






点击上方,选择星标或置顶,每天给你送干货 !
!
阅读大概需要10分钟
跟随小博主,每天进步一丢丢


每日英文
There is a wholeness about the person who has come to terms with his limitations.
人生的完整在于一个人知道如何面对他的缺陷。
Recommender:云不见
作者:老宋的茶书会
方向:自然语言处理
知乎:https://zhuanlan.zhihu.com/p/69101372
编辑:王萌 澳门城市大学(深度学习自然语言处理公众号)

一、前言
最近分类问题搞的有点多,但对一些指标依旧有模糊的地方(虽然做了笔记), 事实证明, 笔记笔记,没有进到脑子里呀。因此,我想着肯定有跟我一样半生半熟的小伙伴在分类指标这块依旧有迷惑,毕竟常用的几个大多数情况下就够用了, 这篇文章就主要讲一讲分类的评估指标。
二、几个定义:混淆矩阵
TP:True Positives, 表示实际为正例且被分类器判定为正例的样本数
FP:False Positives, 表示实际为负例且被分类器判定为正例的样本数
FN:False Negatives, 表示实际为正例但被分类器判定为负例的样本数
TN:True Negatives, 表示实际为负例且被分类器判定为负例的样本数
一个小技巧, 第一个字母表示划分正确与否, T 表示判定正确(判定正确), F表示判定错误(False);第二个字母表示分类器判定结果, P表示判定为正例, N表示判定为负例。
三、几个常规的指标
Accuracy:
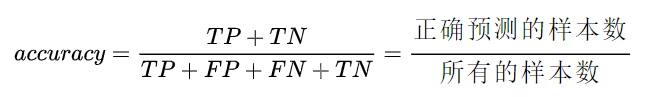
Accuracy 能够清晰的判断我们模型的表现,但有一个严重的缺陷:在正负样本不均衡的情况下,占比大的类别往往会成为影响 Accuracy 的最主要因素,此时的 Accuracy 并不能很好的反映模型的整体情况。
Precision:
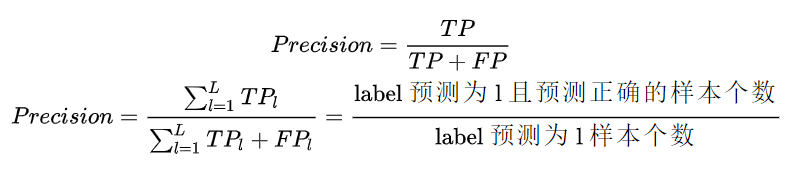
Recall:

Precision 与 Recall 的权衡
精确率高,意味着分类器要尽量在 “更有把握” 的情况下才将样本预测为正样本, 这意味着精确率能够很好的体现模型对于负样本的区分能力,精确率越高,则模型对负样本区分能力越强。
召回率高,意味着分类器尽可能将有可能为正样本的样本预测为正样本,这意味着召回率能够很好的体现模型对于正样本的区分能力,召回率越高,则模型对正样本的区分能力越强。
从上面的分析可以看出,精确率与召回率是此消彼长的关系, 如果分类器只把可能性大的样本预测为正样本,那么会漏掉很多可能性相对不大但依旧满足的正样本,从而导致召回率降低。
四、F1-Score
F1-Score 能够很好的评估模型,其主要用于二分类问题, 计算如下:
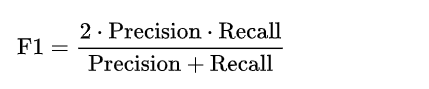
而 更一般的有  :
:

