







本文整理自知乎问答,仅用于学术分享,著作权归作者所有。 如有侵权,请联系后台作删文处理。 观点一加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者|Guohao Li
https://www.zhihu.com/question/366088445/answer/1023290162
来说一下自己的理解。 首先结论是大部分GCN和Self-attention都属于Message Passing(消息传递)。GCN中的Message从节点的邻居节点传播来,Self-attention的Message从Query的Key-Value传播来。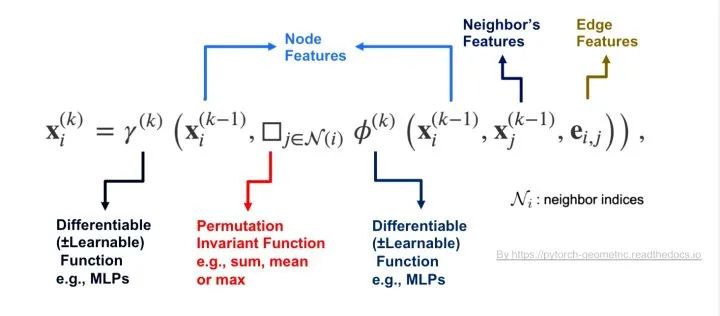 Message Passing[4] 先看看什么是Message Passing。我们知道在实现和设计GCN的时候很多时候都是采用Message Passing的框架[3],其思想是把每个节点的领域的特征信息传递到节点上。在这里举例描述一个节点i在第k层GCN卷积的过程: 1)把节点i的每一个邻居j与该节点的特征经过函数变换后形成一条Message(对应公示里函数\phi里面的操作); 2)经过一个Permutation Invariant(置换不变性)函数把该节点领域的所有Message聚合在一起(对应函数\square); 3)再经过函数\gamma把聚合的领域信息和节点特征做一次函数变化,得到该节点在第k层图卷积后的特征X_i。 那么Self-attention是否也落在Message Passing的框架内呢?我们先回顾一下Self-attention一般是怎么计算的[2],这里举例一个Query i的经过attention的计算过程: 1
Message Passing[4] 先看看什么是Message Passing。我们知道在实现和设计GCN的时候很多时候都是采用Message Passing的框架[3],其思想是把每个节点的领域的特征信息传递到节点上。在这里举例描述一个节点i在第k层GCN卷积的过程: 1)把节点i的每一个邻居j与该节点的特征经过函数变换后形成一条Message(对应公示里函数\phi里面的操作); 2)经过一个Permutation Invariant(置换不变性)函数把该节点领域的所有Message聚合在一起(对应函数\square); 3)再经过函数\gamma把聚合的领域信息和节点特征做一次函数变化,得到该节点在第k层图卷积后的特征X_i。 那么Self-attention是否也落在Message Passing的框架内呢?我们先回顾一下Self-attention一般是怎么计算的[2],这里举例一个Query i的经过attention的计算过程: 1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1935
1935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









