







对 PointNet 做个整理笔记
为什么提出了 PointNet?
在 pointnet 之前的算法没有很好的利用 点云本身的特性 (比如降维或者栅格化)
PointNet的设计是直接在原始点云上操作和学习特征
主要有三个特征
1.无序性
虽然输入的点云是有顺序的,但是这个顺序不应当影响结果
2.点之间的交互
每个点不是独立的,二十与周围的点共同有一些信息,所以模型应该抓住局部的结构和局部之间的交互
3.交换不变性
比如点云整体的旋转和平移不应该影响它的分类或者分割
PointNet 怎么解决的
1.无序性
用对称函数来描述,置换不变性
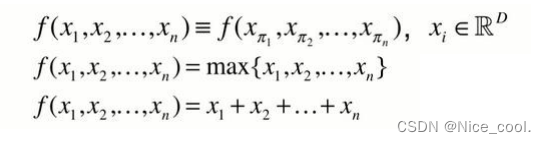
神经网络本质是一个函数,用神经网络直接构造对称函数
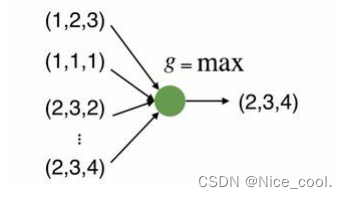
由上式可以看出,虽然具有置换不变性,但是只得到了最远的边界信息,损失了很多有意义的几何信息
所以在 pointnet 中,先进行升维再进行 max 操作 (神经网络隐层)
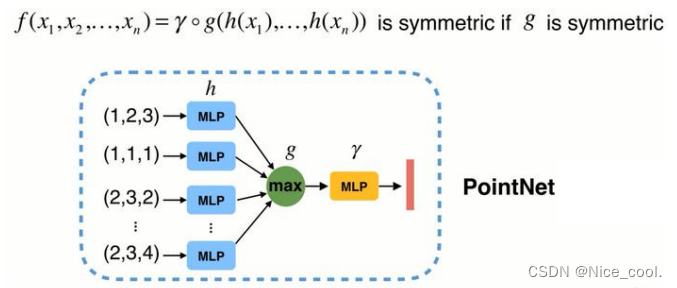
- 先将每个点映射到 冗余的 高维空间,在高维空间中做对称性操作
- 在 max 操作中 通过 冗余 可以避免信息的丢失
- 再通过一个网络来进一步消化信息 -> 得到点云的特征
2.点之间的交互 & 交换不变性
在网络中加入 T-Net (数据对齐网络)。
T-Net 将所有的输入点集对齐到一个统一的点集空间, 直接预测一个变换矩阵(K*K)来处理输入点的坐标,可以在一定程度上保证网络可以学习到变换无关性。
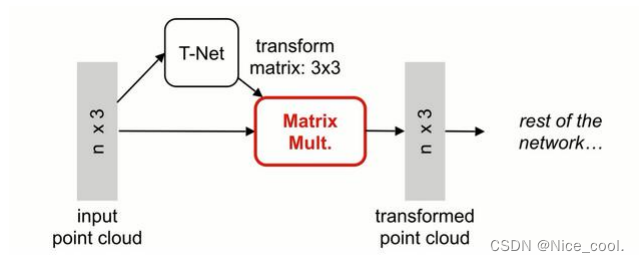
- n个点(x,y,z) 进入 T-net 生成变换参数,之后的网络处理变换之后的点。
- 目标是通过整体优化变换网络和后面的网络使得变换函数对齐输入,如果对齐了,不同视角的问题就可以简化
- 不仅可以在输入作此变换,还可以在中间做N个点 K维特征,用另外网络生成k*k 来做特征空间的变化,生成另一组特征
PointNet 总体网络结构
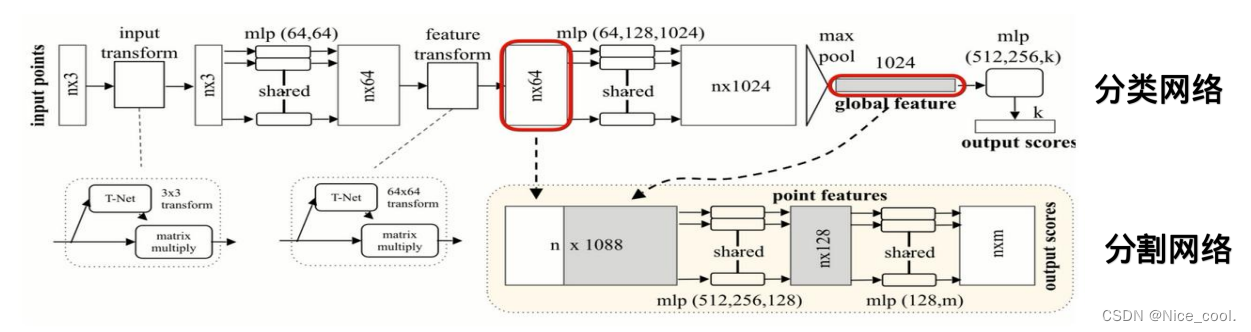
- 输入变换——>对齐输入点云(规范化3x3)T-net
class STN3d(nn.Module):
def __init__(self, channel):
super(STN3d, self).__init__()
self.conv1 = torch.nn.Conv1d(channel, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 9)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = Variable(torch.from_numpy(np.array([1, 0, 0, 0, 1, 0, 0, 0, 1]).astype(np.float32))).view(1, 9).repeat(
batchsize, 1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, 3, 3)
return x
- 点云处理——>MLP处理点云(升维到64)
conv1 = torch.nn.Conv1d(3, 64, 1),即输入通道=3,输出通道=64,卷积核大的大小为1,
卷积核第二个维度是由in_channels来决定的,所以实际上卷积大小为in_channels*kerner_size,这里为3 * 1
self.conv1 = torch.nn.Conv1d(channel, 64, 1)
self.bn1 = nn.BatchNorm1d(64)
x = F.relu(self.bn1(self.conv1(x)))
- 特征变换——>对齐输入特征(规范化64x64)
if self.feature_transform:
trans_feat = self.fstn(x)
x = x.transpose(2, 1)
x = torch.bmm(x, trans_feat)
x = x.transpose(2, 1)
else:
trans_feat = None
- 特征处理——>MLP处理特征(升维到1024)
pointfeat = x
x = F.relu(self.bn2(self.conv2(x)))
x = self.bn3(self.conv3(x))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
if self.global_feat:
return x, trans, trans_feat
else:
x = x.view(-1, 1024, 1).repeat(1, 1, N)
return torch.cat([x, pointfeat], 1), trans, trans_feat