其实,  本质上是Recall, Precision 权重比, 当
本质上是Recall, Precision 权重比, 当  时,
时,  表明 Recall 的权重要比Precision高,其影响更大, ;当
表明 Recall 的权重要比Precision高,其影响更大, ;当  时,
时,  表明 Recall 的权重要比Precision低, 对应的影响更小;
表明 Recall 的权重要比Precision低, 对应的影响更小;
前面提到 F1 针对的是二分类,而更一般的是,对于多分类问题来说, F1 的计算有多种方式,可以参见 Scikit-Learn 中的评价指标,我们来分别介绍一下。
对于一个多分类问题,假设,对于分类  而言有:
而言有:  , 那么各种 F1 的值计算如下。
, 那么各种 F1 的值计算如下。
Macro F1: 宏平均
Macro 算法在计算 Precision 与 Recall 时是先分别计算每个类别的Precision 与 Recall, 然后再进行平均。
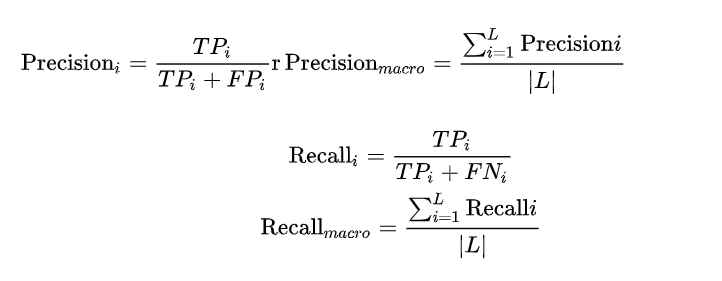
那么我们就得到最终的 Macro F1 的计算为:

我们看到, Macro F1 本质上是所有类别的统计指标的算术平均值来求得的,这样单纯的平均忽略了样本之间分布可能存在极大不平衡的情况
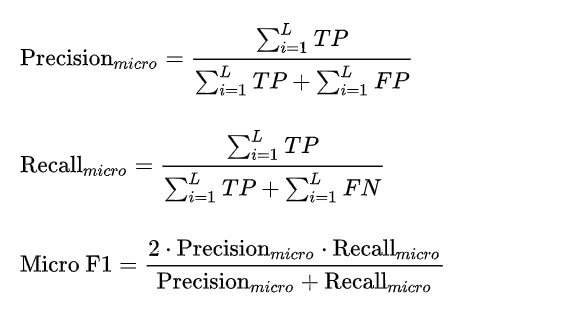
Micro F1 :微平均
Micro 算法在计算 Precision 与 Recall 时会将所有类直接放到一起来计算。
Macro vs Micro [1]
Macro 相对 Micro 而言,小类别起到的作用更大,举个例子而言,对于一个四分类问题有:
class A:1 TP, 1 FP
class B:10 TP , 90 FP
class C:1 TP, 1 FP
class D:1 TP, 1 FP
那么对于 Precision 的计算有:
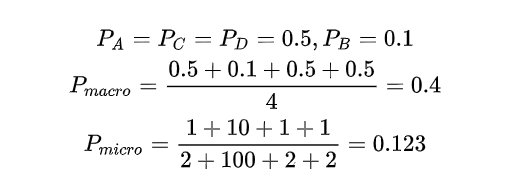
我们看到,对于 Macro 来说, 小类别相当程度上拉高了 Precision 的值,而实际上, 并没有那么多样本被正确分类,考虑到实际的环境中,真实样本分布和训练样本分布相同的情况下,这种指标明显是有问题的, 小类别起到的作用太大,以至于大样本的分类情况不佳。而对于 Micro 来说,其考虑到了这种样本不均衡的问题, 因此在这种情况下相对较佳。
总的来说, 如果你的类别比较均衡,则随便;如果你认为大样本的类别应该占据更重要的位置, 使用Micro;如果你认为小样本也应该占据重要的位置,则使用 Macro;如果 Micro << Macro , 则意味着在大样本类别中出现了严重的分类错误;如果 Macro << Micro , 则意味着小样本类别中出现了严重的分类错误。
为了解决 Macro 无法衡量样本均衡问题,一个很好的方法是求加权的 Macro, 因此 Weighed F1 出现了。
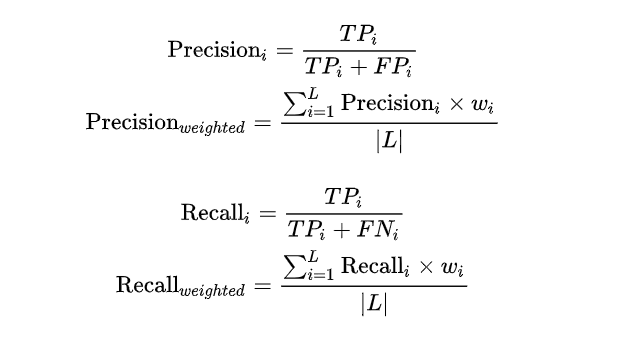
Weight F1
Weighted 算法算术 Macro 算法的改良版,是为了解决Macro中没有考虑样本不均衡的原因, 在计算 Precision与Recall 时候,各个类别的 Precision 与 Recall要乘以该类在总样本中的占比来求和:
那么我们就得到最终的 Macro F1 的计算为:

