









Paper Card
论文标题:DeepSeek-V3 Technical Report
论文作者:DeepSeek-AI
论文链接:https://arxiv.org/abs/2412.19437v1
论文出处:/
论文被引:/
项目主页:https://github.com/deepseek-ai/DeepSeek-V3
Abstract
DeepSeek-V3 是一个强大的专家混合 (MoE) 语言模型,有 6710 亿个参数,每个token激活 370 亿个参数。 为了实现高效的推理和低成本训练,采用了多头潜在注意力 (MLA) 和 DeepSeekMoE 架构,这些架构已在 DeepSeek-V2 中得到充分验证。DeepSeek-V3 开创了一种无需辅助损失的负载均衡策略,并设定了多Token预测训练目标以获得更强的性能。使用 14.8 万亿个多样化且高质量的Token进行预训练,然后进行监督微调和强化学习。综合评估表明,DeepSeek-V3 的性能优于其他开源模型,并达到了与领先的闭源模型相当的性能。完整训练仅需 278.8 万 H800 GPU 小时,其训练过程非常稳定。在整个训练过程中,没有遇到任何不可恢复的损失峰值,也没有进行任何回滚。
Summary
DeepSeek-V3 对具身智能的启发?
- VLA 模型骨干融入MoE架构,policy head部分也可以参考MoE,类似的工作还有HPT,但不是标准的MoE。可以实现具身智能最难的跨本体泛化,不同的action space使用不同的expert进行学习,而模型骨干是共享的。
- 继续演进 DeepSeek-VL2,基于V3构建VL3,提高具身场景的推理能力
研究背景
为进一步突破开源模型的能力边界,构建了 DeepSeek-V3,这是一个具有6710亿参数的大型专家混合模型(MoE),其中每个token激活370亿参数。
方法介绍
DeepSeek-V3 目标是实现强大的模型性能和可控的经济成本。因此,在架构方面,DeepSeek-V3仍然采用多头潜在注意力(MLA)以实现高效推理,并采用 DeepSeekMoE 以实现经济高效的训练。这两种架构已在DeepSeek-V2 中得到验证,证明了它们在实现高效训练和推理的同时保持强大的模型性能的能力。还实现了两种额外的策略增强模型能力。首先,开创了一种无辅助损失的策略用于负载均衡,目的是最大限度地减少为了鼓励负载均衡而对模型性能造成的负面影响。 其次,采用多token预测训练目标,这可以提高评估基准上的整体性能。
为了实现高效训练,支持FP8混合精度训练,并为训练框架实施了全面的优化。低精度训练已成为一种很有前景的高效训练解决方案,其发展与硬件能力的进步密切相关。 本工作引入了一个FP8混合精度训练框架,并首次在一个极大规模的模型上验证了其有效性。通过支持FP8计算和存储,实现了训练加速和GPU内存使用减少。设计了DualPipe算法以实现高效的流水线并行,该算法具有更少的流水线气泡,并通过计算-通信重叠隐藏了训练期间的大部分通信。此重叠确保随着模型进一步扩展,只要保持恒定的计算与通信比率,仍然可以在节点间使用细粒度的专家,同时实现接近于零的全对全通信开销。还开发了高效的跨节点全对全通信内核,以充分利用InfiniBand (IB)和NVLink带宽。还精心优化了内存占用,使得无需使用代价高昂的张量并行就能训练DeepSeek-V3。通过这些努力的结合,实现了高训练效率。
