






活动背景
集成电路EDA设计精英挑战赛是面向国内外高校的集成电路挑战赛,这也是国内唯一一个专注于EDA方向的专业竞赛,从本科到博士都可参赛,赛题覆盖EDA应用及算法,需要计算机、电子、物理、软件、数学、AI等知识储备,对参赛队伍的要求极具综合性。自2019年6月启动时,就受到了来自产业及高校的高度关注,产业界和学术界专家反馈,部分参赛作品具有很好的参考价值,现选出第一届获奖并参与技术征文投稿的队伍作品和大家分享。

作者介绍
1
队伍名称
IClab (第一届集成电路EDA精英挑战赛一等奖)
2
队伍成员
陈鹏 浙江大学 集成电路工程
程智杰 浙江大学 集成电路工程
马孝宇 浙江大学 电子科学与技术
3
指导教师

韩雁:博士、教授、博导。1982年毕业于浙大半导体器件专业。历任教研室主任、研究所副所长,信电系副主任、杭州国家高新技术产业开发区管委会副主任兼滨江区副区长(挂职)。中国半导体行业协会IC分会理事、中国电源学会理事、浙江省电源学会常务理事、浙江省电子学会理事。从事微电子学科及集成电路设计、功率器件设计方向的教学科研工作,承担过国家863 IC设计重大专项、国家科技重大专项(核高基)、国家自然科学基金面上项目、教育部博士点基金、工信部电子信息产业发展基金项目、浙江省重大科技专项、浙江省自然科学基金、海外合作项目、重大横向课题、企业委托项目在内的60余项科研项目。出版论著八部、译著三部。发表论文145篇(包括国际微电子学领域顶级期刊JSSC),获授权发明专利90项(含美、日专利)。
征文内容
题目:基于Innovus的数字IC的复杂层次化物理设计(Cadence篇)
1、摘要
本文基于Cadence 公司的数字IC设计软件Innovus完成了大赛指定芯片dtmf_recvr_core的从综合到物理实现的全流程设计。RTL到Netlist的综合通过Genus完成,将整个芯片划分成了7个partitions,使用hierarchy和top-down的方式对该款芯片进行了物理实现。使用QRC进行高精度的RC-extraction,最终在Tempus中完成signoff级别的STA(静态时序分析static time analysis)。在PR(布局布线)过程中创新性地使用到了signOffOpt flow来对芯片进行signoff 优化,使用 FlexILM flow 减少了top design timing enclusre的迭代次数,采用脚本的方式手动进行timing eco的修复,提高了芯片的面积利用率。
2、关键字
INNOVUS , PnR , Partition,STA
3、引言
