






目录
代码下载链接:https://download.csdn.net/download/weixin_40723264/88011324
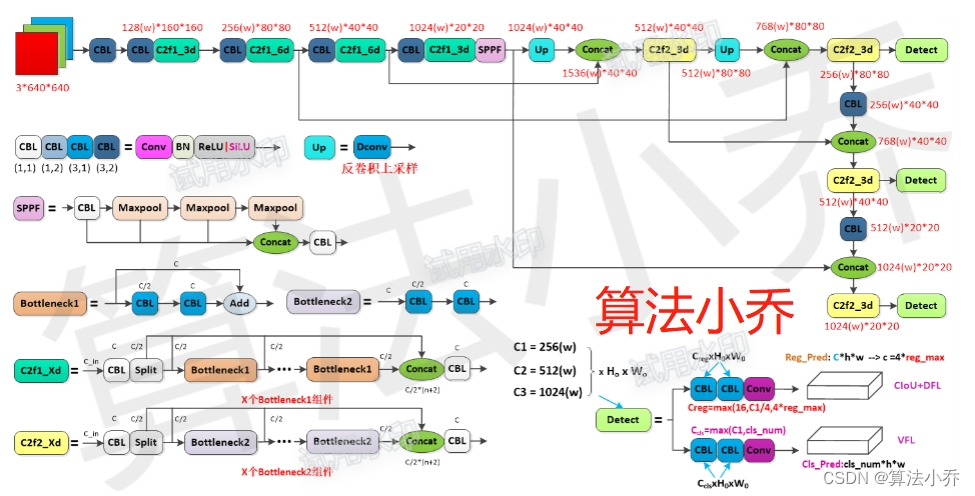
一、介绍概述
本文主要介绍yolov8在训练过程中的两个阶段:
1. Task-Aligned Assigner 正负样本动态分配策略
2. 损失函数计算
由于个人感觉官方代码读起来比较困难,故按照自己的思路重新写了一遍,下面将按照自己的代码进行讲解。
假设:
网络输入大小为:images = b x 3 x 640 x 640
类别数目 cls_num = 2 (person + car )
超参数 reg_max = 16
输出通道为: 4 * reg_max + cls_num
则三个分支的预测size分别为:b x 66 x 80 x 80 + b x 66 x 40 x 40 + b x 66 x 20 x 20
二、Task-Aligned Assigner
1. 分配原理
Task-Aligned Assigner,又名对齐分配器,在YOLOv8中是一种动态的分配策略。
一言以蔽之: 针对所有像素点预测的 Cls score 和 Reg Score(Box与每个GT box的IOU) ,通过加权的方式得到最终的加权分数,通过对加权分数进行排序后选择Topk个正样本。

其中,s是所有像素点-所有类别的Cls score , U是所有像素点预测box与所有GTbox的Reg score(IOU),α和β为权重超参数,两者相乘就可以衡量对齐程度,t作为加权分数。
2. 前期处理
代码如下:
self.cuda = True if inputs[0].is_cuda else False
self.FloatTensor = torch.cuda.FloatTensor if self.cuda else torch.FloatTensor
self.LongTensor = torch.cuda.LongTensor if self.cuda else torch.LongTensor
# ---------- 预测结果预处理 ---------- #
# 将多尺度输出整合为一个Tensor,便于整体进展矩阵运算
pred_scores,pred_regs,strides = self.pred_process(inputs)
# --------- 生成anchors锚点 ---------#
# 各尺度特征图每个位置一个锚点Anchors(与yolov5中的anchors不同,此处不是先验框)
# 表示每个像素点只有一个预测结果
self.anc_points,self.stride_scales = self.make_anchors(strides)
# ------------- 解码 ------------- #
# 预测回归结果解码到bbox xmin,ymin,xmax,ymax格式
pred_bboxes = self.decode(pred_regs)
# ---------- 标注数据预处理 ----------- #
gt_bboxes,gt_labels,gt_mask = self.ann_process(annotations)A. 预测结果解码
对于网络输出的box信息,实际上表示的是相对于每个像素点上不同anchor的偏移值(左上角或右下角相对于中心点的距离)
(1) 预测数据预处理
# ---------- 预测结果预处理 ---------- #
# 将多尺度输出整合为一个Tensor,便于整体进展矩阵运算
pred_scores,pred_regs,strides = self.pred_process(inputs) def pred_process(self,inputs):
'''
L = class_num + 4*self.reg_max = class_num + 64
多尺度结果bxLx80x80,bxLx40x40,bxLx20x20,整合到一起为 b x 8400 x L
按照cls 与 box 拆分为 b x 8400 x 2 , b x 8400 x 64
'''
predictions = [] # 记录每个尺度的转换结果
strides = [] # 记录每个尺度的缩放倍数
for input in inputs:
self.bs,cs,in_h,in_w = input.shape
# 计算该尺度特征图相对于网络输入的缩放倍数
stride = self.input_h // in_h
strides.append(stride)
# shape 转换 如 b x 80 x 80 x cls_num+2 -> b x 6400 x cls_num+2
prediction = input.view(self.bs,4*self.reg_max+self.class_num,-1).permute(0,2,1).contiguous()
predictions.append(prediction)