在预训练期间,使用 14.8T 高质量和多样化的token训练。预训练过程非常稳定。在整个训练过程中,我们没有遇到任何不可恢复的损失峰值,也不需要回滚。接下来,进行两阶段上下文长度扩展。在第一阶段,最大上下文长度扩展到32K,在第二阶段,进一步扩展到128K。此后,进行后训练,包括在DeepSeek-V3的基础模型上进行监督微调(SFT)和强化学习(RL),以使其与人类偏好对齐,并进一步释放其潜力。在后期训练阶段,从DeepSeek-R1系列模型中提取推理能力,同时仔细保持模型精度和生成长度之间的平衡。
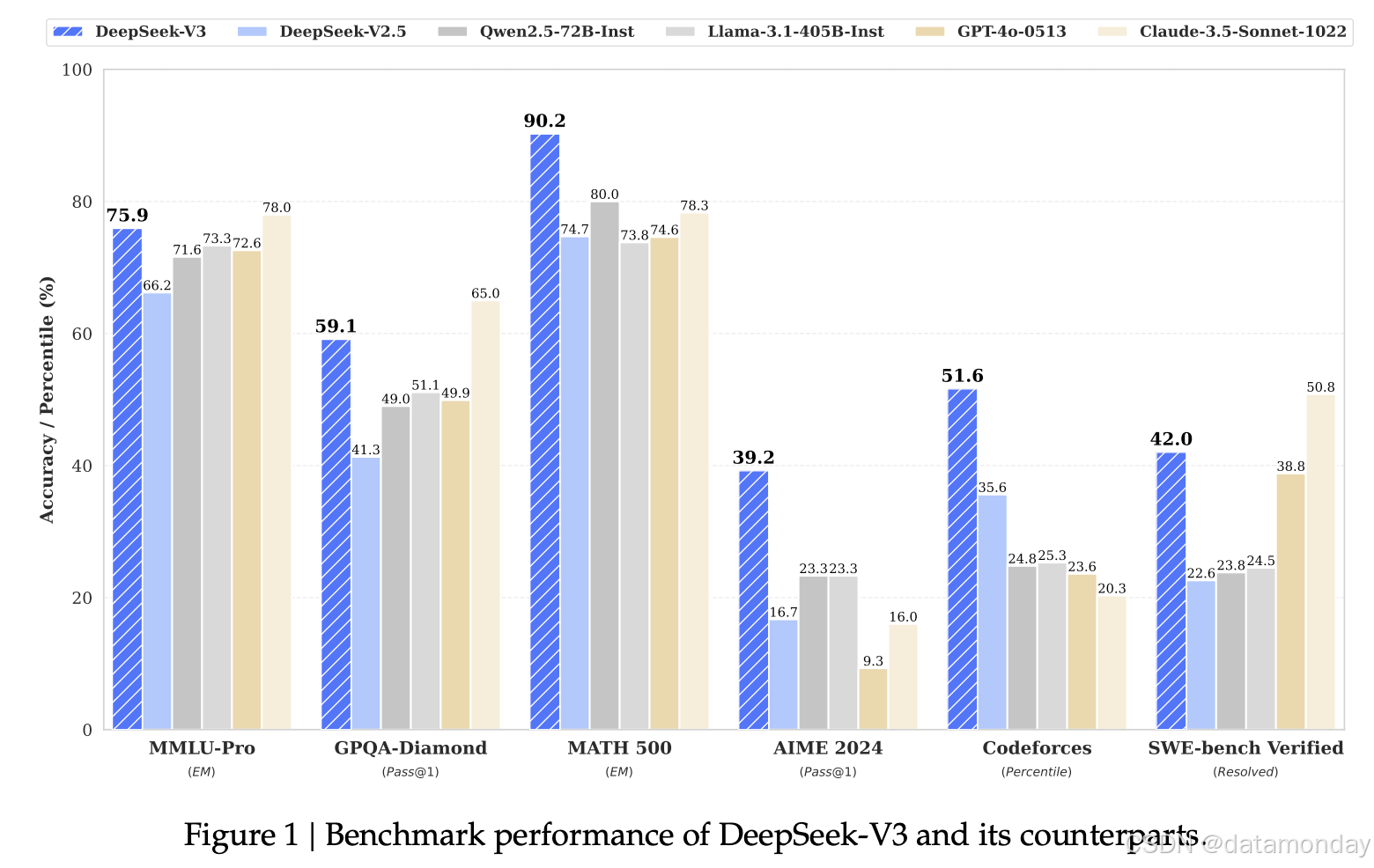
在全面的基准测试集上评估DeepSeek-V3。综合评估显示,DeepSeek-V3-Base已成为目前可用的最强开源基础模型,尤其是在代码和数学方面。其聊天版本也优于其他开源模型,并在一系列标准和开放式基准测试中实现了与领先的闭源模型(包括GPT-4o和Claude-3.5-Sonnet)相当的性能。

DeepSeek-V3经济高效的训练成本,如表1所示,这是通过对算法、框架和硬件的优化协同设计实现的。在预训练阶段,在每个万亿个token上训练DeepSeek-V3只需要18万个H800 GPU小时,即在2048个H800 GPU的集群上运行3.7天。因此,预训练阶段在不到两个月内完成,耗费了266.4万个GPU小时。 加上上下文长度扩展的11.9万GPU小时和后期训练的5千GPU小时,DeepSeek-V3的全部训练仅需278.8万GPU小时。 假设H800 GPU的租赁价格为每GPU小时2美元,总训练成本仅为557.6万美元。上述成本仅包括DeepSeek-V3的正式训练,不包括与先前关于架构、算法或数据的研究和消融实验相关的成本。
主要贡献
架构:创新的负载均衡策略和训练目标
- 在DeepSeek-V2高效架构的基础上,开创了无辅助损失的负载均衡策略,最大限度地减少了鼓励负载均衡造成的性能下降。
- 研究了多token预测(MTP)目标,并证明它有利于模型性能,还可以用于推测性解码以加速推理。
预训练:迈向极致训练效率
- 设计了一个FP8混合精度训练框架,并首次验证了FP8训练在超大规模模型上的可行性和有效性。
- 通过算法、框架和硬件的协同设计,克服了跨节点MoE训练中的通信瓶颈,实现了接近完全的计算通信重叠。这显著提高了训练效率并降低了训练成本,能够在无需额外开销的情况下进一步扩大模型规模。
- 仅以266.4万H800 GPU小时的经济成本,在14.8万亿token上完成了DeepSeek-V3的预训练,从而产生了目前最强大的开源基础模型。预训练后的后续训练阶段仅需0.1万GPU小时。
后训练:来自DeepSeek-R1的知识蒸馏
- 引入了一种创新的方法,将推理能力(特别是来自 DeepSeek R1系列模型之一的)从长链思维(CoT)模型中蒸馏到标准的大语言模型(LLM)中,特别是DeepSeek-V3。 流程巧妙地将R1的验证和反思模式融入DeepSeek-V3,并显著提高了其推理性能。同时,也保持对DeepSeek-V3输出风格和长度的控制。
核心评估结果摘要
- 知识: (1) 在MMLU、MMLU-Pro和GPQA等教育基准测试中,DeepSeek-V3的性能优于所有其他开源模型,其性能与GPT-4o和Claude-Sonnet-3.5等领先的闭源模型相当。 (2) 对于事实性基准测试,DeepSeek-V3在SimpleQA和中文SimpleQA上都展现出优于其他开源模型的性能。虽然在英文事实知识(SimpleQA)方面落后于GPT-4o和Claude-Sonnet-3.5,但在中文事实知识(中文SimpleQA)方面超过了这些模型。