- 对称函数处理——>全局特征(Max pooling)
分类:
点云生成的1024维特征通过最后一个MLP来进行学习,其中k是最后一层的输出数量,代表分类的类别,每个类别会对应对于点云的分类得分
分割:
由于需要考虑局部特征,需要将 n*64 局域特征和 1024维的全局特征结合在一起进行融合,在每一个点的64维特征后接续1024全局特征,随后利用一个 mlp(512,512,128) 对 n ∗ 1088维的特征维度进行学习,生成 n ∗ 128的向量,再利用(128,m)的感知机对最后的特征进行分类(分割问题其实是针对每一个点的分类问题),其中n对应n个点,而m对应的是点对应的m个分类得分
PointNet 代码部分
class get_model(nn.Module):
def __init__(self, k=40, normal_channel=True):
super(get_model, self).__init__()
if normal_channel:
channel = 6
else:
channel = 3
# PointNetEncoder
self.feat = PointNetEncoder(global_feat=True, feature_transform=True, channel=channel)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, k)
self.dropout = nn.Dropout(p=0.4)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(256)
self.relu = nn.ReLU()
def forward(self, x):
x, trans, trans_feat = self.feat(x)
x = F.relu(self.bn1(self.fc1(x)))
x = F.relu(self.bn2(self.dropout(self.fc2(x))))
x = self.fc3(x)
x = F.log_softmax(x, dim=1)
return x, trans_feat
PointNetEncoder
class PointNetEncoder(nn.Module):
def __init__(self, global_feat=True, feature_transform=False, channel=3):
super(PointNetEncoder, self).__init__()
self.stn = STN3d(channel)
self.conv1 = torch.nn.Conv1d(channel, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.global_feat = global_feat
self.feature_transform = feature_transform
if self.feature_transform:
self.fstn = STNkd(k=64)
def forward(self, x):
B, D, N = x.size()
trans = self.stn(x)
x = x.transpose(2, 1)
if D > 3:
feature = x[:, :, 3:]
x = x[:, :, :3]
x = torch.bmm(x, trans)
if D > 3:
x = torch.cat([x, feature], dim=2)
x = x.transpose(2, 1)
x = F.relu(self.bn1(self.conv1(x)))
if self.feature_transform:
trans_feat = self.fstn(x)
x = x.transpose(2, 1)
x = torch.bmm(x, trans_feat)
x = x.transpose(2, 1)
else:
trans_feat = None
pointfeat = x
x = F.relu(self.bn2(self.conv2(x)))
x = self.bn3(self.conv3(x))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
if self.global_feat:
return x, trans, trans_feat
else:
x = x.view(-1, 1024, 1).repeat(1, 1, N)
return torch.cat([x, pointfeat], 1), trans, trans_feat















 932
932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









