







Paper Card
论文标题:Genie: Generative Interactive Environments
论文作者:Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal Behbahani, Stephanie Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Satinder Singh, Tim Rocktäschel
作者单位:Google DeepMind, University of British Columbia
论文原文:https://arxiv.org/abs/2402.15391
论文出处:–
论文被引:–(03/03/2024)
项目主页:https://sites.google.com/view/genie-2024/
论文代码:–
Abstract
Genie 是第一个以无监督方式从无标签的互联网视频中训练出来的生成式交互环境。该模型可以通过文本,合成图像,照片甚至草图来生成无穷无尽的可动作控制的虚拟世界。在参数为 11B 时,Genie 可被视为一个基础世界模型(foundation world model)。它由一个时空视频标记器(spatiotemporal video tokenizer),一个自回归动力学模型(autoregressive dynamics model)和一个简单且可扩展的潜在行动模型组成(latent action model)。Genie 使用户能够在生成的环境中逐帧行动,尽管在训练中不需要任何Ground Truth行动标签或世界模型文献中常见的其他特定领域要求。此外,学习到的潜在动作空间还有助于训练Agent模仿未见视频中的行为,为训练未来的通用Agent开辟了道路。
Keywords: Generative AI, Foundation Models, World Models, Video Models, Open-Endedness
Summary
研究问题:可控的可交互视频生成,试图仅从视频中以无监督的方式学习世界模型。
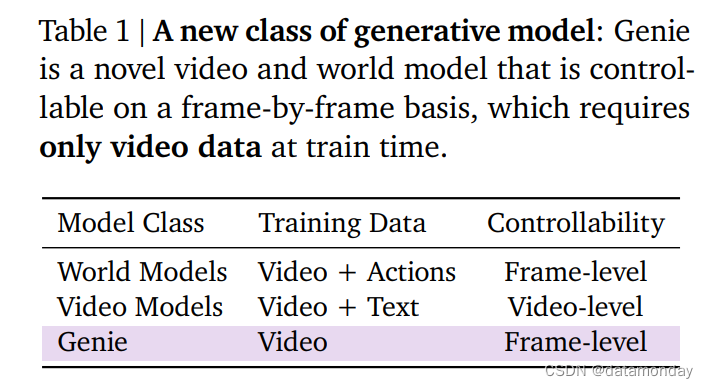
方法概述:可通过单个文本或图像提示(Prompt)生成交互环境。训练时没有动作或文本注释(无监督训练),但它可以通过学习到的潜在动作空间(与其他方法的比较见表 1)逐帧进行控制。
- 模型架构:内存高效的 Spatio-Temporal Transformer,主要成本随帧数的增加而呈线性增长。
- 训练数据:680 万个 16s 视频片段(10 FPS,160x90 分辨率,3 万小时)的互联网上公开的 2D Platformers 游戏视频。
- 涌现能力:在参数为 11B 时,Genie 表现出了基础模型的典型特性——它可以将未见的图像作为提示,从而可以创建和玩完全想象出来的虚拟世界(如图 2)。
主要贡献:
- 第一个以无监督方式从无标签的互联网视频中训练出来的生成式交互环境。
- 30000 小时的无监督 2D Platformers 游戏视频数据集。
主要结论:
- 为了证明方法的通用性,在 RT-1 数据集中的无动作机器人视频上训练了一个单独的模型,学习了具有一致潜在动作的生成环境。
- Genie 可能是打开用于训练下一代通用Agent的无限数据的钥匙。
研究背景
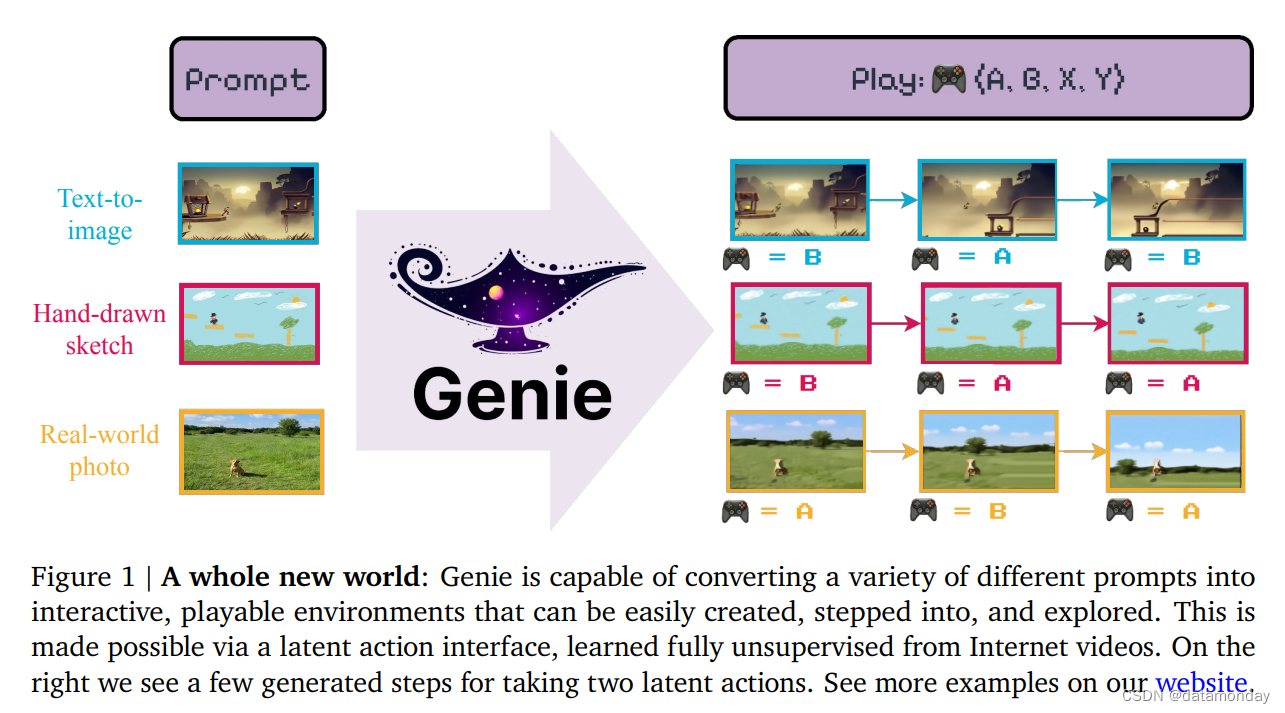
