







通用视觉框架OpenMMLab——图像分类与MMClassification
目录
1.3.1 卷积层 (Convolutional Layer)
1.3.7 归一化层(Normalization Layer)
1.3.8 全连接层(Fully Connected Layer)
2.2 GoogleNet、ResNet、ResNeXt网络
2.3 SENet、MobileNet、ShuffleNet
1. 卷积神经网络以前
1.1 机器学习视角下的图像分类
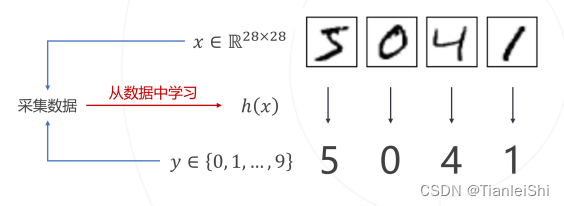
1.1.1 分类问题定义
- 从数据集D中学习一个分类函数
或
,其中x为输入模型的数据,y为模型预测的类别,h(x)为分类器
- 整个过程实现逻辑如下图:
1.1.2 随之而来要解决的两个问题
- 问题1:如何构建函数族
包含全部可能的分类器函数h(x)
- 问题2:如何在函数族中找出最好的分类器
- 对于第1个问题:有线性分类器,参数化函数族,神经网络
- 对于第2个问题:
- 描述“好”→错误率越低越好→损失函数=错误率
- 怎么找到“好”→调整参数降低损失函数→最优化问题
1.1.3 回到图像分类任务
- 我们通过确定卷积神经网络的结构来设计这个函数族的样子
- 通过交叉熵损失函数来衡量分类模型的好坏
- 通过随机梯度下降或者是其他一些经验策略辅助来搜索最佳模型
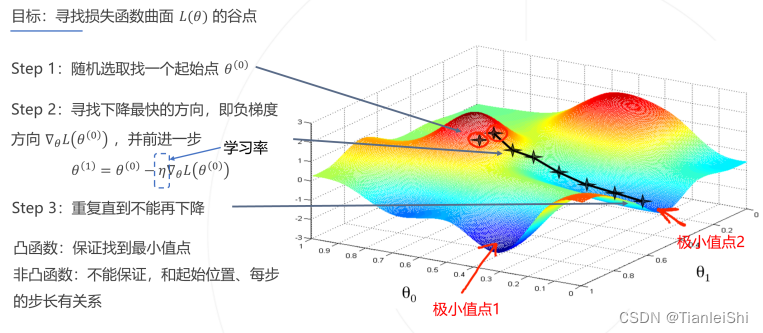
1.1.4 回顾一下梯度下降算法
1.2 多层感知机
