







初始配置工作
这时候刚开始配置。也就是一开始用了python3.8,对于高等级的pytorch不方便,后来换成3.9就好了。在RTX3090上,CUDA最低也要11.1,对应的pytorch也更高,所以尽量用python3.9。
然后就是 MinkowskiEngine 和 pytorch3d 的安装。
MinkowskiEngine 用的是这个教程:链接。
编译过程遇到bug,nvcc fatal : Unsupported gpu architecture ‘compute_86‘。
解决方法:在命令行输入export TORCH_CUDA_ARCH_LIST="8.0"后,再编译。
一开始我输入的是
export TORCH_CUDA_ARCH_LIST="7.5",其实对于RTX3090来说,这个是错误的,应该是8.0。详细原因后面会解释。
pytorch3d一开始参考官方github,按上面说的要整一大堆好几步,特别麻烦。我下载完之后编译,又没用。搞了半天,最后尝试conda install pytorch3d,居然就可以了。
这里给官方的github指引一个差评。
不过,conda install pytorch3d 这个并不准确。正经的做法应该是,进入conda的官网 https://anaconda.org/,搜索pytorch3d,在那里会有正经的命令指导(也是一行命令就搞定)。
这样配置完之后,兴冲冲去运行 sh scripts/train_kitti_det.sh,发现数据集不对。原来还要自己下载数据集。
数据集配置
KITTI官网特别难连接,即使科学上网,也还是无法下载。尝试用wget也没用。最后,还是在百度云上找到的资源。
在这里为后来人做一个分享。
链接:https://pan.baidu.com/s/1srmHOuUJb6eKoQ-vJ-dzOQ
提取码:t5ec
解压之后是80G左右,请预留空间。
一共要下载三个文件,除了这个最大的,还有两个。不过这两个只有1M左右,我也忘了我是怎么下的了,反正这种小文件很好下(好像是直接官网下的?反正这个没用到云盘)。

把三个文件解压后,放在各自的位置上(工程的github上有图展示他们的文件结构),这样数据集就搞定了。
漫长踩坑
继续去跑 sh scripts/train_kitti_det.sh,报错:
UserWarning: resource_tracker: There appear to be 6 leaked semaphore objects to clean up at shutdown warnings.warn('resource_tracker: There appear to be %d '
解决方案请直接往下拉。这中间记录我的 debug 历程,如果你跟我的问题其实不同,有这个思路可以帮助你查出自己的问题。
去谷歌这个的成因,大多数是说你的 batchsize 太大,numworker 太多,加载的东西太多,内存爆了。可是我 batchsize 设为1,numworker 设为1,还是没用。