Generative AI 模型能够生成新颖而富有创造性的内容。视频生成是一个前沿领域,最近的研究结果表明,此类模型也可能受益于规模定律。尽管如此,视频生成模型和语言工具(如 ChatGPT)之间的交互和参与程度仍有差距。
方法介绍
基于互联网大型视频语料库,训练出了生成式交互环境(Generative interactive environments)——Genie,可通过单个文本或图像提示(Prompt)生成交互环境。Genie 是通过一个包含 20 多万小时公开互联网游戏视频的大型数据集训练出来的,尽管训练时没有动作或文本注释,但它可以通过学习到的潜在动作空间逐帧进行控制。参数 11B 的 Genie 表现出了基础模型的典型特性——它可以将未见的图像作为提示,从而可以创建和玩完全想象出来的虚拟世界(如图 2)。
模型架构
Genie 基于最先进的视频生成模型 [1] [2] [3] 构建,其核心设计是 ST-Transformer(Spatio-Temporal Transformer) [3]。Genie 利用视频标记器(video tokenizer),通过因果动作模型(causal action model)提取潜在动作(latent actions)。视频标记和潜在动作都传递给动态模型(dynamics model),该模型使用 MaskGIT [4] 对下一帧进行自回归预测。
[1] Maskvit: Masked visual pretraining for video prediction, 2023
[2] Phenaki: Variable Length Video Generation From Open Domain Textual Description, 2023
[3] Spatial-Temporal Transformer Networks for Traffic Flow Forecasting, 2020
[4] MaskGIT: Masked Generative Image Transformer, 2022
Genie 架构中的几个组件基于 ViT。 为了解决 Transformer 的二次内存成本问题(视频可能包含多达
O
(
1
0
4
)
O(10^4)
O(104) 个 token)。因此,在所有模型组件中采用了一种内存高效的 ST-Transformer 架构(受 [3] 的启发,见图 4),在模型容量与计算约束之间取得了平衡。
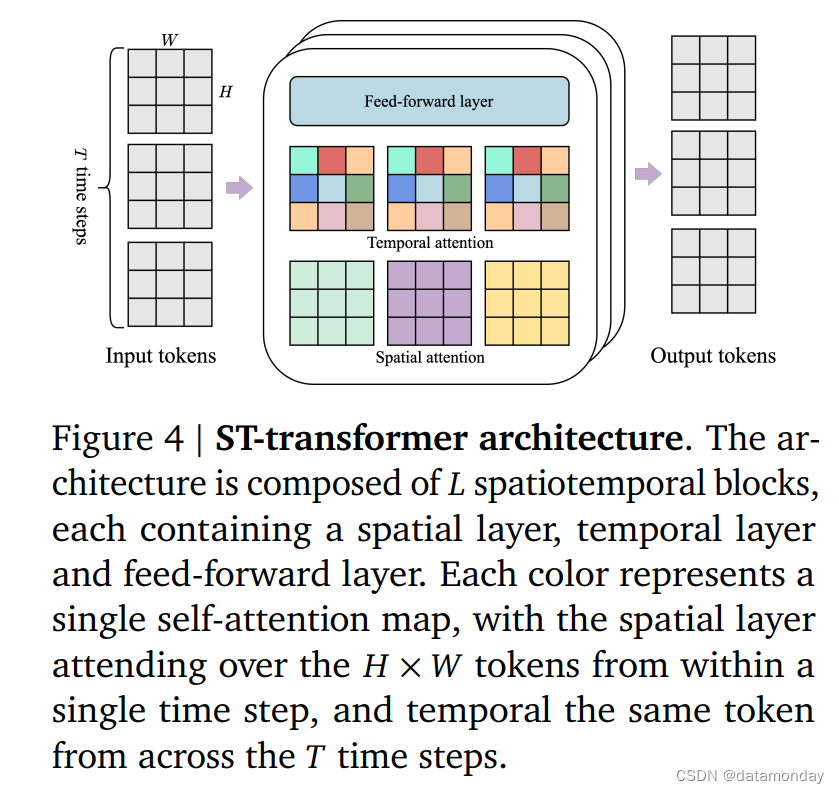
与每个标记都关注所有其他标记的传统Transformer不同,ST-Transformer包含有交错的空间和时间注意层的时空块,以及作为标准注意力块的前馈层(FFW)。空间层中的 self- attention 关注每个时间步内的 1 × H × W 标记,而时间层中的自我注意关注 T × 1 × 1 标记,跨越 T 个时间步。与序列Transformer类似,时间层假设了一个具有因果掩码的因果结构。Genie的架构中,计算复杂度的主要因素(即空间注意力层)与帧数呈线性关系,而不是四次方关系,这使得它在生成视频时更有效率,并能在长时间的交互中保持一致的动态。此外,在 ST 块中,在空间和时间部分之后只包含了一个 FFW,省略了空间后 FFW,以便扩展模型的其他部分。
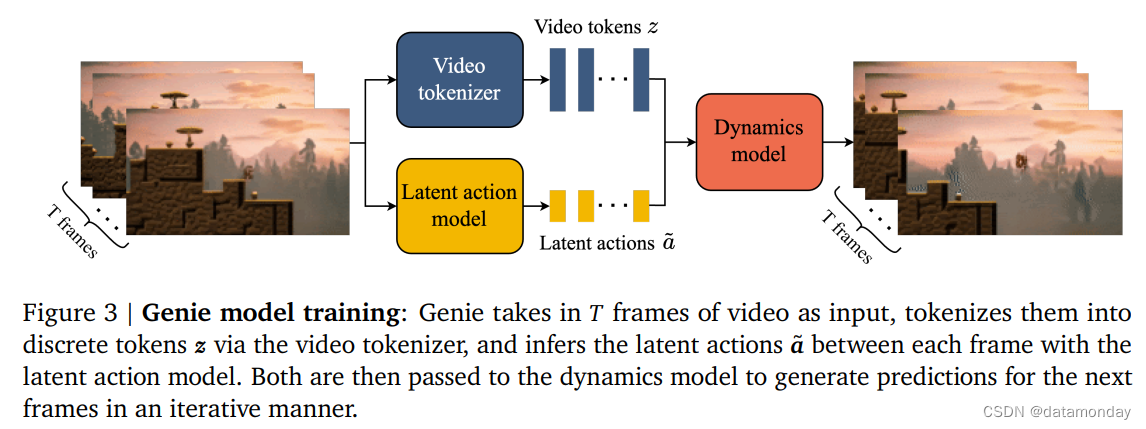
如图 3 上模型包含的三个关键组件:
- 1)潜在动作模型(Latent Action Model,LAM),用于推断每对帧之间的潜在动作 𝒂;
- 2)视频标记器(Video Tokenizer),用于将原始视频帧转换为离散标记 𝒛;
