







2024年12月,IBM推出化学大模型SMI-TED(SMILES-based Transformer Encoder-Decoder):可精准预测分子性质和行为,标志着化学分子预测领域的一项重要技术进展。
huggingface开原链接: https://huggingface.co/ibm-research/materials.smi-ted
文章链接:SMI-TED: A large-scale foundation model for materials and chemistry | OpenReview
技术原理
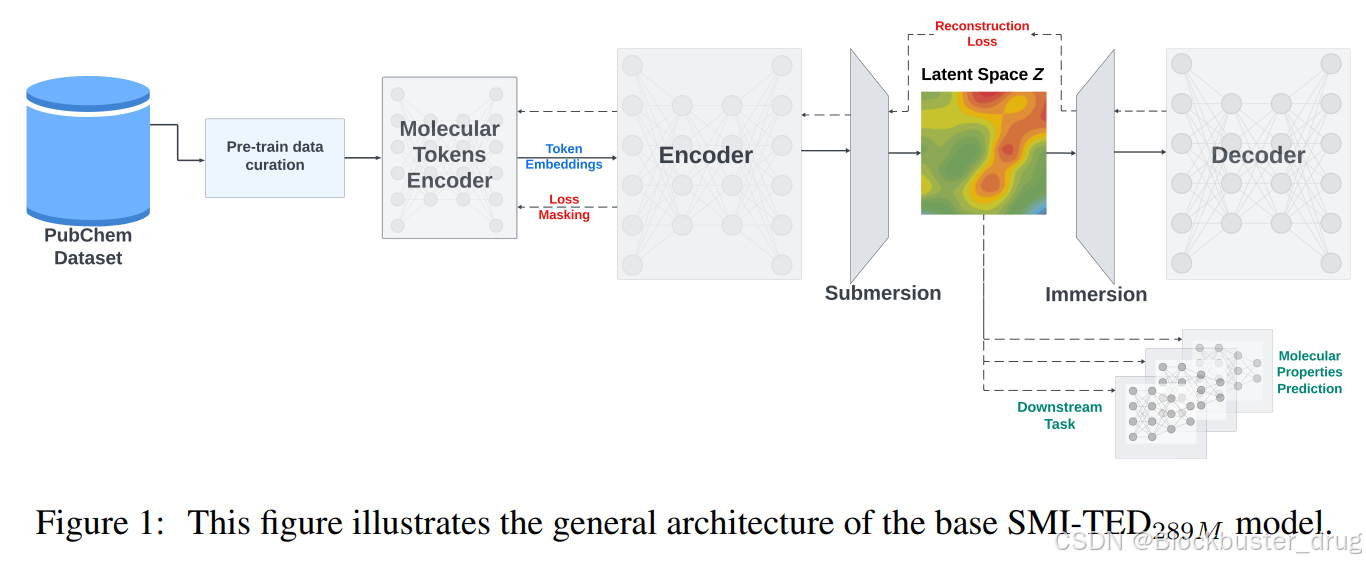
核心架构:SMI-TED 的技术核心在于其深度双向变压器编码器架构。通过对 SMILES 字符串的精准解析,能够理解分子间复杂的关系。编码器负责将输入的分子信息转换为潜在的表征形式,解码器则根据这些信息逐步生成 SMILES 字符串,确保生成的分子信息准确且连贯。
预训练策略:采用双阶段预训练策略。最初阶段主要针对标记编码器进行预训练,以保证模型的稳定性。当编码器达到收敛标准时,整个模型便开始更为复杂的训练过程,此时可以利用所有样本,同时参与编码器与解码器的参数学习,使模型深入学习分子标记之间的关系,掌握将标记快速且准确地组合成完整分子结构的方法。
数据基础
该模型通过分析全球最大的公共化学物质结构数据库 PubChem 中的 9100 万个分子数据进行预训练,相当于 40 亿个分子标记。IBM 的研究团队从 PubChem 数据库中筛选出了 1.13 亿条 SMILES 字符串,经过去重和清洗,最终构建出 9100 万个有效的分子结构,为模型的精准预测提供了坚实的数据支持。
应用领域
药物开发:在药物的活性和性质预测上与实际值高度吻合,能够帮助研发人员快速筛选出具有潜在活性的药物分子,缩短药物研发周期,降低研发成本。还在化合物的毒性预判方面表现出色,为药物安全性评估提供了可靠支持,有助于提前发现潜在的毒性风险,避免在后期临床试验中出现严重的安全问题。
新材料发现:能够生成具有特定性质的新型分子结构,助力科学家对新材料的设计和开发,为寻找性能更优的新材料提供了有力的工具,推动材料科学领域的发展。
