






Trebing K, Staǹczyk T, Mehrkanoon S. SmaAt-UNet: Precipitation nowcasting using a small attention-UNet architecture[J]. Pattern Recognition Letters, 2021, 145: 178-186.
代码:https://github.com/HansBambel/SmaAt-UNet
作者提出一种SmaAt-UNet模型。它使用UNet架构作为核心,并加入注意力机制和深度可分离卷积。主要优势在于可以在效果相当的情况下将模型参数降低到原始UNet的1/4。
文章的任务之一是输入过去1小时的降水图,进行未来30分钟的降水外推。
1 方法
SmaAt-UNet模型介绍
UNet架构是一个U型的编码-解码的结构。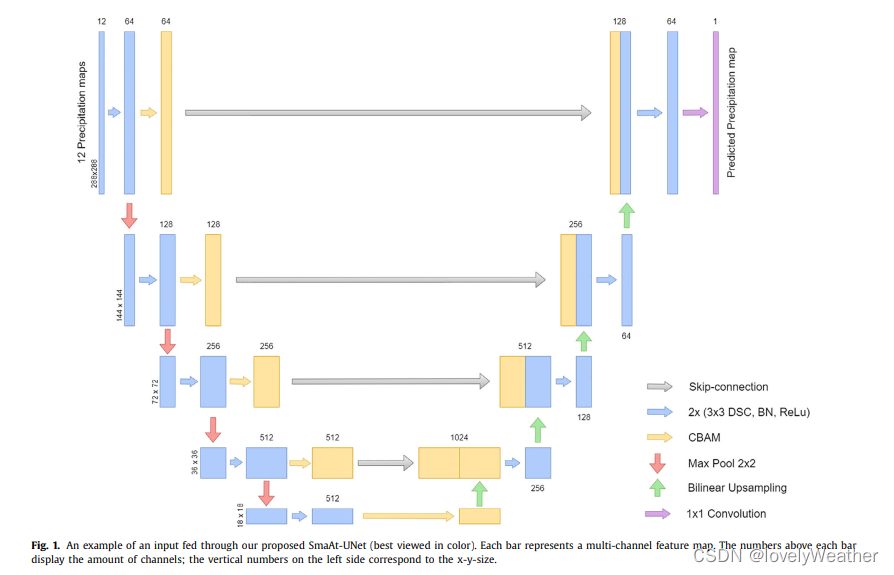
左边是编码部分,包括max-pooling(红色→)和卷积(蓝色→),这样就减小了图像尺寸,增加了特征图。
右边是解码部分,包括上采样(绿色→)以增加特征图的尺寸、拼接前一步编码器的输出(灰色箭头)、卷积。拼接(skip connections)这一步使得模式可以更好地利用输入的多尺度信息(有利于捕获不同尺度的目标)。最终还有一个1×1的卷积(紫色箭头)输出一个特征图,即最终的预测结果。
一般UNets被应用于分类或分割任务,每个像素点预测一个类别。而我们应用于时间序列的预测,预测每个像素的具体数值。
SmaAt-UNet的两个特色
a. 在编码部分加入了CBAM 注意力机制
可以让模型更专注于特定的部分。本文使用卷积块注意力模块来识别图像中不同通道和区域的重要特征。在CBAM中,先后对图像的通道维和空间维应用注意力机制。CBAMs放在了卷积之后(黄色箭头),增强重要特征,抑制不重要的特征。
每一个编码层的输入是没有经过注意力模块的,这就保留了原始图像的特征。注意力模块只进入网络中相应的上采样部分。
b. 将常规的卷积运算改为深度可分离卷积
目的是减少参数数量。
试验相关设计
a. 试验设计:原始UNet模型、加入了注意力机制UNet with CBAM、采用深度可分离卷积UNet with DSC、SmaAt-UNet模型
| Model | Parameters |
| UNet | 17,272,577 |
| UNet with CBAM | 17,428,781 |
| UNet with DSC | 3,955,185 |
| SmaAt-UNet | 4,111,389 |
b. 参数设计
- 迭代次数200
- 早停标准:验证集的损失在15个epoch上都没有增加(这里我认为是‘没减小’的意思,原文可能是写错了)。4组试验都实现了早停,即达到了收敛
- 使用学习率调度器(learning rate scheduler),如果4个epoch中validation loss都没有增加,学习率调整为原来的1/10。初始学习率0.001,Adam optimizer。
- 损失函数MSE
- 评价指标:Precision, Recall (probability of detection), Accuracy, F1-score, critical success index (CSI), false alarm rate (FAR) and Heidke Skill Score (HSS)
2 试验
2.1 数据集1——降水图
荷兰气象局提供的2016-2019年的5分钟累积降水数据,时间分辨率5 min,空间分辨率1 km,总计有420,000张图(765 × 700 )。数据由两部C波段雷达反演,再由雨量计进行订正。2016-2018年数据作为训练集(随机选取10%作为验证集),2019年的作为测试集。