- 为什么要引入多层感知机:经典的异或问题(线性不可分)。多层感知器在单层感知器的基础上引入了隐含层,能够解决非线性分类的问题
- 神经网络:

- 确定结构(层数、每层单元数)的多层感知器构成了一个分类器族,不同的连接权重对应了族内不同的分类器
- 基于梯度下降寻找最优参数,进而得到最优(准确率最高)的网络
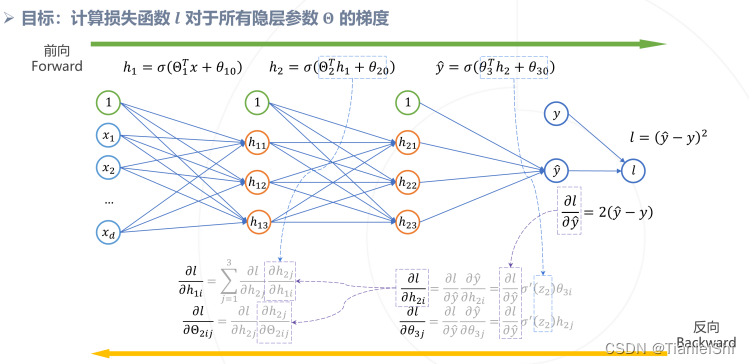
- 随之而来要解决一个问题:如何计算损失函数对于网络参数的梯度?→反向传播算法
1.2.1 反向传播算法
1.2.2 通用近似定理:
- 在神经元数目足够的情况下,单隐层的神经网络可以逼近任意连续函数
- 所需的神经元的数目随数据维度指数级增长
- 图像分类≠拟合任意复杂的分类函数
- 从实用角度讲,需要根据图像的特点设计更高效的模型
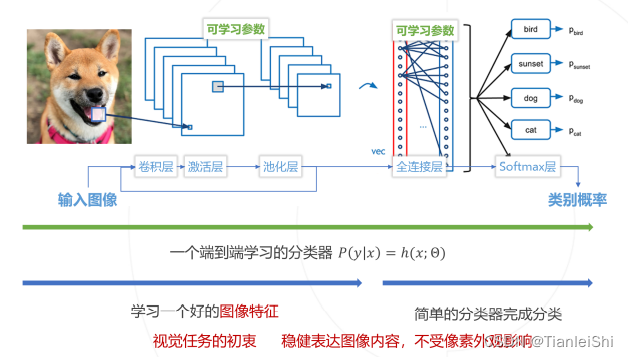
1.3 卷积神经网络
- 卷积神经网络的整体结构
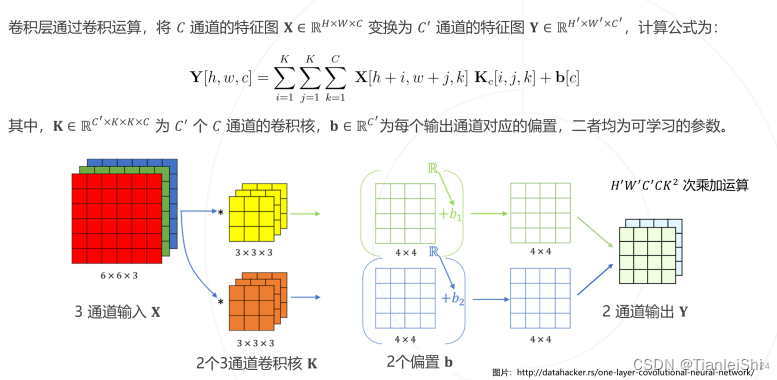
1.3.1 卷积层 (Convolutional Layer)
原则1:卷积核的通道数与输入图像的通道数相同
原则2:输出特征图的通道数与卷积核的个数相同
1.3.2 PyTorch实现卷积层
# Functional API
img = torch.randn(1.3.8.12) # N,C,H,W
weight = torch.randn(6,3,3,3) # C',C,K,K
bias = torch.randn(6) # C'
out = F.conv2d(img,weight,bias,padding=1)