- 代码、数学和推理: (1) 在所有非长链思维(CoT)开源和闭源模型中,DeepSeek-V3在与数学相关的基准测试中实现了最先进的性能。它甚至在某些基准测试(例如MATH-500)上超越了o1-preview。 (2) 在与编码相关的任务中,DeepSeek-V3成为编码竞赛基准测试(例如LiveCodeBench)中性能最高的模型。对于工程相关任务,虽然DeepSeek-V3的性能略低于Claude-Sonnet-3.5,但它仍然显著超越其他所有模型。
模型架构
DeepSeek-V3的基本架构采用了多头潜在注意力 (MLA) 用于高效推理,DeepSeekMoE 用于经济高效的训练,这些已经被DeepSeek-V2彻底验证。对于未明确提及的细节,DeepSeek-V3 遵循 DeepSeek-V2 的设置。
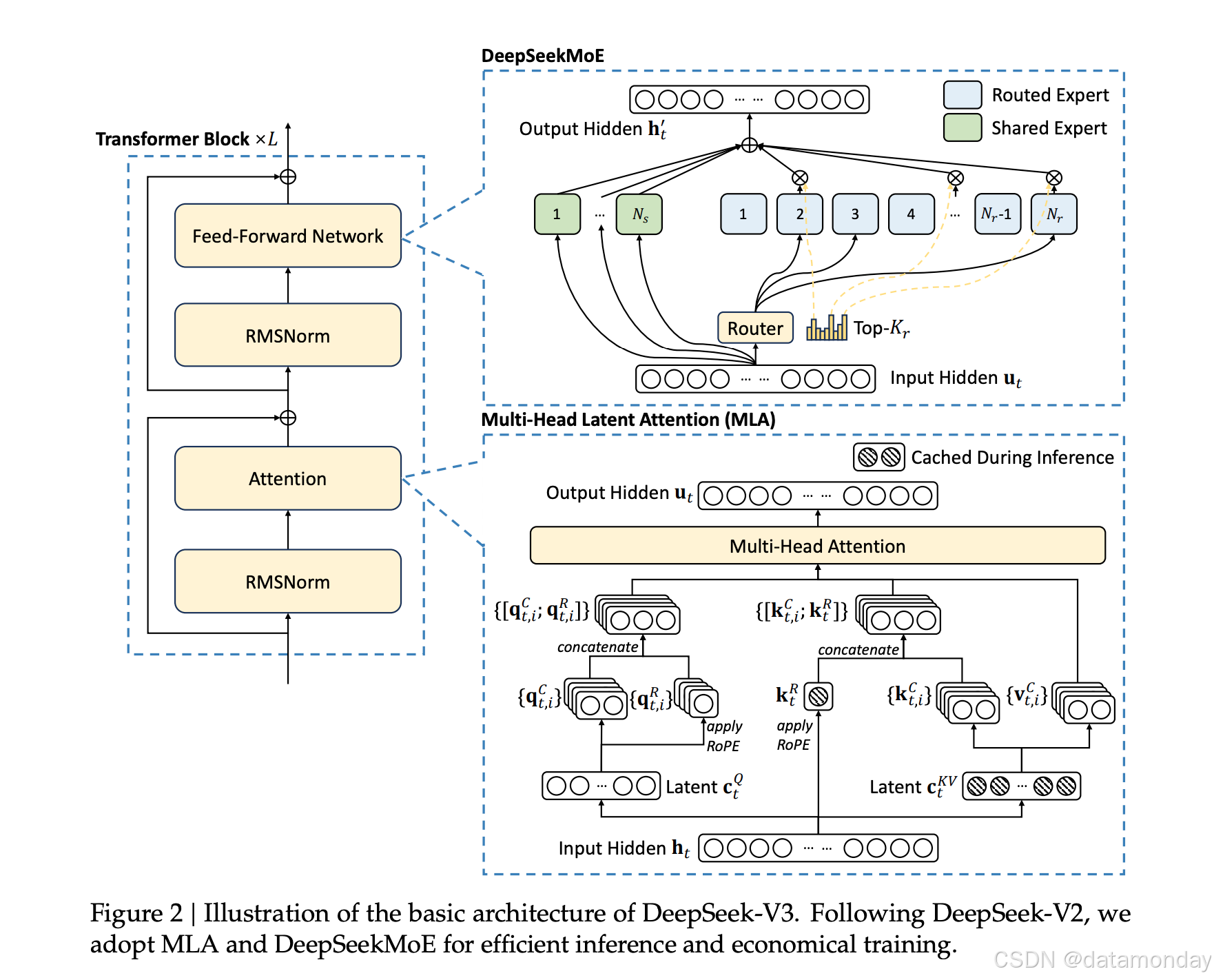
Multi-Head Latent Attention (MLA)
MLA核心是对attention中的 key 和 value 的低秩联合压缩,以减少推理过程中的 KV Cache:
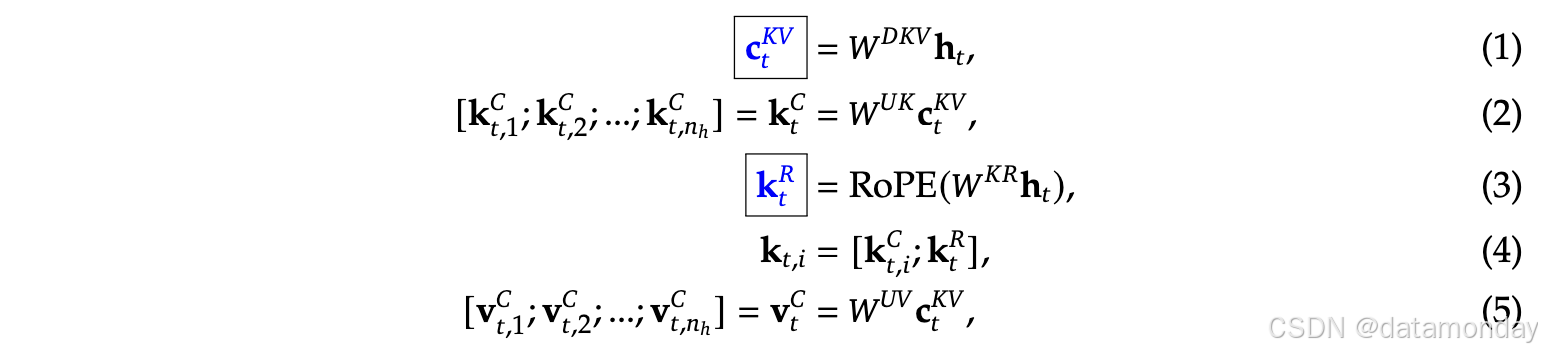
注意力中的 query 也执行低秩压缩,以减少训练过程中的激活内存:
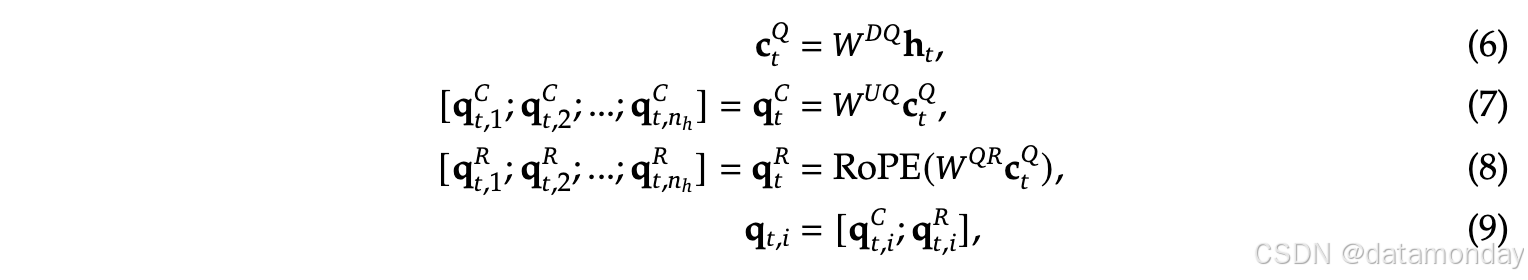
最终的注意力输出为
u
t
\mathbf{u}_t
ut:
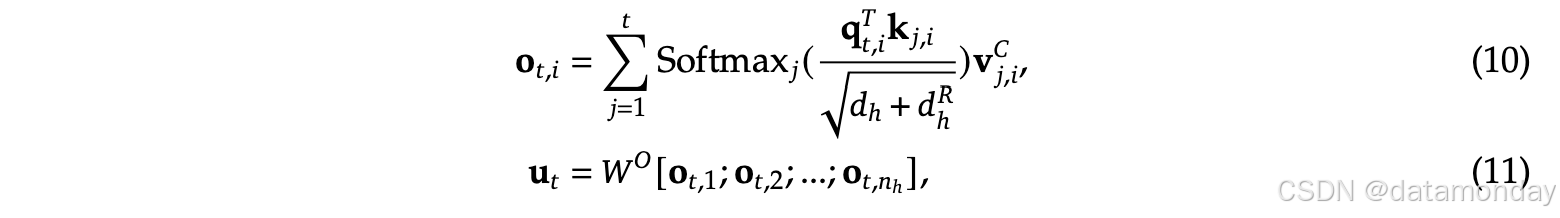
变量名解释:
- d d d: embedding dimension
- n h n_h nh: number of attention heads
- d h d_h dh: dimension per head
- h t ∈ R d \mathbf{h}_t \in \mathbb{R}^d ht∈Rd: attention input for the t-th token at a given attention layer
- c t K V ∈ R d c \mathbf{c}^{KV}_t \in \mathbb{R}^{d_c} ctKV∈Rdc: compressed latent vector for keys and values
- d c ( ≪ d h n h ) d_c (\ll d_hn_h) dc(≪dhnh): KV compression dimension
- W D K V ∈ R d c × d W^{DKV} \in \mathbb{R}^{d_c \times d} WDKV∈Rdc×d: down-projection matrix
- W U K , W U V ∈ R d h n h × d c W^{UK}, W^{UV} \in \mathbb{R}^{d_hn_h \times d_c} WUK,WUV∈Rdhnh×dc: up-projection matrices for keys and values, respectively
- W K R ∈ R d h R × d W^{KR} \in \mathbb{R}^{d^R_h \times d} WKR∈RdhR×d: matrix used to produce the decoupled key that carries Rotary Positional Embedding (RoPE)
- R o P E ( ⋅ ) RoPE(\cdot) RoPE(⋅): the operation that applies RoPE matrices
- c K V , k t R \mathbf{c}^{KV}, \mathbf{k}^R_t cKV,ktR: the blue-boxed vectors need to be cached during generation