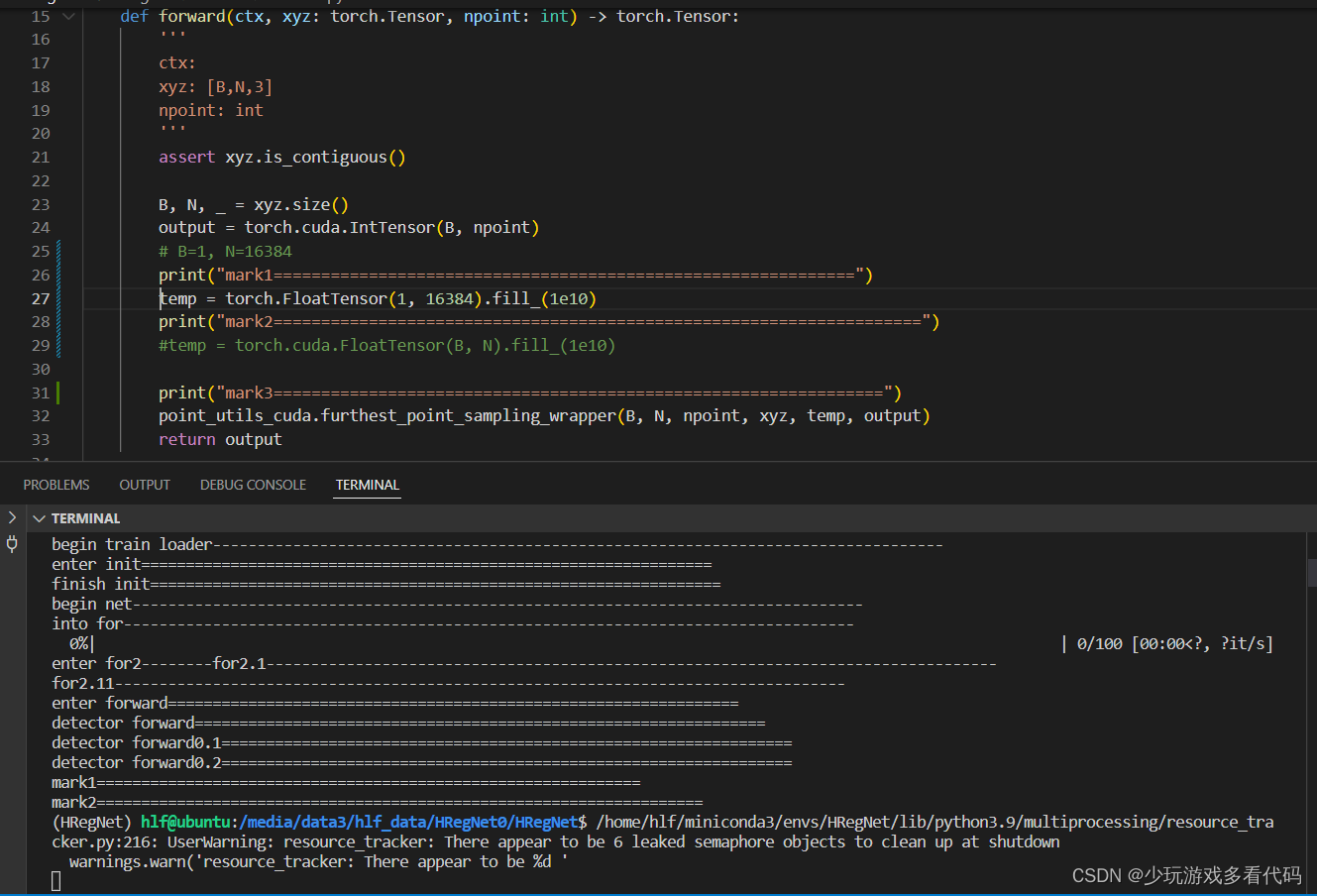
耐心寻找出问题的地方,用 print 在执行的代码中一行行打印,看看它运行到哪里停止。一步步递进,发现在 utils.py 的temp = torch.cuda.FloatTensor(B, N).fill_(1e10) 这一行,程序停止了(如上图)。
把这行代码复制到自己电脑上运行,发现可以运行。所以代码本身是没问题的,并不是因为这段代码需求过多资源,才导致程序停止。
然后针对这个代码进行多种尝试,比如将B和N替换成对应的数字,或者更小的数字。又比如,在上方再加一个同样的代码,看看程序会不会运行到上一个就停下。
经过十几次的测试后,结果非常诡异。甚至出现只打印到第一个log,第一个log和第二个log之间什么都没有,但是就是不打印第二个log。两个连续的print还可以只打印第一个的??
这个测试结果我无法解释,也因此困扰了好几天无从下手。
中间还学习了 top 命令展示的各种参数的含义,多开几个终端,用 top 监控我程序运行时的内存和显存变化,发现根本不存在什么内存爆了的问题。
没办法,继续回去谷歌查报错,细看其他的原因。有的回答说什么 shared memory 的构成和销毁机制啥的,吃力啃完还是没用。只学会了一招:去 warning 文件的 print 里(这个直接在报错信息ctrl+左键就能跳转过去)添加打印 os.pid(),可以看看是哪个进程让他触发这个报错。
用这个方法,我发现,warning 报错的进程,和我 util.py 里的那个进程不是同一个进程。所以并不是我的程序让他出现这个报错的。
再一想,他这个报错的文件在 multiprocessing/resource_tracker.py 里,这显然是一个关于多线程的文件,但是这个工程压根没用多线程(在工程文件夹里搜索 multiprocessing,发现没有 import 过)。
而且前面,那种诡异的两个print连着放,居然只打印一个的情况,一切连起来,都说明,这个报错跟我们的程序无关。
于是我就看向了 wandb,这个可视化模块。在 train_kitti_det.sh 里最后,有一个参数是 --use_wandb, 我把这个删了,果然,没用 wandb 了,报错也消失了。这个报错是由于 wandb 的问题引起的!
终于解决这个 bug 之后,再运行,遇到新报错 nvcc fatal : Unsupported gpu architecture ‘compute_86‘(也可能不是这个,我忘了具体是什么报错了,反正是说我算力不够)。这个报错在编译 MinkowskiEngine 的时候已经遇到过了,那时候是通过手动指定算力为7.5解决的。现在再运行程序,又说我算力不够。
多方查阅,终于知道,工程官方github给的 pytorch1.7.1 + cuda11.1 这个根本就是不科学的。pytorch1.7.1只能和cuda11.0搭配。所以可能从始至终,我的pytorch版本就是有问题的!