本设计采用Cadence数字IC设计软件对一款数字芯片完成了从综合到PR的全流程物理实现,采用Hierarchical的设计方式,在时序收敛的情况下,面积优化到了762.63um x 1000um=762630um2,频率提高到了270MHz。创新性的使用了signoff,FlexILM的设计方式,简化了设计,加速了STA的收敛。
4、作品名称:
基于Innovus的复杂层次化物理设计
5、项目背景:
基于cadence数字IC设计流程完成某款大赛指定芯片从RTL到GDS的实现全过程。
6、项目成果
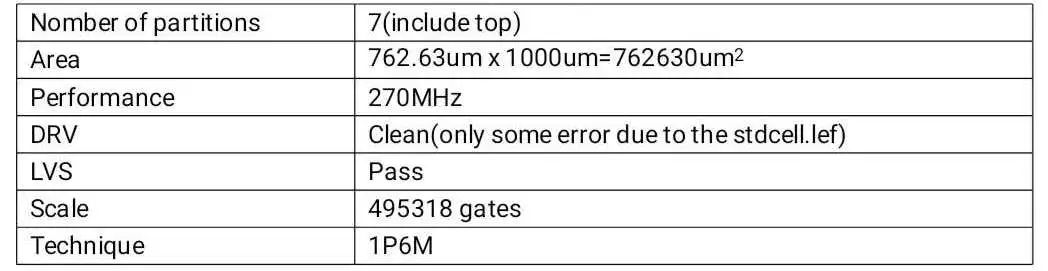
完成指标如表1所示:
表1 完成指标
芯片整体版图如图1所示:

图1 芯片整体版图
7、主要技术路线以及实现方式
主要技术路线以及实现方法:
本组在做该设计时PR的过程使用的脚本分为7步:
1_initDesign
2_Partition
3_palce
4_preCTS
5_postCTS
6_preRoute
7_postRoute
最终Signoff。其中initDesign主要包括对整个设计的初始文件配置,包括global文件、mmmc文件、global net规划、以及其他一些脚本文件调用的设置,这里不做详细描述,下面就第2步到第7步流程做详细介绍。
7.1 Partition & FlexIlm 策略
整个设计由多个dsp_core组成,根据各个dsp_core模块的连接关系,将连线关系较多的module划分到同一个partition中去。最终划分了7个partition(包括顶层),划分后的partition的连接关系图如图2所示,可以看到具有逻辑连接的module已经划分到同一个partition中。与top 有连接关系的partition放置到了合理的位置。
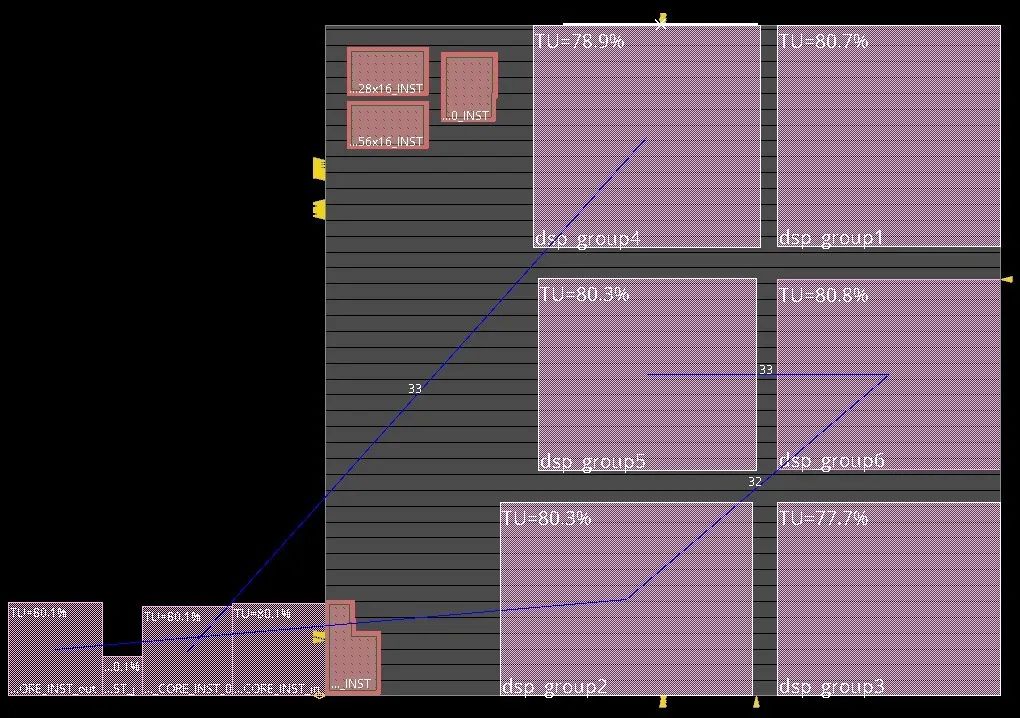
图2.partition划分
(紫色模块为partition,粉色模块为macro)
在初期的划分过程中,只是初步规划了各个partition的大小、位置、并没有做详细规划。因为考虑到后期使用FlexILM,可以在具体实现partition PR的时候来分别对每个partiton进行优化。FlexILM实现方法是,在底层固定好floorplan和pin,在完成preCTS后,出FlexILM接口文件交给顶层来做整体PR。顶层在做PR的时候,允许route对partition pin 和 partitionHornrFence进行修改,产生的接口修改信息通过update_partition –flexIlmEco来交给底层。这样做大大缩小了assemble顶层时的timing consulre 迭代次数。最终做出来在时序收敛的情况下每个partition的面积利用率均达到了80-85%。