# Class API
conv = nn.Conv2d(3,6,kernel_size=(3,3),padding=1) #C,C'
img = torch.randn(1,3,8,12) # N,C,H,W
y = conv(img)1.3.3 激活层(Activation Layer)
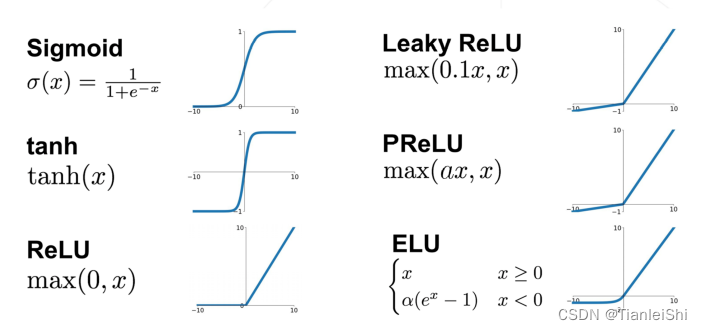
- 激活层基于一个非线性函数
对输入特征图进行逐像素的变换
- 激活曾通常不包含可学习参数
- ReLU是CNN中最常用的非线性激活函数
- 常用激活函数:
1.3.4 PyTorch实现激活层
x = torch.randn(3,3)
# Functional API
y = F.relu(x)
# Class API
relu = nn.ReLU()
y = relu(x)1.3.5 池化层(Pooling Layer)
- 池化层在特种图的局部区域内计算最大值或平均值,从而降低特征图分辨率,节省计算量,提高特征的空间鲁棒性
- 有最大池化和平均池化
1.3.6 PyTorch实现最大池化
x = torch.randn(1,1,4,4)
# Functional API
y = F.max_pool2s(x,kernel_size = 2,stride=2)
# Class API
pool = nn.MaxPool2d(kernel_size=(2,2),stride=2)
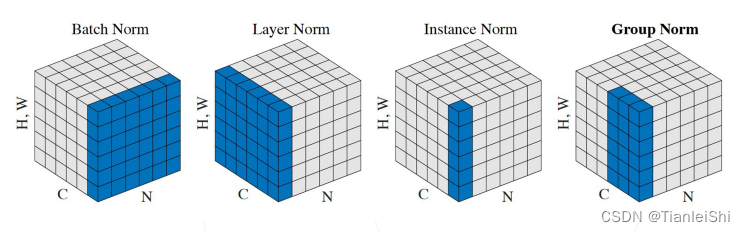
y = pool(x)1.3.7 归一化层(Normalization Layer)
