







置信域方法总结——TRPO、ACER、ACKTR、PPO
一、概述
引用GAE论文的观点,策略梯度法存在的两个方面问题:
- 样本利用率低,由于样本利用率低需要大量采样;
- 算法训练不稳定,需要让算法在变化的数据分布中稳定提升;
目前比较常用的四种置信域方法TRPO、ACER、ACKTR、PPO,就是围绕策略梯度法的上述两方面问题进行改进和优化。
| 算法 | TRPO | ACER | ACKTR | PPO |
|---|---|---|---|---|
| 稳定性问题 | 置信域方法 | 简化的置信域方法 | 基于Kronecker分解的置信域方法 | clip优化目标 |
| 样本利用率问题 | ~ | off-policy更新 | K-FAC近似的自然梯度法 | 多epoch小批量优化 |
二、算法简介
2.1 TRPO
由于强化学习中数据分布是变化的,策略梯度法使用不合适的步长设定会导致训练很不稳定,TRPO的置信域方法就是为了解决步长设计的问题,通过控制步长最大化优化目标,能保证算法单调,能够解决算法训练的稳定性问题。
缺点是需要计算多次Fisher线性矩阵,计算量大,训练速度慢,无法应用到大规模问题中。
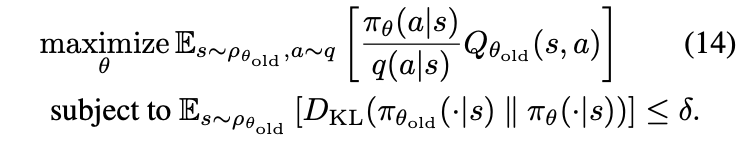
2.2 ACER
ACER的能进行on-policy和off-policy的更新,大大提高了样本利用效率,主要使用了四个技术:
-
截断重要性采样,控制方差的同时保证了无偏性;
-
Q_retrace的使用,提高了off-policy值函数估计的稳定性;
-
stochastic dueling network,SDN,用于连续动作控制算法值函数估计;
-
一种新的置信域方法,计算简单,适合大规模问题。
具体见我另一篇博客:知乎
2.3 ACKTR
ACKTR算法的核心是使用KFAC算法进行优化,K-FAC能够在较短的时间内近似出Fisher矩阵,每次更新所需的时间只比SGD多10~20%,因此能够使用自然梯度对模型进行更新。自然梯度法是二阶优化,相比SGD对单样本利用率更高,从而提高了样本利用率。K-FAC分解如下图所示:

2.4 PPO
PPO使用clip的方法对前后策略变化进行限制,格式简单且运算效率高,能够用于大规模问题,对数据的小批量多次更新也提高了数据利用效率,PPO是目前业界比较主流的算法。
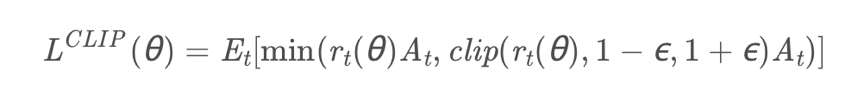
这次读论文的时候发现了,PPO在clip的时候取最小min是因为TRPO的优化目标函数是累计奖励值的下界,通过最大化下界来最大化累计奖励值,理论上不能将下界放大,所以取min。因此对腾讯提出的dual PPO就保持怀疑态度,但是由于clip ratio本身也改变了原优化问题的范围,通过进一步的clip将大的负数部分clip掉对于训练也是有好处的,可能更加稳定。















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