# b x (6400+1600+400)x cls_num+2 = b x 8400 x (cls_num + 2)
predictions = torch.cat(predictions,dim=1)
# 按照cls 与 reg 进行拆分
# 类别用sigmoid方法,对每个类别进行二分类
pred_scores = predictions[...,4*self.reg_max:]
pred_regs = predictions[...,:4*self.reg_max]
return pred_scores,pred_regs,strides (2)生成所有anchor锚点的中心坐标和缩放尺度
# --------- 生成anchors锚点 ---------#
# 各尺度特征图每个位置一个锚点Anchors(与yolov5中的anchors不同,此处不是先验框)
# 表示每个像素点只有一个预测结果
self.anc_points,self.stride_scales = self.make_anchors(strides) def make_anchors(self,strides,grid_cell_offset=0.5):
'''
各特征图每个像素点一个锚点即Anchors,即每个像素点只预测一个box
故共有 80x80 + 40x40 + 20x20 = 8400个anchors
'''
# anc_points : 8400 x 2 ,每个像素中心点坐标
# strides_tensor: 8400 x 1 ,每个像素的缩放倍数
anc_points,strides_tensor = [],[]
for i , stride in enumerate(strides):
in_h = self.input_h//stride
in_w = self.input_w//stride
#
sx = torch.arange(0,in_w,).type(self.FloatTensor) + grid_cell_offset
sy = torch.arange(0,in_h).type(self.FloatTensor) + grid_cell_offset
# in_h x in_w
grid_y,grid_x = torch.meshgrid(sy,sx)
# in_h x in_w x 2 -> N x 2
anc_points.append(torch.stack((grid_x,grid_y),-1).view(-1,2).type(self.FloatTensor))
strides_tensor.append(torch.full((in_h*in_w,1),stride).type(self.FloatTensor))
return torch.cat(anc_points,dim=0),torch.cat(strides_tensor,dim=0)(3) 预测结果解码
# ------------- 解码 ------------- #
# 预测回归结果解码到bbox xmin,ymin,xmax,ymax格式
pred_bboxes = self.decode(pred_regs)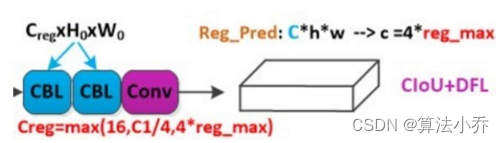
此处,reg_max = 16,通过16个值,结合softmax对box的4个预测值实现离散回归。最后通过积分的方式,得到最终结果。
具体代码如下:
def decode(self,pred_regs):
'''
预测结果解码
1. 对bbox预测回归的分布进行积分
2. 结合anc_points,得到所有8400个像素点的预测结果
'''
if self.use_dfl:
b,a,c = pred_regs.shape # b x 8400 x 64
# 分布通过 softmax 进行离散化处理
# b x 8400 x 64 -> b x 8400 x 4 x 64 -> softmax处理
pred_regs = pred_regs.view(b,a,4,c//4).softmax(3)
# 积分,相当于对16个分布值进行加权求和
# b x 8400 x 4
pred_regs = pred_regs.matmul(self.proj.type(self.FloatTensor))
# 此时的regs,shape-> bx8400x4,其中4表示 anc_point中心点分别距离预测box的左上边与右下边的距离
lt = pred_regs[...,:2]
rb = pred_regs[...,2:]
# xmin ymin
x1y1 = self.anc_points - lt
# xmax ymax
x2y2 = self.anc_points + rb
# b x 8400 x 4
pred_bboxes = torch.cat([x1y1,x2y2],dim=-1)
return pred_bboxes积分之后得到的pred_regs,其中的4个值,分别表示什么?