- 3)动力模型(Dynamics Model),用于在给定潜在动作和过去帧标记的情况下预测视频的下一帧。
该模型按照标准的自回归视频生成流水线分两个阶段进行训练:
- 首先训练视频标记器,该标记器用于动态模型。
- 然后,共同训练潜在动作模型(directly from pixels)和动态模型(on video tokens)。
Latent Action Model
为了实现可控视频生成(Controllable Video Generation),将前一帧的动作作为未来每一帧预测的条件。互联网视频中很少有这种动作标签,而且获取动作注释的成本很高。相反,Genie 以完全无监督的方式学习潜在动作(见图 5)。
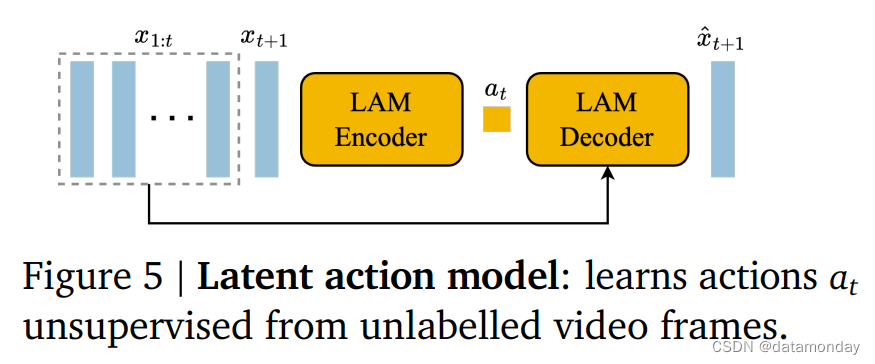
首先,编码器将之前的所有帧 x 1 : t = ( x 1 , . . . , x t ) x_{1:t} = (x_1,..., x_t) x1:t=(x1,...,xt) 以及下一帧 x t + 1 x_{t+1} xt+1 作为输入,并输出一组相应的连续潜在动作 a ~ 1 : t = ( a ~ 1 , . . . , a ~ t ) \tilde{a}_{1:t} = ( \tilde{a}_1,...,\tilde{a}_t) a~1:t=(a~1,...,a~t) 。然后,解码器将之前的所有帧和潜在动作作为输入,预测下一帧 x ^ t + 1 \hat{x}_{t+1} x^t+1。
为了训练模型,利用了基于 VQ-VAE 的目标 [5],能够将预测动作的数量限制在一小组离散的代码中。将 VQ codebook 的词表大小 |A|,即可能的潜在动作的最大数量,限制在一个较小的值,以允许人类的可玩性并进一步加强可控性(在实验中使用 |A|=8)。由于解码器只能访问历史记录和潜在动作, a ~ t \tilde{a}_t a~t 应该编码过去和未来之间最有意义的变化,这样解码器才能成功地重建未来帧。请注意,解码器的存在只是为了提供 LAM 训练信号。事实上,除了 VQ codebook 之外,整个 LAM 在推理时都会被丢弃,取而代之的是用户的操作。
利用 ST Transformer 架构来建立潜在动作模型。时间层中的因果掩码允许将整个视频 x 1 : T x_{1:T} x1:T 作为输入,并生成每帧 a ~ 1 : T − 1 \tilde{a}_{1:T-1} a~1:T−1 之间的所有潜在动作。
[5] Neural discrete representation learning, 2017
Video Tokenizer
根据先前的工作 [1] [2] [6],将视频压缩为离散标记,以降低维度并生成更高质量的视频(见图 6)。使用 VQ-VAE 将 T 帧视频
x
1
:
T
=
(
x
1
,
x
2
,
…
,
x
T
)
∈
R
T
×
H
×
W
×
C
x_{1:T} = (x_1, x_2, \ldots , x_T ) \in \mathcal{R}^{T × H × W × C}
x1:T=(x1,x2,…,xT)∈RT×H×W×C 作为输入,为每个帧生成离散表示
z
1
:
T
=
(
z
1
,
z
2
,
…
,
z
T
)
∈
I
T
×
D
z_{1:T} = (z_1, z_2, \ldots, z_T ) \in \mathcal{I}^{T × D}
z1:T=(z1,z2,…,zT)∈IT×D,其中 D 是离散潜在空间的大小。标记器采用标准的 VQ-VQAE 目标对整个视频序列进行训练。