- 将特征图中的激活值进行归一化处理,例如0均值1方差,降低训练难度
 1.3.8 全连接层(Fully Connected Layer)
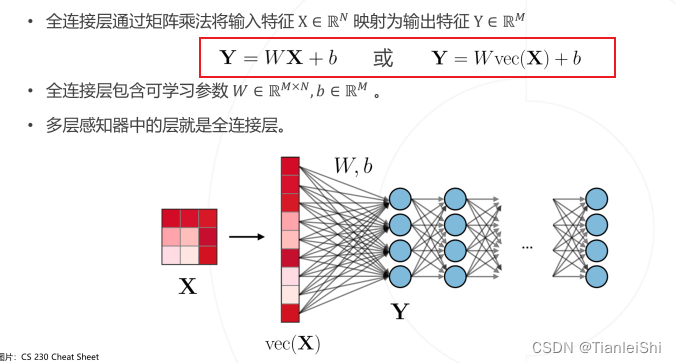
1.3.8 全连接层(Fully Connected Layer)
- 全连接层通过矩阵乘法将输入特征映射为输出特征
- 全连接层包含可学习参数
- 多层感知器中的层就是全连接层
1.3.9 PyTorch实现全连接层
# Vectorize
fmap = torch.randn(1,2,2,2)
x = fmap.view(-1,8)
# Functional API
weight = torch.randn(6,8)
bias = torch.randn(6)
y = F.linear(x,weight,bias)
# Class API
linear = nn.Linear(8,6) # in_features=8,out_features=6
y = linear(x)
1.3.10 概率输出层
- 将任意特征向量转换为概率向量

1.3.11 PyTorch实现Softmax
z = torch.rand(3)
# Functional API
p = F.softmax(z)
# Class API
s = nn.Softmax()
p = s(z)1.4 再谈卷积
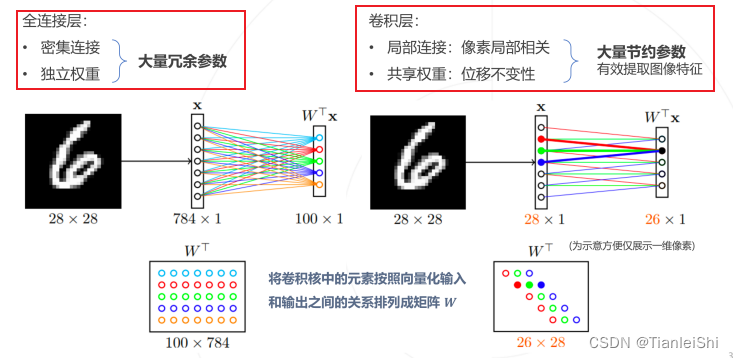
1.4.1 全连接层 VS 卷积层
- 两者都是线性层,实现了输入到输出的线性映射