数据准备
- 归一化:不管是训练集还是测试集,都将数值除以训练集中的最大值
- 裁剪:数据中如果有很多缺测值,神经网络将变得更困难。因此裁剪了其中的288×288个像素点
- input:12张降水图(对应过去1小时)
- output:未来30分钟的降水图
- 数据有很多没有降水或者小雨的情况。为了防止模型倾向于预测出0值,制作了2个额外的数据集,其中目标图像的降水网格数要达到一定的数量,分别是20%(NL-20)和50%(NL-50)。最终是在NL-50数据及上进行的训练。数据及NL-20可以用作一个额外的评价指标,衡量其泛化能力,因为训练时没有遇到过这个数据集中的一些图像。然而,模型可能偏向于预测出更多的雨水。因此,有可能模型在这个测试集上的表现要差一些
| Name | Required rain pixels | Train | Test | Subset |
| NL-Full | 0%(original) | 314940 | 105003 | 100% |
| NL-20 | 20% | 31674 | 11276 | 10.23% |
| NL-50 | 50% | 5734 | 1557 | 1.74% |
2.2 数据集2——云覆盖图(cloud cover)
图像大小256×256;图像是一个二进制图,像素值1表示有云,0表示无云;时间分辨率15 min。样本的输入为4张图(一小时),预测未来6张图(1小时30分钟)。
3 结果与讨论
3.1 降水数据结果
NL-50降水数据集(表4)上的表现
- 各试验结果都比baseline好
- 单独加DSC或者CBAM后评分都略有下降
- 同时DSC和CBAM要比单独加表现好
- 单独加CBAM时MSE最大,说明不应该这样?
- 单独加DSC时MSE变大一点(worse),但参数量减小至1/4
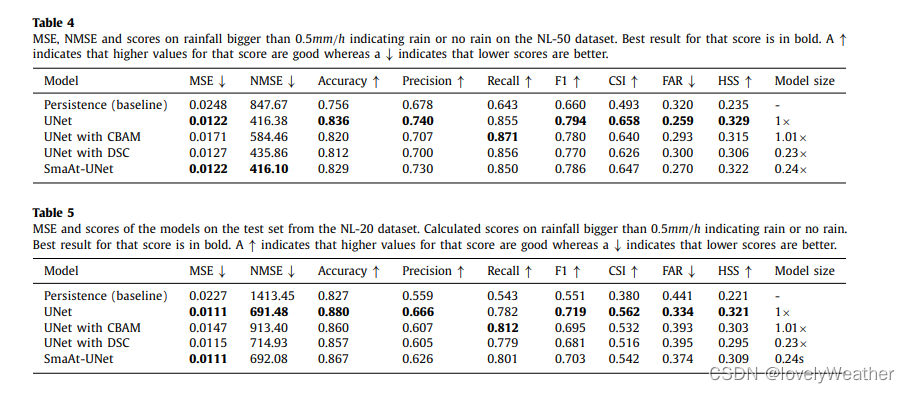
针对NL-20数据集测试了模型的泛化能力(表5),UNet基本还是最好,其次是SmaAt-UNet。各metric的得分与NL-50数据集的结果(表4)相差不太大, 表明泛化能力还行。小雨无雨的网格点多,预测的值也还是小,因此MSE不会大多少。NMSE考虑了数值分布,是一个更好的评价指标。可以看到UNet和SmaAt-UNet比其他好很多。
外推图效果图中,1. 预测的都比实际模糊。原因是使用了MSE作为损失函数,网络希望让误差小,因此要预测一个数接近于所有可能的结果。2. 对左下角的强降水区来说,SmaAt-UNet表现最好,单DSC的东西向太宽了,单CBAM的太弱了,原始UNet垂直方向预测值偏弱。

特征图(图5)为各CBAM层输出的的特征图,网络的注意力图关注的是输入序列的特定部分,如map 2和8,关注左下角的雨区,map 4、5、7关注小(无)雨区。随着层数的增加,分辨率下降,最后一层分辨率最低,网格数为18×18。
 各注意力层输出的特征图
各注意力层输出的特征图
3.2 云覆盖数据结果
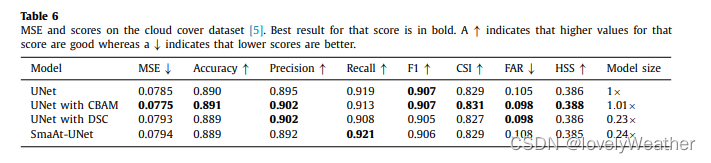
云覆盖问题属于二分类问题,各实验相差不大,但SmaAt-Unet参数为原来的1/4。
4 小结
文章提出的SmaAt-UNet是一个轻量化的、包含了注意力机制的UNet框架,其在保持UNet性能的基础上将模型减小了很多,约减小到1/4。

















 1313
1313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