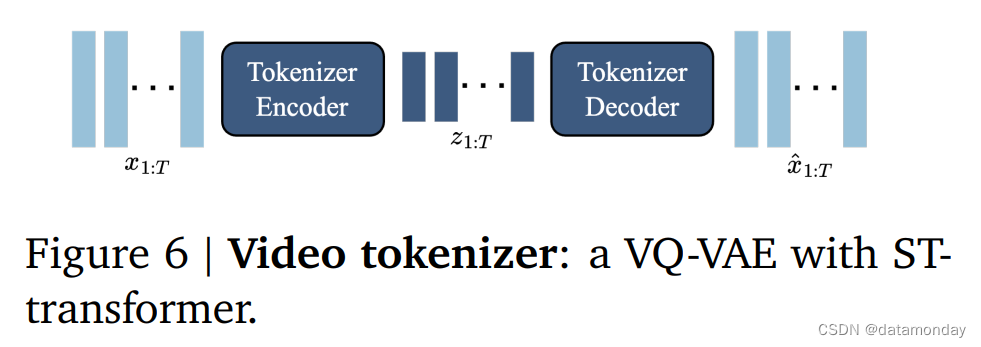
与之前在标记化阶段只关注空间压缩的工作 [1] [7] [8] 不同,在编码器和解码器中都使用了 ST Transformer,将时间动态纳入编码,从而提高了视频生成质量。由于 ST Transformer 的因果性质,每个离散编码 z t z_t zt 都包含了视频 x 1 : t x_{1:t} x1:t 之前所有帧的信息。Phenaki [2] 也使用了一种时间感知标记器 C-ViViT,但这种架构的计算密集度很高,成本随帧数的增加而呈二次曲线增长——相比之下,基于 ST Transformer 的标记器(ST-ViViT)的计算效率要高得多,其主要成本随帧数的增加而呈线性增长。
[6] Temporally consistent transformers for video generation, 2023
[7] CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers, 2022
[8] NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion, 2022
Dynamics Model
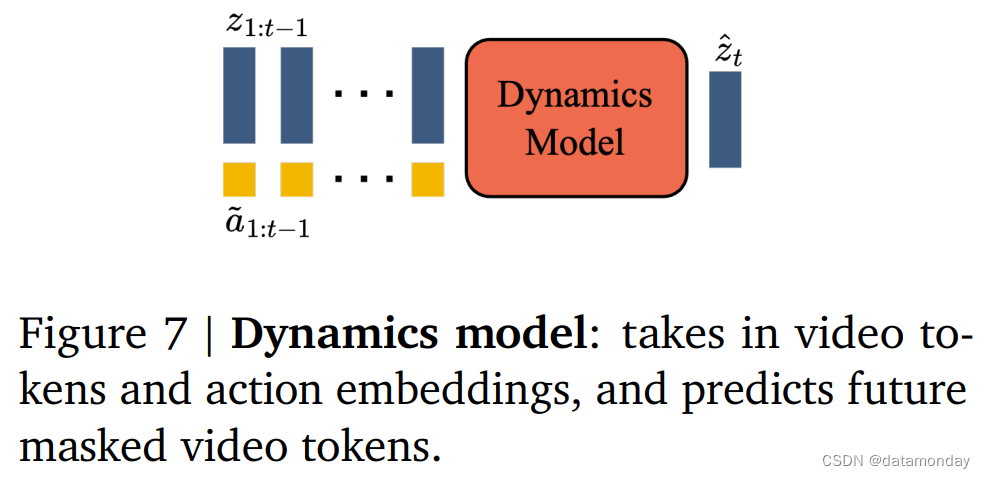
动态模型是一个仅用于解码器的 MaskGIT [4] Transformer(图 7)。在每个时间步骤 t ∈ [ 1 , T ] t \in [1, T] t∈[1,T],它接收标记化视频 z 1 : t − 1 z_{1:t-1} z1:t−1 和停止级潜在动作 a ~ 1 : t − 1 \tilde{a}_{1:t-1} a~1:t−1,并预测下一帧标记 z ^ t \hat{z}_t z^t。用 ST Transformer,其因果结构能够使用来自所有 (T - 1) 帧 z 1 : T − 1 z_{1:T-1} z1:T−1 的标记和潜在动作 a ~ 1 : T − 1 \tilde{a}_{1:T-1} a~1:T−1 作为输入,并生成对所有下一帧 z ^ 2 : T \hat{z}_{2:T} z^2:T 的预测。该模型在预测的标记 z ^ 2 : T \hat{z}_{2:T} z^2:T 和 Ground Truth 标记 z 2 : T z_{2:T} z2:T 之间进行交叉熵损失训练。在训练时,我们根据伯努利分布(Bernoulli distribution)在 0.5 和 1 之间均匀采样的掩码率随机 mask 输入标记 z 2 : T − 1 z_{2:T-1} z2:T−1。训练世界模型的常见做法是将时间 𝑡 的动作与相应的帧连接(concatenate) [9] [10]。然而,将潜在动作作为潜在动作模型和动力学模型的加法嵌入(additive embeddings),有助于提高生成的可控性。
[9] Transformers are sample-efficient world models, 2023
[10] Transformer-based World Models Are Happy With 100k Interactions, 2023
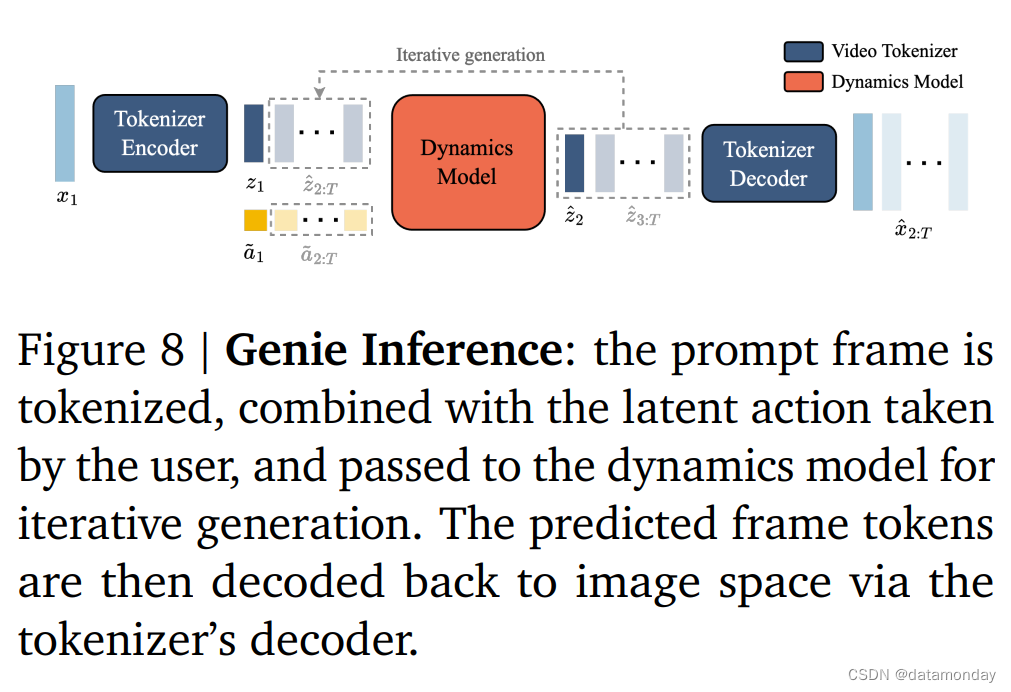
Inference: Action-Controllable Video Generation
玩家首先会用一幅图像 x1(作为初始帧)来提示模型。使用视频编码器对图像进行标记化,得到 z1。然后,玩家指定一个离散的潜在动作 a1,通过选择 [0, |A|) 内的整数值来采取。动态模型利用帧标记 𝑧1 和相应的潜动作