SMI-TED的训练过程分为两个阶段。
初期,模型采用掩蔽语言模型(Masked Language Model, MLM)策略训练编码器部分,掩蔽部分token,并利用95%的数据集来优化token编码器,5%用于解码器训练。这一策略加速了训练进程,同时避免了初期阶段编码器与解码器收敛不一致的问题。随着token嵌入的逐步收敛,训练规模扩大,最终100%的数据集被用来进行编码器与解码器的联合训练,显著提升了模型的整体表现。
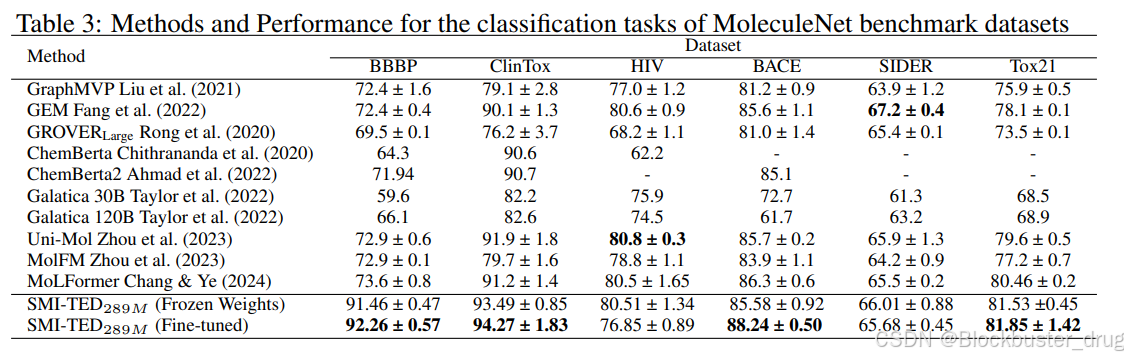
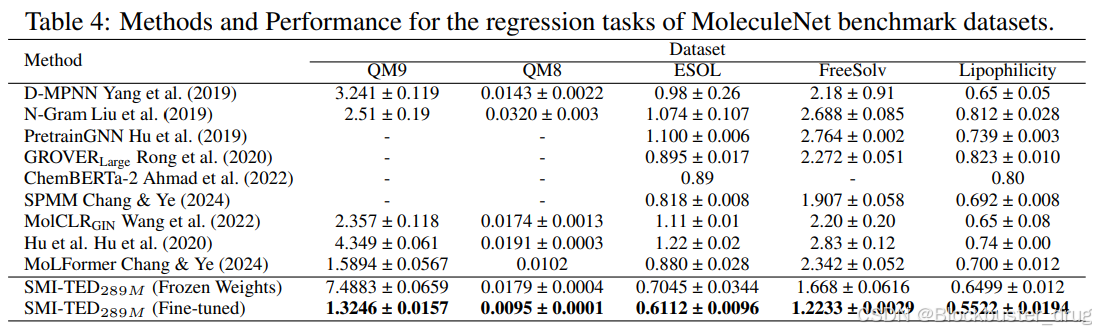 在功能应用方面,SMI-TED支持分子分类、回归和量子力学属性预测等多种化学任务。IBM在多个标准化化学数据集上进行评估,结果表明该模型在分类和回归任务中均达到最前沿的性能。尤其在量子属性的预测方面,SMI-TED凭借深度学习的优势,展现出比传统方法更加精确的预测能力,为化学领域的深入研究提供了强有力的支持。
在功能应用方面,SMI-TED支持分子分类、回归和量子力学属性预测等多种化学任务。IBM在多个标准化化学数据集上进行评估,结果表明该模型在分类和回归任务中均达到最前沿的性能。尤其在量子属性的预测方面,SMI-TED凭借深度学习的优势,展现出比传统方法更加精确的预测能力,为化学领域的深入研究提供了强有力的支持。
进一步提升计算效率和精度的SMI-TED变种(如SMI-TED8x289M)也随之推出,这些变种引入了“专家网络”机制。该策略通过稀疏激活专家模型,在处理特定任务时动态调整计算资源的分配,从而提高了模型的灵活性和泛化能力,尤其在面对不同化学任务时,能够更好地适应多样化需求。
SMI-TED的广泛应用前景令人期待,特别是在药物研发和材料科学领域。其强大的分子生成与预测能力,将极大地推动新分子设计和化学反应的发现。借助SMI-TED,研究人员不仅能够更准确地模拟分子的物理化学性质,还可以在未探索的分子空间中寻找潜在候选物质,从而为科学研究提供了更加高效、可扩展的工具。
为了测试SMI – TED的性能,研究人员在ChEMBL、Tox21、ToxCast、ZINC、QM9等子数据集进行了综合评测。