- [ ⋅ ; ⋅ ] [\cdot;\cdot] [⋅;⋅]: concatenation
- c t Q ∈ R d c ′ \mathbf{c}^Q_t \in \mathbb{R}^{d^{\prime}_c} ctQ∈Rdc′: compressed latent vector for queries
- d c ′ ( ≪ d h n h ) d^{\prime}_c (\ll d_hn_h) dc′(≪dhnh): query compression dimension
- W D Q ∈ R d c ′ × d , W U Q ∈ R d h n h × d c ′ W^{DQ} \in \mathbb{R}^{d^{\prime}_c \times d}, W^{UQ} \in \mathbb{R}^{d_hn_h \times d^{\prime}_c} WDQ∈Rdc′×d,WUQ∈Rdhnh×dc′: down-projection and up-projection matrices for queries, respectively
- W Q R ∈ R d h R n h × d c ′ W^{QR} \in \mathbb{R}^{d^R_hn_h \times d^{\prime}_c} WQR∈RdhRnh×dc′: matrix to produce the decoupled queries that carry RoPE
- W O ∈ R d × d h n h W^O \in \mathbb{R}^{d \times d_hn_h} WO∈Rd×dhnh: output projection matrix
DeepSeekMoE with Auxiliary-Loss-Free Load Balancing
Basic Architecture of DeepSeekMoE
对于 FFNs,DeepSeek-V3采用DeepSeekMoE架构。 与 GShard 等传统的MoE架构相比,DeepSeekMoE使用更细粒度的专家,并将一些专家隔离为共享专家。
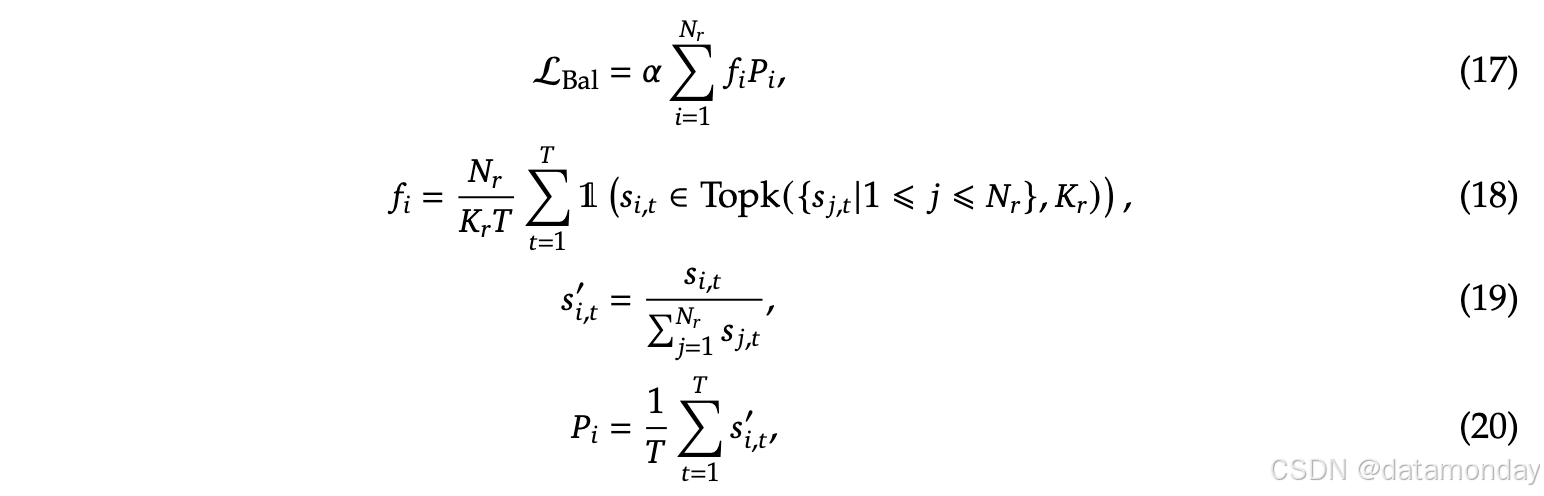
变量名解释:
- u t \mathbf{u}_t ut:
- h t p r i m e \mathbf{h}^{prime}_t htprime:
- N s , N r N_s, N_r Ns,Nr: numbers of shared experts and routed experts, respectively
- F F N ( s ) i ( ⋅ ) , F F N ( r ) i ( ⋅ ) FFN^(s)_i(\cdot), FFN^(r)_i(\cdot) FFN(s)i(⋅),FFN(r)i(⋅): the i-th shared expert and the i-th routed expert, respectively
- K r K_r Kr: the number of activated routed experts
- g i , t g_{i,t} gi,t: the gating value for the i-th expert
- s i , t s_{i,t} si,t: the token-to-expert affinity, DeepSeek-V3 uses the sigmoid function to compute the affinity scores, and applies a normalization among all selected affinity scores to produce the gating values
