







YOLOv8 : TAL与Loss计算
1. YOLOv8 Loss计算
YOLOv8从Anchor-Based换成了Anchor-Free,检测头也换成了Decoupled Head,论文和网络资源中有大量的介绍,本文不做过多的概述。
Decoupled Head具有提高收敛速度的好处,但另一方面讲,也会遇到分类与回归不对齐的问题。具体来讲,在一些网络中,会通过将feature map中的cell与ground truth进行IOU计算以分配预测所用cell,但用来分类和回归的最佳cell通常不一致。为了解决这一问题,引入了TAL技术。想详细了解这一部分,可以参考“TOOD: Task-aligned One-stage Object Detection(https://arxiv.org/abs/2108.07755v3)”这篇论文。
YOLOv8采用了TAL(Task Alignment Learning)任务对齐分配技术(正负样本分配),并引入了DFL(Distribution Focal Loss)结合CIoU Loss做回归分支的损失函数,使用BCE做分类损失,使得分类和回归任务之间具有较高的对齐一致性。
2. TAL
TAL一般用在decoupled head网络中,用于将不同的任务进行对齐。典型的,用来解决分类与回归cell一致性问题,更具体的,TAL用于为计算LOSS所构建的GT feature map的cell分配标签。TAL,一句话,就是给feature map中的每一个cell(当然,也有人称做anchor)分配ground truth框。当然,有的cell能够分配到gt(ground truth)框,有的cell分配不到gt框。根据fm(feature map)与gt的分配情况,构建用于Loss计算的target_labels、target_bboxes和target_scores。
下面结合官方代码(class TaskAlignedAssigner)进行理论与工程化相结合的讲解。
第一步,计算位置掩码mask_gt,对齐度量矩阵align_metric和IOU矩阵overlaps,三者均为shape(bs, n_max_boxes, na),其中mask_gt标识每一个gt框的topk个匹配cells。align_metric计算方式如下:
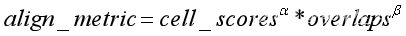
此处需要注意,cell_scores是经过mask_gt过滤过的得分矩阵,α默认取值为1.0,默认取值为6.0。
第二步,为每一个cell选择IOU最大的gt框,并标记。返回每一个cell匹配的gt索引target_gt_idx(shape(bs, na)),每一个cell匹配的gt数量fg_mask(shape(bs, na)),以及更新后的全局gt和anchor的匹配情况mask_pos(shape(bs, n_max_boxes, na))。
第三步,根据target_gt_idx构建用于loss计算的target_labels(shape(bs, na)), target_bboxes(shape(bs, na, 4))和target_scores(shape(bs, na, num_class))。
接下来做一些代码方面的解释。
在YOLOv8中,虽然使用了Anchor Free技术,但实际上也是存在Anchor的,那就是Feature Map本身的cell。接下来参照YOLOv8代码中的TaskAlignedAssigner做些了解。
(1) get_pos_mask
这一部分主要是获得gt候选cell的标记(mask_pos),对齐度量矩阵(align_metric)和gt与cell的IOU矩阵(overlaps)。
mask_pos: shape(bs, n_max_boxes, na),经过筛选的gt候选cell位置标记;
align_metric: shape(bs, n_max_boxes, na), gt候选cell的度量值;
overlaps: shape(bs, n_max_boxes, na),gt与其候选cell的IOU值;
下面就几个关键的节点函数做一些讲解。
mask_gt: shape为(bs, n_max_labels, 1), 实际上,在处理的时候是构建一个GT tensor, shape为(bs, n_max_labels)。我们知道,batch中每一幅图片所拥有的gt box数量并不相同,因此我们需要使用一个mask来标记哪一些是有效的,哪一些是无效的。
