获这些数据类型中存在的时空依赖性的修改后的目标函数,对彼此进行了增量改进。在这些作品中为某些架构实现的损失函数不一定会推广到其他架构;因此它们变得特定于架构。时间序列 GAN 的架构选择会影响数据的质量和多样性。然而,在实际应用中生成的数据和 GAN 的实际实施方面仍然存在悬而未决的问题,特别是在这些模型的性能可以直接影响患者护理/治疗质量的健康应用中。
“最好的” GAN 架构和目标函数仍有待确定。就目前而言,GAN 倾向于特定于应用程序,也就是说,它们的预期目的表现良好,但不能很好地泛化到其原始领域之外。时间序列 GAN 的一个主要限制是对架构可以管理的指定序列长度的限制。在撰写本文时,验证时间序列 GAN 对不同数据长度的适应能力的记录实验明显缺乏。
9 Conclusion
本文回顾了生成对抗网络在时间序列数据中不断增长的使用,主要基于架构演化和损失函数变体。我们看到每个 GAN 都提供特定于应用程序的性能,并且不一定能很好地推广到其他应用程序,例如由于架构或损失函数施加的一些限制,用于生成高质量生理时间序列的 GAN 可能无法生成高保真音频。提供了对时间序列 GAN 在现实世界问题中的应用的详细回顾,以及它们的数据集和用于每个领域的评估指标。如 [4] 所述,GAN 相关的时间序列研究在性能和模型泛化的定义规则方面都落后于计算机视觉。总之,这篇综述强调了该领域的开放挑战,并为未来的工作和技术创新提供了方向,特别是与评估、隐私和分散学习相关的 GAN 方面。



















 1905
1905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