最终6个partition的PR版图如图3所示。
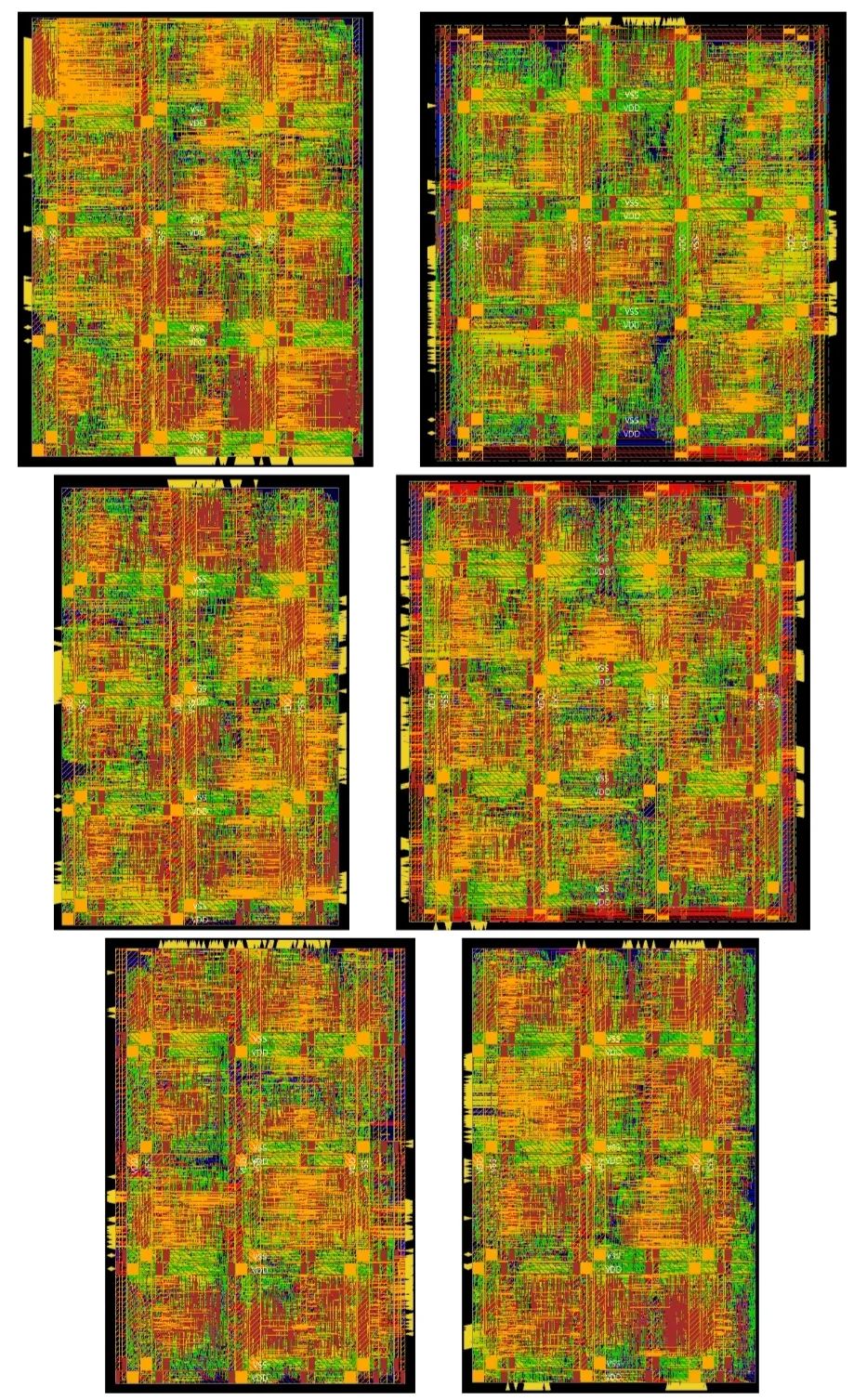
图3.partition 1-6的layout图
7.2 Place
Place阶段主要做芯片macro的摆放与电源网格的规划。电源采用M6(V-垂直),M5(H-水平),M4(V-垂直)来做power strip,physical pin 出自于M6与M5。Power rail由M2连接到M4以及各个partitions的block ring上,这样做可以保证整个网络电源分配的均匀,最大程度降低IR-drop,同时也提高了芯片走线效率。TopCell的floorplan如图4所示:
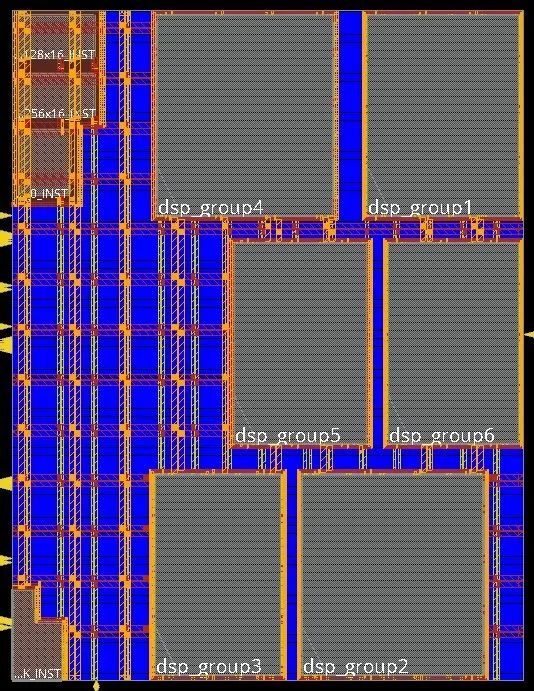
图4.芯片整体的floorplan
规划floorplan的面积时,采用了一种可以获得较为准确利用率的估算方法。首先,使用place_design将stand cell大致排布上去,这个过程中需要打开drc_check,global_fast_cts,detail_route,timingDrive等开关来进行place预估,这样可以大致得到一个place的utilization。接着使用optDesign –preCTS对上一步的place进行优化,通过这一步得到的utilization更为准确,最后根据这个utilization来指定芯片的面积,经多个partition验证,这种方法预估的utilization与signoff之后的utilization仅仅相差3-5个百分点。
7.3 PreCTS
PreCTS阶段的任务是在做时钟树之前,对place阶段的stand cell进行DRV和setup的初步修复。这个阶段可以将opt_design的密度设置得高一点,holdTargetSlack和setupTargetSlack设置得高一点,来最大力度的修复一些DRV还有setup违规,最好在CTS之前将DRV清理干净。该芯片在设计时将初始的利用率设置得较高,增加了一些cellPad来使得后期的timing更易收敛。
7.4 PostCTS
PostCTS阶段需要完成整个时钟树的生成。为了最大程度的提高布线资源的利用率,降低时钟树的skew,top_rule采用M6-M5,2倍线宽,2倍间距,trunk_rule采用M5-M4,2倍线宽,2倍间距来走线,leaf采用M3-M2,2倍线宽来走线。为了避免时钟树多级生长,通过max_fanout来限制时钟树的级数过长,最终的时钟树如图5所示。该设计最大的skew为0.082 ns,时钟树较为平衡,有利于后期的时序收敛。