如果pred_regs的最后维度的4个值用 left_regs,top_regs,right_regs,bottom_regs表示,则它们分别表示在特征图(80x80,40x40,20x20)每个像素点上,anchors points中心点距离预测框左侧、上侧、右侧、下侧的距离。

B. 标注Targets数据预处理
# ---------- 标注数据预处理 ----------- #
gt_bboxes,gt_labels,gt_mask = self.ann_process(annotations)预处理的目的:
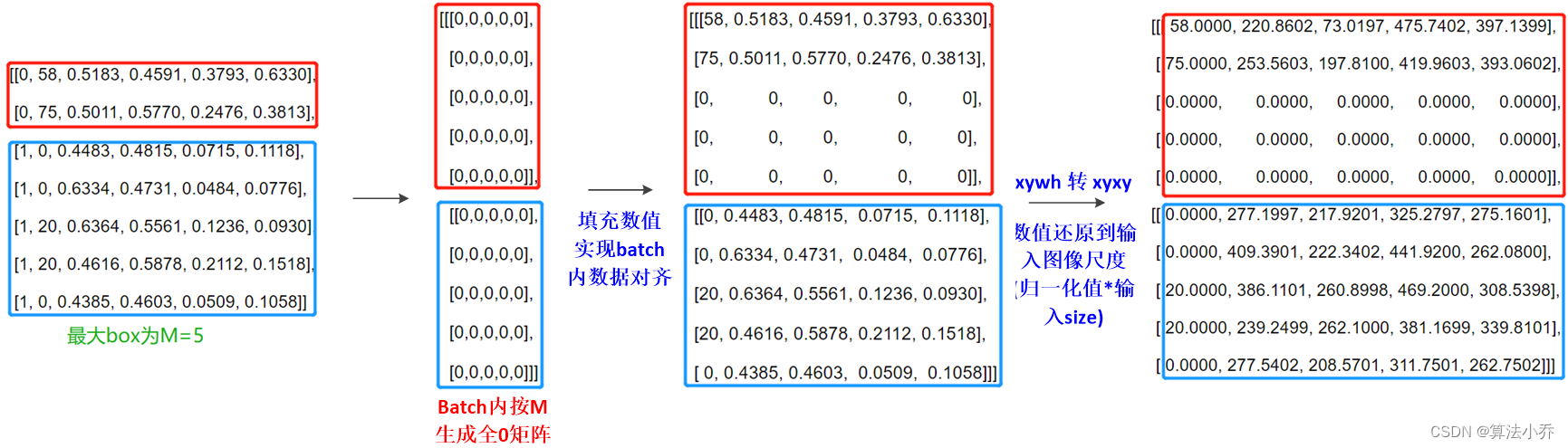
因为batch内不同图像的标注目标个数可能不同,需要进行对齐处理。所谓对齐,如batch_size=2, 其中第二张图像标注5个box,则其shape为 5 x 6, 6表示[img_idx,cls_id,cx,cy,width,height],第一张图像标注2个box,则其shape为2x6,故需要按标注目标数目最大的进行对齐,即将第张图像的2x6填充为5x6,空余位置用0补齐。
经过预处理之后,得到的标注数据,在后期训练正样本的筛选过程中就可以更方便的调用。
下面结合图像对该过程进行叙述:
(1) Dataloader获取信息
如batch_size = 2,cls_num=80, 其中第1张图像有5个obj,第二张图像有2个obj,如下所示:

(2) 对齐操作
将box信息由归一化尺度转换到输入图像尺度,并对bath内每张图像的gt个数进行对齐(目标个数都设置一个统一的值M,方便进行矩阵运算)
M值的设置规则为,选取batch内最大的gt num作为M
def ann_process(self,annotations):
'''
batch内不同图像标注box个数可能不同,故进行对齐处理
1. 按照batch内的最大box数目M,新建全0tensor
2. 然后将实际标注数据填充与前面,如后面为0,则说明不足M,用0补齐
'''
# 获取batch内每张图像标注box的bacth_idx
batch_idx = annotations[:,0]
# 计算每张图像中标注框的个数
# 原理对tensor内相同值进行汇总
_,counts = batch_idx.unique(return_counts=True)
counts = counts.type(torch.int32)
# 按照batch内最大M个GT创新全0的tensor b x M x 5 ,其中5 = cx,cy,width,height,cls
res = torch.zeros(self.bs,counts.max(),5).type(self.FloatTensor)
for j in range(self.bs):
