







摘要:
近年来,卷积神经网络在三维几何预测方面取得了良好的结果。他们可以从很少的输入数据中进行预测,比如单个彩色图像。这种方法的一个主要限制是,它们只预测一个粗分辨率的体素网格,它不能很好地捕捉到物体的表面。我们提出了一个通用的框架,称为层次表面预测(HSP),它促进了高分辨率体素网格的预测。主要的优点是,预测表面周围的高分辨率体素就足够了。对象的外部和内部可以用粗分辨率的体素来表示。我们的方法并不依赖于一个特定的输入类型( RGB图、深度图、部分的体素网格)。我们展示了几何预测的结果,从颜色图像,深度图像和形状完成从部分体素网格。我们的分析表明,我们的高分辨率预测比低分辨率预测更准确。
主要框架

我看后总结的是:
给如一个输入I(可以是RGB图、深度图、部分的体素网格),经过一个卷积编码网络,得到一个特征向量C(文中是128位维度得到),然后这个C在经过上卷积(去卷积)解码网络得到体素块八叉树B(下面会有说明),为了更好的得到这个B和为了能够得到更高的分辨率,又引入了特征块F,特征块的空间范围大于或等于体素块中的一个,以允许填充p≥0。正如我们稍后将看到的,填充物在预测邻近的体素块时允许重叠,从而导致更平滑的结果。
1)理解解码过程:
最重要的是当给出一个分辨率为L的时候,怎么变成L+1
1、特征裁剪(Feature Cropping.)
在我们在这一点上假设我们给出了特征块F(l,s)。目标是为特定八元体O对应的子节点生成输出。功能块F(l,s)包含用来为所有子节点生成输出的信息。为了只处理与O对应的子节点预测相关的信息,我们从以O为空间中心的四维张量F中提取了一个((b/2 + 2p)3 × c)的区域。如果邻近的八位体被处理,提取的特征通道将有一些重叠,这有助于产生更平滑的输出.
我理解的是在原有的体素块夸大一点就变成了了特征块。而在现有的分辨率下,对一个体素块夸大一点就变成下一个特征块了。
2、上采样方式(Upsampling)
上采样模块从裁剪模块获取输入,并通过上卷积和卷积层预测一个新的(b+2p)^3特征块F(l+1,r)。
3、输出
输出网络从上采样模块中获取对特征块F(l+1,r)的预测,并生成体素块B(l+1,r)。这是使用一系列的卷积层来完成的。以体素块B(l+1,r)的三个地面真相标签的形式进行监督,即。对树的每一层都有监督。一旦生成了输出,就会生成下一级的子节点。关于是否增加子节点以及因此增加更高分辨率的预测的决定是基于体素块B(l+1,r)的相应八分度中的边界预测。我们计算了相应的八分体O0的最大边界预测响应.
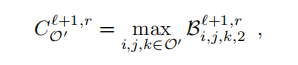
标签2就是边界标签。如果Cl+1,1、rO0高于小阈值γ,则生成子节点。这种选择背后的直觉是,一旦有一些证据表明表面正在通过一个特定的块,我们就应该预测一个更高分辨率的输出。另一方面,如果在特定水平上的预测非常确定在该子树内没有边界,那么就不需要进行更高分辨率的预测。对于飞机、椅子和汽车平均只有大约5%到10%的体素被预测为高分辨率,这表明我们的方法有效地减少了需要预测的体素的数量。
在树的第一级,从形状代码C预测根节点,一个小的解码网络直接预测第一个特征块,中间没有裁剪模块。同样地,在树的最深处,也不需要明确的特征块.因此,输出是直接由上一级的裁剪特性生成。还要注意,输出和上采样模块在树的每个级别都有各自的滤波器。此外,由于这种体系结构,所有的卷积和向上卷积都是标准层,不需要八字树的特殊版本。
2)体素块八叉树
在我们的层次表面预测方法中,我们提出预测一种具有向上卷积解码器结构的数据结构,我们称之为“体素块八叉树”。它的灵感来自于在传统的多视图重建方法中使用的八叉树公式。