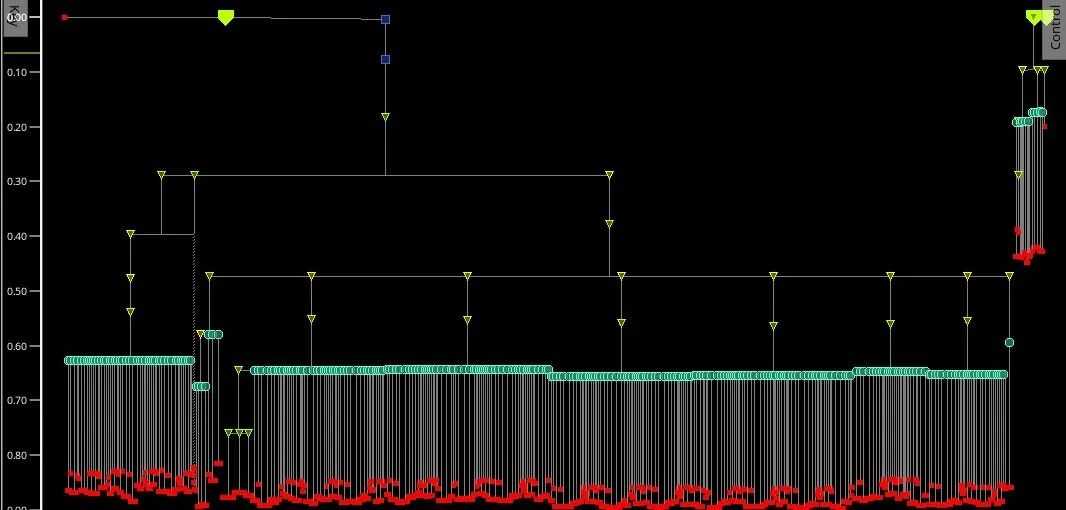
图5.整体时钟树
7.5 Preroute
Preroute阶段主要修复生成时钟树之后设计中存在的一些DRV违规,通过optDesign对setup和hold进行更近一步的优化。这个过程中,maxDensity可以进一步提高,适当的降低holdTargetSlack,setupTargetSlack的指标来更好的实现DRV的修复和时序的收敛。尽管OptDesign可以一次性修复DRV、setup、hold违规,为了获得最好的修复效果,采取分步修复的方式,依次修复DRV,setup,hold违规 。
7.6 Postroute
Postroute阶段是对芯片进行全局的route,此时的extraction模式设置为medium,来进行更准确的寄生参数抽取,此时PR已经完成了大多数的步骤,maxDensity的密度可以进一步提高,如果在这个阶段依旧出现了一些hold和DRV违规,需要手动进行修复,这阶段同时还可以做SI分析,由于赛题并未提供相关的文件,所以忽略这个步骤。
7. 7Signoff
SignOff的阶段采用的是innovus的signoffDesign流程,包括QRC的寄生参数提取和Tempus的STA分析。Signoff将extraction的等级提高到high,采用的是GBA的方法来做Signoff的STA。首先通过setSignOffOptMode –preStaTcl 将Tempus的脚本映射过来,通过signoffOptDesign –hold | -setup | -drv来进行signoff的修复。时序收敛之后,DRV,LVS通过之后,再对整体设计插入filler和metal filler 来提高设计密度,增加设计良率。
8、主要创新点
FlexILM flow
1.在partition模块中创建FlexILM文件
CreateInterfaceLogic –dir flexIlm_signoff –useType flexIlm –optStage postCTS
2.在顶层中导入这些FlexILM文件
Commit_module_model –flex_ilm {dsp_group1 ./ptn/dsp_grou1/flexIlm_signOff} \
-flex_ilm {dsp_group2…..}
-mmc_file ./ptn/dtmf_recver_core/viewDefition.tcl
3.顶层PR时允许对partition内部进行pin的修改
setRouteMode –earlyGlobalRoutePartitionHonorPin false –eatlyGlobalRoutePartitionHonorFence true