a
~
1
\tilde{a}_1
a~1(该潜动作是通过索引 VQ codebook 和离散输入 𝑎1 得到的)来预测下一帧标记 𝑧2。当动作继续传递给模型时,这一过程会重复进行,以自回归方式生成序列的其余部分
z
^
2
:
T
\hat{z}_{2:T}
z^2:T,而标记则通过标记器的解码器解码为视频帧
x
^
2
:
T
\hat{x}_{2:T}
x^2:T。可以通过向模型传递起始帧和从视频中推断出的动作,从数据集中重新生成Ground Truth视频,或者通过改变动作生成全新的视频(或轨迹)。
实验结果
Datasets
数据来源:互联网上公开的 2D Platformers(以下简称 “Platformers”)视频
数据规格:10FPS,160x90 分辨率,5500 万个 16s 视频片段。最终数据集包含 680 万个 16s 视频片段(3 万小时),与其他流行互联网视频数据集 [11] [12] 的数量级相当。
为了验证方法的通用性,还考虑了用于训练 RT-1 的机器人数据集,大约 130 k 机器人演示数据集与一个单独的模拟数据集以及先前工作 [13] 中的 209 k episodes 真实机器人数据相结合。没有使用这些数据集中的任何动作,只是将它们视为视频。
[11] Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval, 2021
[12] Internvid: A large-scale video-text dataset for multimodal understanding and generation, 2023
[13] QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation, 2018
Metrics
通过两个因素来考察Genie的视频生成性能,
- 视频保真度(video fidelity):即视频生成的质量。使用了 Frechet Video Distance (FVD),这是一个视频级指标,已被证明与人类对视频质量的评价高度一致 [14] 。
- 可控性(controllability):即潜在动作对视频生成的影响程度。设计了一个基于峰值信噪比(peak signal-to-noise ratio,PSNR)的指标,称之为 △ t P S N R \triangle_t PSNR △tPSNR,该指标用于衡量在根据 Ground Truth 推断出的潜在动作( x ^ t \hat{x}_t x^t)与随机分布采样( x ^ t ′ \hat{x}_t^{\prime} x^t′)的条件下,视频生成的差异程度:
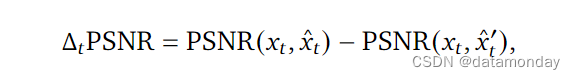
其中, x t x_t xt 表示时间𝑡处的 Ground Truth 帧, x ^ t \hat{x}_t x^t 表示从 Ground Truth 帧中推断出的潜在行动 a ~ 1 : t \tilde{a}_{1:t} a~1:t, x ^ t ′ \hat{x}_t^{\prime} x^t′ 表示从分类分布中随机抽取的潜动作序列生成的同一帧。因此, △ t P S N R \triangle_t PSNR △tPSNR 越大,随机潜在动作生成的视频与 Ground Truth 的差异就越大,这表明潜在动作的可控性越高。在所有实验中,我们都报告了 △ t P S N R \triangle_t PSNR △tPSNR(𝑡 = 4)。