- e i \mathbf{e}_i ei: the centroid vector of the i-th routed expert
- T o p ( ⋅ , K ) Top(\cdot,K) Top(⋅,K): the set comprising K highest scores among the affinity scores calculated for the t-th token and all routed experts
Auxiliary-Loss-Free Load Balancing
背景:MoE模型,不均衡的专家负载会导致路由崩溃,并且在专家并行场景中会降低计算效率。常规方法是辅助损失来避免不均衡负载。然而,过大的辅助损失会损害模型性能。为了在负载均衡和模型性能之间取得更好的平衡,引入了无辅助损失的负载均衡策略。 具体来说,为每个专家引入一个偏差项
b
i
b_i
bi,并将其添加到相应的亲和力分数
s
i
,
t
s_{i,t}
si,t 中以确定 top-K 路由:
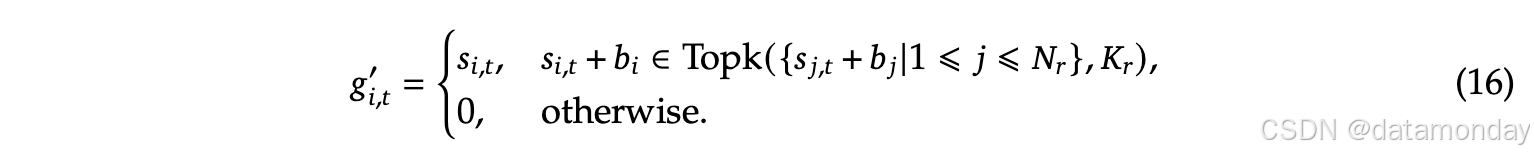
Complementary Sequence-Wise Auxiliary Loss
为了防止单个序列内的不平衡,仍然添加了一种补充的序列级平衡辅助损失,以保证每个序列上的专家负载保持平衡:
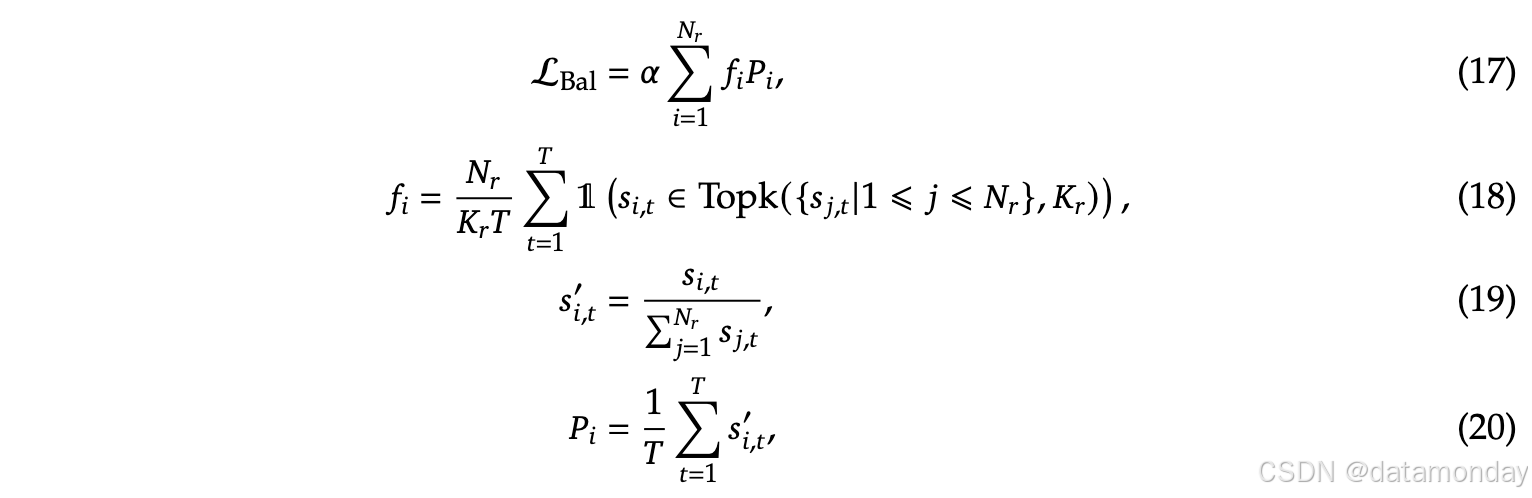
变量名解释:
- α \alpha α: balance vector, an extremely small value
- 1 \mathbb{1} 1: indicator function
- T T T: the number of tokens in a sequence
Node-Limited Routing
DeepSeek-V3也使用受限路由机制来限制训练期间的通信成本。简而言之,确保每个 token 最多会被发送到
M个节点,这些节点根据每个节点上分布的专家最高
K
r
M
\frac{K_r}{M}
MKr 个亲和力分数之和来选择。
No Token-Dropping
由于有效的负载均衡策略,DeepSeek-V3在其整个训练过程中保持良好的负载平衡。 因此,DeepSeek-V3在训练过程中不会丢弃任何 token。 此外,还实现了特定的部署策略以确保推理负载平衡,因此DeepSeek-V3在推理过程中也不会丢弃 token。
Multi-Token Prediction (MTP)
多token预测目标将预测范围扩展到每个位置的多个未来token。一方面,MTP目标使训练信号更加密集,并可能提高数据效率。另一方面,MTP 可以使模型预先规划其表示,以便更好地预测未来的token。
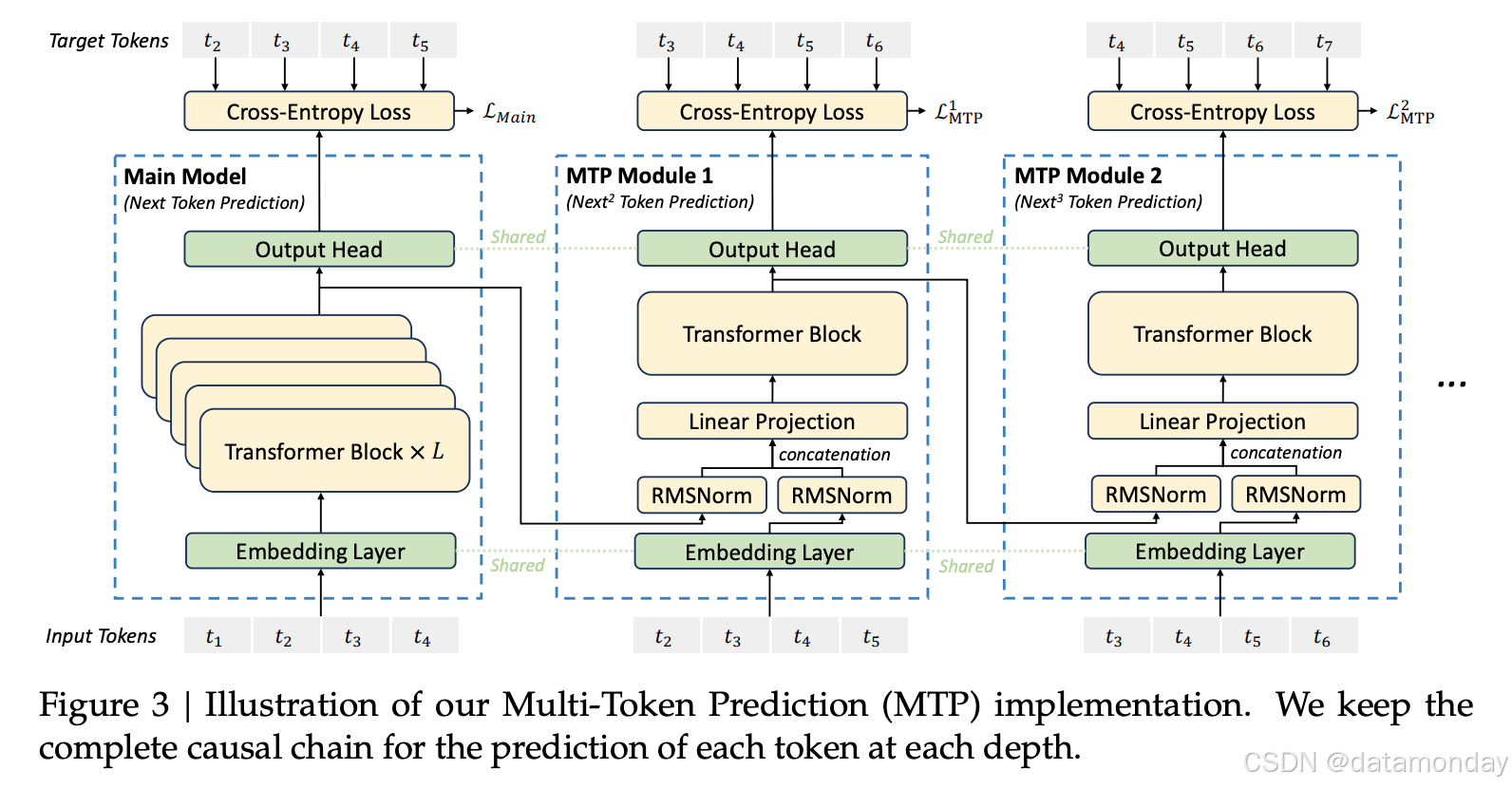
MTP Modules
MTP 实现使用 D 顺序模块来预测 D 个附加token。 第 k 个 MTP 模块由一个共享嵌入层、一个共享输出头、一个 Transformer 块和一个投影矩阵组成。
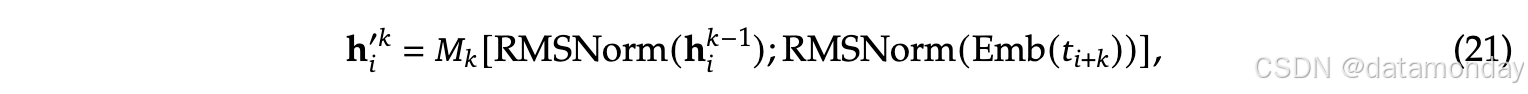

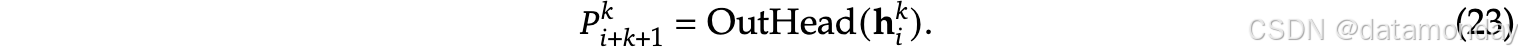
变量名解释:
- E m b ( ⋅ ) Emb(\cdot) Emb(⋅): a shared embedding layer