- 卷积层输入输出之间的连接仅存在于局部空间,且连接的权重在不同输出单元之间是共享的。
1.4.2 卷积的变形
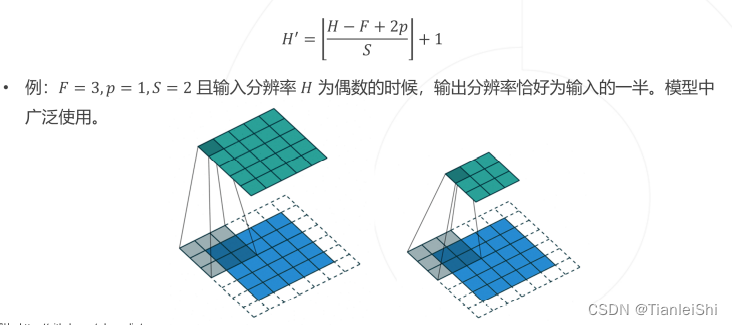
- 卷积层可以增加边缘填充(padding),步长(stride),和空洞(dilation)
- 边缘填充(padding)在输入特征图的边界处填补p个像素宽度的0值,以扩大输入和输出特征的空间尺寸。

- 步长(stride)降低卷积计算的空间频率,实现空间降采样。
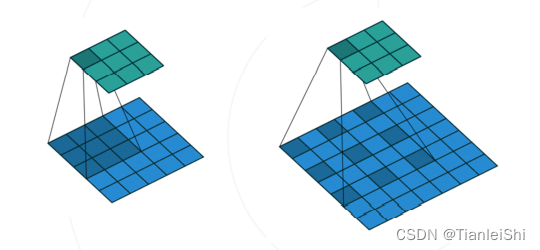
- 空洞卷积(dilation convolution)可以在不增加参数的情况下“扩大”卷积核,从而增加卷积层感受野。在语义分割模型中广泛应用。
2.图像分类模型设计
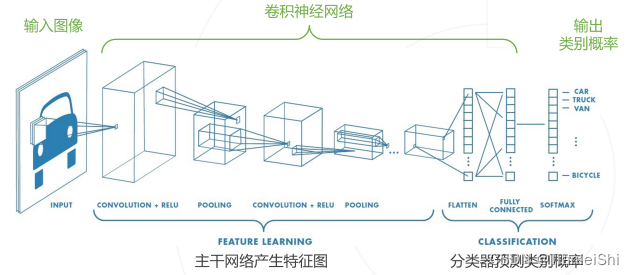
主要介绍以下网络:LeNet-5(1998),AlexNet(2012),VGGNet(2014),GoogleNet(Inception,2014)ResNet(2015),ResNeXt(2017),SENet(2017),MobileNet(2017),ShuffleNet(2017)的设计思路变化过程
- 图像分类网络通常可以分为主干网络和分类器两部分
2.1 LeNet-5、AlexNet、VGGNet网络
- LeNet-5最早的卷积神经网络之一。由7层网络组成,其中2层为卷积层,2层为下采样层,3层为全连接层。一共60k个可学习参数