五、MCC :马修斯相关系数
MCC 主要用于衡量二分类问题,其综合考虑了 TP TN, FP , FN, 是一个比较均衡的指标, 对于样本不均衡情况下也可以使用。MCC的取值范围在[-1.1],取值为1表示预测与实际完全一致, 取值为0表示预测的结果还不如随机预测的结果,-1表示预测结果与实际的结果完全不一致。因此我们看到, MCC 本质上描述了预测结果与实际结果之间的相关系数。
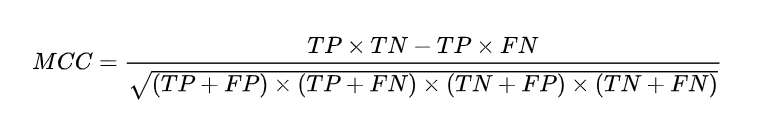
值得注意的是,对于两个分类器而言,可能其中一个分类器的 F1 值较高,而其 MCC 值较低, 这表示单一的指标是无法衡量分类器的所有优点与缺点的。
六、ROC 曲线
在分类任务中,测试部分通常是获得一个概率表示当前样本属于正例的概率, 我们往往会采取一个阈值,大于该阈值的为正例, 小于该阈值的为负例。如果我们减小这个阈值, 那么会有更多的样本被识别为正类,这会提高正类的识别率,但同时会降低负类的识别率。
为了形象的描述上述的这种变化, 引入ROC曲线来评价一个分类器的好坏。ROC 曲线主要关注两个指标:
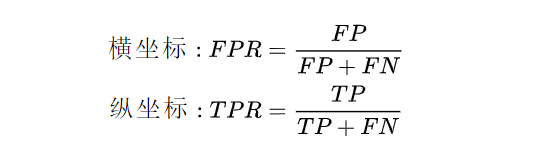
其中, FPR 代表将负例错分为正例的概率, TPR 表示能将正例分对的概率, 如果我们增大阈值, 则 TPR 会增加,而对应的FPR也会增大, 而绘制ROC曲线能够帮助我们找到二者的均衡点,下图很清晰的描述了ROC 曲线关系:

在 ROC 曲线中, 有:
FPR = 0, TPR = 0:表示将每一个实例都预测为负类
FPR = 1, TPR = 1:表示将每一个实例都预测为正例
FPR = 0, TPR = 1:为最优分类点
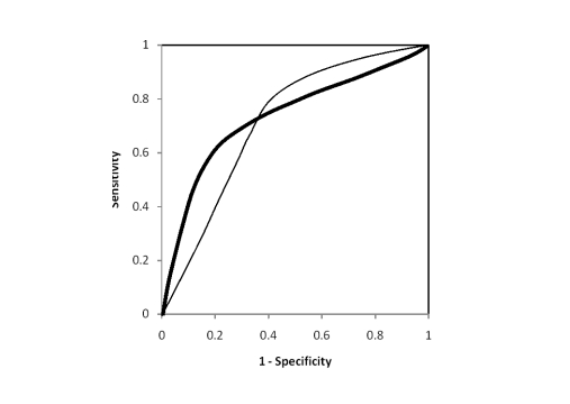
分类器对应的ROC曲线应该尽可能靠近坐标轴的左上角, 而对角线的位置意味着分类器的效果和随机猜测一样的差。
ROC曲线在测试集中的样本分布发生变化的时候能够保持不变。但遗憾的是,很多时候, ROC 曲线并不能清晰的说明哪个分类器的效果更好, 而 AUC 恰恰能够对分类器做出直观的评价。
七、AUC:Area under Curve
AUC 为ROC 曲线下的面积, 这个面积的数值介于0到1之间, 能够直观的评价出分类器的好坏, AUC的值越大, 分类器效果越好。
AUC = 1:完美分类器, 采用该模型,不管设定什么阈值都能得出完美预测(绝大多数时候不存在)
0.5 < AUC < 1:优于随机猜测,分类器好好设定阈值的话,有预测价值
AUC = 0.5:跟随机猜测一样,模型没有预测价值
AUC < 0.5 :比随机猜测还差,但是如果反着预测,就优于随机猜测。
值得一提的是,两个模型的AUC 相等并不代表模型的效果相同, 比如这样:
实际场景中, AUC 的确是非常常用的一种指标。
需要注意的是, 在多分类场景下的 ROC 曲线以及 AUC 值, 此时 ROC 曲线应该有多个, 而AUC 的计算如下:
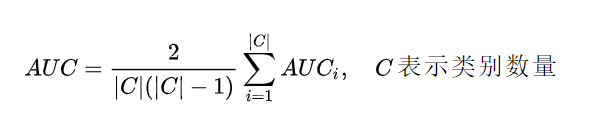
八、P-R 曲线
P-R 曲线其横坐标为 Recall, 纵坐标为 Precision, 其能帮助我们很好的做出权衡
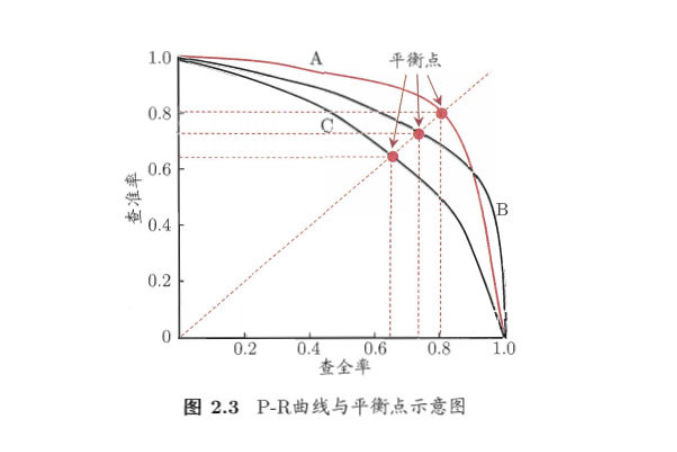
在上图中,我们发现, A 完全包住了C, 着意味着A 的Precision 与 Recall 都高于C, A优于C。而对比 A,B, 二者存在交叉的情况,此时采用曲线下面积大小衡量性能,面积越大,性能越好,此处的A优于B。
九、最后
对于最终分类指标的选择, 在不同数据集,不同场景,不同时间下都会有不同的选择,但往往最好选出一个指标来做优化,对于二分类问题,我目前用 AUC 比较多一些, 多分类我还是看 F1 值。
十、Reference
[1] Should I make decisions based on micro-averaged or macro-averaged evaluation measures? [2] Micro Average vs Macro average Performance in a Multiclass classification setting> [3 机器学习性能评估指标说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
专辑 | NLP论文解读

整理不易,还望给个在看!














 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