结果显示,SMI - TED 在这些子数据集上表现出了优异的性能。例如,在 ChEMBL 数据集中,SMI - TED 能够准确地预测分子的活性和性质,其预测结果与实际值之间的误差较小;在Tox21 和 ToxCast 数据集中,模型对化合物的毒性预测表现出色,为药物安全性评估提供了有力的支持;
在 ZINC 数据集中,SMI - TED 在分子生成任务中展现出了强大的能力,能够生成具有特定性质的新颖分子结构
在量子化学方面,在 QM9 数据集中,模型对分子的量子力学性质的预测精度较高,为理解和设计新型材料提供了重要的参考。
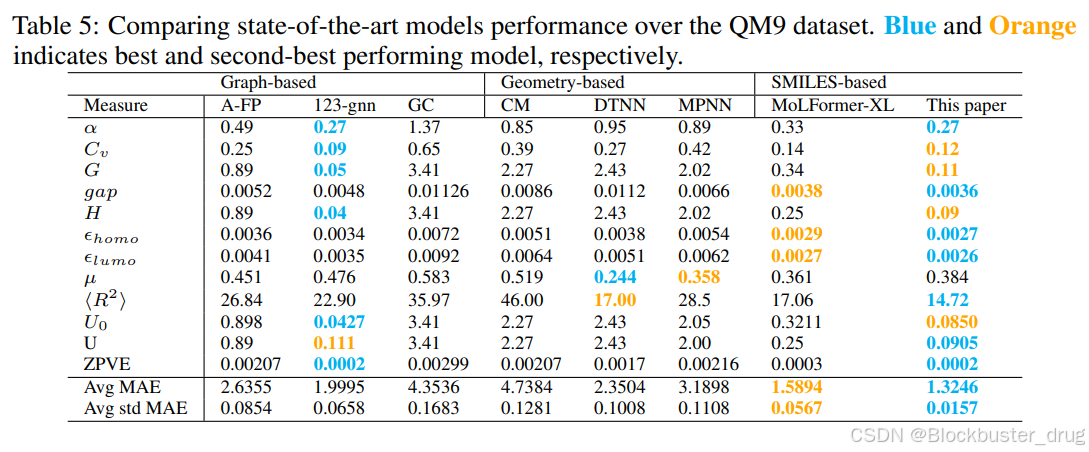
本文介绍了SMI-TED289M系列化学基础模型,这些模型在包含9100万个SMILES样本的精心策划的数据集上进行了预训练,共计40亿个分子标记。SMI-TED289M系列包括两个配置:一个拥有2.89亿参数的基础模型和一个由8×2.89亿参数组成的MoE-OSMI模型。
通过在不同任务上的广泛实验评估了这些模型的性能,包括分子属性分类和预测。我们的方法在大多数任务中取得了最先进的成果,特别是在预测分子量子力学方面,在QM9数据集的12个任务中的11个中获得了最佳或第二佳的结果。
一个关键结果是,该模型在反应产率预测的各种数据分割上的稳健性,尤其是在仅使用一小部分数据集进行训练的低资源设置下。这强调了利用大规模预训练来编码通用化学知识的重要性,然后可以针对特定任务(如反应产率预测)进行微调。
相比之下,专门为特定任务设计的模型倾向于过度拟合训练数据的细微差别,并且在训练集大小减少时难以泛化,凸显了它们设计中的一个关键局限性。
我们还研究了这些基于语言的基础模型创建的潜在空间的结构,为了清晰起见使用了简单的化学结构。SMI-TED289M生成了一个嵌入空间,它为每个家族创造了良好的分离,并尊重层次距离结构,几乎在每个家族之间建立了线性关系。编码器-解码器模型在少量学习方面的能力得到了评估。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