matches = batch_idx == j
n = matches.sum()
if n:
res[j,:n] = annotations[matches,1:]
# res 为归一化之后的结果,需通过scales映射回输入尺度
scales = [self.input_w,self.input_h,self.input_w,self.input_h]
scales = torch.tensor(scales).type(self.FloatTensor)
res[...,:4] = xywh2xyxy(res[...,:4]).mul_(scales)
# gt_bboxes b x M x 4
# gt_labels b x M x 1
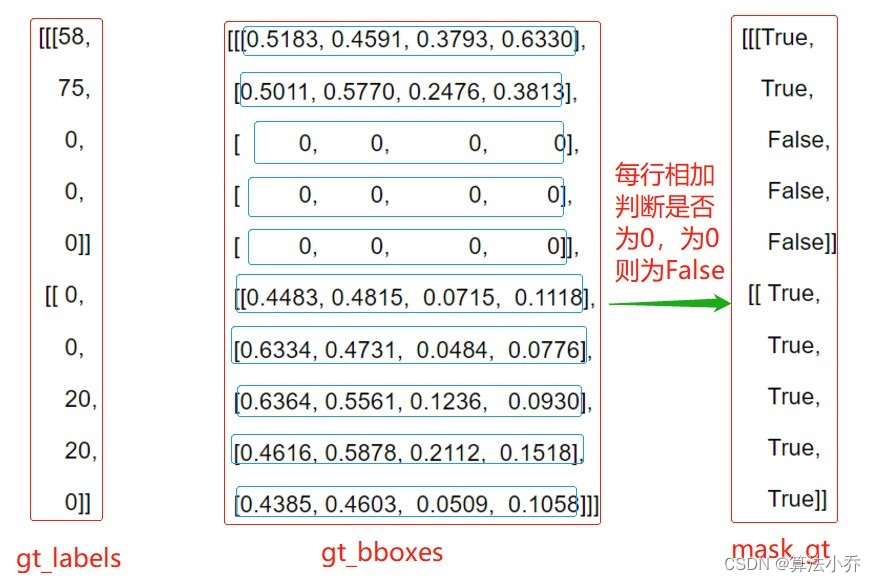
gt_bboxes,gt_labels = res[...,:4],res[...,4:]
# gt_mask b x M
# 通过对四个坐标值相加,如果为0,则说明该gt信息为填充信息,在mask中为False,
# 后期计算过程中会进行过滤
gt_mask = gt_bboxes.sum(2,keepdim=True).gt_(0)
return gt_bboxes,gt_labels,gt_mask过程如下:
然后,gt_bboxes、gt_labels分开,并得到相应的gt_mask(用于区分正负样本)
3. 正负样本分配
大体流程:
(1) 网络输出的pred_scores[bx8400xcls_num],进行sigmoid处理(每个类别按照2分类处理)。
(2) 经过解码的pred_bboxes[bx8400x4], 与 stride_tensor[8400x1]相乘,将bboxes转换到网络输入尺度[bx3x640x640];
(3) 预处理得到的anchors_points[8400x2],与stride_tensor[8400x1]相乘,将anchors的中心点坐标转换到输入尺度
(4) 然后,将上述pred_scores、pred_bboxes、anchors_points,还有标注数据预处理之后的gt_labels、gt_bboxes、gt_mask,相结合进行正样本的筛选工作。
self.assigner = TaskAlignedAssigner(topk=10, num_classes=self.nc, alpha=0.5, beta=6.0)
# 每个gt box 最多选择topk个候选框作为正样本
其中,S是预测类别分值,U是预测框和GT Box的ciou值,α和β为权重超参数,两者相乘就可以衡量匹配程度,当Cls的分值越高且CIOU越高时,t的值就越接近于1,此时预测box就与GTbox越匹配,就越符合正样本的标准.