- AlexNet第一个成功应用于大规模图像分类的CNN模型。8个可学习层,5个卷积层,3个全连接层,共有60M个可学习参数。使用2个NVIDIA GTX 580 GPU训练了1周
- AlexNet出来后第二年,开始研究神经网络可视化,可以看出每层学习出了什么样的特征
- 卷积网络中的多层次特征:第一层通常是图像的局部的一些小的边缘,还有一些颜色这种特征,再经过第二层后,经过一些组合变成稍微有点形状的,比如圆形。再往后就可以逐渐得到更复杂的形状,甚至到最后就可以学习出一些物体的特征
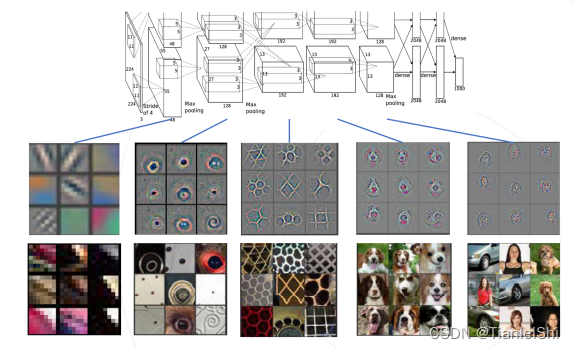
- VGGNet,只使用3*3的卷积核(感受野不变的前提下,降低模型参数量,更少的参数达到了一个更好的网络表达能力),层数增多到16~19层,边界填充1像素,维持空间分辨率。倍增通道数的同时减半空间分辨率
- VGG-16有138M权重参数,其中超过100M来自全连接层

2.2 GoogleNet、ResNet、ResNeXt网络
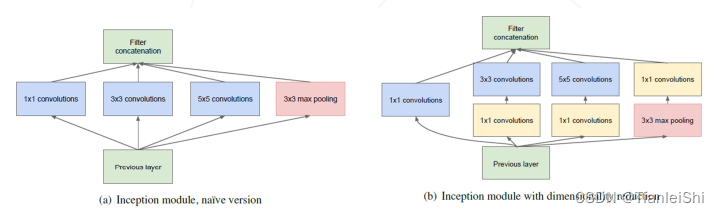
- GoogleNet使用了Inception模块,在同一层使用不同尺寸的卷积核。GoogleNet(Inception v1)一共有22个可学习层,仅7M权重参数


- 通过Padding操作使得不同尺寸的卷积核卷积后输出特征图的尺寸相同
- Inception模块
- 使用不同大小的卷积核,再将特征图沿通道拼接
- 对于3*3和5*5的卷积核,进一步使用1*1的卷积核压缩通道,降低计算量。
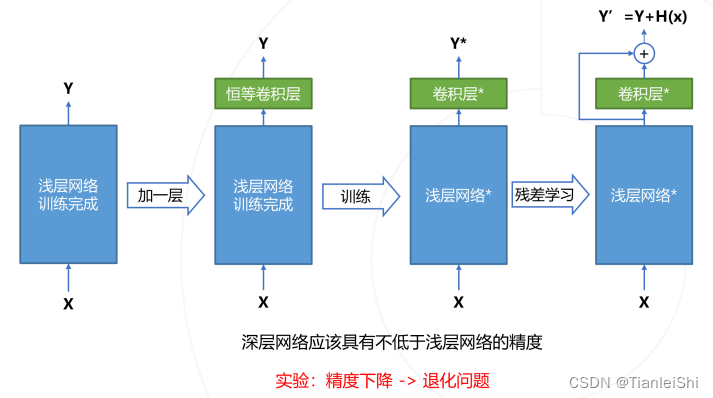
