






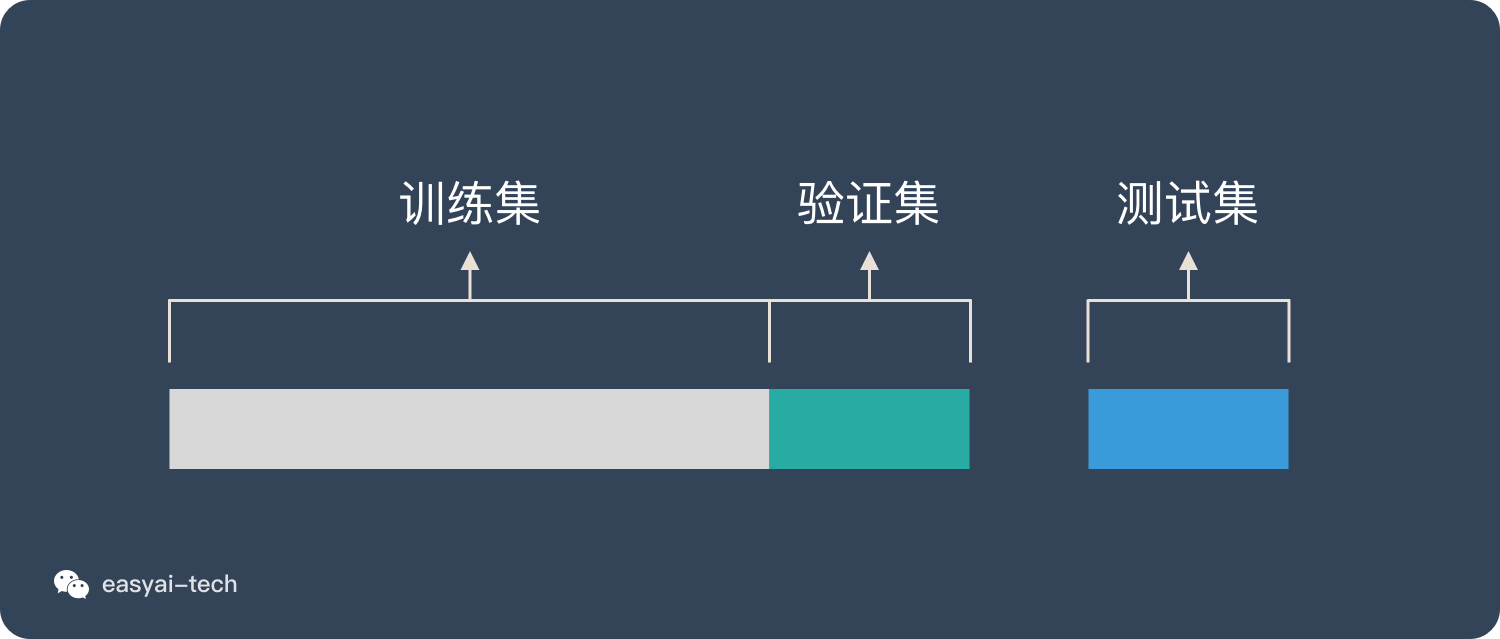
数据集
训练集(Training Set)
用来训练模型的数据。就像给学生提供教材一样,训练集帮助模型学习如何从输入数据预测出正确的结果。

验证集(Validation Set)
这个数据集用来检查模型在训练过程中的表现。它帮助我们调整模型训练参数的设置,以确保模型不仅在训练数据上表现好,也能在新的数据上表现好。
验证集有2个主要的作用:
- 评估模型效果,为了调整超参数而服务
- 调整超参数,使得模型在验证集上的效果最好
说明:
- 验证集不像训练集和测试集,它是非必需的。如果不需要调整超参数,就可以不使用验证集,直接用测试集来评估效果。
- 验证集评估出来的效果并非模型的最终效果,主要是用来调整超参数的,模型最终效果以测试集的评估结果为准。

测试集(Test Set)
测试集用来评估模型的最终性能。它包含了模型在训练过程中没有见过的数据,这样我们就可以更真实的了解模型在现实世界中的表现。
通过测试集的评估,我们会得到一些最终的评估指标,例如:准确率、精确率、召回率、F1等。

三种数据集的划分
损失(loss)
用来衡量模型的预测结果和实际结果之间差距的度量值。训练就是通过不断调整模型的参数,让预测值尽可能接近标准答案的过程,目标就是将loss最小化。
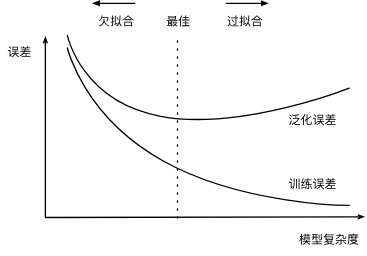
拟合
训练误差
Training Error:指的是模型在训练数据集上的预测误差或损失函数值。具体来说,就是模型输出与训练数据标注的正确答案之间的差距。具体来说,就是模型输出与训练数据标注的正确答案之间的差距。训练误差越小,意味着模型越能够很好的拟合已见的训练数据。但过小的训练误差也可能意味着模型过拟合训练数据的风险。
测试误差
Test Error:指的是模型在完全未见过的测试数据集上的预测误差或损失函数值。测试数据没有参数与模型的训练过程。测试误差可以更加客观的评估模型对新鲜数据的泛化能力和实际预测性能。测试误差越小,说明模型的泛化能力越强。
拟合
- 训练误差<<测试误差:过拟合训练数据
-
- 正则化,减少模型复杂度;提前停止训练;增加训练数据
- 训练误差≈测试误差:模型泛化性较好
- 训练误差≈测试误差(但都很大):欠拟合,模型没有从数据中学习到足够的信息
-
- 增加训练时间
















 1116
1116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