通过训练t可以引导网络动态的关注于高质量的正样本。
a. 对于每个GT,对所有预测框基于该GT的类别pred score 结合 与该GT box的 CIOU,加权得到一个关联Cls及Box Reg的对齐分数alignment_metrics。
b. 对于每个GT,直接基于alignment_metrics对齐分数,通过排序后,选取topK个预测框作为正样本。
对流程进行梳理:
<1> 初步筛选
原理:anchor_points即落在gt_boxes内部,作为初步筛选的正样本。
得到gt_boxes的左上角lt,以及右下角rb,分别令anchor_points减去lt,rb减去anchor_points,如果结果均为正,则说明该anchor_point在gt_box内部。对于anchor_points: 8400 x 2 ,得到对应的mask -> in_gts_mask, 便于后面的过滤操作。
代码如下:
# ---------------------- 初筛正样本 ------------------------- #
# -------------- 判断anchor锚点是否在gtbox内部 --------------- #
# M x 8400
in_gts_mask = self.__get_in_gts_mask(gt_bboxes,anc_points) def __get_in_gts_mask(self,gt_bboxes,anc_points):
# 找到M个GTBox的左上与右下坐标 M x 1 x 2
gt_bboxes = gt_bboxes.view(-1,1,4)
lt,rb = gt_bboxes[...,:2],gt_bboxes[...,2:]
# anc_points 增加一个维度 1 x 8400 x 2
anc_points = anc_points.view(1,-1,2)
# 差值结果 M x 8400 x 4
bbox_detals = torch.cat([anc_points - lt,rb - anc_points],dim=-1)
# 第三个维度均大于0才说明在gt内部
# M x 8400
in_gts_mask = bbox_detals.amin(2).gt_(self.eps)
return in_gts_mask <2> 精细筛选
上面只是进行了粗略的初步筛选,所得到的结果中仍然存在一部分负样本(虽然anchor_point在gtbox内部,但IOU过低或scores过低),需要进一步进行筛除。
a. 计算 每个预测box与所有GT box的CIOU值,即上面公式中的u.
b . 预测的scores是上面公式中的s, 将 scores 和 cious带入是公式得到t
c. 对t进行排序后得到前 topk个作为正样本,其余的作为负样本
思考:此处yolov8与yolov5的区别?
a. yolov5 采用的是静态分配策略,通过观察anchor_box与gt_box的iou值,如满足一定阈值0.5,则认为是正样本。
b. yolov8采用的是动态分配策略,在分配过程中综合考虑了iou与scores值,对预测的两个分支综合考虑。
静态分配策略是训练开始之前就确定的,这种分配策略通常基于经验得出,可以根据数据集的特点进行调整,但是不够灵活,可能无法充分利用样本的信息,导致训练结果不佳。
动态分配策略,可以根据训练的进展和样本的特点动态的调整权重(在损失函数中会添加对应的权重,下面会详细叙述),在训练初期,模型可能会很难区分正负样本,此时权重惩罚值很大,会更加关注那些容易被错分的样本。随着训练的进行,模型组件变得更加强大,可以更好地区分样本,因此权重的惩罚值就会动态的变低。动态分配策略可以根据训练损失或者其他指标来进行调整,可以更好地适应不同的数据集和模型。
代码如下:
# ---------------------- 精细筛选 ---------------------- #
# 按照公式获取计算结果
align_metrics,overlaps = self.__refine_select(pb_scores,pb_bboxes,gt_labels,gt_bboxes,in_gts_mask * gt_mask)
# 根据计算结果,排序并选择top10
# M x 8400
topk_mask = self.__select_topk_candidates(align_metrics,gt_mask.repeat(1,self.nc)) def __refine_select(self,pb_scores,pb_bboxes,gt_labels,gt_bboxes,gt_mask):
# 根据论文公式进行计算得到对应的计算结果
# reshape M x 4 -> M x 1 x 4 -> M x 8400 x 4
gt_bboxes = gt_bboxes.unsqueeze(1).repeat(1,self.nc,1)
# reshape 8400 x 4 -> 1 x 8400 x 4 -> M x 8400 x 4
pb_bboxes = pb_bboxes.unsqueeze(0).repeat(self.n_max_boxes,1,1)
# 计算所有预测box与所有gtbox的ciou,相当于公式中的U
gt_pb_cious = bbox_iou(gt_bboxes,pb_bboxes,xywh=False,CIoU=True).squeeze(-1).clamp(0)
# 过滤填充的GT以及不在GTbox范围内的部分
# M x 8400
gt_pb_cious = gt_pb_cious * gt_mask