[14] FVD: A new Metric for Video Generation, 2019
Training Details
视频标记器 200M 参数,patch size = 4 ,embedding size = 32 和 1024 个唯一编码的codebook,我们发现,考虑到标记器的重构质量和视频预测的下游性能之间的权衡,这是最有效的。
潜动作模型 300M 参数,patch size = 16,codebook 的 embedding size = 32,唯一编码为 8(潜在动作)。
对于所有建模组件,使用的序列长度为 16 帧,FPS=10。
采用 bfloat16 和 QK norm 来训练动态模型,这已被证明能稳定大规模训练 [15] [16]。在推理时,使用随机抽样对每个温度为 2 的帧执行 25 个 MaskGIT 抽样步骤。详见附录 C。
[15] Scaling Vision Transformers to 22 Billion Parameters, 2023
[16] Query-Key Normalization for Transformers, 2020
Scaling Results
研究模型的规模行为,探讨模型大小和批量大小的影响。
Scaling Model Size
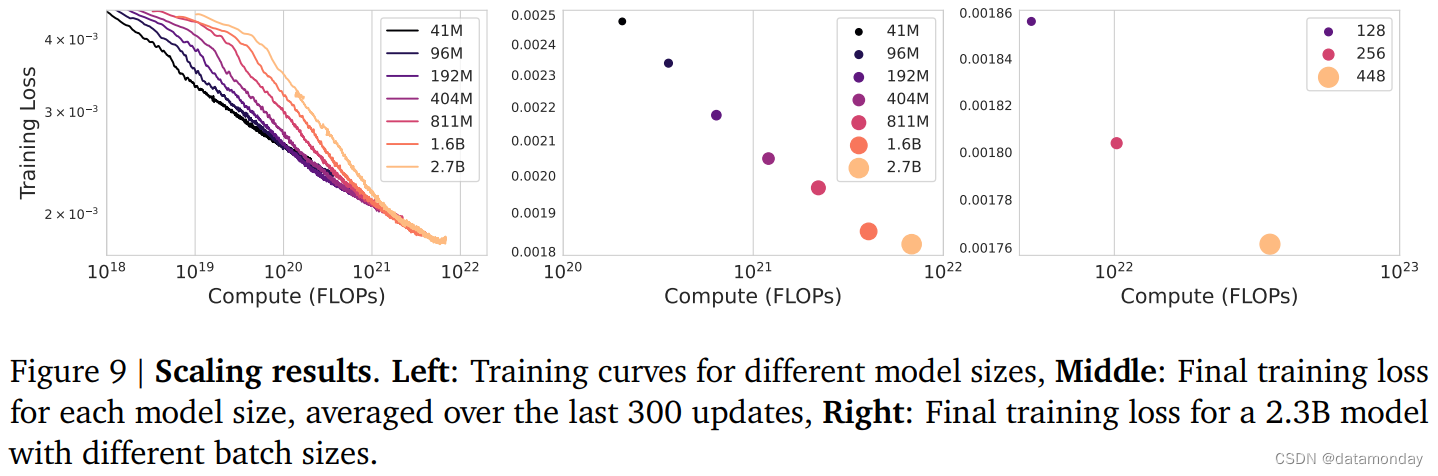
视频标记器和动作模型架构固定,从 40M 到 2.7B 的动态模型,图 9 显示,架构可以随着模型参数的增加而扩展,每增加一个参数,最终的训练损失都会相应减少。
Scaling Batch Size
的 2.3B 模型,如图 9 所示,增加批量大小同样能提高模型性能。
Genie Model
增加模型大小和批量大小都有助于提高模型性能。因此,在最终模型中,使用 256 个 TPUv5p 训练了 10.1B 动态模型,批量大小为 512,共 125k 步。与标记器和动作模型相结合后,总参数达到 10.7B,在 942B tokens 上进行了训练,将其称为 Genie 模型。
Qualitative Results
Robotics-trained model

从机器人数据集中的三个不同起始帧开始的轨迹。每列显示五次采取相同的潜在动作所产生的帧。尽管训练中没有动作标签,但相同的动作在不同的提示框中是一致的,并且具有语义含义:向下、向上和向左。
在机器人数据集上训练了一个 2.5B 参数的模型,使用的超参数与 Platformers 数据集上最好的超参数相同,在测试集上的 FVD 达到了 82.7。如图 13 所示,该模型成功地从视频数据中学习到了独特而一致的动作,既不需要文本也不需要动作标签。模型不仅能学习机械臂的控制,还能学习各种物体的交互和变形(图 11)。可以利用互联网上更大的视频数据集来创建机器人技术的基础世界模型,该模型具有低层次可控模拟能力,可用于各种应用。
Training Agents
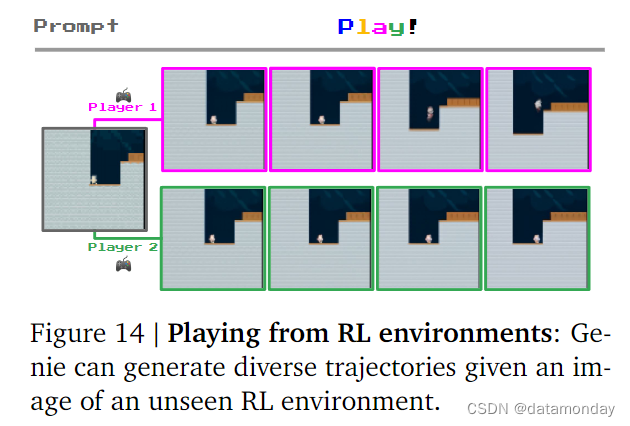
Genie终有一天会成为训练通用Agent的基础世界模型。图 14 显示,该模型已可用于在给定起始帧的未知 RL 环境中生成各种轨迹。
Ablation Studies
Design choices for latent action model
在设计潜在动作模型时,仔细考虑了要使用的输入类型。最终选择了使用原始图像(像素),将这一选择与使用标记化图像(图 5 中用 z 代替 x)的替代方法进行了评估。将这种替代方法称为 token-input 模型(表 2)。