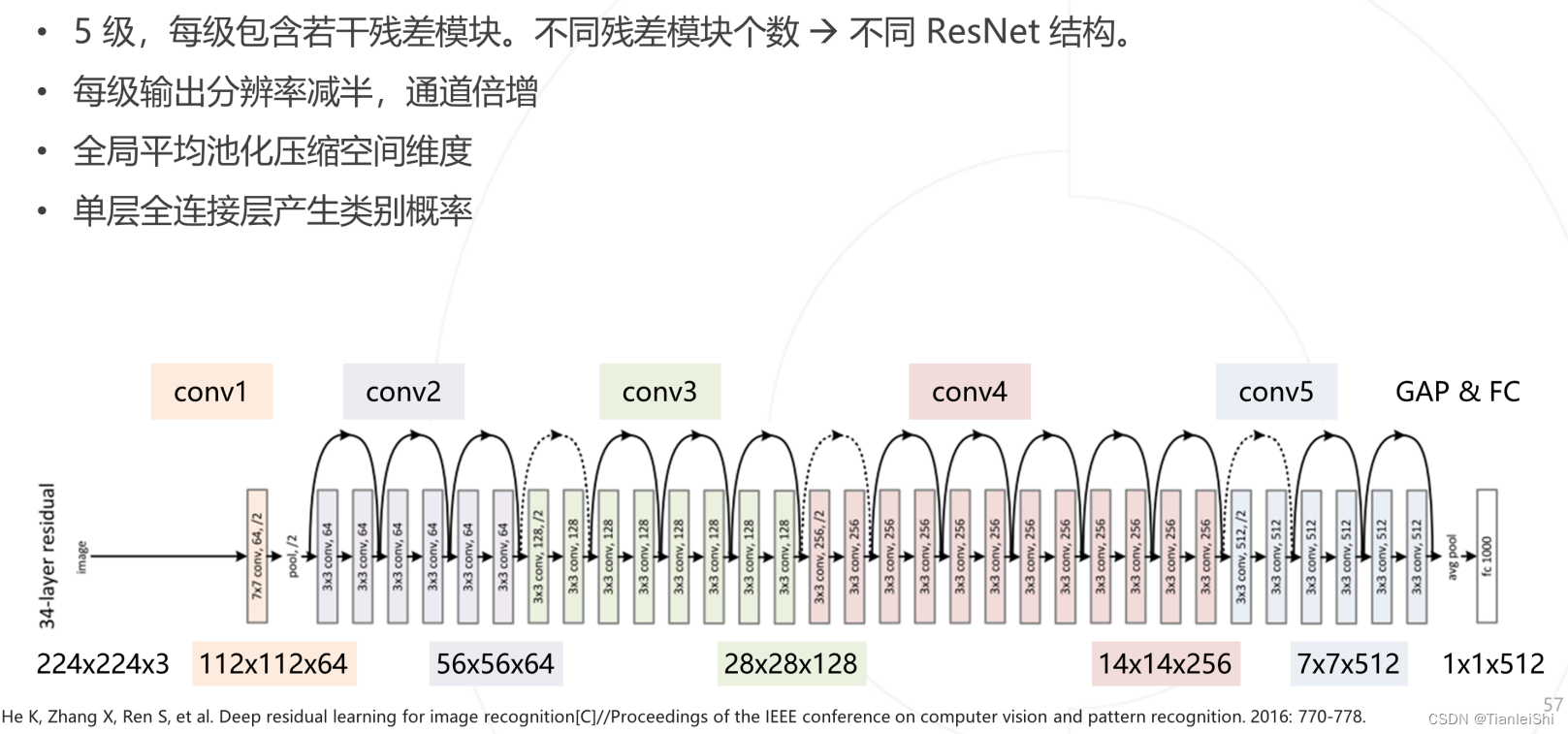
- ResNet是迄今为止影响力最大、使用最广泛的模型结构之一,获得CVPR2016最佳论文奖
- 残差学习:引入了跨层连接,将网络深度提高到了上百层

- 残差学习缘起
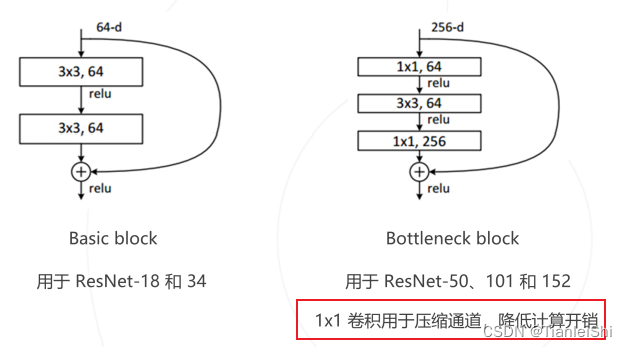
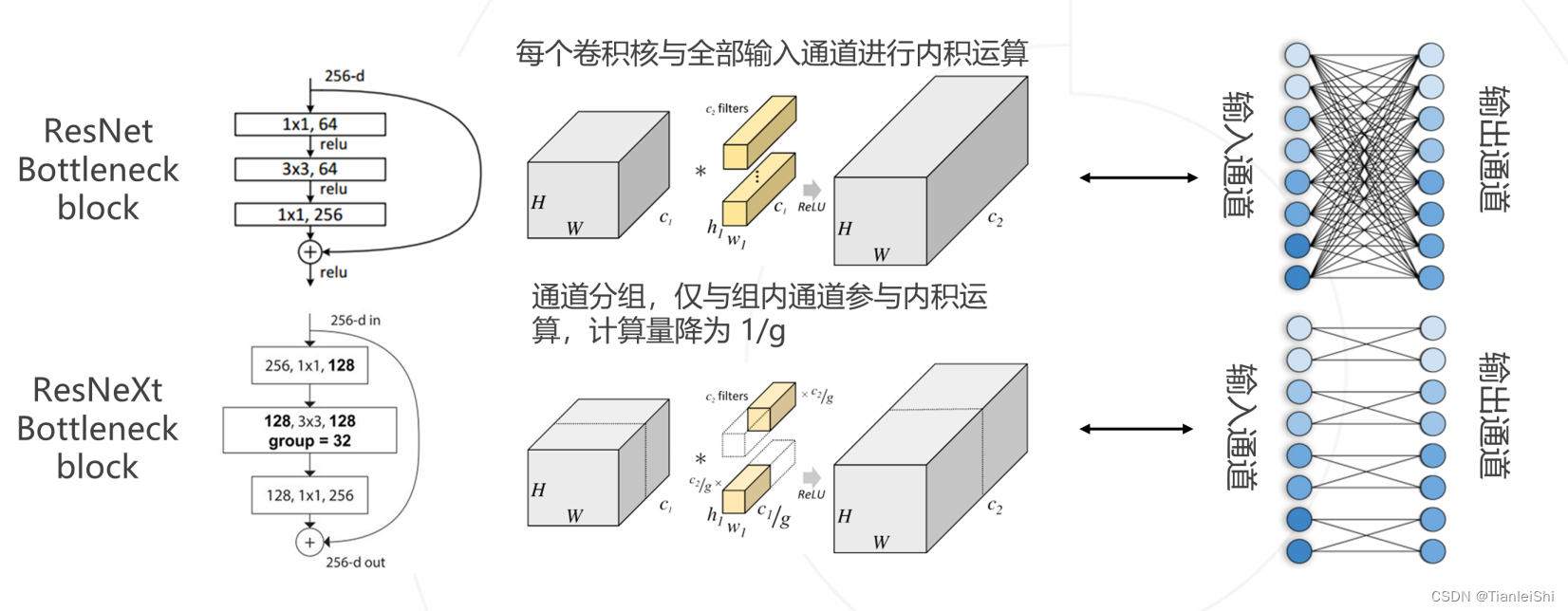
- 残差模块有两种:Basic block和Bottleneck block,后者主要是在大一点的ResNet网络中,去做一个计算量的压缩
- ResNet模型主体结构
- ResNeXt将ResNet的Bottleneck block中3*3的卷积改为分组卷积,降低模型计算量。
2.3 SENet、MobileNet、ShuffleNet
- SENet引入注意力机制,显式建模不同通道的重要性。属于即插即用模块,可以插入到任意模型中:SE+ResNet = SENet

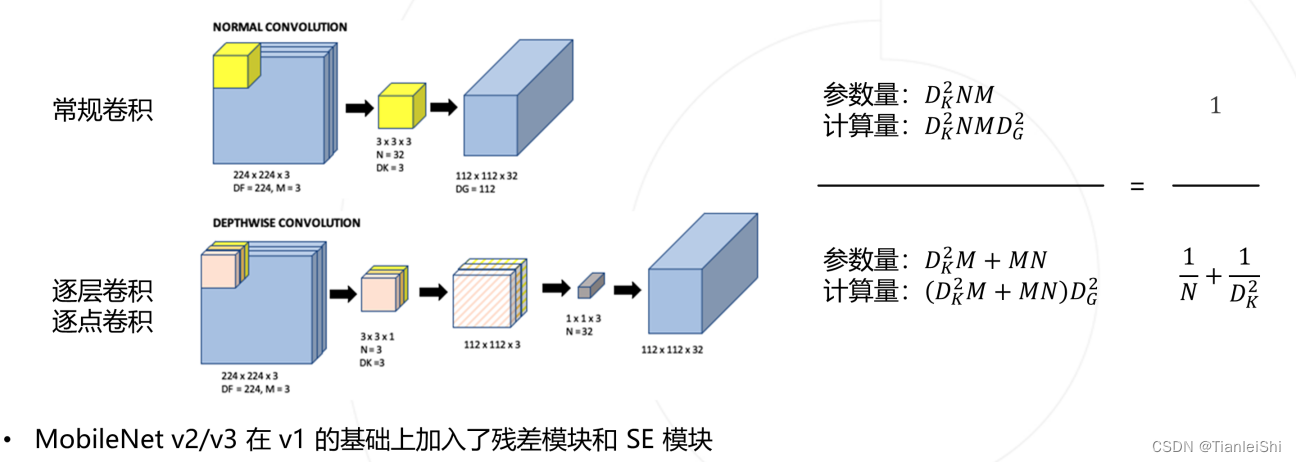
- MobileNet将常规卷积分解为逐层卷积和逐点卷积,以降低参数量和计算量
- 全尺寸的MobileNet只有4.2M参数
- ShuffleNet网络提出了channel shuffle的思想(组卷积虽然可以降低参数量和计算量,但是不同组之间没有信息交流,效果不好)
















 3418
3418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