# 获取与GT同类别的预测结果的scores
# 8400 x cls_num -> 1 x 8400 x cls_num -> M x 8400 x cls_num
pb_scores = pb_scores.unsqueeze(0).repeat(self.n_max_boxes,1,1)
# M x 1 -> M
gt_labels = gt_labels.long().squeeze(-1)
# 针对每个GTBOX从预测值(Mx8400xcls_num)中筛选出对应自己类别Cls的结果,每个结果shape 1x8400
# M x 8400
scores = pb_scores[torch.arange(self.n_max_boxes),:,gt_labels]
# 根据公式进行计算 M x 8400
align_metric = scores.pow(self.alpha) * gt_pb_cious.pow(self.beta)
# 过滤填充的GT以及不在GTbox范围内的部分
align_metric = align_metric * gt_mask
return align_metric,gt_pb_cious def __select_topk_candidates(self,align_metric,gt_mask):
# 从大到小排序,每个GT的从8400个结果中取前 topk个值,以及其中的对应索引
# top_metrics : M x topk
# top_idx : M x topk
topk_metrics,topk_idx = torch.topk(align_metric,self.topk,dim=-1,largest=True)
# 生成一个全0矩阵用于记录每个GT的topk的mask
topk_mask = torch.zeros_like(align_metric,dtype=gt_mask.dtype,device=align_metric.device)
for i in range(self.topk):
top_i = topk_idx[:,i]
# 对应的top_i位置值为1
topk_mask[torch.arange(self.n_max_boxes),top_i] = 1
topk_mask = topk_mask * gt_mask
# M x 8400
return topk_mask <3> 排除一个锚点被分配给多个GT box的情况
a. 通过对mask矩阵,每个anchor对于所有GT求和,查看值是否大于1,如大于1,这说明被分配给多个GT
b. 筛除多余分配的情况,原则: 通过观察该anchor与被多分配的每个GT的CIOU值,选择值最大者。
代码如下:
# ------------------ 排除某个anchor被重复分配的问题 ---------------- #
# target_gt_idx : 8400
# fg_mask : 8400
# pos_mask: M x 8400
target_gt_idx,fg_mask,pos_mask = self.__filter_repeat_assign_candidates(pos_mask,overlaps) def __filter_repeat_assign_candidates(self,pos_mask,overlaps):
'''
top_mask : M x 8400
gt_pb_cious: M x 8400
过滤原则:如某anchor被重复分配,则保留与anchor的ciou值最大的GT
'''
# 对列求和,即每个anchor对应的M个GT的mask值求和,如果大于1,则说明该anchor被多次分配给多个GT
# 8400
fg_mask = pos_mask.sum(0)
if fg_mask.max() > 1:#某个anchor被重复分配
# 找到被重复分配的anchor,mask位置设为True,复制M个,为了后面与overlaps shape匹配
# 8400 -> 1 x 8400 -> M x 8400
mask_multi_gts = (fg_mask.unsqueeze(0) > 1).repeat([self.n_max_boxes, 1])
# 每个anchor找到CIOU值最大的GT 索引
# 8400
max_overlaps_idx = overlaps.argmax(0)
# 用于记录重复分配的anchor的与所有GTbox的CIOU最大的位置mask
# M x 8400
is_max_overlaps = torch.zeros(overlaps.shape, dtype=pos_mask.dtype, device=overlaps.device)
# 每个anchor只保留ciou值最大的GT,对应位置设置为1
is_max_overlaps.scatter_(0,max_overlaps_idx.unsqueeze(0),1)
# 过滤掉重复匹配的情况
pos_mask = torch.where(mask_multi_gts, is_max_overlaps, pos_mask).float()
# 得到更新后的每个anchor的mask 8400
fg_mask = pos_mask.sum(0)
# 找到每个anchor最匹配的GT 8400
target_gt_idx = pos_mask.argmax(0)
'''
target_gt_idx: 8400 为每个anchor最匹配的GT索引(包含了正负样本)
fg_mask: 8400 为每个anchor设置mask,用于区分正负样本
pos_mask: M x 8400 每张图像中每个GT设置正负样本的mask
'''
return target_gt_idx,fg_mask,pos_mask<4>获得筛选样本的训练标签
前面<1><2><3>步的目的是为了获得正负样本的mask,即fg_mask、pos_mask、以及target_gt_idx,其中:
fg_mask : shape为 8400,其作用是服务于8400个anchors的,对8400个anchors设置True和False,代表该样本为正还是为负。
pos_mask:shape为M x 8400,其作用是服务于M个gtbox的,表示了每个gtbox的正负样本,其作用是对M个gtbox的负样本进行过滤。
target_gt_index: shape为 8400,其作用服务于8400个anchors,表示与每个anchor,M个gtbox中最匹配的gtbox的索引index。
因为网络输出的预测值分别为: pred_scores(8400xcls_num) + pred_bboxes(8400x4)
然后根据预处理阶段得到的gt_labels(5x1),gt_bboxes(5x4) 结合 target_gt_index、fg_mask,得到最终同shape的训练标签:target_labels(8400xcls_num)、target_bboxes(8400x4)
# ------------------ 根据Mask设置训练标签 ------------------ #
# target_labels : 8400 x cls_num
# target_bboxes : 8400 x 4
target_labels,target_bboxes = self.__get_train_targets(gt_labels,gt_bboxes,target_gt_idx,fg_mask) def __get_train_targets(self,gt_labels,gt_bboxes,target_gt_idx,fg_mask):
'''
gt_labels: M x 1
gt_bboxes: M x 4
fg_mask : 8400 每个anchor为正负样本0或1
target_gt_idx: 8400 每个anchor最匹配的GT索引(0~M)
'''
# gt_labels 拉直
gt_labels = gt_labels.long().flatten()
# 根据索引矩阵,获得cls 8400
target_labels = gt_labels[target_gt_idx]
# 同理bbox同样操作,
# 根据索引矩阵,获得bbox 8400 x 4
target_bboxes = gt_bboxes[target_gt_idx]
# 类别转换为one-hot形式,8400xcls_num
target_one_hot_labels = torch.zeros((target_labels.shape[0],self.num_classes),
dtype=torch.int64,
device=target_labels.device)
# 赋值,对应的类别位置置为1, 即one-hot形式
target_one_hot_labels.scatter_(1,target_labels.unsqueeze(-1),1)
# 生成对应的mask,用于过滤负样本 8400 -> 8400x1 -> 8400 x cls_num
fg_labels_mask = fg_mask.unsqueeze(-1).repeat(1,self.num_classes)
# 正负样本过滤
target_one_hot_labels = torch.where(fg_labels_mask>0,target_one_hot_labels,0)
return target_one_hot_labels,target_bboxes上面提到,动态分配策略,可以根据训练情况动态的调整权重值,所以在训练过程中,需要设置一个动态的权重,实现在训练过程中对欠佳的预测结果(困难样本)惩罚的目的。
提问:那上面提到的这个动态的权重该如何设置,才能有这样的效果呢?
灵感:既然上面在选取正样本过程中进行了scores与overlaps的计算,那师傅是可以巧妙得利用这个结果,添加上一定的转换进而作为动态的权重呢?
同时,通过添加动态权重,也就更加深了cls与box的关联性,避免出现cls预测准确度很高,iou很低的情况。

答案是可以的,代码如下:
# align_metric,overlaps均需要进行过滤
align_metrics *= pos_mask # M x 8400
overlaps *= pos_mask # M x 8400
# 找个每个GT的最大匹配值 M x 1
gt_max_metrics = align_metrics.amax(axis=-1,keepdim=True)
# 找到每个GT的最大CIOU值 M x 1
gt_max_overlaps = overlaps.amax(axis=-1,keepdim=True)
# 为类别one-hot标签添加惩罚项 M x 8400 -> 8400 -> 8400 x 1
# 通过M个GT与所有anchor的匹配值 x 每个GT与所有anchor最大IOU / 每个类别与所有anchor最大的匹配值
norm_align_metric = (align_metrics*gt_max_overlaps/(gt_max_metrics+self.eps)).amax(-2).unsqueeze(-1)
# 8400 x cls_num,为类别添加惩罚项
target_labels = target_labels * norm_align_metric
b_target_labels[i] = target_labels附一张行人检测的效果图:



















 1134
1134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