- O u t H e a d ( ⋅ ) OutHead(\cdot) OutHead(⋅): a shared output head
- T R M k ( ⋅ ) TRM_k(\cdot) TRMk(⋅): Transformer block
- M k ∈ R d × 2 d M_k \in \mathbb{R}^{d \times 2d} Mk∈Rd×2d: a projection matrix
- t i t_i ti: the i-th input token
- h i k − 1 ∈ R d \mathbf{h}^{k-1}_i \in \mathbb{R}^d hik−1∈Rd: the representation of the i-th token at the (k−1)-th depth
- h i ′ k \mathbf{h}^{\prime k}_i hi′k: the input of the Transformer block at the k-th depth
- h i : T − k k \mathbf{h}^k_{i:T-k} hi:T−kk: the output representation at the current depth h i k \mathbf{h}^k_i hik
- T T T: the input sequence length
- i : j _{i:j} i:j: the slicing operation
- V V V: vocabulary size
- P i + 1 + k k ∈ R V P^k_{i+1+k} \in \mathbb{R}^V Pi+1+kk∈RV: the probability distribution for the k-th additional prediction token
OutHead(⋅) 将表示线性映射到 logits,随后应用 Softmax(⋅) 函数来计算第k个附加token的预测概率。对于每个 MTP 模块,其输出头与主模型共享。
MTP Training Objective
对于每个预测深度,计算交叉熵损失:
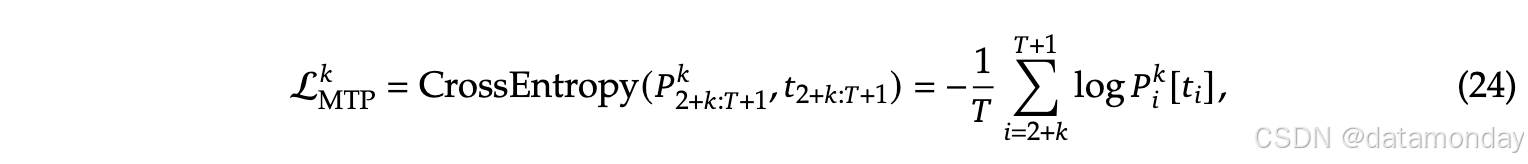
将所有深度的MTP损失取平均值,并乘以权重因子λ,得到整体MTP损失,这作为DeepSeek-V3的附加训练目标:
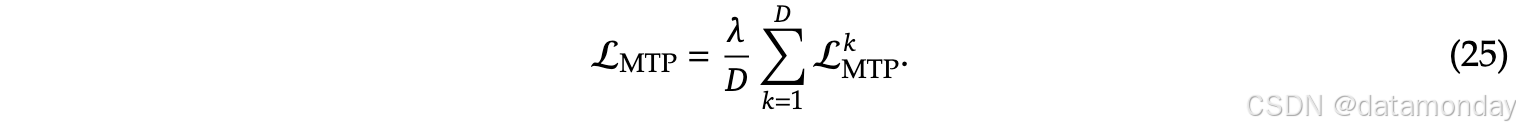
MTP in Inference
MTP策略主要旨在提高主模型的性能,因此在推理过程中,可以直接丢弃MTP模块,主模型可以独立正常运行。
基础设施
详情见技术报告原文。
计算集群:2048个NVIDIA H800 GPU,每个节点包含8个通过节点内的NVLink和NVSwitch连接的GPU。不同节点之间,利用 InfiniBand 互连来通信。
训练框架:自研的高效轻量级训练框架HAI-LLM,DeepSeek-V3应用了16路流水线并行,跨8个节点的64路专家并行,以及ZeRO-1数据并行。
FP8训练:提出了一种细粒度的混合精度框架,利用FP8数据格式训练DeepSeek-V3。在这个框架中,大多数计算密集型操作都在FP8中进行,而一些关键操作则战略性地保留其原始数据格式,以平衡训练效率和数值稳定性。
推理和部署:为了同时确保在线服务的服务级别目标(SLO)和高吞吐量,采用了预填充和解码阶段分开的策略。
预训练阶段
数据构建