select_candidates_in_gts
将每一个GT Box与所有的cells进行ltrb的计算,本质上是确定哪些cell的中心点落在了GT范围内。如图一所示,蓝色半透明框为GT,那么橙色狂所标识的cell都被选为候选cell。
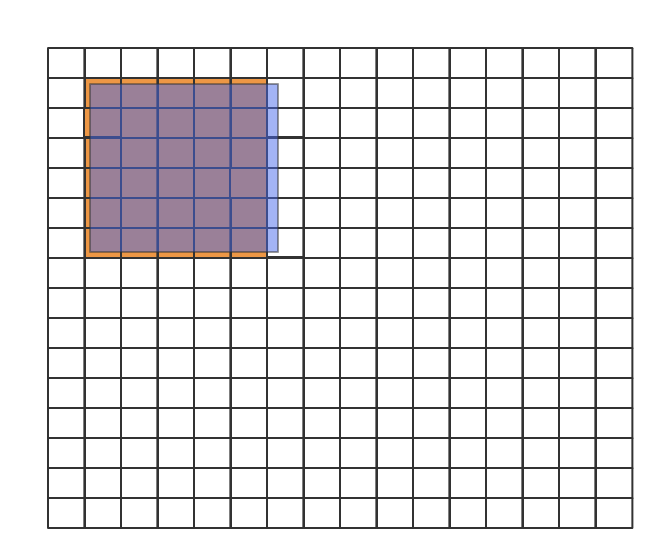
图一 Candidates cells
最终返回一个shape(ngt, n_max_labels, na)的tensor。
get_box_metrics
一个关键的导入参数是mask_gt, 用来标记对应每一个gt,中心点位于该gt内部的cell索引,shape为(bs, n_max_boxes)。我们在此称gt候选cell。
bbox_scores, shape(bs, n_max_boxes, na), 标识gt候选cell的得分,首先针对每一个gt,根据其lebel,获取对应所有cell的得分,然后通过mask_gt进行索引,得到每一个gt候选cell的得分。
overlaps,shape(bs, n_max_boxes, na), 标识gt候选cell的IOU信息。
align_metric, shape(bs, n_max_boxes, na), 对齐度量矩阵。
返回两个tensor, 其中第一个tensor是一种度量,shape为(bs, n_max_labels, total_cells)。第二各参数是gt与pred box的iou,shape为(bs, n_max_labels, total_cells)。
select_topk_candidates
首先通过torch.topk函数对metrics(align_metric)进行排序筛选,每个gt候选cell选取前topk个。得到topk_metrics和topk_idxs, shape均为(bs, n_max_boxes, topk)。
counter_tensor, shape(bs, n_max_boxes, na), 取值非0即1,取值1代表当前cell的度量值位于前topk。
总结为如下4个步骤:
- 构建gt候选cell;
- 构建gt候选cell的得分矩阵,IOU矩阵和对齐度量矩阵;
- 对对齐度量矩阵执行topk操作,标记符合topk的位置;
- 使用topk、候选cell和mask_gt执行过滤。
(2) select_highest_overlaps
参数mask_pos实际上是gt候选cell标记矩阵。
fg_mask = mask_pos.sum(-2)
计算每一个cell对应的gt数量。
当某一个cell服务于多个gt时,我们将gt与cell的IOU进行排序,并取iou最大的gt作为cell所最终服务的gt。
(3) get_targets
构建用于计算loss的信息,包括target_labels, target_bboxes, target_scores。
target_labels: shape(bs, na, 1)
target_bboxes: shape(bs, na, 4)
target_scores: shape(bs, na, num_classes)
3. DFL
DFL(Distribution Focal Loss),本质上是Focal Loss,是一种带权重的交叉熵。一般情况下,我们认为交叉熵常用作分类损失,根本上讲,是用在计算一种符合多项分布的预测Loss。
在论文“Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection”中,作者认为预测的目标框坐标是固定的,不能够灵活的表示(如图二所示)。针对一些便捷比较模糊的目标,很难确定边界的具体位置。DFL将边界表示成一种分布,解决边界不明确的问题。关于DFL具体理论,我们将做一个专题讲解。
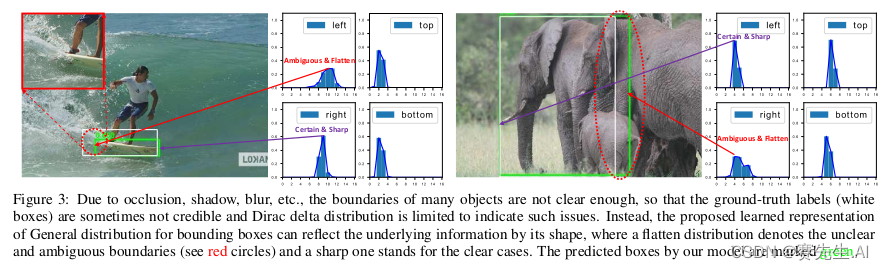
图二 边界分布
在官方代码中,网络输出pred_distri为一个shape(bs, 64, na)的Tensor,进一步permute为shape(bs, na, 64)的Tensor,再经过reshape为shape(bs, na, 4, 16)的Tensor,最后经过加权计算,获得shape(bs, na, 4)的LTRB输出。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