允许我们在预测框架中使用这样种数据结构的关键见解是将标准的两个标签公式扩展到一个内部、边界和外部标签的三个标签公式。正如我们稍后将看到的,我们的数据结构允许我们以高分辨率生成一个完整的体素网格,同时只在表面周围进行预测。这导致了一种便于端到端高效训练编码器/解码器架构的方法。
八叉树是一种用于划分三维空间的树形数据结构。根节点描述了三维空间中感兴趣的多维数据集。每个内部节点最多有8个子节点,描述当前节点的立方集到八个八位体的细分。请注意,我们稍微偏离了八进树的标准定义,其中没有或所有8个子节点。
我们认为一个树的水平l∈{1,…,L},每个树的节点包含了一个“体素块”,将节点的三维空间细分为大小为b3的体素网格。体素块中的每个体素在树的水平l<L中包含对所占用空间、边界和可用空间的三个标签的分类器响应。层中的节点l∈{1,…,L−1},因此,包含体素块B(l,s)∈[0,1]b3×3,其中索引s描述了体素块相对于全局体素网格的位置。在最低级别L中,我们不需要边界标签,因此它由包含体素块B(l,s)∈[0,1]b3的节点组成,其中块的每个元素描述了二进制分类为自由或二进制空间的分类器响应。请注意,每个子节点描述一个空间,其立方体边长度只有当前节点一半的空间。通过将体素块分辨率固定在b3,我们还将体素边长度除以2倍。这意味着子节点中的预测的分辨率更高。选择体素块分辨率b,使它足够大,可以使用上卷积解码器网络有效地预测,同时也足够小,从而可以在表面周围进行局部预测。在我们的实验中,我们使用了一个b为=16的体素块和一个深度为=5的树。
3)用下采样高效的训练
总之就是快了。。。。。。
4)实验部分
使用了ShapeNet-Core,使用了其中的三类:椅子、飞机、汽车。
1)真实数据的体素化
就是将一些真实数据做成体素网格模型,最大化的把分辨率做的高一些,大多数达到了256,一些粗估计也有16.
2)基准
就是找了两个估计的算法基准,用文中的算法和这两个算法基准进行比较,从而突出文中算法的优点。
对于这两个基准,我们都使用32^3的统一预测分辨率。
它们在计算地面真相的方式上有所不同。第一个基线遵循标准的方法,将所有与地面真实网格表面相交的体素标记为被占用的空间,然后填充内部。这可以通过对我们的高分辨率地面真相进行下采样,并将至少包含一个高分辨率占用空间体素的所有低分辨率体素标记为占用空间,并将所有其他空间标记为自由空间来实现。我们将此基线称为“低分辨率硬”(LR硬)。另一个基线对低分辨率使用软分配,标签是由高分辨率自由空间与占用空间体素的比例给出的。因此,这些标签可以有分数分配。我们将此基线称为“低分辨率软”(LR软)。请注意,基线LR软化利用了高分辨率的体素化,但基线LR硬化相当于低分辨率的体素化。由于我们的目标是预测高分辨率几何,我们对323到2563的原始分类输出进行上采样,并以高分辨率进行评估。
3)输入数据
为了获得用于训练和测试CNNs的输入的RGB/深度图像,我们使用Blender在形状网数据集中呈现CAD模型。对于每个CAD模型,我们从随机的角度渲染10张图像通过0-360度的均匀采样方位角和20-30度的高角获得。我们还使用随机照明变化来渲染RGB图像。
我们还使用部分体素网格作为输入。在实践中,当一个对象的多个深度映射可用,但它们都来自对象的同一侧时,就会出现这样的输入。为了模拟这个任务,我们使用LR软基线的地面真相,并在体素网格的一半中随机零数据。然后,网络学习了预测完整的高分辨率重建来自部分低分辨率的输入。
4)定量分析
总之就是好
5)定性分析
好的不得了。。。。。。
文中主要的算法就是对八叉树的运用。
https://blog.csdn.net/Augusdi/article/details/36001543















 125
125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