与DeepSeek-V2相比,提高数学和编程样本的比例来优化预训练语料库,扩展了英语和中文以外的多语言覆盖范围,改进数据处理流程,最大限度地减少冗余,同时保持语料库的多样性。实现了用于数据完整性的文档打包方法,但在训练过程中未加入跨样本注意力掩码。训练语料库包含 14.8T tokens。
与DeepSeekCoder-V2一致,在DeepSeek-V3的预训练中引入了中间填充(FIM)策略。 具体来说,用前缀-后缀-中间(PSM)框架来构建数据:
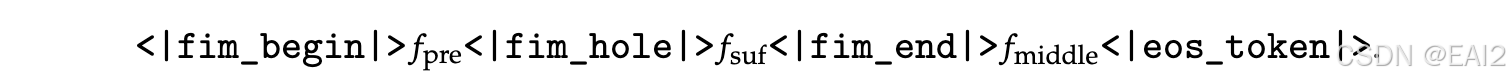
此结构作为预打包过程的一部分应用于文档级别。 FIM策略的应用率为0.1,与PSM框架一致。
DeepSeek-V3的分词器采用字节级 BPE,词汇量扩展到128K个token。 修改了预分词器和训练数据以优化多语言压缩效率。 新的预分词器引入了结合标点符号和换行符的token。
超参数
模型超参数
模型参数量:6710亿,每个token激活参数量370亿
Transformer 层数:61
隐藏层维度:7168
MLA中,注意力层中head的数量
h
h
h_h
hh:128
MLA中,每个head的维度
d
h
d_h
dh:128
MoE Expert 专家数量:1个共享专家,256个路由专家
MoE 中每个 Expert 隐藏层的维度:2048
Router Expert中每个 token 激活的专家数:8
Router Expert 中每个 token 最多发送的专家数:4
MTP 的预测深度D:1
训练超参数
AdamW优化器,β1=0.9、β2=0.95、weight_decay=0.1
预训练期间最大序列长度为 4K
…
长上下文扩展
在预训练阶段之后,应用YaRN进行上下文扩展,并执行两个额外的训练阶段,每个阶段包含1000步,以逐步将上下文窗口从4K扩展到32K,然后扩展到128K。

模型评估
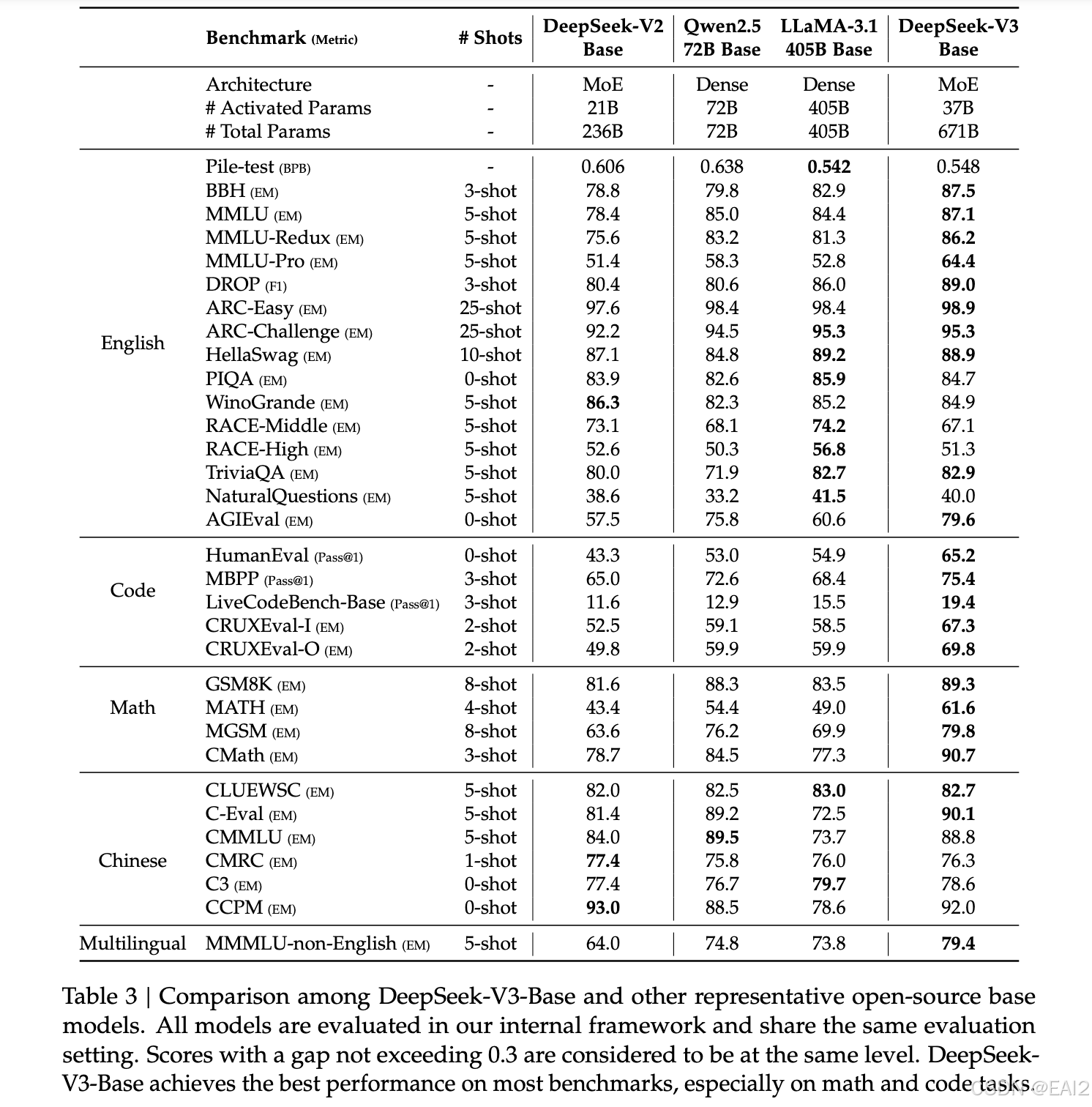
将DeepSeek-V3-Base与其他开源基础模型分别进行比较。
(1) 与DeepSeek-V2-Base相比,由于改进了模型架构、扩大了模型规模和训练token数量,并提高了数据质量,DeepSeek-V3-Base取得了显著更好的性能。
(2) 与目前最先进的中文开源模型Qwen2.5 72B Base相比,DeepSeek-V3-Base仅使用了其一半的激活参数,却展现出显著的优势,尤其是在英语、多语言、代码和数学基准测试中。至于中文基准测试,除了CMMLU(一项中文多学科多项选择任务)外,DeepSeek-V3-Base也表现出比Qwen2.5 72B更好的性能。 (3) 与激活参数是其11倍的最大的开源模型LLaMA-3.1 405B Base相比,DeepSeek-V3-Base在多语言、代码和数学基准测试中也表现出好得多的性能。英语和中文语言基准测试,DeepSeek-V3-Base展现出具有竞争力或更好的性能,尤其在BBH、MMLU系列、DROP、C-Eval、CMMLU和CCPM上表现出色。
由于高效的架构和全面的工程优化,DeepSeek-V3实现了极高的训练效率。 在训练框架和基础设施下,训练DeepSeek-V3每个万亿token仅需18万H800 GPU小时,这比训练72B或405B密集模型便宜得多。
后训练阶段
SFT
数据:指令调优数据集包含跨多个领域的 150 万个样本,每个领域都采用针对其特定需求量身定制的不同数据创建方法。
推理数据:与推理相关的各种数据集,包括专注于数学、代码竞赛问题和逻辑难题的数据集,利用内部 DeepSeek-R1 模型来生成数据。首先使用SFT和RL训练流水线相结合的方法,开发一个针对特定领域(例如代码、数学或一般推理)的专家模型,用作最终模型的数据生成器。