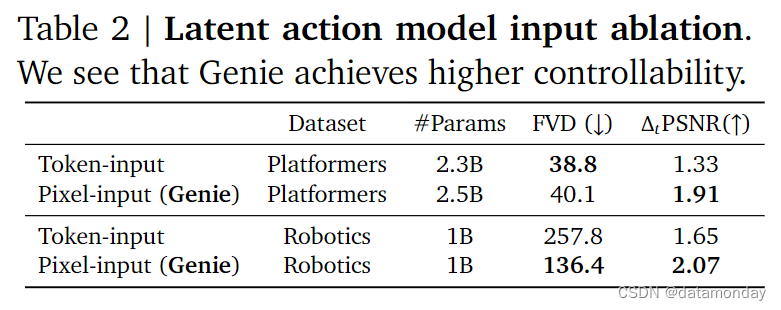
虽然该模型在 Platformers 数据集上的 FVD 分数略低,但在 Robotics 数据集上并没有保持这一优势。更重要的是,在这两种环境中,tokens输入模型都表现出更差的可控性(以 Δ𝑡 PSNR 衡量)。这表明在标记化过程中可能丢失了一些有关视频动态和运动的信息,因此将原始视频作为输入对潜在动作模型是有益的。
Tokenizer architecture ablations
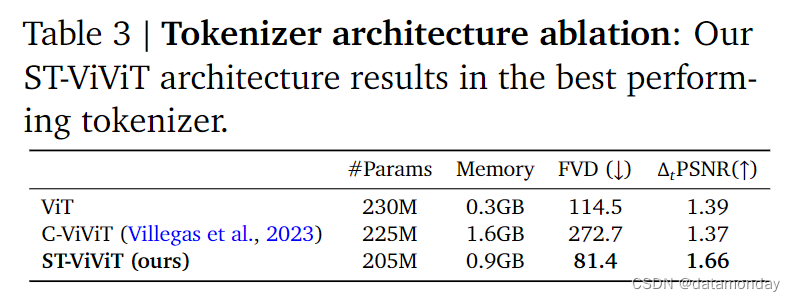
比较了三种标记化器的性能(表 3)。对所有标记器都使用了类似的参数数量,片段大小为 10,批量大小为 128,序列长度为 16。然后,在这三种不同的标记器上训练相同的动态和潜在动作模型,并报告其 FVD 和 Δ𝑡 PSNR。
与 C-ViViT 和纯空间 ViT 相比,本文提出的 ST-ViViT 架构在内存方面进行了合理权衡,同时改进了视频生成(FVD)和Δ𝑡 PSNR。这分别证明了其生成高保真和可控视频的能力。虽然 C-ViViT 采用了全时空注意力机制,导致在相同参数数下内存消耗明显高于其他两种架构,但这并没有转化为性能的提高。事实上,C-ViViT 有过拟合的倾向,因此在训练过程中必须进行强正则化,这可能是其性能较低的原因。
相关工作
World models
生成式交互环境可被视为一类世界模型[17] [18],可根据行动输入进行下一帧预测 。这些模型对训练 Agent 非常有用,因为在 Agent 训练时,它们可以在没有直接环境经验的情况下用于学习策略。然而,学习模型本身通常需要直接从环境中获取行动条件数据(action-conditioned data)。与此相反,Genie试图仅从视频中以无监督的方式学习世界模型。GAIA-1 [19] 和 UniSim [20] 分别为自动驾驶和机器人操纵学习世界模型。这些方法都需要文本和动作标签,而 Genie 则专注于从公开可用的互联网视频中获取纯视频数据进行训练。
[17] Recurrent World Models Facilitate Policy Evolution, 2018
[18] Action-Conditional Video Prediction using Deep Networks in Atari Games, 2015
[19] Gaia-1: A generative world model for autonomous driving
[20] Learning interactive real-world simulators
Video models
视频模型通常以初始帧(或文本)为条件,并预测视频中的剩余帧。 Genie 与最近基于 Transformer 的模型最相似,如 Phenaki,TECO 和 MaskViT,因为在标记化图像上使用了 MaskGIT 和 ST Transformer。虽然视频模型的可控性越来越强,但追求的目标更加Agent化,并明确地从数据中学习潜在动作空间,允许用户或Agent使用以潜在动作为条件的预测来 “play” 模型。
Playable Video Generation
Genie超越了 Playable Video Generation (PVG) [21],在 PVG 中,潜在动作用于控制直接从视频中学习的世界模型 [21] [22]。与 Genie 不同的是,PVG 考虑的是特定领域的静态示例,而不是通过提示生成全新的环境。因此,要超越这种设置,就需要进行非同小可的架构改变,放弃归纳偏差,以换取通用方法。