4.设置优化策略可以对partition进行优化
SetOptMode –handlePartitionComplex true
5.进行PR
6.将修改过后的partition文件更新回去
Update_partition
参赛队伍采访
参赛队伍:IClab队
比赛之前从没有接触过hierarchical 的设计方式, 初拿到赛题,充满惊喜与挑战,惊喜的是终于有机会接触这种复杂的设计方式,挑战在于赛题设计方法开放性大,要在细节处雕刻才能做出最优的PPA。最终经过团队的不懈努力,终于摸着石头过了河,突破了自我,交出了令人满意的答卷。衷心感谢组委会提供了这场集成电路EDA精英竞争的平台,也感谢Cadence公司提供接触先进的集成电路设计EDA工具的机会。
指导老师:浙江大学韩雁教授
业界一般认为Cadence软件主打模拟IC设计(根据自动化与人工参与程度的相互关系,我更喜欢叫它CAD工具),Synopsys软件主打数字IC设计(同理,我更喜欢叫它EDA工具)。本文介绍的却是用Cadence公司的Innovus软件来设计数字IC的一个全流程。虽然各种EDA软件各有所长,但从用户的角度来讲,也还是能够发现一些美中不足的。这里陈列出一些BUG,是希望今后我们的国产IC设计工具能够克服这些问题,做得比国外产品更好。
1. 模拟IC设计工具
1.1 如果在不同的library下面取相同的cell名字,那么在对A library中的某一cell下的layout做LVS时,有可能会识别到B library中相同cell名字下的layout上去。
1.2 用Stb做系统稳定性仿真时,在差分放大器反馈环路中插入diffstbprobe单元,仿真出来的系统稳定性和时域仿真的结果会不相吻合,比如用前者仿真结论是稳定的,但用后者仿真的结果却是不稳定的。
2. 数字IC设计工具
2.1 在数字IC仿真的源代码中,如果忘记写stop语句,系统不会发现和提示,直至发生仿真数据把整个内存占满造成死机的后果。
2.2 数字IC的规模很重要,但从目前的设计工具中,无法直接获得以逻辑门为单位或者以晶体管数为单位的数字IC的规模大小。
2.3 数字IC在完成综合后,不能进行时序仿真,以观察此时的工作频率能达多少。而这种需求的目的是,想研究单纯逻辑门造成的延时和最终布局布线后加上连线延时的总延时究竟会相差多少。
寄语:愿EDA大赛伴随国产EDA一起成长,将和历届参赛师生们一起,书写和见证中国EDA从小到大、从弱到强的历史。
















 2515
2515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