非推理数据:例如创意写作、角色扮演和简单的问答,利用DeepSeek-V2.5生成回复,并请人工标注者验证数据的准确性和正确性。
微调设置:使用SFT数据集对DeepSeek-V3-Base进行两个 epoch 的微调,使用余弦衰减学习率调度,从
5×10−6开始,逐渐减小到1×10−6。
RL
RL 过程中采用基于规则的奖励模型(RM)和基于模型的RM
- 基于规则的奖励模型:对于可以使用特定规则验证的问题,采用基于规则的奖励系统来确定反馈。例如,某些数学问题具有确定性结果,要求模型以指定的格式(例如,填空)提供最终答案,从而应用规则来验证正确性。同样,对于LeetCode问题,可以利用编译器根据测试用例生成反馈。通过尽可能地利用基于规则的验证,确保了更高的可靠性水平。
- 基于模型的奖励模型:对于具有自由形式真值答案的问题,依靠奖励模型来确定响应是否与预期的真值匹配。相反,对于没有明确真实答案的问题,例如涉及创意写作的问题,奖励模型的任务是根据问题和相应的答案作为输入提供反馈。奖励模型是从 DeepSeek-V3 SFT 检查点训练的。为了提高其可靠性,构建了偏好数据,这些数据不仅提供了最终奖励,还包括导致奖励的思维链。此方法有助于减轻特定任务中奖励黑客攻击的风险。
优化方法采用组相对策略优化 (GRPO),它放弃了通常与策略模型大小相同的裁判模型,而是从组分数估计基线。
模型评估

表 6 展示了评估结果,表明 DeepSeek-V3 是性能最佳的开源模型。 此外,它在与GPT-4o和Claude-3.5-Sonnet等前沿闭源模型的竞争中也具有竞争力。
关键结论
本文介绍了一个大型 MoE 语言模型 DeepSeek-V3,拥有 6710 亿总参数和 370 亿激活参数,在 14.8 万亿个token上进行训练。 除了 MLA 和 DeepSeekMoE 架构之外,还采用了无辅助损失的负载均衡策略,并设定了一个多token预测训练目标以增强性能。由于 FP8 训练和细致的工程优化支持,DeepSeek-V3 的训练具有成本效益。 后训练也成功地从 DeepSeek-R1 系列模型中提取了推理能力。综合评估表明,DeepSeek-V3 已成为目前最强大的开源模型,其性能可与 GPT-4o 和 Claude-3.5-Sonnet 等领先的闭源模型相媲美。 保持了经济的训练成本。包括预训练、上下文长度扩展和后训练在内,其完整训练仅需 2,788,000 个 H800 GPU 小时。
DeepSeek-V3 在部署方面存在一些局限性。首先,为了确保高效的推理,DeepSeek-V3 的推荐部署单元相对较大,这可能会给小型团队带来负担。其次,虽然我们针对 DeepSeek-V3 的部署策略已实现比 DeepSeek-V2 快两倍以上的端到端生成速度,但仍存在进一步提升的空间。
DeepSeek 一直坚持长期主义的开源模型路线,旨在稳步接近 AGI 的最终目标。未来计划:
- 将持续研究和改进模型架构,旨在进一步提高训练和推理效率,努力实现对无限上下文长度的有效支持。 此外,尝试突破Transformer的架构限制,从而拓展其建模能力的边界。
- 持续迭代训练数据的数量和质量,并探索整合额外的训练信号源,旨在推动数据扩展涵盖更全面的维度范围。
- 持续探索和迭代模型的深度思考能力,旨在通过扩展其推理长度和深度来增强其智能和解决问题的能力。
- 探索更全面和多维的模型评估方法,以避免在研究过程中过度优化固定的基准。



















 3297
3297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