[21] Playable Video Generation, 2021
[22] Playable Environments: Video Manipulation in Space and Time, 2022
Environment generation
与 Procedural Content Generation (PCG),相关,例如 [23]。机器学习在生成游戏关卡方面被证明非常有效 [24],最近通过语言模型直接编写游戏代码 [25] [26]。语言模型本身也可被视为交互环境 [27],尽管缺乏视觉组件。相比之下,在我们的设置中,关卡可以直接从像素中学习和生成,这使我们能够利用互联网视频数据的多样性。
[23] Increasing generality in machine learning through procedural content generation, 2020
[24] Procedural Content Generation via Machine Learning (PCGML), 2018
[25] Level Generation Through Large Language Models, 2023
[26] Prompt- guided level generation, 2023
[27] From Word Models to World Models: Translating from Natural Language to the Probabilistic Language of Thought, 2023
Training agents with latent actions
之前的研究已经将潜动作用于观察模仿 [28],规划 [29] 和预训练 RLAgent [30]。这些方法的目标与我们的潜在行动模型类似,但尚未大规模应用。VPT [31] 是一种最新方法,它使用从人类提供的动作标签数据中学习的反动力学模型,为互联网规模的视频贴上动作标签,然后用于训练策略。Genie可以利用从互联网视频中学习到的潜在动作来推断任意环境下的策略,从而避免了对 Ground Truth 动作的需求,因为 Ground Truth 动作的成本很高,而且可能无法通用。
[28] Imitating Latent Policies from Observation, 2018
[29] Learning what you can do before doing anything, 2019
[30] Learning to act without actions, 2024
[31] Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos, 2022
实验结论
局限性:Genie 继承了其他自回归 Transformer 模型的一些弱点,可能会存在幻觉。虽然在时空表征方面取得了进展,但仍然受限于 16 帧的内存,这使得很难在长时间内获得一致的环境。Genie目前的运行速度约为 1FPS,需要未来的进步才能实现高效的交互帧率。只是简单介绍了使用 Genie 训练Agent的能力,但鉴于缺乏丰富多样的环境是 RL 的主要局限之一,我们可以开辟新的道路,创造出更具通用能力的Agent。



















 143
143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