首先RTX3090,这个显卡的算力就是8.6,你要是用算力为7.x的CUDA(比如10.x),是不能匹配的。所以他只能搭配11.x的CUDA。然后11.x的CUDA,只能搭配比较高等级的pytorch。
这中间pytorch版本1.8.1,可能够匹配CUDA11.1了,但不够1.10.1那么高,无法完全发挥他8.6的算力,导致 nvcc fatal : Unsupported gpu architecture ‘compute_86‘报错。这时你也要指定成8.0的算力,切勿跟风指定成7.5的算力,不然后面会出问题。
解决方案(更换正确的pytorch套件)
搜索之后,决定用pytorch1.8.1 + cu111,参考链接https://pytorch.org/get-started/previous-versions/
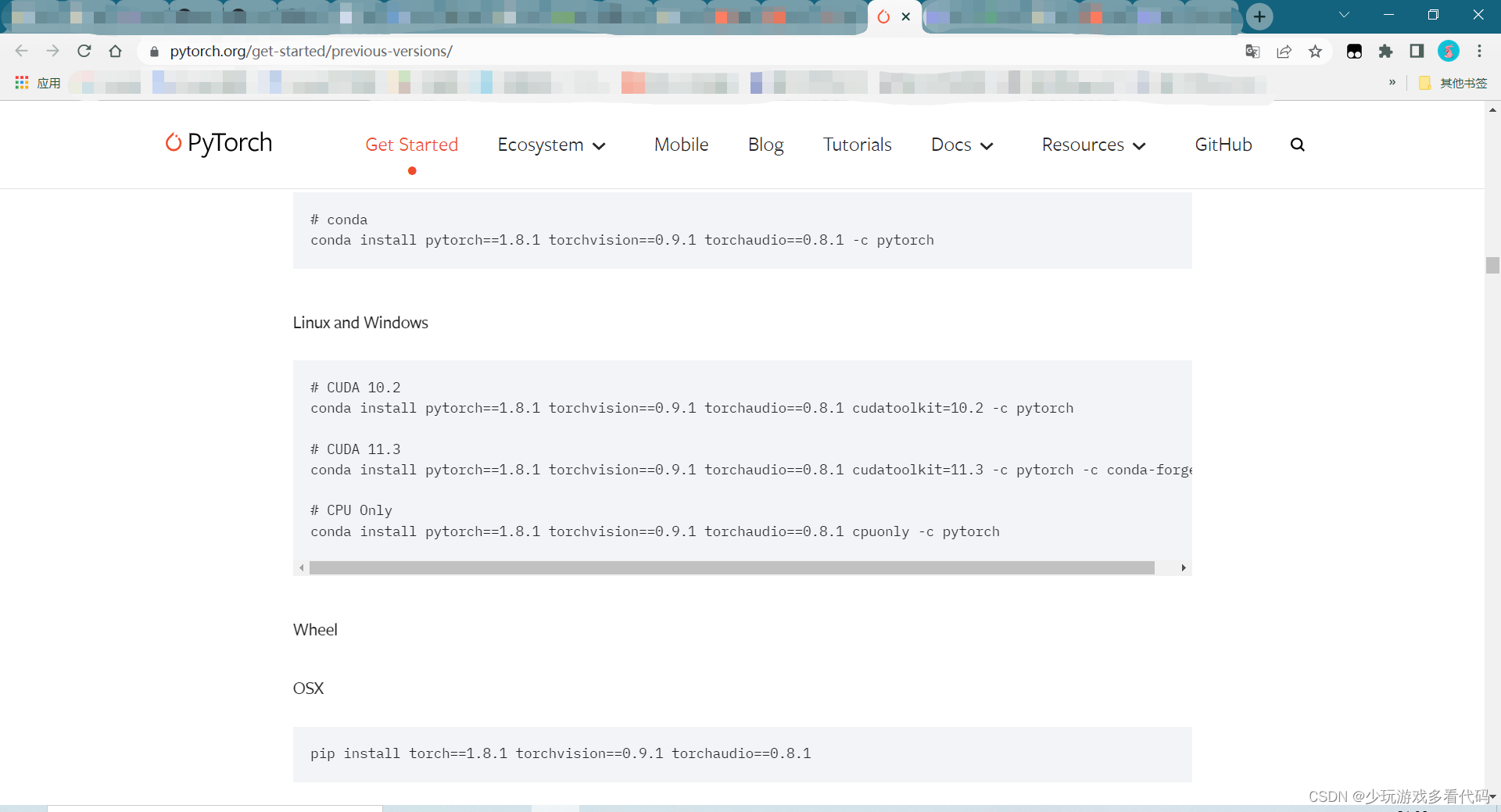
把命令中的cudatoolkit=11.3改为cudatoolkit=11.1,一行命令一次下载安装搞定。
更新了pytorch之后,需要再重新安装 MinkowskiEngine 和 pytorch3d。编译MinkowskiEngine的时候,还是会遇到 nvcc fatal : Unsupported gpu architecture ‘compute_86‘,参考了https://blog.csdn.net/qq_30614451/article/details/111173703 评论区的建议,这次采用 export TORCH_CUDA_ARCH_LIST="8.0"。编译成功。
一切准备就绪之后,回去运行sh scripts/train_kitti_det.sh,一切正常。记得把 train_kitti_det.sh 改回来。















 3253
3253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









