







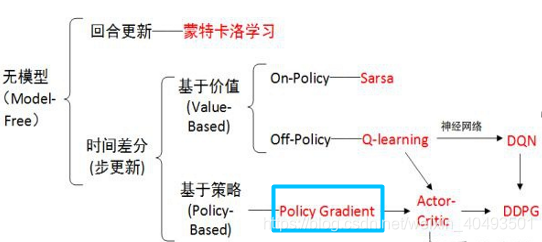
 本文介绍了策略梯度法在强化学习中的定位和作用,详细阐述了策略的参数化表示,特别是针对离散动作的情况。通过数学公式解析了策略梯度的目标、误差和梯度计算,探讨了基线的概念以确保公平性,并提到了在代码实现中采用的损失函数neg_log_prob。
本文介绍了策略梯度法在强化学习中的定位和作用,详细阐述了策略的参数化表示,特别是针对离散动作的情况。通过数学公式解析了策略梯度的目标、误差和梯度计算,探讨了基线的概念以确保公平性,并提到了在代码实现中采用的损失函数neg_log_prob。
一、来源和定位
1.1 PG算法在强化学习方法中的定位
策略梯度是基于策略搜索方法中最基础的方法,要理解AC,DDPG需要先学习策略梯度。
策略梯度方法就是将策略参数化,寻找最优的参数,使总体收益最大。关键在如何将策略参数化。
1.2 策略梯度直观理解
策略的表示
一般将策略表示为状态的函数:![]() ,
,
对于离散动作来说是一种随机分布:![]() ,随机策略参数化即为参数化这种分布。
,随机策略参数化即为参数化这种分布。
对于连续动作来说是随机高斯策略,用高斯策略来表示这种分布,参数化的方法为参数化高斯分布的均值和方差。
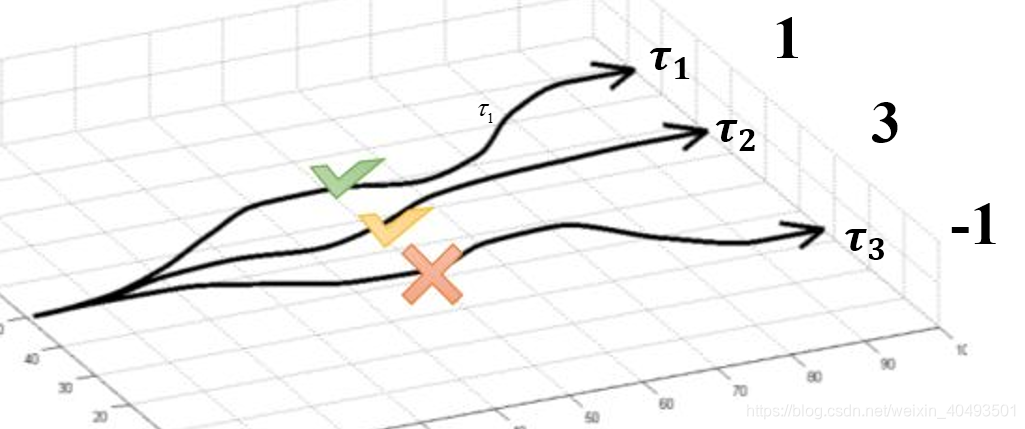
策略梯度是将智能体的策略转换成参数的非线性函数,通过寻优参数找到函数的最值,从而使回报值最大。如下图所示,假设有三条路径(每一条路径理解为一个策略)回报分别为1,3,-1.最直观的做法是尽量选择第二条路径,即增加该策略的概率,使最终的回报最大。
二、问题数学表示
2.1 误差
主要思想是使最终的回报最大,即一个完成的交互episode(从初始状态到最终状态的一个策略)。
目标:【一条完整的episode的回报期望最大】
![]()
要使该目标最大,则参数的更新方向为梯度上升的方向。
![]()
此公式中有两点需要注意,第一是上式第三行的变换,该方法在梯度中经常使用,直接记住即可,第二是最后一等式的变换,
是概率,与累加和可以看成是求后面部分的期望
策略产生的轨迹如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









